1.本发明属于音视频处理领域,具体涉及一种基于跨媒体的室外重点场所人群异常行为预警系统和方法。
背景技术:
2.当前视频监控以及远程喊话系统已被广泛的用于公共场所实现治安辅助,提升社会治安管理能力。视频监控系统实时将监控现场信息传回监控中心,视频存储系统将视频场景数据录制并存储,在需要的时候监控中心管理人员可以根据需要将现场实时视频显示在监控屏幕上。目前城市中安装了大量监控摄像机,管理人员无法实时查看所有监控场景下所发生的事情,仅在接到报警的情况下将监控屏接入现场视频,或通过回看监控历史数据,辅助事件的解决处理。然而,对于酒吧、ktv等重点场所以及周边,出现的人群以青年人为主,而青年人群本身性格上容易冲动,在酒精等物质刺激下,几句无关紧要的言语或轻微的肢体接触,就可能导致双方产生纠纷,进而导致激烈肢体冲突,造成社会治安事件的严重后果。因此如何充分发挥当前已经部署监控视频网络,加强对重点场所人群异常行为监视能力,及时发现异常行为,在事态没有进一步恶化之前干预,遏制治安事件发生。这对提高社会治安管理水平,建设和谐社会有重要意义。
3.重点场所中活动人群之间陌生人较多,所产生的异常事件具有很高的偶发性。事件发生普遍具有从小纠纷到相互争吵,最终肢体冲突的逐步发展过程。在这个过程中,一般会出现人群聚集、激烈争吵、肢体接触等异样状态,面对这些异常情况如何利用视频监控网络,发现并通知治安人员在前期介入如在人群聚集、激烈争吵或肢体接触阶段,进行预警与干预。然而,重点场所如街道、菜场等,行人熙熙攘攘、车来车往、人声鼎沸等,环境十分嘈杂,如何从监控系统所拍摄音视频信息中,及时检测出异常状况是一个具体挑战性的问题。
4.现有的人群异常行为识别方法主要基于视频图像分析技术,通过提取视频中人群密度、人数、动作等信息,然后采用规则或机器学习算法判断是否存在异常。这些方法仅利用视觉信息,基于人群密度、人数等信息进行判断,面对街道、校门口等人群密集场所,误报率很高,完全无法在实际中应用。因此,要实现重点场所人群异常行为进行检测和识别,仅依赖单一视觉媒体信息进行分析,无法满足实际治安预警应用需求。
技术实现要素:
5.当前针对人群的异常检测主要基于视频图像人群聚集等特点来实现,这些方法在面对街道、菜场、集市等复杂场景中,使用人群聚集等方法无法识别出场景中是否出现异常,而这些公共场所是日常治安事件高发场所。
6.本发明提供一种基于跨媒体的室外重点场所人群异常行为预警系统和方法,通过基于音频和视频两种媒体的检测和识别算法实现预警功能,目标是在初始阶段准确发现人群异常,并通过自动语音喊话功能实时干预,实现早期介入处理,防止事态发展造成严重后果。通过提取音频和视频两种媒体融合信息,采用人工智能预测算法,实现复杂场景下的人
群异常行为的预警功能。
7.为了达到上述目标,本发明采用了如下技术方案:
8.本发明的一方面提供了一种基于跨媒体的室外重点场所人群异常行为预警方法,该方法包括以下步骤:
9.s1.配置云台摄像机,摄像机按照预设值的点位,定时巡检各预置点位;
10.s2.配置定向拾音器,拾音器拾音方向跟随摄像机转动,实现定向音频数据采集;
11.s3.定时间长度采集预置点位视角范围内的音视频数据混合数据流;
12.s4.服务器接收音视频数据并分离,获得视频流和音频流数据;
13.s5.提取视频流的关键帧,对预设区域进行人体和头部目标检测;
14.s6.对检测出的人体和头部分别采用自适应聚集密度评估算法得到监控区域范围内的最高人群密度值;
15.s7.采用背景声音去除算法对音频数据进行预处理;
16.s8.将固定时间长度的音频数据分割为指定采集频率的音频片段数据;
17.s9.将音频片段数据通过深度学习的卷积神经网络模型进行分类,确定该音频片段数据是否为人的说话音频;
