关联散列树
1.相关申请的交叉引用
2.本技术要求享受于2021年4月20日递交的美国临时专利申请63/176,901,以及于2022年1月31日递交的美国临时专利申请63/304,726的优先权,以引用方式将上述两个申请并入本文。
技术领域
3.概括地说,本发明涉及数据验证,并且具体地说,本发明涉及散列树。
背景技术:
4.散列函数将可变长度的数据输入转换为固定长度的数据输出。输入字符串通常被称为消息,并使用一种算法进行转换,该算法将输入数据确定性地映射到被称为散列值、散列、摘要(digest)或状态的输出。
5.散列算法具有5个关键特征:
6.(a)它是确定性的,这意味着相同的输入消息总是产生相同的输出散列。
7.(b)计算散列值的速度很快。
8.(c)这是一个单向过程,使得从散列值生成输入消息是不可行的。
9.(d)它是抗冲突的,这意味着两条不同的消息很可能不会产生相同的散列值。
10.(e)对数据块的微小变化将会造成对散列值的很大变化,这就是所谓的雪崩效应。
11.万一两个不同的输入映射到相同的散列输出或“发生冲突”,有一些应用方法可以解决冲突,例如就像在散列查找表中一样。
12.加密散列函数的示例是sha-2系列,已知它是安全且抗冲突的。sha-2的常用的具体示例是sha-256,其输出长度为256比特或32字节的散列值。
13.散列用于许多应用:在数据存储和取回中,散列用作散列数据表或存储器位置中数据块的索引;在加密中,如上所述;并且在数据验证中,散列用作用于验证数据块的内容的指纹。通过从数据块中复制散列指纹,对数据的任何更改都会产生对散列值的更改。当需要建立数据块的完整性时,可以在本地计算散列值并相对于与数据一起远程存储的散列值对该散列值进行测试。
14.散列树同时针对多个数据块执行数据验证。单个数据块散列被表示为树上的叶子,这些叶子经由一系列节点和分支连接到根。通过执行从叶子到根的迭代计算,可以计算出被称为“根散列”的单个散列值。根散列就像树中所有数据块作为一个组的单个指纹。
15.散列树结构和计算
16.散列树的一种众所周知且常用的实施方式是merkle树,如图1所示,现在参考merkle树。merkle树10是二叉散列树。它的顶部有根11,底部有叶子12,而根11和叶子12之间有分支节点13。每个叶子12具有叶子编号la和散列值ha,其中a是叶子编号。叶子值表示数据块14的散列。例如,对标记为db1的数据块1进行散列,并将散列值h1分配给叶子l1。散列树中叶子的位置本身是确定性的,但将不对其进行进一步讨论。在该示例中,从底部层级
1到顶部层级4(从叶子12到根11)执行计算。在树10中有:4个层级-层级1到层级4;8片叶子,编号为l1至l8;并且有8个输出散列状态h1到h8,它们被映射到位于层级1的叶子l1到l8。
17.根据公式1计算散列状态h1到h8。
18.ha=h(dba)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
19.其中h表示散列函数,而a=1到8。dba表示数据块a中的数据;而ha表示与叶la相关联的dba的散列值。所有计算都存储在存储器中。
20.与叶子12类似,节点13具有节点编号节点b,以及相关联的散列值hb。hb表示对子叶子或子节点执行的计算。例如,h3a(节点3a的散列值)被计算为h2a(节点2a的散列值)的散列和h2b(节点2b的散列值)的散列。在下文中对该计算进行解释。
21.需要注意的是,merkle树采用分叉节点结构,其中每个节点最多只能划分为2个子节点。因此,随着更多的叶子被添加到merkle树中,可能需要添加更多的节点和层级。散列树的其他实现以及merkle树的改编可以具有不同的特性。
22.例如,第1层的每一对叶子都连接到层级2的节点。分别针对每个节点2a、2b、2c和2d将所有层级2节点的散列值h2a、h2b、h2c和h2d计算为每个节点的级联叶子散列的散列,如公式2所示。
23.hp=h(hq||hr)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
24.其中p是叶子节点编号;q和r是连接到节点p的叶子的叶子编号;hq是与叶子q相关联的数据块q的散列,而hr是与叶子r相关联的数据块r的散列。
