1.本发明属于光伏功率预测技术领域,尤其涉及一种基于特征工程的 光伏发电短期预测方法。
背景技术:
2.太阳能具有分布范围广、能量密度大、清洁环保的特点,被认为是 未来最具竞争力的新能源之一。与火力、水力发电不同,光伏发电具有 不确定性。地表太阳能属于间歇性能源,受太阳辐照强度与气象状况的 影响,输出功率呈现出间断性和随机性等特征。将光伏电能高比例并入 电网,大大增加了电力调度的难度,迫切需要对其发电功率进行准确预 测,以满足电力系统的要求。
3.在传统的预测方法上,多数采用概率论和统计学的拟合方法,如最 小二乘法进行拟合、经验公式法、马尔科夫链等,计算方法简单,但受 地面天气变化的影响大,容易被异常值干扰。随着元启发学习算法的兴 起,目前更多的研究采用支持向量机和各类人工神经网络的算法,包括 bp神经网络、前馈神经网络和反馈神经网络在内的神经网络都在预测 中取得了较好的效果,但是现有技术的预测精度和有效性较差。
技术实现要素:
4.本发明要解决的技术问题是:提供一种基于特征工程的光伏发电短 期预测方法,以解决传统方法存在的预测精度和有效性较差等技术问题。
5.本发明的技术方案是:
6.一种基于特征工程的光伏发电短期预测方法,它包括:
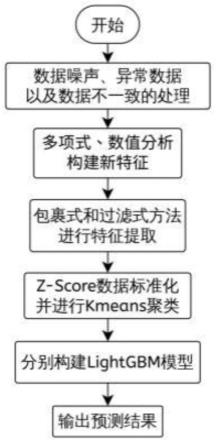
7.步骤1、采集历史发电数据和气象数据,并进行数据噪声、数据异 常、数据不一致问题的识别及处理;
8.步骤2、利用多项式和数值分析的方法对历史数据进行新特征的构 建,通过包裹式和过滤式的方法进行特征提取;
9.步骤3、对所有数据进行z-score标准化和规范化;对历史光伏功 率数据进行聚类划分;
10.步骤4、将聚类划分后的二类光伏功率数据及特征组合划分为训练 集、验证集和测试集,分别构建lighgbm模型并得到预测结果。
11.步骤1所述数据噪声的处理方法为:将相关特征负值数据进行修正, 将辐照度为负值的数据删除,功率为负值的数据修正为0;异常数据的 处理,将离群的少量数据设定为异常数据,利用正态分布的95%分位 点对辐照度和功率数据的异常值进行剔除,如下公式所示:
[0012][0013]
式中,σ代表数据的标准差,n为样本数量,xi表示第i个数据,表示该 数据特征下的平均值,根据单侧检验显著性水平0.05对应的标准正态分 布的分位数为1.645,式中b代表95%分位点的下界,为数据期 望值,即平均值。
[0014]
数据不一致问题的处理方法为:考虑辐照度与功率正相关的关系,设置 6.5个单位的辐照度为辐照度阈值,将辐照度达到1.5倍阈值而功率小 于功率均值0.5%的数据进行删除;将数据的辐照度划分成若干个足够 小的区间,对每个区间内的功率与辐照度比值进行正态分布95%分位 点筛选。
[0015]
步骤2所述利用多项式和数值分析的方法对历史数据进行新特征的 构建的方法包括:
[0016]
步骤2.1、数据集中包含的基本特征集合有:温度、湿度、压强、 风速、风向和辐照度特征,为增加特征间的线形关系,将特征进行二次 和三次多项式特征处理,将已有特征的自乘二次和三次以及特征间的互 乘二次和三次结果加入到特征集合中;
[0017]
步骤2.2、通过数值分析考虑时间特征和气象数据,将已有特征的 日均值、最大值、最小值和极差加入到特征集合,将每条数据所处 的月份、该月所处天数、当日日出时长作为新的特征,将日最大辐 照度的时间与当日日出时间的差值加入到特征集合中。
[0018]
所述通过包裹式和过滤式的方法进行特征提取的方法为:
[0019]
步骤2.3、通过过滤式方法进行初步筛选,根据下式计算各个特征的 皮
[0020]
尔逊相关系数,并设置筛选阈值为0.2;
[0021][0022]