18.s10.根据固定时间长度内的所有音频片段数据的音频分类结果,通过人声的比率是否超过设定阈值,确定本段音频是否为人的说话音频;
19.假如不是人的说话声则确定为背景音,采用原始音频计算背景音频声音强度等级;
20.s11.针对判断为人说话的音频,采用声音强度计算算法,对整段音频采用设定频率计算片内的声音强度,得到整个固定时间长度内音频强度值列表;
21.s12.将音频强度值列表输入音频烈度判别模型,得到人声烈度等级;
22.s13.根据背景音频声音强度等级,自动调整人群密度阈值;
23.s14.将自动调整后的人群密度阈值与s6中得到最高人群密度值进行比较,如果s6中得到最高人群密度值大于等于人群密度阈值,则对最高人群密度区域采用人员变动识别算法,判断这个时段内,该区域的大多数人员是否有变化;
24.s15.融合s12得到人声烈度等级、s6中得到最高人群密度值以及s14人员变化判断结果,判断在摄像机监控区域内是否出现争吵,实现跨媒体音视频流的处理能力;
25.s16.根据s15的结果,判断是否满足预警要求,假如需要预警,输出预警类型并启动远程喊话,提前干预现场;
26.s17.重复s3~s16上述步骤完成室外重点场所人群异常行为的实时预警。
27.本发明的另一方面提供了一种基于跨媒体的室外重点场所人群异常行为预警系统,该系统包括:
28.视频数据采集模块,由带有云台摄像机按照预设值的点位,定时巡检各预置点位采集监控区域范围内的视频数据;
29.音频采集模块,拾音器跟随摄像机转动,定向采集音频数据;
30.音视频数据合成模块,通过将音视频数据按时间同步合成音视频流,实现网络传输;
31.音视频数据分离模块,服务器接收网络传输的音视频数据并分离,获得视频流和
音频流数据;
32.人体和头部目标检测模块,对视频流解码后获得的帧图像,在预设区域范围内检测所有人体和头部的位置坐标;
33.自适应人群聚集密度估算模块,根据场景中人群的远近采用与距离相关的自适应聚集密度算法估算人群密度;
34.背景声音去除模块,对接收的音频数据,采用背景声音去除算法,去除背景声音;
35.音频分割模块,将固定时间长度的音频分割为指定采集频率的音频片段数据;
36.人声片段识别模块,对音频片段数据采用深度学习的卷积神经网络模型判断是否为人声;
37.人声整段识别模块,根据固定时间长度内的所有音频片段数据的音频分类结果,通过人声的比率是否超过设定阈值,确定本段音频是否为人的说话音频;假如不是人的说话声则确定为背景音,采用原始音频计算背景音频声音强度等级;
38.音频强度值列表计算模块,针对判断为人说话的音频,采用声音强度计算算法,对整段音频采用设定频率计算片内的声音强度,得到整个固定时间长度内音频强度值列表;
39.人声烈度等级识别模块,根据音频强度列表采用智能判别模型,得到人声烈度等级;
40.人群密度阈值调整模块,根据背景音频强度等级,自动调整人群密度阈值;
41.人员流动识别模块,针对高密度人群区域范围,采用人员变化识别算法,判断聚集的人群是否流动;
42.争吵行为识别模块,根据声音烈度等级、人群密度以及人员流动结果,判断在是否出现争吵行为;
43.预警远程喊话模块,输出行为异常预警信息,并启动远程网络语音播放系统,自动播放预设语音内容。
44.本发明的有益效果:本发明采用跨媒体即音视频媒体,提取固定片段内的音频烈度信息、视频人群聚集信息以及肢体动作信息,实现室外重点场所人群异常行为预警方法。该方法除避免了现有方法无法区别音频是否为人声以及人声烈度、无法在室外监控场景下自适应计算人员聚集度以及无法快速识别聚集人员是否变化,采用跨媒体融合方法提高了复杂环境室外下重点场所人群异常行为识别能力,大幅降低误识率。
附图说明
45.图1为室外设备安装示意图。
46.图2为部分典型场景的音频频谱对比图。
47.图3为本发明的音视频流分析处理流程图。