25.公式2可用于计算具有子叶子节点的任何节点:使用散列h1和h2来计算h2a;使用散列h3和h4来计算h2b;等等。从存储器中取回所有散列h1到h8,并且任何新的计算都存储在存储器中。
26.对于散列树10,层级2节点对连接到层级3节点,而3层级节点对连接到层级4的根11。根11的散列值rh被称为根散列。针对所有层级3节点,节点3a和节点3b,将散列值计算为级联的从存储器中调用的2层级节点散列的散列。根散列值rh计算为级联的也是从存储器中调用的3层级节点散列的散列,如公式3所示。
27.hs=h(hp1||hp2)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
28.其中,s为节点编号;p1和p2是连接到节点s的子节点的节点编号;而hp1和hp2分别是预先计算并存储在存储器中的p1和p2的散列值。
29.公式3可用于计算任何具有子节点的节点:使用散列h2a和h2b计算h3a;使用散列h2c和h2d计算h3b,而使用散列h3a和h3b计算hr。从存储器中取回散列h2a、h2b、h2c、h2d、h3a和h3b。在上文的示例中,merkle数10是“密集的”,这意味着所有叶子散列值都存在于层级1。表示来自散列函数的所有可能输出散列的叶子l1到l8都存在,如图1所示。需要注意的是,叶子在merkle树中的位置是确定性的,这意味着相同的输出散列被分配给相同的叶子。
30.稀疏散列树
31.有时,只有一些输出散列值作为叶子存在,从而导致“稀疏”树。现在参考图2,图2表示稀疏merkle树20,其仅具有可能存在的8个叶子中的4个-l1、l2、l6和l7。与密集merkle树10类似,从底部层级1到顶部层级4计算稀疏merkle树20的根节点11。
32.然而,在稀疏merkle树中,计算根散列rh所需的缺失叶子和缺失节点被散列h0代替,散列h0是全零数据块的散列值。现在参考图3,图3示出了稀疏merkle树20,其具有所需
的替代叶子l5和l8,并且为了rh计算的目的而添加了所需的替代节点2b。为了清楚起见,添加的叶子和节点被添加了阴影。如上文所述执行计算。
33.如上所述,merkle树和散列树通常可以用于验证发送的数据块。这是通过共享部分或全部散列树以便可以在本地重新计算树或树的一部分以验证散列值来实现的。有关验证过程的更多信息,请参阅美国纽约市布鲁克林区的polytechnic university的dhungel等人的文章“the pollution attack in p2p live video streaming:measurement results and defenses”。
34.散列树更新
35.如前所述,merkle树的确定性本质意味着:如果某个数据块被删除,则表示被删除散列值的叶子也会从树中被删除。同样,如果添加了新数据块,则表示新数据块散列值的新叶子将被添加到树中。现在参考图4,图4示出了其中数据块db6已被删除并且数据块db3已被添加的稀疏merkle树30。
36.由于示例中的树30是稀疏树,因此需要添加和删除替代叶子和节点,以便重新计算根散列rh。从删除的叶子(l6)到根11(如箭头17所示)或从添加的叶子(l3’)到根1(如箭头18所示)的路径上的任何节点都需要重新计算。但是,不在这些路径上的任何节点都不需要重新计算,并且可以从存储器中调用它们的值。
37.重新计算按以下6个步骤执行。
38.步骤1-通过对db3’进行散列来计算h3’,如公式1所示。
39.步骤2-(因为h2b’现在具有叶子,之前的散列值h0不再有效)通过对h3'(新添加的叶子l3’的散列)和h0(新需要的替代叶子l4'的散列值)的级联进行散列来计算h2b’,如公式2所示。
40.步骤3-通过对h2a和h2b’(来自步骤2)的级联进行散列来计算h3a'(因为它不在从改变的叶子到根的路径上,不需要被重新计算,并且可以从存储器中取回),如公式3所示。
41.步骤4-用h0替换h2c’(因为h2c'现在没有叶子-因为l6已被删除,并且不再需要用散列值h0来替换叶子l5)。
42.步骤5-通过对h0(来自步骤4)和h2d(来自存储器,因为不在改变的路径上)的级联进行散列来计算h3b’,如公式3所示。