式中,n为样本数量,xi,yi为变量x,y对应的i点观测值,分别 为x,y样本的平均数,r即皮尔逊相关系数,其取值情况可以反映x,y 两个样本之间的关系。
[0023]
步骤2.4、将数据等距离离散化,对于每一个特征和标签的数据,将连 续数值分为10个相等的区间,根据下式计算各个区间中特征的信息增 益,提取信息增益前50的特征;
[0024][0025][0026]
其中gain(a)为信息增益,a代表属性,d代表原有数据集,dv代表 新增某一条件时,自变量取某一值时对应的样本数目,v即表示新增的 某一特征数据;ent(d)为数据的信
息熵,m为特征数目,pi是标签在 某一取值时的频率;
[0027]
步骤2.4、将筛选得到的两个特征集合取并集进行下一步的筛选;
[0028]
步骤2.5、通过前向选择的包裹式方法,筛选出新增某一特征后新的特 征子集的信息熵低于之前信息熵3%的特征作为最优新增特征,将最 优新增特征增值添加到特征集合中,直至遍历所有的特征集合且特征子 集不再变化。
[0029]
对所有数据进行z-score标准化的公式为:
[0030][0031]
其中x
*
为标准化后得到的数据,μ为对应某一特征的平均值,σ为 对应某一特征的标准差,标准化得到的数据值落于-1.5到1.5之间,标 准化后数据的均值和标准差均为1。
[0032]
规范化的方法为:将数据的时间范围设定为每天的08:00-19:00, 时间间隔为15min,对于原始功率数据中在此区间之外的删除,在此区 间内开始或最后缺失的设为0,区间内缺失的利用线形插值进行补充。
[0033]
对历史光伏功率数据进行聚类划分的方法为:将一天的功率数据序 列作为一个样本数据,根据欧氏距离进行迭代计算;最后将数据集划分 为两类,一类的总体功率数值高且日功率数据偏向于正态分布,偏向于 各季节晴天天气特征;另一类的总体数据功率数值低且有数值突变,偏 向于阴雨天等极端的天气特征。
[0034]
选取均方根误差mse与平均绝对百分比误差mape进行预测结 果进行评估,
[0035][0036][0037]
式中,n表示预测的数据数目,wi分别代表第i个预测数据和实 际的发电数据。
[0038]
在计算mape时设置选取阈值为3%的日最大功率值;上式中,n 为样本数量,与wi分别是第i个样本的预测值与真实值。
[0039]
本发明的有益效果:
[0040]
本发明的光伏发电短期预测方法,对噪声数据、异常数据、数据不 一致问题进行处理后,通过数值分析和多项式方法进行数据的特征工程 构造,通过包裹式和过滤式方法结合进行特征选择,然后由简单稳定的 kmeans算法对数据进行聚类划分,得到两类不同天气特征的数据子集, 分别构建lightgbm预测模型进行预测;相比于传统的预测模型更加注 重天气数据的影响,对于lightgbm预测模型相比简单的gbdt模型, 运算速度更快;基于特征工程的lightgbm预测模型有更强的非线性表 述能力,增加了预测的准确性。
[0041]
本发明通过特征工程充分挖掘数据信息,结合基于集成思想的 lightgbm模型,较传统方法在不同的气候条件下提高了预测精度和有 效性。
附图说明
[0042]
图1是本发明预测方法的流程图;
[0043]
图2是本发明无特征工程多层感知机的部分预测结果示意图;
[0044]
图3是本发明无特征工程lightgbm模型的部分预测结果示意图;
[0045]
图4是本发明经特征工程后多层感知机的部分预测结果示意图;
[0046]
图5为是本发明经特征工程后lightgbm模型的部分预测结果示 意图。
具体实施方式
[0047]
本实施例具体包括以下步骤
[0048]