具体实施方式
48.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单介绍,对于本领域一般技术人员来讲,在不付出创造性劳动的前提下,可以根据这些附图获得其他的附图。
49.一种基于跨媒体的室外重点场所人群异常行为预警方法,包括以下步骤:
50.s1.配置云台摄像机,摄像机按照预设值的点位,定时巡检各预置点位;
51.s2.配置定向拾音器,拾音器拾音方向跟随摄像机转动,实现定向音频数据采集;
52.s3.按参数配置方式定时间长度采集预置点位视角范围内的音视频数据混合数据流;
53.s4.服务器接收音视频数据并分离,获得视频流和音频流数据;
54.s5.提取视频流的关键帧,对预设区域进行人体和头部目标检测;
55.s6.对检测出的人体和头部分别采用自适应聚集密度评估算法得到监控区域范围内的最高人群密度值;
56.进一步的,还可以调节摄像机焦距以及云台,将相机拍摄区域定位到高密度人群区域范围,拍摄更加清晰的视频数据,检测区域范围内的人体骨骼关键点,将得到的多人骨骼关键点输入肢体冲突行为识别模型,判断是否存在肢体冲突行为;
57.s7.采用背景声音去除算法对音频数据进行预处理;
58.s8.将固定时间长度的音频分割为指定采集频率(f1)的片段数据;
59.s9.将音频片段数据通过深度学习的卷积神经网络模型进行分类,确定片段是否为人的说话音频;
60.s10.根据固定时间长度内的所有片段数据的音频分类结果进行判断,通过人声的比率是否超过设定阈值,确定本段音频是否为人的说话音频;
61.假如不是人的说话声则确定为背景音,采用原始音频计算背景音频声音强度等级;
62.s11.针对判断为人说话的音频,采用声音强度计算算法,对整段音频采用设定频率(f2)计算片内的声音强度,得到整个固定时间长度内音频强度值列表;
63.s12.将音频强度值列表输入音频烈度判别模型,得到人声烈度等级;
64.s13.根据背景音频强度等级,自动调整人群密度阈值;
65.s14.假如s6中得到最高人群密度值大于等于人群密度阈值,则对最高人群密度区域采用人员变动识别算法,判断这个时段内,该区域的大多数人员是否有变化;
66.s15.融合s12得到声音烈度等级、s6中得到最高人群密度值以及s14人员变化判断结果,判断在该摄像机监控区域内是否出现争吵,实现跨媒体音视频流的异常行为识别能力;
67.s16.根据s15的结果,判断是否满足预警要求,假如需要预警,输出预警类型并启动远程喊话,提前干预现场;
68.s17.重复s3~s16上述步骤完成室外重点场所人群异常行为的实时预警功能。
69.本发明提供一种基于跨媒体的室外重点场所人群异常行为预警系统,它包括:
70.视频数据采集模块,由带有云台摄像机按照预设值的点位,定时巡检各预置点位采集监控区域范围内的视频数据;
71.音频采集模块,拾音器跟随摄像机转动,定向采集音频数据;
72.音视频数据合成模块,通过将音视频数据按时间同步合成音视频流,实现网络传输;
73.音视频数据分离模块,服务器接收网络传输的音视频数据并分离,获得视频流和音频流数据;
74.人体和头部目标检测模块,对视频流解码后获得的帧图像,在预设区域范围内检测所有人体和头部的位置坐标;
75.自适应人群聚集密度估算模块,根据场景中人群的远近采用与距离相关的自适应聚集密度算法估算人群密度;
76.背景声音去除模块,对接收的音频数据,采用人声与背景声音分离算法,去除背景声音;
77.音频分割模块,将固定时间长度的音频分割为指定采集频率的音频片段数据;
78.人声片段识别模块,对音频片段采用深度学习的卷积神经网络模型判断是否为人声还是其它声音;