43.步骤6-通过对h3a’(来自步骤3)和h3b’(来自步骤5)的级联进行散列来计算rh’,如公式3所示。
44.可以看出,单个数据块的变化导致在树30的多个层级上进行多次重新计算以计算rh’。
技术实现要素:
45.因此,根据本发明的优选实施例,提供了一种根据多个叶子散列值动态计算根散列值的系统。所述系统包括平面关联存储器和散列解析器。所述平面关联存储器存储所述多个叶子散列值,并且所述散列解析器从所述多个叶子散列值中提取经压缩数量的分支节点,根据所述多个叶子散列值确定分支节点关系,以及保存所述经压缩数量的分支节点和所述分支节点关系。
46.此外,根据本发明的优选实施例,所述多个叶子散列值存储在所述平面关联存储
器的列中。
47.此外,根据本发明的优选实施例,所述散列解析器提取所述经压缩数量的分支节点,并且根据顶部根节点向下到叶子集合确定所述分支节点关系。
48.此外,根据本发明的优选实施例,所述散列解析器从所述多个叶子散列值的最高有效字节到最低有效字节来解析所述多个叶子散列值。
49.此外,根据本发明的优选实施例,所述散列解析器在所述多个叶子散列值之间找到公共前缀。
50.此外,根据本发明的优选实施例,所述系统包括节点计算器,其根据所述分支节点关系来计算分支节点散列值和所述根散列值。
51.此外,根据本发明的优选实施例,所述系统包括至少一个平面节点表,其保存所述经压缩数量的分支节点以及所述分支节点关系。
52.此外,根据本发明的优选实施例,所述至少一个平面节点表记录所述分支节点散列值和所述根散列值。
53.此外,根据本发明的优选实施例,所述节点计算器使用至少一个新计算的分支节点散列值和存储在所述至少一个平面节点表中的所述分支节点散列值来重新计算新的根散列值。
54.此外,根据本发明的优选实施例,所述散列解析器在关联处理单元中实现。
55.此外,根据本发明的优选实施例,所述至少一个平面节点表在cpu存储器中实现。
56.此外,根据本发明的优选实施例,所述节点计算器在cpu上实现。
57.因此,根据本发明的优选实施例,提供了一种根据多个叶子散列值动态计算根散列值的方法。所述方法包括:将所述多个叶子散列值存储在平面关联存储器中;从所述多个叶子散列值中提取经压缩数量的分支节点;根据所述多个叶子散列值确定分支节点关系;以及保存所述经压缩数量的分支节点,以及所述分支节点关系。
58.此外,根据本发明的优选实施例,所述存储包括:将所述多个叶子散列值存储在所述平面关联存储器的列中。
59.此外,根据本发明的优选实施例,所述提取和所述确定是从顶部根节点向下到叶子集合来执行的。
60.此外,根据本发明的优选实施例,所述提取是从所述多个叶子散列值的最高有效字节到最低有效字节来执行的。
61.此外,根据本发明的优选实施例,所述提取在所述多个叶子散列值之间找到公共前缀。
62.此外,根据本发明的优选实施例,所述方法包括:根据所述分支节点关系来计算分支节点散列值和所述根散列值。
63.此外,根据本发明的优选实施例,所述保存包括:保存到至少一个平面节点表。
64.此外,根据本发明的优选实施例,所述方法包括:将所述分支节点散列值和所述根散列值记录到所述至少一个平面节点表中。
65.此外,根据本发明的优选实施例,所述方法包括:使用至少一个新计算的分支节点散列值和存储在所述至少一个平面节点表中的所述分支节点散列值来重新计算新的根散列值。
附图说明
66.被认为是本发明的主题在说明书的结尾部分被特别指出并明确要求保护。然而,本发明关于组织和操作方法,连同其目的、特征和优点,在阅读附图时可以通过参考以下具体实施方式得到最好的理解,其中:
67.图1是密集merkle树的图示;
68.图2是稀疏merkle树的图示;
69.图3是图2的稀疏merkle树的根散列计算的图示;
70.图4是稀疏merkle树的根散列的重新计算的图示;
71.图5a是根据本发明的优选实施例构造和操作的关联散列树系统的图示;
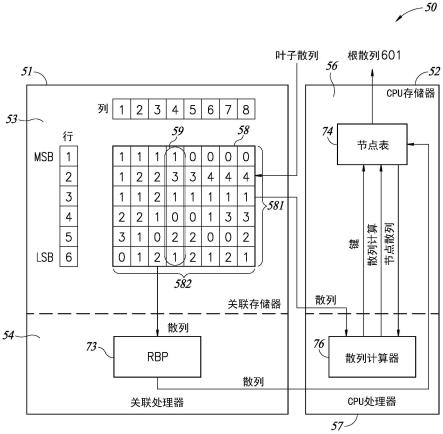
72.图5b是从图5a中的散列值导出的稀疏关联散列树的图示;
73.图6是示例性关联散列树系统的图示;
74.图7是从图5a中的散列值导出的节点表7a至7f的表格说明;
