1.本发明属于远程医疗技术领域,尤其涉及一种自适化远程医疗专 家推荐方法。
背景技术:
2.远程医疗是解决医疗资源不均衡问题的战略途径,因其能够借助 互联网技术提供跨区域、跨机构的诊疗服务而得到了蓬勃发展。远程 医疗在使用过程中已收集、积累了大量代表患者健康状况的临床数 据,明显增加了可用于面向患者决策的数字信息,使得数据驱动个性 化医疗服务成为可能。但现有远程医疗服务并未充分利用和发挥其大 数据价值。
3.患者最关心的是如何找到最专业的医学专家来解决他们的健康 问题,但对患者来说,为自己挑选合适的专家极具挑战性,尤其是在 没有合适的匹配机制的情况下。面对信息体量的快速增长,由于患者 缺乏专业的医疗背景和知识,他们在寻找合适的专家时不知所措,面 临巨大的时间和搜索成本,使得问题不能得到及时有效地解决,甚至 造成医疗资源的浪费,降低诊疗效率。因而目前大多采用申请方医生 或调度人员人工推荐的方式为患者选择会诊专家。但随着会诊量的增 加,人工推荐的方式无法保证医疗服务的专业性和质量,加之医疗信 息的不对称性,易引起患者的不信任,进而影响医患关系和患者满意 度。
4.个性化推荐是解决信息过载和“知识迷向”问题的有效途径,能 够帮助患者和远程医疗调度人员过滤掉大量不相关的医生,从专业层 面快速准确地找到符合患者需求的远程医疗专家,降低患者搜索成 本,辅助医疗决策,确保医疗服务价值的有效实现,从而为患者和远 程医疗机构增益
5.尽管推荐系统已被尝试运用于医疗保健领域,然而已有研究也存 在一些不足:
①
大多患者与医生之间的交互数据较少,因为他们很少 生病;同时,出于隐私保护,患者不愿在在线平台上透漏过多个人信 息,数据稀疏性问题导致难以捕捉患者偏好,从而导致推荐效果不佳。
ꢀ②
单一地根据患者的择医偏好为其提供个性化推荐,忽略了患者对不 同推荐方式的选择偏好。
③
忽视了医生的兴趣度和活跃度及其随时间 的变化,导致匹配成本增加,从而影响整个系统性能。
④
存在冷启动 问题,新注册医生由于历史数据的不足缺乏展示机会,难以被发现。 同时,由于以下原因,远程医疗情境下的医生推荐仍具有挑战性:
①ꢀ
区别于传统推荐,极少患者会就不同种类的保健项目进行投票或评 分,这给协同过滤机制带来了困难;
②
健康相关数据较为敏感,在远 程医疗情境下,患者无法获得其他类似患者的信息,其决策行为不会 受到其他患者的影响,这给采用基于社交网络的推荐系统带来了困 难。
技术实现要素:
6.本发明的目的是提供一种自适化远程医疗专家推荐方法,解决了 基于患者病历、远程医疗专家长短期知识背景,通过构建具有反馈调 节的自适应推荐模型,来实现远程医
疗情境下的个性化专家推荐的技术问题。
7.为实现上述目的,本发明采用如下技术方案:一种自适化远程医疗专家推荐方法,包括如下步骤:
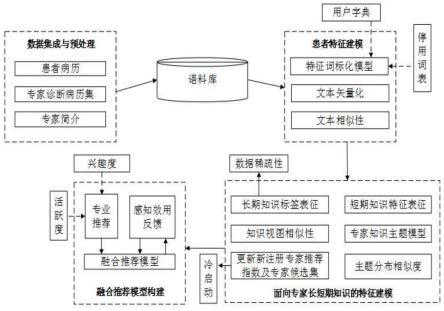
8.步骤1:数据集成与预处理模块首先从远程医疗平台数据库中积累的业务数据和在线医疗平台中的医生简介数据,并将收集到的数据集成为原始数据;业务数据中包含患者病历;
9.数据集成与预处理模块对原始数据进而预处理,利用自定义用户字典识别医疗领域专业词汇,利用停用词列表过滤掉无意义的词、数字和符号;生成语料数据并存入语料库中;
10.步骤2:患者特征建模模块从语料库中获取语料数据,利用词的上下文信息将语料数据中的高维语句转换成低维实数向量,提取出描述患者特征的关键词,形成患者特征模型;
11.对比患者特征模型,以专家诊断过的相似患者的最高相似值作为专家初始推荐指数,构建初始的推荐专家候选集;
12.步骤3:长短期知识特征建模模块分别对专家的长期知识特征和短期知识特征进行建模,生成专家长短期知识特征,具体包括如下步骤:
13.步骤s3-1:在对长期知识特征进行建模时,首先从专家简介中提取专家的长期知识特征,然后对长期知识领域进行知识视图相似性测算,更新新注册专家的初始推荐指数,并按照相似性排序更新推荐专家候选集;
14.步骤s3-2:在对短期知识特征进行建模时,选用lda(latentdirichletallocation)主题模型凝练专家诊断过的病历文本,从中识别代表疾病类别的隐藏主题,隐藏主题代表医生擅长的疾病特征,一个专家属于一个或多个隐藏主题,生成基于隐藏主题的专家短期知识特征描述框架,在语义层面扩展推荐专家候选集;
15.步骤4:在患者特征模型和专家长短期知识特征的基础上,融合专家活跃度和兴趣度,以及患者主客观感知效用构建带有反馈调节的可解释性专家推荐模型,使得推荐结果向积极性的专家倾斜。
16.优选的,在执行步骤2时,具体包括如下步骤:
17.步骤s2-1:加载同义词字典、特征词字典和停用词表,对患者病历进行规范化处理、中文分词、文本标注和特征词提取;
18.步骤s2-2:在引入特征词典和停用词表的基础上,利用文本分词技术将文本转换为由词语组成的特征词集,然后借助word2vec模型计算出文本中每个关键词的向量,并对不重复的词向量取平均值,进而合成句向量表示文本的最终向量;
19.步骤s2-3:采用词频-逆文档频率值作为特征词权重,刻画特征词的重要程度,得到矢量化文本;
