技术特征:
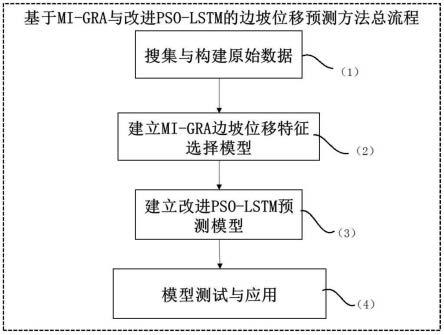
1.一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于,包括以下步骤:(1)搜集与构建边坡位移预测的原始数据;(2)在构建的边坡位移预测的原始数据基础上,建立mi-gra的边坡位移特征选择模型;(3)将经过特征选择后的数据作为边坡位移预测的最优特征集输入,建立改进pso-lstm边坡位移预测模型;(4)将建立好的边坡预测模型进行模型预测与测试。2.如权利要求1所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于,步骤(1)包括:边坡多源监测数据的搜集;在获得边坡监测原始数据后,针对缺失数据进行插补;将原始数据进行分类,分为位移数据和位移潜在影响因素数据。3.如权利要求2所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于,缺失数据的插补采用中位数插补的方法,其公式如下;该公式中,x
cb
为经过缺失值插补后的数据,x
t-1
为待插补点的前一个时刻的数据,x
t 1
为待插补点的后一个时刻的数据。4.如权利要求1所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:所述步骤(2)包括:在位移数据的基础上,利用mi算法优选最佳历史位移特征;在位移及位移潜在影响因素数据的基础上,利用gra算法优选位移影响因素特征;综合最佳历史位移特征和位移影响因素特征,获得最优特征集。5.如权利要求4所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:所述利用mi算法优选最佳历史位移特征包括以下步骤:将位移数据归一化处理,所述数据的归一化处理采用如下公式:x
scaled
=x
std
*(max-min) min该式中,x为要归一化的位移数据,x
min(axis=0)
为每列数据中的最小值组成的行向量,x
max(axis=0)
为每列数据中的最大值组成的行向量,max为要映射到的区间最大值,默认是1,min为要映射到的区间最小值,默认是0,x
std
为标准化结果,x
scaled
为归一化结果;构造每个预测日的特征矩阵s
input
和输出序列s
output
,特征矩阵s
input
和输出序列s
output
的公式如下:s
output
=[s(t 1)1…
s(t 1)
n
]
t
该式中,s
input
为特征矩阵,由各个历史位移特征构成,n取为30,代表历史位移特征数量为30个,f
k
(k=1,2
…
30)对应于第k个历史位移特征,s
output
为输出序列,由预测位移数据构成;计算互信息评价指标i(s
k
;s
output
);历史位移特征排序与优选。6.如权利要求5所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:计算互信息评价指标包括以下步骤:计算信息熵:h(f
k
)=-p(s
k
(i))log2∫p(s
k
(i))ds
k
(i)h(s
output
)=-∫p(s(t 1)
j
)log
2 p(s(t 1)
j
)ds(t 1)
j
h(f
k
,s
output
)=-∫∫p
joint
(s
k
(i),s(t 1)
j
)log
2 p
joint
(s
k
(i),s(t 1)
j
)ds
k
(i)ds(t 1)
j
该式中,h(f
k
)和h(s
output
)分别为的历史位移特征序列和输出序列的信息熵,用来度量各自的信息含量;h(f
k
,s
output
)为历史位移特征序列和输出序列的二维联合熵,用来量化变量间共有信息的大小,p为单个变量的边缘概率分布,p
joint
是两个变量之间的联合概率分布;计算互信息i(s
k
;s
output
):该式中,i(f
k
;s
output
)为历史位移特征序列和输出序列之间的互信息。7.如权利要求4所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:利用gra算法优选位移影响因素特征包括以下步骤:确定边坡位移特征选择分析数列:将位移数据及影响因素数据均值化后,设定位移数据为母序列y0,位移影响因素数据为比较序列x,记为:y0=[y0(1),y0(2),
…
,y0(n)]该式中,n为天数,m为边坡位移的影响因素指标个数;计算关联系数:该式中,δx=y0(j)-x
i
(j),ρ为分辨系数,一般取0.1~1.0,本文取0.5;计算关联度:
该式中,γ为关联度,一般大于0.6时可认为序列之间相关性较强,i=1,2,
…
,m;j=1,2,
…
