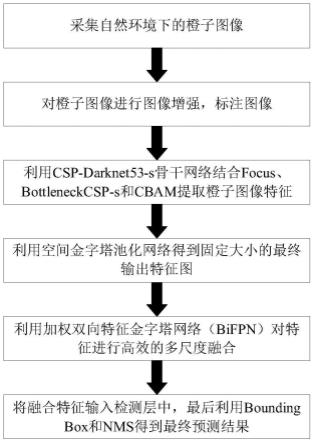
1.本发明属于目标实时检测领域,涉及一种基于深度学习的橙子采摘机器人目标实时检测方法.
背景技术:
2.水果采摘机器人目标检测识别技术主要应用在智慧农业生产领域。国内外相关研究人员在水果采摘机器人目标实时检测方面取得了一系列研究成果,水果采摘机器人目标实时检测的方法经历了基于传统数字图像处理、机器学习的图像处理以及深度学习的图像处理。
3.传统数字图像处理技术需要精确的目标果实特征信息,它曾经广泛的应用于水果采摘机器人目标检测研究中,并取得了很多成果。众多研究人员从水果颜色、纹理、形状和多特征融合等方面来分割识别水果。此类方法在环境较理想的情况下可以取得较好的识别效果,然而,由于自然环境下光线不均匀、土壤和天空等背景干扰、图像噪声等因素使得采用果实的光谱反射特性进行果实分割、提取和识别往往达不到理想的效果;其次对于枝叶遮挡果实、相互重叠果实的情况,采用果实的色彩、灰度信息往往不能分割和识别出单个果实区域;最后采用数字图像处理的方法进行果实识别时,特征提取过程大大增加了计算量,耗时而无法满足实时性的需求。
4.随着机器学习图像处理的方法日渐成熟,越来越多的分类识别算法被融入到水果采摘机器人目标检测研究中,并取得了很多成果,如贝叶斯算法、knn聚类算法、svm算法、k-means聚类算法等。虽然此类分类算法相较于传统数字图像处理可以取得较好的效果,但其也具有明显的缺点,如:通过滑动窗口策略进行区域选择时针对性不强且全局遍历运算量大,这提高了时间复杂度和窗口冗余;手动设计的特征对于目标的多样性并没有很好的鲁棒性。
5.近年来,深度学习的发展非常迅速,它被大量的应用于智慧农业领域,基于深度学习的卷积神经网络也被很多学者应用于水果采摘机器人目标检测研究中,如:cnn网络模型、alexnet网络模型、vggnet网络模型、残差神经网络(resnet)网络模型的水果目标检测、faster r-cnn网络模型、ssd网络模型和yolo网络模型等。以上各种基于深度学习的水果采摘机器人目标检测方法研究,受环境影响的程度较低,具备较强的特征学习能力,无需人工再进行复杂的特征组合与设计工作,节省了大量的人力物力,最后得到的水果识别准确率和速度都能媲美甚至远超于传统的基于传统数字图像处理和基于机器学习的水果目标检测方法。但是纵观基于深度学习的水果目标识别研究,现有的大部分水果检测模型虽然识别准确率较高,但由于其复杂度高、参数多、规模大、很多模型的实时性不足。
技术实现要素:
6.有鉴于此,本发明的目的在于提供一种基于深度学习的橙子采摘机器人目标实时检测方法,在保证水果识别准确率的同时,满足采摘机器人实时识别的要求。
7.为达到上述目的,本发明提供如下技术方案:
8.一种基于深度学习的橙子采摘机器人目标实时检测方法,包括以下步骤:
9.s1:采用yolov5s作为橙子目标实时检测的框架,将改进的csp-darknet-s作为骨干网络对橙子图像进行特征图提取,所述改进的csp-darknet-s为:将切片结构(focus)、改进的瓶颈层(bottleneckcsp-s)和cbam(convolutional block attention module)注意力机制模块进行结合得到的网络模型;
10.s2:将所述特征图输入空间金字塔池化网络(spp)进行最大池化,得到固定大小的最终输出特征图;
11.s3:采用加权双向特征金字塔网络(bifpn)架构作为颈部网络,将所述最终输出特征图输入到bifpn中,对特征图进行多尺度融合;
12.s4:将多尺度融合特征图输入到检测网路中,经过卷积层后,输出三个尺度的特征图;
13.s5:将三个尺度的特征图输入bounding box损失函数来预测边界和原始图像中目标的类别并标记;
14.s6:使用非极大值抑制(non maximum suppression,nms)来处理步骤s5中重复冗余的预测框,保留置信度最高的预测框信息,得到最终预测结果。
15.进一步,在步骤s1之前对橙子进行图像采集和图像增强,所述图像采集包括以下情况:橙子被树叶遮挡,橙子被树枝遮挡、混合遮挡、水果之间重叠、自然光角度、逆光角度、侧光角度;所述图像增强包括图像亮度增强和降低、水平镜像、垂直镜像、多角度旋转。
16.进一步,步骤s1中,所述切片结构(focus)的实施步骤为:首先输入608
×
608
×
3的图像,随后进行切片操作,从而得到304
×
304
×
12的特征图,随后再经过一次32个卷积核的卷积操作,最后输出304
×
304
×
32的特征图;
17.所述改进的瓶颈层(bottleneckcsp-s)为1个卷积核大小为1
×
1的卷积层(conv2d bn hardswish激活函数)与一个bottleneck模块和一个卷积核大小为1
×
1的卷积层连接起来的残差网络架构,瓶颈模块的最终输出是bottleneckcsp-s部分的输出和通过残差结构的初始输入的相加;
18.所述cbam注意力机制模块融合两种注意力机制,先是channel attention,然后是spatial attention,使用cbam提取需要注意的区域,以减少获取其他无关的信息。
19.进一步,步骤s1中,cbam注意力机制模块融合两种注意力机制,先是channel attention,然后是spatial attention,具体流程为:
20.将输入的特征图f(h