20.步骤s2-4:利用计算余弦相似度的方法计算矢量化文本间的相似度;
21.步骤s2-5:以专家诊断过的相似患者的最高相似值作为专家初始推荐指数,完成患者特征到专家特征的映射,即通过目标患者特征与专家诊断的患者特征之间的相似性映射医-患背景的相似性,将相似患者的诊治专家组成初始推荐专家候选集。
22.优选的,在执行步骤s2-5时,采用以下两个步骤构建推荐专家候选集:
23.步骤s2-5-1:统计所有相似专家,将其相似患者的最高相似度作 为专家初始推荐指数,并按照专家初始推荐指数进行降序排序;
24.步骤s2-5-2:从排序结果中取前十名纳入候选集。
25.优选的,在执行步骤s3-2时,基于知识的属性特征采用jaccard 相似系数来计算知识视图中的知识之间的属性相似性。
26.优选的,在执行步骤s3-1时,具体包括如下步骤:
27.步骤s3-1-1:通过计算专家知识属性的视图相似性来表征专家长 期知识领域之间的相似度,构建专家知识属性矩阵;采用频次统计方 法对专家简介信息不完整的特征模型进行缺失值填充;
28.步骤s3-2-2:根据专家擅长疾病构建其知识结构,并通过计算专 家之间的知识视图相似性来预测专家的能力匹配。
29.优选的,在执行步骤s3-2时,具体包括如下步骤:
30.步骤s3-2-1:整合专家诊断过的患者病历文本作为专家短期知识 背景,进而形成lda主题模型训练语料库,从而对专家短期知识特 征模型进行构建和训练;
31.步骤s3-2-2:通过lda主题模型的主题聚类凝练出隐藏的主题以 及每个医生的“文档-主题”分布;
32.步骤s3-2-3:lda主题模型的主题聚类生成的“主题-词项”概率分 布用于完成对专家短期知识特征的表达;
33.在lda主题模型中文本采用服从dirichlet(dirichletdistribution)分 布的主题概率向量来衡量,若使用余弦夹角来计算文本相似度就失去 了主题模型的优势,kl散度作为一种衡量两个概率分布差异性的方 法,常被用来计算文档主题分布向量的相似度,但由于kl散度的不 对称性使其不能用作距离测量,作为kl散度的变形,具有对称性的 js散度被提出来弥补kl散度的不足;因此采用js散度的变形来衡 量概率分布的相似度;
34.步骤s3-2-3:基于“文档-主题”概率分布的相似性得到与推荐专家 候选集中具有相似知识特征的专家,并以此作为面向专家短期知识特 征的推荐指数,这些具有相似知识特征的专家也具有诊疗目标患者的 能力。
35.优选的,在执行步骤4时,具体包括如下步骤:
36.步骤s4-1:专家sj的最近活跃度acj计算如下公式所示:
[0037][0038]
其中,t表示专家会诊时间的合集,tc表示目标患者申请时间,t
l
表示该专家上次会诊时间,为了降低专家最近活跃度的跳跃性,将最 近活跃度acj作如式下公式的处理:
[0039][0040]
其中,ac
max
表示最活跃专家的活跃度;
[0041]
步骤s4-2:采用衰减函数对会诊专家sj的兴趣度ij进行动态建 模,其建模公式如下:
[0042][0043]
其中,nj(t)是专家sj在t阶段的会诊次数,n(t)是t阶段的总 会诊次数,e-t
为时刻t的指数函数;
[0044]
为消除权重系数融合时量纲的影响,进一步对兴趣度进行如下公 式的处理,得到专家的兴趣度,i
max
表示表现出最高兴趣的专家的兴 趣度:
[0045][0046]
在推荐指数的基础上融合专家活跃度和兴趣度进行推荐,推荐指 数包含了专家的初始推荐指数和面向专家短期知识特征的推荐指数, 使推荐结果分布向最近、最频繁的专家倾斜,具体表达形式如下公式 所示:
[0047]
prof_score=(γ1lac γ2ai)
×
ini_score
×
short_score;
[0048]
其中,γ1和γ2分别是活跃度和兴趣度的权重系数,且γ1 γ2=1, ini_score为专家的初始推荐指数,short_score为面向专家短期知识特 征的推荐指数;
[0049]
步骤s4-3:患者反馈划分为主观qos反馈和客观qos反馈:
[0050]
主观qos反馈指患者在得到推荐结果前对推荐指数偏好的反馈, 根据患者偏好调整融合推荐指数优化推荐排序,使推荐结果关注权重 更高的内容,形成可解释性推荐策略;
[0051]
在对推荐指数进行规范化处理后,将上述推荐指数进行线性融合, 具体表示为:
[0052]
compre_score=ω
p
prof_score
′
ωqqos_score;
[0053]
其中,prof_score'=prof_score/prof_score
max
,ω
p
和ωq分别 为患者对专业推荐策略和服务质量的偏好权重,满足ω
p
ωq=1;
[0054]
客观qos反馈是指患者在服务完成后的事后评价反馈,患者根据 服务过程中的感知质量对医疗服务进行评价,即患者感知效用值,体 现了患者对医疗服务和专家的满意度,是对专家客观qos值的反馈 调整,设定qos
1,j
,qos
2,j
,...,qos
m,j
是m位患者对专家sj的综合客 观qos评价值,患者pi在服务完成后作出qos
i,j
的反馈评价,通过 患者反馈进一步调整更新专家sj的客观qos值为:
[0055][0056]
其中,qos
u,j
表示第u位患者对专家sj的客观qos评价值;
[0057]
经标准化后转换为患者反馈感知效用指数,如下公式所示:
[0058][0059]
其中,qos
max
是所有专家的最高评价值;
[0060]
更新专家qos值,对推荐结果排序的做进一步反馈调整优化。
[0061]
本发明所述的一种自适化远程医疗专家推荐方法,在充分刻画患 者和专家知识背景的基础上,提出了专家推荐指数,并将专家活跃度 与兴趣度及患者效用反馈纳入同一推荐框架,构建了具有反馈调节的 自适应推荐模型,解决了远程医疗情境下的个性化专家推荐的技术问 题,在患者满意的同时使推荐更具时效性。结合专家长、短期知识特 征的全面刻画专家的知识领域信息,通过对专家长期知识特征的提 取,刻画新注册专家的特征知识背景,为缺乏历史诊断数据的新注册 专家增加被推荐机会,在一定程度上缓解冷启动问题;专家活跃度及 对远程医疗的兴趣会随时间发生变化,通过动态衡量专家在远程医疗 服务中的活跃度及兴趣度,使推荐结果分布向最频繁、最活跃的专家 倾斜,提升匹配成功率和推荐能力,进而提升服务效率和质量;为充 分考虑患者对不同推荐方式的偏好,构建了基于电子病历的专家自适 化推荐模型,通过患者偏好的反馈动态调节推荐结果,提高推荐结果 的自适性与可解释性;同时,本发明所提方法减少了大量额外信息的 提交,压缩数据空间,解决了数据稀疏性和隐私保护问题,该方法能 够指导远程医疗实践,完善远程医疗平台建设,促进远程医疗的可持 续发展。该方法同样适用于在线健康问答平台及评审专家推荐系统, 考虑专家的兴趣领域及其随时间的变化,能够为专家推荐相关的问题 或符合兴趣领域的评审稿件,提升推荐的合理性,保证工作效率和效 果。
附图说明
[0062]
图1是本发明的远程医疗专家推荐框架图;
[0063]
图2是本发明的lda概率模型图;
[0064]
图3是本发明的会诊数量分布情况图;
[0065]
图4是本发明的困惑度曲线图;
[0066]
图5是本发明的不同权重偏好下的融合推荐模型性能曲线图;
[0067]
图6是本发明的推荐结果准确率和召回率对比曲线图;
[0068]
图7是本发明的基准模型和融合模型在推荐结果的相关性的对 比图;
[0069]
图8是本发明的基准模型和融合模型在推荐结果的活跃度的对 比图;
[0070]
图9是本发明的基准模型和融合模型在推荐结果的兴趣度的对 比图;
[0071]
图10是本发明的基准模型和融合模型这两种推荐方法的适切度 评价对比图。
具体实施方式
[0072]
由图1-图10所示的一种自适化远程医疗专家推荐方法,包括如 下步骤:
[0073]
步骤1:数据集成与预处理模块首先收集远程医疗平台数据库中 积累的业务数据和在线医疗平台中的医生简介数据,并将收集到的数 据集成为原始数据;业务数据中包含患者病历;
[0074]
数据集成与预处理模块对原始数据进而预处理,利用自定义用户 字典识别医疗领域专业词汇,利用停用词列表过滤掉无意义的词、数 字和符号;生成语料数据并存入语料库中;
[0075]
本实施例中,数据来源于双渠道,即远程医疗平台数据库中积累 的业务数据和在线医疗平台中的医生简介,原始数据较为粗糙,在进 行文本挖掘前需对其进行预处理工作:
①
提取、整合、存储相关数据 信息,并对数据进行规范化、完整性检查,剔除异常数据、
基于填补规则补充缺失值,进而形成可靠语料。
②
创建自定义用户字典以使医疗领域专业词汇能够被正确识别。
③
创建停用词列表过滤掉对本实施例无意义的词、数字和符号,以便后文的数据分析,提高推荐准确率。
[0076]
步骤2:患者特征建模模块从语料库中获取语料数据,利用词的上下文信息将语料数据中的高维语句转换成低维实数向量,提取出描述患者特征的关键词,形成患者特征模型;
[0077]
对比患者特征模型,以专家诊断过的相似患者的最高相似值作为专家初始推荐指数,构建初始的推荐专家候选集;
[0078]
步骤s2-1:加载同义词字典、特征词字典和停用词表,对患者病历进行规范化处理、中文分词、文本标注和特征词提取;
[0079]
步骤s2-1是特征词标化过程,患者病历以专业化的术语组成了患者病症的特征描述,面对专业性强、表述方式因人而异的医学术语,本实施例加载同义词字典、特征词字典和停用词表进行患者病历进行规范化处理、中文分词、文本标注和特征词提取。这一策略可增强文本的表征力,使得专业术语能够被正确识别和划分,压缩特征空间维度,提高数据处理效率。
[0080]
步骤s2-2:在引入特征词典和停用词表的基础上,利用文本分词技术将文本转换为由词语组成的特征词集,然后借助word2vec模型计算出文本中每个关键词的向量,并对不重复的词向量取平均值,进而合成句向量表示文本的最终向量;
[0081]
步骤s2-2是文本矢量化表示过程,在引入特征词典和停用词表的基础上,利用文本分词技术将文本转换为由词语组成的特征词集,然后借助word2vec模型计算出文本中每个关键词的向量,并对不重复的词向量取平均,进而合成句向量表示文本的最终向量。如患者pi的病历di由f个特征词构成,其规范化表示为:
[0082]
p.feature_profile={wk|wk∈di,k=1,2,...,f},di表示患者pi的病历文本,wk表示第k个特征词,其对应的词向量为vk={v
k1
,v
k2
,...,v
kp
}。
[0083]
步骤s2-3:采用词频-逆文档频率值作为特征词权重,刻画特征词的重要程度,得到矢量化文本;
[0084]
步骤s2-3是特征词权重计算过程,词频(termfrequency,tf)是指给定单词在文本中出现的频率,而逆文档频率(inversedocumentfrequency,idf)是衡量单词重要性的指标。则中的关键词wk的tf-idf值表示为:
[0085]
tf-idf(wk,di)=tf(wk,di)
×
idf(wk)
[0086][0087][0088]
其中,n
k,i
表示特征词wk在病历文档di中出现的频次;m表示所有病历的数量;|{d:wk∈d}|表示包含特征词wk的病历数量。但是,若病历中不包含wk,除数将变为0使公式无意义,因此,|{d:wk∈d}|通常表示为1 |{d:wk∈d}|。tf-idf的值越大,该特征词在病历中的
重要程度越高,反之亦然。因此,本实施例采用tf-idf值作为特征词 权重,刻画特征词的重要程度。病历di的特征向量表示为:
[0089][0090]
步骤s2-4:利用计算余弦相似度的方法计算矢量化文本间的相似 度;
[0091]
步骤s2-4是文本相似性测度过程,本实施例中,矢量化的文本可 以利用余弦相似度计算文本间的相似度,即各文本与目标文本的相似 度sim(di,dj)。余弦相似度是一种最简单、有效的向量相似度计算 方法,其公式如下所示:
[0092][0093]
步骤s2-5:以专家诊断过的相似患者的最高相似值作为专家初始 推荐指数,完成患者特征到专家特征的映射,即通过目标患者特征与 专家诊断的患者特征之间的相似性映射医-患背景的相似性,将相似 患者的诊治专家组成初始推荐专家候选集。
[0094]
为推荐优质医生,需返回高相似度患者的会诊专家,但是由于远 程会诊患者并不是常见疾病或特征,因此,设置相似度阈值会限制推 荐结果,本实施例采用以下两个步骤构建推荐专家候选集:
[0095]
步骤s2-5-1:统计所有相似专家,将其相似患者的最高相似度作 为专家初始推荐指数,并按照专家初始推荐指数进行降序排序;
[0096]
步骤s2-5-2:从排序结果中取前十名纳入候选集。
[0097]
步骤3:短期知识特征体现了专家近期的关注与兴趣变化,长期 知识特征体现了专家持续性的特质,相对较稳定。二者结合能够更加 全面的刻画专家的领域知识信息,提高推荐的准确性和科学性。病历 库反映了专家在一定时间段内诊疗的疾病特征,而网页上公布的专家 简介表征了专家持续性积累的经验及长期关注的疾病领域,因此专家 的短期知识特征以病历库为基础,专家的长期知识特征从专家简介中 提取。
[0098]
基于患者病历文本相似性确定推荐专家候选集的推荐策略只能发 现诊断过与目标患者具有相似病情的专家,对于系统中新注册或诊断 数量较少的专家,由于业务量少、缺乏足够的业务数据支撑,以至于 被推荐机会不高。为解决新注册医生的冷启动问题,本实施例面向专 家医生的长期知识领域进行知识视图相似性测算,赋予新注册医生初 始推荐指数,进而增加他们的推荐机会,在一定程度上缓解冷启动问 题。
[0099]
长短期知识特征建模模块分别对专家的长期知识特征和短期知识 特征进行建模,生成专家长短期知识特征,具体包括如下步骤:
[0100]
步骤s3-1:在对长期知识特征进行建模时,首先从专家简介中提 取专家长期知识特征,然后对长期知识领域进行知识视图相似性测 算,更新新注册专家的初始推荐指数,按照相似性排序更新推荐专家 候选集;
[0101]
在执行步骤s3-1时,具体包括如下步骤:
[0102]
步骤s3-1-1:通过计算专家知识属性的视图相似性来表征专家长 期知识领域之间的相似度,构建专家知识属性矩阵;采用频次统计方 法对专家简介信息不完整的特征模型进行缺失值填充;
[0103]
本实施例针对知识的多样性,根据其所属领域、研究专长等赋予 其不同的属性,如:医生和疾病之间存在多对多的关系,即一个医生 可能擅长多种疾病,一种疾病也可被多个医生擅长,医生专长可以用 向量表示,且取值为{0,1},1表示医生擅长该疾病,0则表示不擅长 该疾病。因此,本实施例通过计算医生知识属性的视图相似性来表征 医生长期知识领域之间的相似度,为此构建如表1所示的专家知识属 性矩阵:
[0104][0105]
表1
[0106]
专家简介信息的不完整使得特征模型面临数据稀疏性问题。如果 取所有医生同时具有的属性作为填充值,则相似度偏低,为保持中立, 本实施例采取频次统计方法进行缺失值填充。具体是,假设a
jp
为缺 失值,即专家sj的第p个知识属性未知,若则令a
jp
=1,否则a
jp
=0。其中,|s|为专家总数,专家长期知识 特征规范化描述为d.feature_profile={a
jp
,j=1,2,...,n;p=1,2,...,g}。
[0107]