79.人声整段识别模块,根据固定时间长度内的所有音频片段数据的音频分类结果,通过人声的比率是否超过设定阈值,确定本段音频是否为人的说话音频;假如不是人的说话声则确定为背景音,采用原始音频计算背景音频声音强度等级;
80.音频强度值列表计算模块,针对判断为人说话的音频,采用声音强度计算算法,对整段音频采用设定频率计算片内的声音强度,得到整个固定时间长度内音频强度值列表;
81.人声烈度等级识别模块,根据音频强度列表采用智能判别模型,得到人声烈度等级;
82.人群密度阈值调整模块,根据背景音频强度等级,自动调整人群密度阈值;
83.人声烈度等级识别模块,根据音频强度列表采用智能判别模型,该模型基于说话声音快慢高低变化判断烈度等级;
84.人员流动识别模块,针对高密度人群区域范围,采用人员变化识别算法,判断聚集的人群是否流动;
85.争吵行为识别模块,根据声音烈度等级、人群密度以及人员流动结果,判断在是否出现争吵行为;
86.预警远程喊话模块,输出行为异常预警信息,并启动远程网络语音播放系统,自动播放预设语音内容。
87.还可以包括肢体冲突行为识别模块,根据高密度人群区域范围内的人员骨骼关键点,采用智能推理算法,判断是否出现肢体冲突行为;
88.进一步说,s5中采用基于深度学习端到端的目标检测模型,对模型利用fp16半精度计算方法以及tensor rt加速技术实现在图像的预设区域中快速检测人体和头部区域并输出矩形区域坐标。
89.进一步说,s6中根据s5检测人体或头部矩形,求得矩形中心点坐标。本发明所涉及场景的摄像机由于采用倾斜安装并且安装高度和角度固定,拍摄范围的近处人员轮廓比较大,而远程人员轮廓比较小。但是在同一个y坐标轴位置的人员成像大小基本是一致的。根据这个应用特殊要求,本发明设计一种基于y轴距离的自适应密度评估算法,具体是:
90.根据拍摄到人体的正面或背面,或者根据拍摄到的未戴帽子的人头区域坐标,将拍摄到的多个人的肩宽或人头的x方向宽度进行平均,基于均值像素估计人员位置以及人员之间的距离,对检测区域内的人员距离进行归一化,然后利用公式(1)计算出场景中人群的最高密度值,式中d为设定阈值。通过该算法实现不同场景、不同摄像机架设角度等复杂应用场景下的自适应处理能力。
[0091][0092]
进一步说,s7中采用基于深度学习端到端的非人声的背景去除算法,实现在复杂环境中提取说话人声音,完成对原始音频数据进行预处理。
[0093]
进一步说,s9中将s8所获取的音频片段,分别按顺序输入判断是否为人的说话音频的卷积神经网络模型。针对相同类型声音内部差异性大、部分声音类型之间相似性高的特点,为提升模型的分类效果,提出一种基于空间向量距离的中心间隔距离目标函数用于模型的训练。目标函数新增加的部分如公式(2)所示,该函数实现强化相同类型内部特征的聚集,不同类型特征距离增加的目标。
[0094][0095]
公式中c
yi
为声音类型的中心,该中心在训练过程中动态变化,cj为不等于c
yi
的其它声音类型的中心,函数h(x)=max(x,0),k为声音类型个数,n为训练每批次的数量,o
l
为卷积神经网络的输出特征向量,mrg为最小距离约束参数。
[0096]
进一步说,s11中对音频按照设定时长如四分之一秒,计算该时长内的声音平均强度,得到一个音频强度列表a[m],m为个数。a[m]生成采用公式(3)计算所得,式中avg为平均值函数,f(x)为求声音强度方法,segi为第i个音频切片。
[0097][0098]
进一步说,s12中将s11中获得的音频强度列表a[m]输入音频烈度判别模型,该模型根据人的声音强度值的高低以及强度高的人声出现频度,采用智能分类算法输出等级。
[0099]
进一步说,s13中,根据背景音响度等级,自动调整人群密度阈值,其目的在于针对不同场景条件下人流量差异大,如夜深人静时,发生争吵行为围观的人员会比较少,这样人群密度阈值就需要调小。
[0100]