75.图8是根据本发明的优选实施例构造和操作的经更新的散列值存储的图示;
76.图9是从图8中的散列值导出的稀疏关联散列树的图示;以及
77.图10是使用从图8中的散列值导出的数据更新的节点表的表格图示。
78.应当意识到,为了说明的简单和清晰,图中所示的元素不必按比例绘制。例如,为了清楚起见,一些元素的尺寸可能相对于其他元素被夸大了。此外,在认为适当的情况下,附图标记可以在附图中重复以指示相对应或类似的元素。
具体实施方式
79.在下文的具体实施方式中,阐述了大量具体细节以便提供对本发明的透彻理解。然而,本领域的技术人员将理解是:可以在不使用这些具体细节的情况下来实施本发明。在其他实例中,没有对公知的方法、过程和组件进行详细描述,以防止模糊本发明。
80.关联散列树
81.申请人已经意识到散列树结构(即节点和叶子的分层布置)不需要被存储和从存储器调用,并且可以在运行中动态地构建。
82.申请人已经意识到这样的散列树可以数据为中心的方式从一组数据散列动态地构建。
83.申请人还意识到,可以通过在逐个字节地同时解析叶子散列值,在运行中从最高有效字节(msb)到最低有效字节(lsb)动态地构建散列树,以产生将根节点连接到叶子节点的分支节点。
84.存储叶子散列
85.现在参考图5a,图5a示出了包括关联处理单元(apu)51和cpu 52的示例性关联散列树系统50。apu 51还包括关联存储器53和关联处理器54。apu 51可以是任何合适的关联处理单元,例如从美国gsi technology inc.商购的gemini apu。cpu 52包括cpu存储器56和cpu处理器57。cpu 52可以在任何传统的计算机存储器和处理器上实现。关联存储器53包括散列值存储58,其可以是具有行581和列582的存储器阵列,并且根据本发明的优选实施例,可以将散列值59存储在列582中。在示例性图5a中,散列值存储58被示为将八个6字节散列值5 9存储在列582中。散列59的六个字节中的每个字节都存储在单独的行581中,每个散
列的msb可以位于列的顶部(在第1行),而lsb可能位于列的底部(在第6行)。下面将进一步解释关联处理器54、cpu存储器56和cpu处理器57。
86.上述分支节点或节点可以具有“节点编号”,也被称为“键”。此外,每个节点也具有值,它是与键相关联的散列值。节点编号的示例可以是0、02、041、0413、03102。在叶子节点中,节点编号可以与散列值相同(散列值与键相同),例如011230。
87.解析叶子散列
88.申请人已经意识到,在运行时从一组叶子散列从头确定动态散列树的结构的方法可以使用递归的、深度优先的、回溯解析和压缩(rdbpc)算法,这将在下文中解释。
89.申请人还意识到上述构建动态散列树的方法在解析期间动态地压缩树。在上文提到的merkle树中,每个叶子的深度是固定的,并且与(log(散列长度))成正比。在关联散列树中,由于动态散列树中使用的压缩方法,可以使每个叶子的深度更短。
90.rdbpc算法可以首先从第1行向下开始同时解析所有列,以识别来自根节点的分支节点和叶子节点结构。这些子树和节点可以通过同时在8个叶子散列中找到最长的公共前缀来识别。参考图5b,图5b示出了通过对图5a中所示的散列值存储58中的8个叶子散列59进行解析而创建的动态散列树60的最终表示。
91.如上所述,解析跨所有列同时进行,并从根节点开始并且向下进入第1行。第1行包含字节值0和1,因此在第1行的8个叶子散列中没有单个最长的公共前缀或值。这2个值指示:根节点分支到另外两个分支-分支1和分支0。可能需要对这两个分支进行进一步解析。
92.接下来,将分支1向下解析为第2行(我们可以从分支0开始,这没有区别),揭示了第2行中的字节值1、2和3-这指示:分支1本身在第2行中分支为三个分支。此类分支的存在指示第1行包含节点编号为1的节点。由于这是根节点之后的第一个节点,因此可以将其描述为深度为1的分支节点,如图5b所示。
93.当从一行到下一行向下对多于一个分支进行解析时,如果没有遇到另一个分支,那么这些分支共享公共前缀。该公共前缀指示这些分支可以被压缩成单个分支。当遇到下一个分支时,该压缩分支可以变成压缩节点。将在下文对其进行进一步解释。