步骤s3-2-2:根据专家擅长疾病构建其知识结构,并通过计算专 家之间的知识视图相似性来预测专家的能力匹配;
[0108]
根据医生擅长疾病构建其知识结构,并通过计算医生之间的知识 视图相似性来预测医生的能力匹配。基于知识的属性特征,本实施例 采用jaccard系数来计算知识之间的属性相似性,其计算公式为
[0109][0110]
其中,a(j)和a(h)分别表示专家sj和sh的知识属性集, |a(j)∩a(h)|表示专家sj和sh同时拥有的知识个数, |a(j)∪a(h)|表示专家sj和sh共有的知识个数。
[0111]
此外,基于不同知识的贡献和重要程度的差异性,通过权重对不 同知识加以区分,得到加权的jaccard知识视图相似度:
[0112][0113]
其中,ω(a)是知识属性的权重。为充分利用属性信息,通过信息 熵的大小为属性确权,权重是从数据中学习的,避免了专家确权的主 观性过强,即
[0114]
ω(a)=-p(a)log2p(a)-(1-p(a))log2(1-p(a));
[0115][0116]
其中,p(a)为属性a出现的概率,n(a)为属性a出现的次数。
[0117]
为返回具有相似知识领域背景的专家,本实施例设置专家相似性阈值为0.7,若sim
knowledge
≥0.7,则返回该专家索引值。同时,更新新注册专家的初始推荐指数
[0118]
并按照相似性排序更新推荐专家候选集。其中,ini_scoreh为符合阈值要求的相似专家的初始推荐指数,q为新注册专家的相似专家数量。
[0119]
步骤s3-2:基于lda的专家短期知识特征模型仅通过寻找相似患者形成推荐专家候选集的推荐策略是片面的,系统中可能存在其他符合目标患者需求的专家。lda主题概率模型将专家知识特征映射至隐主题空间,在同一主题下寻找具有相似概率分布的专家,能够从语义层面有效识别出擅长诊治相似疾病的医生,大大降低寻找相似医生的规模和时间成本。因此,本实施例选用lda主题模型凝练专家诊断过的病历文本,从中识别代表疾病类别的隐藏主题,这些主题代表医生擅长的疾病特征,每个专家属于一个或多个隐藏主题,生成基于主题的专家短期知识特征描述框架,在语义层面扩展推荐专家候选集。
[0120]
lda模型是一种用于语料库建模的非监督产生式概率方法,是主题建模最常用的方法。lda根据文档和词汇的概率分布将高维文本-词汇矩阵分为两个低维的文档-主题矩阵和主题-词汇矩阵,从而得到文档的主题分布。一条文本的生成过程可以形式化表述如下:
①
从dirichlet(α)分布中抽取文档d下的多项式主题分布θd,即θd~dirichlet(α);
②
从dirichlet(β)分布中抽取主题t下的多项式词分布即
③
对于文档d中的词wk,从以θd为参数的多项式分布中抽取主题zn,即z
n-multi(θd),从以为参数的多项式分布中抽取文档d中的第k个单词,即其概率模型如图2所示。
[0121]
lda的建模过程可以描述为为每个资源寻找主题的混合,即文档中的每个词以特定概率选择某个主题,并从主题中以一定概率选择某个特征词来得到,该过程可形式化为以下公式。
[0122][0123]
其中,p(wk|di)是给定文档di中第k个特征词的概率;zn是潜在主题,其数量是预设的,p(wk|zn)是特征词wk出现在主题zn的概率;p(zn|di)是从文档di的主题zn中选择特征词的概率。
[0124]
在对短期知识特征进行建模时,选用lda(latentdirichletallocation)主题模型凝练专家诊断过的病历文本,从中识别代表疾病类别的隐藏主题,隐藏主题代表医生擅长的疾病特征,一个专家属于一个或多个隐藏主题,生成基于隐藏主题的专家短期知识特
征描述 框架,在语义层面扩展推荐专家候选集;
[0125]
在远程医疗情境中,一位专家可以诊疗多名患者,一名患者也可 以通过多次申请享受同一位或多位专家的服务。本发明侧重于由专家 诊断过的患者病历文本组成的专家短期知识,因此,医患对应关系类 型对本发明影响不大。鉴于此,本发明在隐私保护基础上,在隐主题 空间上构建面向短期知识特征的专家知识模型,其建模过程具体包括 如下步骤:
[0126]
步骤s3-2-1:整合专家诊断过的患者病历文本作为专家短期知识 背景,进而形成lda主题模型训练语料库,从而对专家短期知识特 征模型进行构建和训练;
[0127]
步骤s3-2-2:通过lda主题模型的主题聚类凝练出隐藏的主题 topic(t)={topic1,topic2,...,topick}以及每个医生的“文档-主题”分 布d.topic_profile={t1,t2,...,tk},k为经过lda主题聚类出的主题 数;
[0128]
步骤s3-2-3:lda主题聚类生成的“主题-词项”概率分布可完成 对专家短期知识特征的表达 d.feature_profile={<fi,ωi>,i=1,2,...,n},fi为主题下的特征 词,ωi为特征词的权重,n为特征词个数;
[0129]
步骤s3-2-3:基于“文档-主题”概率分布的相似性得到与推荐专家 候选集中具有相似知识特征的专家,并以此作为面向专家短期知识特 征的推荐指数short_score,这些相似专家也具有诊疗目标患者的能 力。