×w×
c)分别经过基于width和height的全局最大池化(global max pooling)和全局平均池化(global average pooling),得到两个1
×1×
c的特征图;
21.接着,再将两个1
×1×
c的特征图分别送入一个两层的神经网络(mlp),第一层神经元个数为c/r,其中r为减少率,激活函数为relu,第二层神经元个数为c,两层的神经网络是共享的;
22.而后,将mlp输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即m_c;
23.最后,将m_c和输入特征图f做element-wise乘法操作,生成spatial attention模
块需要的输入特征;
24.将channel attention模块输出的特征图f’作为spatial attention模块的输入特征图,首先做一个基于channel的全局最大池化(global max pooling)和全局平均池化(global average pooling),得到两个h
×w×
1的特征图;
25.然后将两个h
×w×
1的特征图基于channel做通道拼接(concat)操作;
26.接着经过一个7
×
7卷积操作,降维为1个channel,即h
×w×
1;
27.再经过sigmoid生成spatial attention feature,即m_s;
28.最后将m_s和m_c做乘法,得到最终生成的特征。
29.进一步,步骤s2中,金字塔池化网络(spp)通过一个1
×
1的卷积对步骤s1得到的特征图进行卷积操作,并通过三个平行的最大池化层(maxpooling)进行深度连接得到最终输出特征图。
30.进一步,步骤s3中,bifpn通过引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自下而上的多尺度特征融合,以聚合不同分辨率的特征。
31.进一步,步骤s4中,将步骤s3得到的多尺度融合特征图输入到检测网路中,经过卷积层后,输出76
×
76、38
×
38和19
×
19维的特征图,对应检测小目标、中目标、大目标。
32.进一步,步骤s5中,将步骤s4得到的三个尺度的特征图采用ciou_loss做bounding box的损失函数来预测边界和原始图像中目标的类别并标记,ciou_loss损失函数的计算公式为:
[0033][0034][0035][0036]
其中α表示预测框和目标框的长宽比,v表示衡量长宽比一致的参数,iou表示真实框和预测框之间的交并集,distance_22表示最小外接矩形对角线距离,w
gt
、h
gt
表示真实框的宽度和高度,w
p
、h
p
表示预测框的宽度和高度。
[0037]
进一步,步骤s6中,采用diou_nms来筛选预测框,diou_nms的表达式如下所示:
[0038][0039][0040]
其中表示高置信度候选框,是遍历各个候选框与置信度高的重合情况。
[0041]
本发明的有益效果在于:本方法解决了传统目标检测容易受到光照条件的影响、复杂背景影响、水果重叠遮挡、枝叶遮挡、水果成簇生长等问题,还克服了一般基于深度学习的水果检测方法计算时间长、复杂度高、参数多、梯度消失慢以及实时性不足等缺点。
[0042]
1)本发明能够解决自然光照条件变化、枝叶遮挡果实、果实聚类重叠遮挡的检测识别难题,使采摘机器人对橙子的目标识别具有较好的实时性和鲁棒性。
[0043]
2)本发明采用改进的轻量化yolov5s神经网络,不仅可以快速的识别出橙子,识别
橙子的准确度还很高,同时满足了识别的实时性和准确性。
[0044]
3)本发明将rgb彩色相机获取到的彩色图像缩放为480*480,极大减少模型训练和测试的计算量和运行时间。
[0045]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0046]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0047]
图1是本发明基于深度学习的橙子目标实时检测方法的流程示意图;
[0048]
图2是本发明基于改进的yolov5s目标检测框架中改进的瓶颈层bottleneckcsp-s的结构示意图;
[0049]
图3是本发明基于改进的yolov5s目标检测框架结构示意图;
[0050]
图4是本发明基于改进的yolov5s目标检测框架中注意力机制模块cbam的结构示意图;
[0051]
图5是本发明基于改进的yolov5s目标检测框架中加权双向特征金字塔网络(bifpn)融合底层和高层特征图的流程示意图。
具体实施方式
[0052]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0053]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0054]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0055]
请参阅图1~图5,本发明优选了一种基于深度学习的橙子目标实时检测方法,首先,需要进行橙子图像采集和图像增强,图像采集包括以下情况:橙子被树叶遮挡,橙子被