进一步说,s14中采用人员变动识别算法,得到不同时刻同一行人的位置坐标,其目的在于确定高密度人群是否为流动人群。针对节假日期间景点流量大时,虽然人群密度高于阈值,但是该场景为正常场景不需要预警。流动判别方法如公式(4),式中dist为距离公式,n为人员个数,d为阈值,pi(t)为第i个人在t时刻的位置坐标。
[0101][0102]
公式中pi(t 1)可能已经消失,则直接采用一个远点坐标替换,使得距离计算结果远大于d。本发明在如何判断不同时刻所拍摄的目标为同一个人员时,与现有直接采用人员轨迹跟踪算法不同,本发明采用基于外形识别的方法,实现人员轨迹分析近似效果。该方法在室外开放环境下,在不影响系统响应的基础上,大幅度降低计算复杂度,降低了系统的部署成本。原来目标跟踪算法一般需要每秒检测三帧以上,本发明可以间隔5-10秒检测一帧,需要的计算量大大降低。
[0103]
综上,本发明针对发明中需要面对的人群聚集、音频识别、人员变化识别等核心问
题,结合应用场景的特殊要求,分别设计了基于y轴距离的自适应密度评估算法、基于空间向量距离的中心间隔距离模型以及人员变动识别算法。基于y轴距离的自适应密度评估算法解决了在倾斜视角下的人员密度快速估计问题;基于空间向量距离的中心间隔距离模型实现在不改变推理计算复杂度的前提下,提高分类识别效果;基于外形的人员变化识别算法则是采用外形对比以及欧式距离公式实现了传统人员轨迹跟踪算法的效果,大幅度地降低了方法的算力。表1展示了空间向量距离的中心间隔距离模型与非改进前在测试数据集上的改进效果,重复10次取平均值。
[0104]
表1空间向量距离的中心间隔距离模型实验结果
[0105]
方法名称识别准确率vgg标准模型89.16 0.21空间向量距离的中心间隔距离模型(vgg骨干网络)93.58 0.25
[0106]
表2为在相同硬件(geforce gtx 1050,i5处理器),处理视频的速度对比。
[0107]
表2基于外形的人员变化识别算法速度对比
[0108]
方法名称识别速度基于deep sort轨迹跟踪的人员变化识别算法40帧基于外形的人员变化识别算法813帧
[0109]
说明:帧数是实际视频处理过程中通过的帧总数(包括跳过的帧)。
[0110]
如图1所示,本实施例需要在室外监管场所中安装了一个面向监控区域的摄像机1、一个远距离拾音器2和一个扩音器3。其中摄像机要求带有云台以及变焦控制功能,拾音器能够清晰采集设定区域范围的说话声音,扩音器在设定范围能以震慑的音量喊话,三者都安装在立杆4上。
[0111]
本实施例内容处理内容涉及以下几个方面:音频类型识别、说话声音烈度等级分类、人群密度估计、肢体冲突行为推断、人员流动分析以及跨媒体信息融合的人群异常行为预测。
[0112]
1)音频类型识别是针对室外场景中存在大量复杂声音,如汽车声、下雨声、鸟叫声、切割声、电钻声等,采用海量不同场景下音频数据训练声音类型识别模型,实现准确识别监控场景音频类型,判断场景中是否有人说话,在第一时间排除非说话声的场景,避免算力浪费。
[0113]
2)说话声音烈度等级分类是根据图2中展示部分不同类型声音,它们的频谱特点有显著差异,根据日常生活经验,处于争吵的人情绪都比较激动,说话声音的频率高且声音大,本算法基于这个特点进行设计。通过采集大量不同类型说话场景,基于声音强度和语义激烈程度采用人工智能算法预测说话声音烈度等级。
[0114]
3)人群密度估计采用深度卷积神经网络方法对监控场景中人体目标进行识别,一般而言普通行人之间会保持一定的社交距离,一旦有异常事件发生如争吵,部分行人就会驻留造成人群聚集。算法分别统计人头和人体,通过人体或人头尺寸,估计行人之间距离,采用归一化方法重新构建人员位置分布图,降低了摄像机因倾斜拍而影响密度估计结果。其中人群聚集密度估计采用欧氏距离算法遍历计算每个人员周边的密度指数,距离越小指数越高,得到人群密度最高的区域范围。