[0130]
在lda模型中,文本用服从dirichlet分布的主题概率向量来衡量, 若使用余弦夹角来计算文本相似度就失去了主题模型的优势。kl散 度作为一种衡量两个概率分布差异性的方法,常被用来计算文档主题 分布向量的相似度,则两个分布p和q的kl散度可表示为:
[0131][0132]
但由于kl散度的不对称性使其不能用作距离测量,即 d
kl
(p||q)≠d
kl
(q||p)。因此,作为kl散度的变形,具有对称性 的js散度被提出来弥补kl散度的不足。d
js
∈[0,1],d
js
的值越 小,表示两个分布越相似,当两个分布相同时,d
js
=0。两个分布 p和q的js散度可表示为:
[0133][0134]
两个分布越相似,d
js
的值越小,因此,为了方便进行相似度计 算,本实施例对js散度值进行转换,转换方式如下公式,其中ε为 调节因子,相似度取值范围为[0,1]。
[0135][0136]
步骤4:本实施例将上述推荐指数、专家活跃度和兴趣度及患者 效用反馈融合,形成带有反馈调节的远程医疗专家自适化推荐模型, 在考虑患者偏好的基础上为患者推荐相关且活跃的会诊专家。首先, 融合专家推荐指数与专家活跃度和兴趣度,构成基于患者病历的专业 推荐方法;然后,借鉴注意力机制,引入患者感知效用反馈,通过患 者主、客观
qos(quality of service)反馈实现可解释性推荐和推荐 结果的动态调整,进一步调整优化推荐结果。
[0137]
在患者特征模型和专家长短期知识特征的基础上,融合专家活跃 度和兴趣度,以及患者主客观感知效用构建带有反馈调节的可解释性 专家推荐模型,使得推荐结果向积极性的专家倾斜。
[0138]
在执行步骤4时,具体包括如下步骤:
[0139]
步骤s4-1:专家活跃度会随着时间的推移而发生变化。专家在远 程医疗平台中越活跃,其愿意开展远程医疗服务的可能性越大。因此, 在考虑相似性的基础上,还应考虑专家在平台中的活跃度,推荐列表 应向活跃度高、具有较大热情的专家进行倾斜。专家在最近一段时间 会诊病历越多,会诊间隔越小(以天为单位),表明专家在平台中越 活跃,专家sj的最近活跃度acj计算如下公式所示:
[0140][0141]
其中,t表示专家会诊时间的合集,tc表示目标患者申请时间, t
l
表示该专家上次会诊时间,为了降低专家最近活跃度的跳跃性,将最 近活跃度acj作如下公式的处理:
[0142][0143]
其中,ac
max
表示最活跃专家的活跃度;
[0144]
步骤s4-2:专家的会诊数量可以看作专家对远程医疗服务的显性 反馈,是专家兴趣行为的表现。随着会诊频次的增加,专家表现出对 远程医疗较高的偏好和兴趣,此类专家更加信任和愿意服务于远程医 疗患者,这使得我们可以根据专家的会诊频次来动态衡量专家对远程 医疗的兴趣。同时,用户兴趣会随着时间的演进发生变化。因此,考 虑到会诊的频率和时间,采用衰减函数对会诊专家sj的兴趣度ij进行 动态建模,其建模公式如下:
[0145][0146]
其中,nj(t)是专家sj在t阶段的会诊次数,n(t)是t阶段的 总会诊次数,e-t
为时刻t的指数函数;
[0147]
为消除权重系数融合时量纲的影响,进一步对兴趣度进行如下公 式的处理,得到专家的兴趣度,i
max
表示表现出最高兴趣的专家的兴 趣度:
[0148][0149]
在推荐指数的基础上融合专家活跃度和兴趣度进行推荐,推荐指 数包含了专家的初始推荐指数和面向专家短期知识特征的推荐指数, 使推荐结果分布向最近、最频繁的专家倾斜,具体表达形式如下公式 所示:
[0150]
prof_score=(γ1lac γ2ai)
×
ini_score
×
short_score;
[0151]
其中,γ1和γ2分别是活跃度和兴趣度的权重系数,且γ1 γ2=1, ini_score为
专家的初始推荐指数,short_score为面向专家短期知识特 征的推荐指数;
[0152]
步骤s4-3:融合推荐将专业推荐策略和患者反馈评价纳入同一框 架。用户反馈是需求与服务匹配推荐环节中闭环控制的重要环节。患 者反馈划分为主观qos反馈和客观qos反馈:
[0153]
主观qos反馈指患者在得到推荐结果前对推荐指数偏好的反馈, 根据患者偏好调整融合推荐指数优化推荐排序,使推荐结果关注权重 更高的内容,形成可解释性推荐策略;
[0154]
在对推荐指数进行规范化处理后,将上述推荐指数进行线性融合, 具体表示为:
[0155]
compre_score=ω
p
prof_score
′
ωqqos_score;
[0156]
其中,prof_score'=prof_score/prof_score
max
,ω
p
和 ωq分别为患者对专业推荐策略和服务质量的偏好权重,满足 ω
p
ωq=1;
[0157]
客观qos反馈是指患者在服务完成后的事后评价反馈,患者根据 服务过程中的感知质量对医疗服务进行评价,即患者感知效用值,体 现了患者对医疗服务和专家的满意度,是对专家客观qos值的反馈 调整,设定qos
1,j
,qos
2,j
,...,qos
m,j