对相关数据的收集。本实施例以某地2017年1月-2018年12月 的历史发电数据和气象数据为研究对象。
[0049]
步骤1、数据噪声、数据异常、数据不一致问题的识别及处理;
[0050]
步骤1.1、数据的噪声主要来源于记录错误、电厂电力不足或某 些特殊情况下,表现为小部分功率产生数据为负值,将主要的相关特 征负值数据进行修正,将辐照度为负值的数据删除,功率为负值的数 据修正为0;
[0051]
步骤1.2、异常数据的处理,将离群的少量数据设定为异常数据, 利用正态分布的95%分位点对辐照度和功率数据的异常值进行剔除, 如下公式所示:
[0052][0053]
式中,σ代表数据的标准差,n为样本数量,xi表示第i个数据,表示该 数据特征下的平均值,根据单侧检验显著性水平0.05对应的标准正态分 布的分位数为1.645,式中b代表95%分位点的下界,为数据期 望值,即平均值。
[0054]
步骤1.3、数据不一致问题的处理,考虑辐照度与功率强正相关 的关系,设置6.5个单位的辐照度为辐照度阈值,将辐照度达到1.5 倍阈值而功率小于功率均值0.5%的数据进行删除;将数据的辐照度 划分成若干个足够小的区间,对每个区间内的功率与辐照度比值进行 正态分布95%分位点筛选。
[0055]
步骤2、对数据进行特征工程构建与选择;
[0056]
步骤2.1、通过已有数据中的特征进行多项式特征构造和数值分 析特征构建;
[0057]
步骤2.1.1、目前得到的数据集中包含的基本特征集合有:温度、 湿度、压强、风速、风向和辐照度特征,为增加特征间的线形关系对 其进行二次和三次多项式特征处理,将已有特征的自乘二次和三次以 及特征间的互乘二次和三次结果加入到特征集合中;
[0058]
步骤2.1.2、通过数值分析考虑时间特征和具有强物理意义的气象 数据,将已有特征的日均值、最大值、最小值、极差加入到特征集合, 将每条数据所处的月份、该月所处天数、当日日出时长作为新的特征, 将日最大辐照度的时间与当日日出时间的差值加入到特征集合中。
[0059]
步骤2.2、通过过滤式和包裹式相结合的方法对已有的特征集合进 行特征选择;
[0060]
步骤2.2.1、通过过滤式方法进行初步筛选,根据下式计算各个特 征的皮尔逊相关系数,并设置筛选阈值为0.2;
[0061][0062]
式中,n为样本数量,xi,yi为变量x,y对应的i点观测值,分别 为x,y样本的平均数,r即皮尔逊相关系数,其取值情况可以反映x,y 两个样本之间的关系。
[0063]
步骤2.2.2、将数据等距离离散化,对于每一个特征和标签的数据, 将连续数值分为10个相等的区间,根据下式计算各个区间中特征的 信息增益,提取信息增益前50的特征;
[0064][0065][0066]
其中gain(a)为信息增益,a代表属性,d代表原有数据集,dv代表 新增某一条件时,自变量取某一值时对应的样本数目,v即表示新增的 某一特征数据;ent(d)为数据的信息熵,m为特征数目,pi是标签在 某一取值时的频率;
[0067]
步骤2.2.3、将筛选得到的两个特征集合取并集进行下一步的筛选;
[0068]
步骤2.2.4、通过前向选择的包裹式方法,筛选出新增某一特征后 新的特征子集的信息熵低于之前信息熵3%的特征作为最优新增特征, 将最优新增特征增值添加到特征集合中,直至遍历所有的特征集合且 特征子集不再变化。
[0069]
步骤3、避免不同特征数值范围的不同给机器学习带来极大的误 判需要对数据进行归一化或标准化,考虑到后续工程中有新数据加入, 对所有数据根据下式进行z-score标准化处理;
[0070][0071]
其中x
*