,n;位移影响因素特征排序与位移主要影响因素确定。8.如权利要求1所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:所述步骤(3)中建立改进pso-lstm边坡位移预测模型包括以下步骤:a.获取山区边坡位移和位移主要影响因素的时序数据并对其做归一化处理,所述归一化处理与mi特征选择中的处理一致、采用的公式一致;b.将数据集划分为训练集、验证集和测试集,并将训练集和验证集输入lstm网络模型中;c.初步设置改进pso算法中的参数,并随机初始化lstm模型中待优化的超参数;d.计算粒子适应度(fit);e.分别更新个体最优和群体最优f.更新学习因子c1和c2、惯性因子w;g.判断迭代次数是否大于m
max
,满足条件则改进pso算法优化结束,否则转到步骤3,重复执行步骤d、e、f,直到满足判别条件;h.在获得最优网络模型配置的基础上进行模型的迭代训练,并保存模型。9.如权利要求8所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:所述lstm网络模型为深度学习模型,lstm网络模型循环单元的一次前向计算为:i
t
=σ(w
i
·
[h
t-1
,x
t
] b
i
)f
t
=σ(w
f
·
[h
t-1
,x
t
] b
f
)该式中,i
t
为输入门,f
t
为遗忘门,σ为sigmoid激活函数,可使门限的范围在0~1之间,x
t
为当前时刻的输入特征,h
t-1
表示上一时刻的隐藏状态,w
i
和w
f
分别为输入门和遗忘门的待训练权重矩阵,b
i
和b
f
是分别为输入门和遗忘门的待训练偏置项;候选态表示归纳出的待存入细胞态的新知识,是当前时刻的输入特征和上个时刻的隐藏状态的函数;细胞态表示长期记忆,它等于上个时刻的长期记忆通过遗忘门的值和当前时刻归纳出的新知识通过输入门的值之和,具体计算过程可以表示为:时刻归纳出的新知识通过输入门的值之和,具体计算过程可以表示为:该式中,为候选态,tanh为激活函数,w
c
为待训练权重矩阵,b
c
是待训练偏置项,c
t
为当前时刻的细胞态,c
t-1
为前一时刻的细胞态;输出门将细胞态中的信息选择性的进行输出,而隐藏状态可由当前细胞态经过输出门得到,具体计算过程可以表示为:o
t
=σ(w
o
·
[h
t-1
,x
t
] b
o
)h
t
=o
t
*tanh(c
t
)该式中,o
t
为输出门,w
o
和b
o
分别为输出门的待训练权重矩阵和偏置项,h
t
为当前时刻的隐藏状态;所述改进pso算法为传统pso算法的优化算法,包括:
改进学习因子,所述改进学习因子的改进公式如下:改进学习因子,所述改进学习因子的改进公式如下:该式中,m
cur
为当前迭代次数,m
max
为最大迭代次数,c
1b
、c
1e
、c
2b
和c
2e
分别为c1和c2的初始值和最终值,一般取c
1b
=2.5、c
1e
=0.5、c
2b
=0.5和c
2e
=2.5时算法效果较好;改进惯性因子惯性因子w越大,粒子飞行速度越大,粒子将以更长的步长进行全局搜索;惯性因子w较小,则趋向于精细的局部搜索,改进公式如下:该式中,ω
max
表示ω的最大值,ω
min
表示ω的最小值,f表示当前目标函数值,f
avg
表示当前平均目标函数值,f
min
表示目标函数极小值;所述目标函数以验证集上的平均绝对误差mae作为目标函数,其公式如下:该式中,n代表预测样本数,y(y1,y2,
…
,y
n
)为验证集中的实测边坡位移值,为在验证集上的预测边坡位移值。10.如权利要求1所述的一种基于mi-gra与改进pso-lstm的山区边坡位移预测方法,其特征在于:所述步骤(4)将建立好的边坡预测模型进行模型预测与测试包括以下步骤:预测模型调用,所述调用的预测模型为经过训练后保存好的改进pso-lstm边坡位移预测模型;测试集输入,并进行预测测试;所述预测测试方式为滚动预测;得到预测结果,进行模型预测精度的评估;所述模型精度评估采用选择拟合优度r2和平均绝对百分比误差mape,其公式如下:和平均绝对百分比误差mape,其公式如下:
该式中,r2为拟合优度,其值越大,模型精度越高,mape为平均绝对百分比误差,其值越小,预测误差越小,n为预测样本数,y
t
为测试集中的实测位移值,为测试集上的预测位移值,为实测值的平均。
技术总结
本发明公开了一种基于MI-GRA与改进PSO-LSTM的山区边坡位移预测方法,包括以下步骤:(1)搜集与构建边坡位移预测的原始数据;(2)在构建的边坡位移预测的原始数据基础上,建立MI-GRA的边坡位移特征选择模型;(3)将经过特征选择后的数据作为边坡位移预测的最优特征集输入,建立改进PSO-LSTM边坡位移预测模型;(4)将建立好的边坡预测模型进行模型预测与测试。本方法解决了既往预测算法本身均呈静态特性,不能兼顾边坡位移的历史信息,制约了预测精度的提升,以及既往边坡位移预测关注的重点仅仅只有位移本身,未能将位移影响因素纳入预测模型,导致预测效果不佳等问题。导致预测效果不佳等问题。导致预测效果不佳等问题。
技术研发人员:王武斌 邓志兴 谢康 董敏琪 李艳东
受保护的技术使用者:西南交通大学
技术研发日:2022.06.30
技术公布日:2022/10/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。