是m位患者对专家sj的综合客 观qos评价值,患者pi在服务完成后作出qos
i,j
的反馈评价,通过 患者反馈进一步调整更新专家sj的客观qos值为:
[0158][0159]
其中,qos
u,j
表示第u位患者对专家sj的客观qos评价值;
[0160]
经标准化后转换为患者反馈感知效用指数,如下公式所示:
[0161][0162]
其中,qos
max
是所有专家的最高评价值;
[0163]
更新专家qos值,对推荐结果排序的做进一步反馈调整优化。
[0164]
以下为本实施例中的具体的实验与分析。
[0165]
样本选择与预处理
[0166]
本实施例的临床实验数据从国家远程医疗中心获得,其依托郑州 大学第一附属医院展开运营,专家简介信息从“好大夫在线”平台爬 取,作为补充数据以刻画专家长期知识背景。由于医疗机构的不同设 置会导致科室划分的差异,申请医生在申请会诊时对申请科室存在不 确定性和模糊性,且由于内科和外科是医疗领域两大科室,门类多样 且交叉、数据量大。因此,本实施例不考虑科室的具体分支,选取内 科和外科两个部门的业务数据作为实验数据进行分析。首先,根据郑 州大学第一附属医院官方网站公布的科室分布情况将具体科室划分 为内科医学部、外科医学部、综合医学部、妇产科医学部、老年医学 部等12大类。然后,根据研究目的,提取内科和外科医学部两个部 门下属医生的会诊数据。为充分保护患者隐私,本实施例尽可能压缩 数据空间,提取了包含会诊时间、诊断结果、专家名称和科室四类属 性的数据集,采集2021年全年数据共9078条,数据集的统计信息如 表2所示,每月会诊量分布情况如图3所示会诊数量分布情况。结合 表2数据统计,经审查证实了会诊专家与患者的多对多关系。
[0167]
数据集会诊专家患者会诊数内科13157146174外科12127962904
[0168]
表2
[0169]
之后,对采集数据进行预处理操作。首先,同义疾病名称应该用 医学领域的具体术语替换,如:“呼衰”替换为“呼吸衰竭”,“hbv”替 换为“乙肝”,保证数据的一致性,同时,采取2.3提到的频次统计方 法进行缺失值填充,保证数据的完整性;其次,使用python中的jieba 包进行中文分词,且在分词处理过程中使用搜狗输入法词库中的医学 词汇大全来构建用户词典以识别专业医学词汇,如“类风湿性关节 炎”、“系统性红斑狼疮”的正确识别;最后,在哈工大停用词表的基 础上根据实际情况加入对本发明无用的词汇进行停用词剔除,过滤掉 无实际意义且对本实施例分析无用的词、数字和符号等,以支持文本 向量化。
[0170]
实验设计及评价标准
[0171]
实验设计:通过设计多个对比实验来评估本实施例所提方法的性 能,这些对比实验主要围绕两个方面展开:
①
实验验证,主题数量k 显著影响lda主题模型的聚类效果,统计不同主题数量下的模型困 惑度,确定最优主题个数,使lda模型建模性能达到最优。
②
对比 分析,将本实施例所提的融合策略与传统的基于内容的推荐策略进行 性能对比分析,计算患者不同主观qos反馈和不同推荐项目数量下 推荐结果的准确率(pre@n)、召回率(rec@n)、相似度(relevance)、 活跃度(activity)和兴趣度(interest)。
[0172]
评价标准:本实施例采用top-n推荐系统中广泛使用的准确率、 召回率作为推荐策略性能的评价指标,并通过推荐结果相关性、兴趣 度和活跃度的对比分析,检验模型性能。准确率表示正确推荐项目占 所有推荐项目的比率;召回率表示正确推荐项目占样本中应检索到项 目的比率,这两个评价指标的计算方法如下所示。
[0173][0174][0175]
其中,tp表示正确判别项目,fp表示错误判别项目,fn表示 假阴性,即错误项目被推荐。准确率和召回率越高,模型的推荐性能 越好。
[0176]
相关性是指推荐专家诊断的患者与目标患者间的相似性,相似程 度越高表明专家越适合为目标患者提供远程医疗服务;活跃度是指专 家在远程医疗活动中的活跃程度;兴趣度是指专家对远程医疗活动所 表现出的行为兴趣。
[0177]
实验及结果分析
[0178]
主题模型参数选择:为获取较优模型,实验需先确定模型参数。 对于主题模型,主题个数的取值对建模的质量和主题的生成十分关 键。若直接根据经验给定主题数量,可能导致lda模型的性能不能 达到最优,大大影响推荐效果,因而需采取科学的手段选择主题数量。 本实施例采用困惑度选择主题个数,根据肘部法则选取主题数量,实 验结果如图4所示,横坐标表示主题个数,纵坐标表示lda模型的 困惑度,可以看出,当k=14时,lda模型
的困惑度最低。因此,在 接下来的实验中设置主题个数为14,迭代次数为500,每个主题下展 示前10个高频词。
[0179]
对比实验:本实验选取2021年12月31日的数据集作为测试数据 对算法进行测试,并通过不同情境下的对比实验来评估融合推荐模型 的性能。若专家简介中包含目标患者疾病标签则视为正确推荐。
[0180]
(1)权重系数对融合推荐策略的有效性检验
[0181]