为标准化后得到的数据,μ为对应某一特征的平均值,σ 为对应某一特征的标准差,标准化得到的数据值落于-1.5到1.5之间, 标准化后数据的均值和标准差均为1,便于新增数据。
[0072]
进一步的,将数据进行规范化,将数据的时间范围设定为每天的 08:00-19:00,时间间隔为15min,对于原始功率数据中在此区间之外 的删除,在此区间内开始或最后缺失的设为0,区间内缺失的利用线 形插值进行补充;
[0073]
然后根据光伏历史功率数据进行kmeans聚类划分,将一天的功 率数据序列作为一个样本数据,根据欧氏距离进行迭代计算。
[0074]
进一步的,由于天气因素复杂多变,只将数据集划分为两类,其 中一类的总体功率数值偏高且日功率数据偏向于正态分布,偏向于各 季节晴天天气特征,另一类的总体数
据功率数值偏低且数值突变情况 较多,偏向于阴雨天等极端的天气特征;
[0075]
步骤4、对步骤3得到的两类数据进行训练集、验证集和测试集 划分;由经过聚类后的光伏功率数据训练集构建lightgbm模型,得 到预测模型,并输出预测结果。
[0076]
选取均方根误差mse与平均绝对百分比误差mape进行预测 结果进行评估,其中由于将部分缺失数据设置为0,在计算mape时 设置选取阈值为3%的日最大功率值,计算如下式所示:
[0077][0078][0079]
式中,n表示预测的数据数目,wi分别代表第i个预测数据和 实际的发电数据。
[0080]
通过以上方式,本发明发光伏发电短期预测方法,对噪声数据、 异常数据、数据不一致问题进行处理后,通过数值分析和多项式方法 进行数据的特征工程构造,通过包裹式和过滤式方法结合进行特征选 择,然后由简单稳定的kmeans算法对数据进行聚类划分,得到两类 不同天气特征的数据子集,分别构建lightgbm预测模型进行预测; 相比于传统的预测模型更加注重天气数据的影响,对于lightgbm预 测模型相比简单的gbdt模型,运算速度更快;基于特征工程的 lightgbm预测模型有更强的非线性表述能力,增加了预测的准确性。
[0081]
实施例
[0082]
表1为未进行特征工程的多层感知机与lightgbm 的预测误差比较。
[0083]
表2为经特征工程后的多层感知机与lightgbm的 预测误差比较。
[0084]
表1不同模型的预测误差
[0085][0086]
表2不同模型的预测误差
[0087][0088]
表1是对未经过特征工程处理的数据集进行的预测分析,数据间隔 精度为15分钟,每日数据范围为08:00-19:00,训练集共11339条 数据,其中晴天特征的数据集包含7034条数据,阴雨天特征的数据集 包含4305条数据,验证集分别包含1803和1097条数据,测试集分 别包含961和600条数据通过与多层感知机模型在有无特征工程的条 件下比较,计算各模型的均方根误差mse与平均绝对百分比误差 mape,从表2中可以看出,lightgbm模型均方根误差在晴天特征数据 集下预测结果为0.847,低于多层感知机模型。通过对比有无特征工程, 两种算法模型的mse与mape均有所降低,可以看出经过特征工程的 气象参数聚类可以有效降低预测误差。表2是本实施例中采用特征工程 后不同预测模型的结果预测图,从表2可看出:在同样的特征条件下 lightgbm模型在波峰波谷处的预测效果优于多层感知机,证明了基于 集成思想的lightgbm预测模型的有效性。图2至图5是本实施例中未 采用和采用特征工程情况下两种预测模型的预测结果图,从图中可看出: 通过进一步的特征工程及数据挖掘方法后,各模型预测精度的大幅提升。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。