94.解析沿上述3个分支继续向下进行。这些分支是:分支11(发音为“branch one one”),如图5a的第1列所示,从第1行到第2行;分支12,如图5a的第2列和第3列所示,从第1行到第2行;分支13,如图5a的第4列所示,从第1行到第2行。
95.分支11在第1列中只有到第6行的未分割路径,而分支13在第4列中只有到第6行的未分割路径。这指示分支11和分支13分别包含节点编号为111230和131021的叶子节点,它们可以是节点1的子节点。
96.分支12在第2列和第3列中具有两条路径,第2列和第3列在第1行和第2行中共享相同的前缀。这指示第2列和第3列在第1行和第2行之间被压缩。由于该压缩分支本身在第3行中分支为分支121和122,这指示存在压缩节点12,如图5b所示。
97.向下解析分支121(第2列)和分支122(第3列),揭示了到第6行的未分割路径,这指示节点12的两个子节点二者都是叶子节点,它们的节点编号为121211和122102。在解析了分支1之后,可以以类似的方式来解析下一个分支0。生成的动态散列树60可以具有:根节点rha;5个分支节点:节点1、节点0、节点12、节点041和节点0413;以及8个叶子:节点111230、节点121211、节点122102、节点131021、节点031022、节点041101、节点041302和节点
041321,即表58中的8个散列值。
98.申请人已经意识到叶子散列值解析在关联处理单元(apu)中的关联存储器阵列上实现简单,并且可以在相对较少的存储器周期内执行。正如rdbpc算法可以从第1行向下开始同时解析所有列,在8个叶子散列中搜索公共前缀,然后向下移动子树,应当意识到,对于数百或数千个叶子散列值,该过程是相同的。关联处理单元可以对存储在关联存储器阵列列中的大量(32k、64k 128k
……
)叶子散列值并行操作,而不影响处理时间。增加散列中的字节数量当然会增加解析时间,但是apu的大规模并行处理能力使得允许:可以与叶子散列的数量无关的根散列值的计算性能。将进一步意识到,下文讨论的运行中压缩可能仅改善处理时间。
99.相比之下,merkle树需要额外的强制节点计算,其中叶子散列增加,因为需要更多的强制分支节点和树层级。
100.在关联存储器上实现的叶子散列值解析和大规模并行处理一起可以提供处理时间的数量级改进和计算复杂性的显著降低。
101.关联散列树压缩
102.简单的增量解析可以产生未经压缩的树(例如图2中的merkle树20),其中节点表示解析过程中n的每个增量。申请人已经意识到rdbpc算法可以产生压缩树(例如图5b中的关联散列树60)。这是因为在最长公共前缀中没有遇到分支的每个增量解析都可以表示将顺序节点压缩为压缩节点。这种压缩可以通过图5b中的关联散列树60中的节点12、节点041和节点0413来反映。应当意识到,这种动态压缩可以由关联处理器54非常高效地执行。
103.如上所述,找到最长的公共叶子散列前缀是解析和压缩算法的主要步骤。步骤1-选择列条目的集合,它们可以具有长度为n的公共前缀。步骤2-检查来自步骤1中的集合中的所有条目是否在位置(n 1)处具有相同的散列值。如果不是,则存在分支。步骤3a-如果不存在分支,则来自步骤1的集合条目具有长度为n 1的公共前缀。然后增加n并返回步骤2。步骤3b-如果存在分支,则长度为n的前缀可以表示分支节点键。步骤4-在存储器中记录分支节点键或根散列。应当意识到,关联处理器54可以非常高效地执行对分支的检查。
104.如上所述,解析可以产生自上而下的关联散列树结构,但是根散列的计算需要从底部层级的叶子散列到根的节点散列的计算。
105.申请人已经意识到,通过压缩不分支的节点,与需要在每个节点处计算的merkle树之类的散列树的实施方式相比,可以减少计算rh所需的计算次数。
106.关联散列树系统
107.申请人已经意识到:可以将动态的、从下到上的根散列计算集成到上述rdbpc算法中。
108.参考图6,图6示出了关联散列树系统50。在优选实施例中,cpu处理器57还包括散列计算器76。关联处理器54还包括递归回溯解析器(rbp)73。cpu存储器56还包括节点表74。