[0115]
4)肢体冲突行为推断需要在一段时间内根据肢体动作的变化来识别是否存在打
架的冲突行为。对视频流按照设定时间间隔(f3)抽取帧,对人群密度最高的区域范围的人体采用肢体关键点识别,分别求出人群中相互位置最近的人,将所获关键点位置对分别输入肢体动作识别模型。假如识别为冲突行为动作比例超过阈值,则推断为发生肢体冲突行为。
[0116]
5)人员流动分析是针对当某个区域出现聚集,而且聚集区域的人体位置在视频流中变化不大时,需要进一步确定人群中的个体是否出现变化。分析算法采用人员变动识别算法对视频片段聚集区域的人群进行跟踪并获得平均移动距离,当距离超过阈值,判定聚集区域人群为流动人群,否则判定人群未移动。
[0117]
6)跨媒体融合信息的人群异常行为预测则是基于上述音视频分析和识别的结果,采用信息融合以及人工智能推理模型,对监控范围内是否出现人群异常行为进行预测。
[0118]
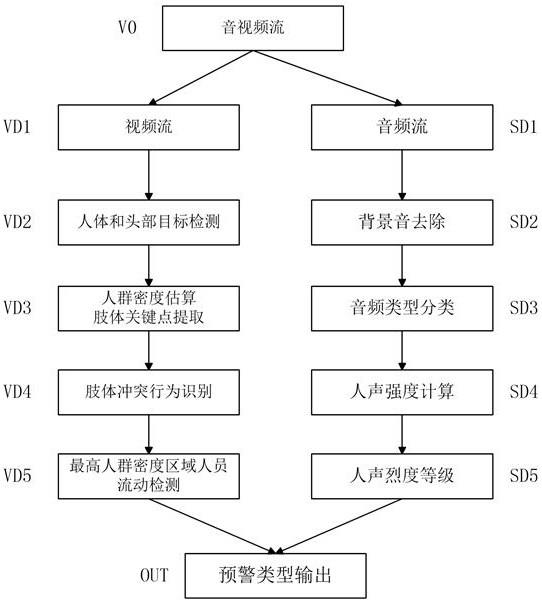
上述内容可以采用图3的处理流程进行描述,具体如下:
[0119]
1)v0为现场音视频采集设备,分别采集音频流和视频流数据,并分别进行编码按时间同步生成音视频流,采用流媒体协议进行传输;
[0120]
2)服务器或边缘处理设备通过网络采集到音视频流媒体数据,将音视频流分离,并分别解码,分别进入vd2和sd3处理步骤;
[0121]
3)vd2步骤中采用人体和头部目标检测算法,检测出监控区域范围内是否有人的出现;
[0122]
4)vd3步骤中,对vd2中检测的结果采用自适应人群密度检测算法,获得人群密度最高的区域,并对密度最高区域的人群提取肢体关键点;
[0123]
5)vd4步骤中对视频流提取肢体关键点流,通过肢体冲突行为识别算法,识别是否存在肢体冲突行为;
[0124]
6)vd5步骤中采用人员变化识别算法对最高密度人群区域的人群进行跟踪,判断该区域的人群是流动还是停留;
[0125]
7)sd2步骤中,对音频流采用去背景音算法提取人的说话声音,降低背景噪音对后续处理的影响;
[0126]
8)sd3步骤中,对去背景音后的音频流采用声音类别分类模型,判断是否为人的说话音频;
[0127]
9)sd4步骤中,采用声音强度计算方法,将音频流转化为一组数值;
[0128]
10)sd5步骤中,采用声音烈度计算模型对音频流的对话激烈程度进行分级;
[0129]
11)out步骤中,融合视频流和音频流的相关分析和识别信息,输出预警类型。
[0130]
综上所述,本发明通过采用跨媒体智能技术处理监控场景中采集的音视频流数据,对所获取的音视频数据分离处理;其中视频数据帧检测出包含的人体和头部目标,利用自适应聚集密度评估算法,得到监控范围内最高人群密度值以及区域范围,对所获区域范围的人体进行关键点检测,采用基于肢体关键点的冲突行为识别模型判断是否存在肢体冲突行为。
[0131]
音频数据在去除背景噪音以及切成片段后,采用深度卷积神经网络模型直接分类确定音频内容是否为人的说话声音。基于固定时间内所有片段的分类结果确定是否为人在说话,假如不是则计算原始音频背景音强度等级,否则按设定频率计算去除背景音的音频强度,得到强度值列表;将强度值列表输入音频烈度判别模型得到人声烈度等级。
[0132]
最终融合人声烈度、人群密度和人流变化信息,实现室外重点场所人群异常行为的实时预警的目标。
[0133]
以上为本发明的最佳实施方式,依据本发明公开的内容,本领域的普通技术人员能够显而易见地想到的一些雷同、替代方案,均应落入本发明保护的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。