树枝遮挡、混合遮挡、水果之间重叠、自然光角度、逆光角度、侧光角度等。另外,图像增强方法包括图像亮度增强和降低、水平镜像、垂直镜像、多角度旋转等。然后进行橙子目标实时检测,包括如下具体步骤:
[0056]
(1)采用轻量级网络yolov5s作为橙子目标实时检测的框架,将改进的csp-darknet-s作为骨干网络,即结合切片结构(focus)、改进的瓶颈层(bottleneckcsp-s)和cbam(convolutional block attention module)注意力机制模块对橙子图像进行特征图提取;
[0057]
切片结构(focus)具体实施步骤为首先输入608
×
608
×
3的图像,随后进行切片操作,从而得到304
×
304
×
12的特征图,随后再经过一次32个卷积核的卷积操作,最后输出304
×
304
×
32的特征图;改进的瓶颈层(bottleneckcsp-s)为1个卷积核大小为1
×
1的卷积层(conv2d bn hardswish激活函数)与一个bottleneck模块和一个卷积核大小为1
×
1的卷积层连接起来的残差网络架构,瓶颈模块的最终输出是将该部分的输出与初始输入通过残差结构相加。
[0058]
cbam注意力机制模块融合了两种注意力机制,先是channel attention,然后是spatial attention,具体流程为:将输入的特征图f(h
×w×
c)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1
×1×
c的特征图,接着,再将它们分别送入一个两层的神经网络(mlp),第一层神经元个数为c/r(r为减少率),激活函数为relu,第二层神经元个数为c,这个两层的神经网络是共享的。而后,将mlp输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即m_c。最后,将m_c和输入特征图f做element-wise乘法操作,生成spatial attention模块需要的输入特征;将channel attention模块输出的特征图f’作为本模块的输入特征图。首先做一个基于channel的global max pooling和global average pooling,得到两个h
×w×
1的特征图,然后将这2个特征图基于channel做concat操作(通道拼接)。然后经过一个7
×
7卷积(7
×
7比3
×
3效果要好)操作,降维为1个channel,即h
×w×
1。再经过sigmoid生成spatial attention feature,即m_s。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
[0059]
(2)将步骤(1)得到的特征图输入空间金字塔池化网络(spp)进行最大池化得到固定大小的最终输出特征图,具体为:首先输入大小为512
×
20
×
20的特征图,经过卷积核大小为1
×
1的卷积层后输出大小为256
×
20
×
20的特征图;然后,将该特征图与经过三个平行的maxpooling层(最大池化层)进行二次采样的输出特征图进行深度连接,输出特征图的大小为1024
×
20
×
20;最后,通过具有512个卷积核的卷积层,得到大小为512
×
20
×
20的最终输出特征图。
[0060]
(3)采用加权双向特征金字塔网络(bifpn)架构作为颈部网络,将步骤(2)得到的最终输出特征输入到bifpn中,对特征图进行高效的多尺度融合;bifpn通过引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自下而上的多尺度特征融合,以聚合不同分辨率的特征。
[0061]
(4)将步骤(3)得到的多尺度融合特征图输入到检测网路中,经过卷积层后,输出76
×
76、38
×
38和19
×
19维的特征图,对应检测小目标、中目标、大目标。
[0062]
(5)将步骤(4)得到的三个尺度的特征图采用ciou_loss做bounding box的损失函
数来预测边界和原始图像中目标的类别并标记,采用其中ciou_loss做bounding box的损失函数。损失函数ciou_loss增加了一个影响因子既考虑了预测框和目标框的长宽比,又考虑了重叠面积和中心点距离,当目标框包裹预测框时,直接度量两个框的距离,使得预测框回归的速度和精度更高。ciou_loss损失函数的表达式如下所示:
[0063][0064][0065][0066]
其中α表示预测框和目标框的长宽比,v表示衡量长宽比一致的参数,iou表示真实框和预测框之间的交并集,distance_22表示最小外接矩形对角线距离,w
gt
、g
gt
表示真实框的宽度和高度,w
p
、h
p
表示预测框的宽度和高度。
[0067]
(6)使用非极大值抑制(non maximum suppression,nms)来处理步骤(5)中重复冗余的预测框,保留置信度最高的预测框信息,得到最终预测结果,采用diou_nms来筛选预测框。使用diou作为nms的标准,不仅考虑了重叠区域iou的值,还考虑了两个box中心点距离。diou_nms的表达式如下所示:
[0068][0069][0070]
其中表示高置信度候选框,是遍历各个候选框与置信度高的重合情况。
[0071]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。