109.如上文所解释的,分支节点的子节点可以被散列在一起以产生节点值。当节点具有兄弟节点时,需要在兄弟节点之间进行计算以计算父节点值。在图5b的示例性关联散列树60中,节点最多可以具有256个子节点。为了计算动态散列树60的节点根(根是根节点的节点编号或键)的根散列rha,可以采取以下步骤并将结果写入节点表74。
110.节点表
111.现在参考图7,图7示出了包括表7a到表7d的节点表74。应该注意,分支散列表74中的表的数量可以取决于散列树60中的节点层级的数量以及特定的表实施方式而变化。应该注意,节点表可以存储为一组平面数据值,而不是存储为分层存储器结构,这与用于将树、节点和叶数据存储在如上所述的merkle树中的那些节点表不同。可以不存储关联散列树的层次结构,而是可以通过解析和重新解析叶子散列值而在运行时重新创建该结构。
112.还应注意,分支散列表可以实现为具有不同列的单个表。表7a-表7d是根据表中分支节点的节点深度来组织的,如下文所述。表7a-表7d可以包含3列:第1列可以包含节点编号或键;第2列可以包含任何子节点编号或键;第3列可以包含计算出的节点散列值。可选的附加列可以包含节点深度和索引信息。应当意识到,为了清楚起见,表7a-表7d的第3列包含用于计算散列值的公式,而不是实际散列值。
113.计算根散列
114.为了计算rha,可能只需要确保由公式2计算的散列值的排序(如背景技术中提到的)是根据节点键按照字典顺序完成的,这意味着(a)应先计算具有较高节点深度的子节点的分支节点,并且(b)也按照字典顺序计算兄弟节点。作为(a)的示例,节点深度为3的节点0413的散列计算应该在节点深度为2的节点041的散列计算之前。在下面的例子中,节点0413的计算应该在节点041的计算之前,并且节点041的计算应该在节点0的计算之前。同样,节点12的计算应该在节点1的计算之前。作为(b)的示例,在节点0413的计算中,节点041302在节点041321之前。节点rha的计算可以仅在已经计算出节点0和节点1时发生。为了清楚起见,在示例中,可以以相反的节点深度顺序对表执行计算,从表7d开始,然后是表7c,然后是表7b,最后是表7a。
115.第一-表7d-节点深度3。
116.步骤1-计算节点0413:根据表7d(第2列),节点0413的子节点是节点041302和节点041321。节点041302和节点041321的散列值是已知的;它们与节点编号相同,因此0413的散列是其两个子叶子节点041302和041321根据公式2的散列。得到的散列值h(0413)可以存储在表7d中(第3列列出了产生h(0413)的公式)。
117.第二-表7c-节点深度2。
118.步骤2a-计算节点12:使用表7c中的数据与上述步骤1a中的0413类似地计算,并且得到的散列值可以存储在表7c中。
119.步骤2b-计算节点041:根据表7c,节点041的子节点是节点041101和节点0413。节点041101的散列值是已知的,其与节点编号相同。在步骤1a中计算节点0413的散列值并将其存储在表7d中。因此041的散列是它的两个子节点、节点041101和从表7d中取回的散列值的散列。得到的散列值可以存储在表7c中。
120.第三-表7b-节点深度1
121.步骤3a-计算节点1:使用来自表7c中的数据与上述步骤2a中的041类似地计算,并且得到的散列值可以存储在表7b中。
122.步骤3b-计算节点0:使用来自表7c中的数据与上述步骤2a中的041类似地计算,并且得到的散列值可以存储在表7b中。
123.最后-表7a-节点深度0(根散列)。
124.步骤4-计算rha:根据表7a,节点根的子节点为:节点0和节点1。可以从表7b中调用
散列值;
125.返回参考图6,如上所述,叶子节点散列可以存储在散列值存储58中,散列值存储58可以实现为关联存储器53中的平面列表,并且可以使用关联存储器处理器54对其进行解析。需要计算散列值的散列树的任何应用可以由cpu处理器57执行,并且存储在节点表74中和/或从节点表74中取回,节点表74可以是cpu存储器56中的专用表,如下文所述。rbp 73可以识别分支节点和分支节点的子节点并且可以更新节点表74,如上文所解释的。散列计算器76然后可以计算分支节点散列值以及随后计算rha,并且然后可以将结果添加到节点表74,如上文所解释的。