推荐热度是根据患者投票、医生回复率、口碑和患者满意度等多 指标按照一定规则融合计算的结果,能够综合反映医生的服务质量。 因此,本实施例提取好大夫在线的医生综合推荐热度作为各专家的初 始服务质量评价值。不同偏好权重ωq下融合推荐模型的推荐性能结 果如图5所示,其中,n=10表示专家推荐返回结果的个数,pre@10 表示推荐准确率,rec@10表示召回率,横坐标表示ωq的不同取 值,纵坐标代表百分比。
[0182]
从图5可以看出,融合方法的推荐准确率和召回率在ωq≤0.4时 保持较高水平;之后,随着权重系数ωq的不断增大,推荐结果的准 确率和召回率呈整体下降趋势,其中ωq增加意味着患者对服务质量 更为重视,削弱了医、患现实背景对推荐结果的影响,进而影响了推 荐模型整体性能,因此,在进行专家推荐时不应过分强调患者感知效 应。
[0183]
(2)推荐结果个数对推荐模型的有效性检验
[0184]
专家推荐根据患者病历文本的相似性来实施专家推荐,这是典型 的基于内容的推荐方法。因此,为检验融合推荐模型的性能,本实施 例采用基于内容的推荐方法作为基准方法。本实验分别对基准方法和 本实施例所提的融合推荐方法进行建模,通过分析不同推荐结果个数 下两种推荐方法的准确率、召回率、相关性、活跃度和兴趣度来评估 模型性能。经过上节实验验证,当ωq=0.4时,达到最佳实验效果, 因而,本实施例在模型对比分析过程中设定ω
p
=0.6,ωq=0.4。 模型在准确率和召回率上的对比实验结果如图6所示,其中,横坐标 表示专家推荐返回结果的个数,即top-n中n的取值,主纵坐标表 示准确率,次纵坐标表示召回率。
[0185]
根据准确率的定义,一般情况下,对于同一算法,n取值越大, 其推荐结果的准确率越低,即准确率随着n值的增加呈下降趋势。 图6显示pre_融合>pre_基准,表明融合方法在会诊专家推荐中表现 出较高的准确性,能够准确为患者推荐合适的会诊专家,提高了推荐 结果的准确率。同样地,融合推荐方法在召回率上也表现出较高的性 能。综上,本实施例所提的融合方法提高了专家推荐结果的准确率和 召回率。
[0186]
图7显示了基准模型和融合模型在推荐结果的相关性、活跃度和 兴趣度上的对比,横坐标表示推荐返回结果的个数,纵坐标反映推荐 结果的相关性、活跃度和兴趣度。图7、图8、图9显示融合推荐方 法的推荐结果在专家的相关性、活跃度和兴趣度上均优于基准模型, 表明融合推荐模型能够在保证推荐准确性的基础上,为患者推荐相关 且活跃的专家,进一步证实了本实施例所提方法的有效性。
[0187]
(3)适切度分析
[0188]
为进一步检验融合推荐模型的性能,本实施例分别采用基准模型 和融合模型对一随机案例进行专家推荐,产生两组推荐结果。之后, 根据推荐结果制作问卷进行实地调查以评估推荐结果与目标患者的 适切度。问卷内容包括目标患者病历描述及两组推荐结果的合理性评 估,并采用likert五级量表进行评分,1~5分别表示非常不合理~非 常合
理。将调查问卷发放给国家远程医疗中心4位长期从事远程医疗 调度工作的医疗人员,其结合实际并根据自身工作经验对两种推荐结 果进行适切度评分,评分结果如图10所示。
[0189]
如图10所示,在适切度评价上融合推荐方法优于基准方法,足以 证明融合推荐方法的推荐医生列表比基准方法的推荐列表更合理,更 能满足患者的疾病及其就诊需求。
[0190]
总的来说,融合推荐方法能够为患者推荐相关且在远程医疗服务 过程中具有较高积极性的专家,也就是说,本实施例所提方法能够在 考虑患者个性化偏好的基础上确保推荐结果的准确性和相关性,同时 也保证推荐的专家对远程医疗具有较高的兴趣度和活跃度,进而提高 远程医疗效率和服务质量,促进远程医疗的可持续发展
[0191]
本发明所述的一种自适化远程医疗专家推荐方法,在充分刻画患 者和专家知识背景的基础上,提出了专家推荐指数,并将专家活跃度 与兴趣度及患者效用反馈纳入同一推荐框架,构建了具有反馈调节的 自适应推荐模型,解决了远程医疗情境下的个性化专家推荐的技术问 题,在患者满意的同时使推荐更具时效性。结合专家长、短期知识特 征的全面刻画专家的知识领域信息,通过对专家长期知识特征的提 取,刻画新注册专家的特征知识背景,为缺乏历史诊断数据的新注册 专家增加被推荐机会,在一定程度上缓解冷启动问题;专家活跃度及 对远程医疗的兴趣会随时间发生变化,通过动态衡量专家在远程医疗 服务中的活跃度及兴趣度,使推荐结果分布向最频繁、最活跃的专家 倾斜,提升匹配成功率和推荐能力,进而提升服务效率和质量;为充 分考虑患者对不同推荐方式的偏好,构建了带有反馈调节的专家自适 化推荐模型,通过患者偏好的反馈动态调节推荐结果,提高推荐结果 的自适性与可解释性;同时,本发明所提方法减少了大量额外信息的 提交,压缩数据空间,解决了数据稀疏性和隐私保护问题,该方法能 够指导远程医疗实践,完善远程医疗平台建设,促进远程医疗的可持 续发展。该方法同样适用于在线健康问答平台及评审专家推荐系统, 考虑专家的兴趣领域及其随时间的变化,能够为专家推荐相关的问题 或符合兴趣领域的评审稿件,提升推荐的合理性,保证工作效率和效 果。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。