126.应当意识到,通过在关联处理器51上实现散列解析器73,可以利用大规模并行处理高效地执行对大量大的多字节散列值的同时解析和压缩。
127.一旦针对标准散列树(例如merkle树)计算了根散列,该树就被存储为节点和叶子的树结构以及相关联的计算。当叶子值发生变化时,如果需要,所有节点都需要检查和重新计算。
128.申请人已经意识到,对于动态散列树,可以不存储实际的散列树结构。可以只存储叶子和节点计算:叶子可以作为“叶子袋”扁平地存储在关联存储器53中;节点计算可以存储在节点表74中。
129.叶子散列更新
130.申请人已经意识到,对于关联散列树60,当添加、编辑或删除了数据块时,可以通过对新叶子散列进行解析来重新导出树结构,然后如上所述进行节点重新计算,并且可以从节点表74中调用存储在存储器中的可以被重用的任何现有节点计算。
131.参考图8,图8示出了散列值存储58’,其包含与散列存储58相同的数据,其中添加了叶子散列值121210并且要删除叶子散列值。添加的和删除的散列值可以是数据块添加到存储器和从存储器中删除数据块的结果。应当意识到,数据块的编辑可以造成叶数据59被新的数据块散列替换。这样的编辑可以被描述为在同一列中的删除和添加,并且因此在下文中在添加和删除叶子散列的示例中进行说明。
132.对经更新的叶子散列进行解析
133.与上述方法类似,rdbpc算法可以对存储在散列表58’中的叶子值进行解析。生成的动态散列树60’可以具有:根节点;6个分支节点:节点1’、节点12’、节点12121、节点0、节点041和节点0413;以及8个叶子:节点111230、节点121210、节点121211’、节点122102、节点031022、节点041101、节点041302和节点041321,即图8中的8个其余的散列值。简要地参考图9,图9示出了经更新的关联散列树60’。
134.更新节点表
135.下一步是更新节点表74’,节点表74’将用于重新计算散列树60’的根散列值rh
a’。现在参考图10,图10示出了使用表7a’、7b’、7c’和7d’对分支节点表74’的更新。当要删除叶子散列值131021并将叶子散列值121210添加到散列存储58’时,可以对节点表74’进行以下更新(为清楚起见,新的、经更新的和被移动的表条目被加上了下划线,因此显示为xxxx,而被删除的条目被划掉,因此显示为xxxx):
136.(i)散列值131021可以作为子节点从表7b’中的节点1’中删除(如被划掉的值所指示的)。(ii)节点121211可以作为表7c’中节点12’的子节点被删除。(iii)可以添加新的分
支节点12121为表7c’中节点12’的子节点(如带下划线的值所指示的)。(iv)新的分支节点12121可以作为节点本身添加到表7d’。(v)节点121211可以作为节点12121的子节点添加到表7d中。(vi)可以添加新的叶子节点散列121210作为表7d’中节点12121的子节点。
137.散列表74’现在可以反映作为对在散列值存储58’中新的散列值进行解析的结果的分支节点和子节点,如上文所示。
138.重新计算根散列
139.接下来,可以使用与上文所述类似的方法来重新计算rh
a’:
140.第一-表7d
’‑
节点深度3。
141.步骤1a-计算节点0413:该节点及其子节点未发生变化,因此先前针对树60计算的值可能仍然有效,并且可以从表7d’中被调用。
142.步骤1b-计算节点12121:根据公式2计算为叶子散列值121210和121211的散列,并且得到的散列值可以存储在表7d'中。
143.第二-表7c
’‑
节点深度2。
144.步骤2a-计算节点012:节点122102的散列值是已知的,而节点12121的散列值是在步骤1b中计算的,并且可以从表7d'中被调用。得到的散列值可以存储在表7c’中。
145.步骤2b-计算节点041:该节点及其子节点未发生变化,使得先前针对树60计算的值可能仍然有效,并且可以从表7c’中被调用。
146.第三-表7b
’‑
节点深度1。
147.步骤3a-计算节点1:使用来自表7c’中的数据与上述步骤2a中的012类似地计算,得到的散列值可以存储在表7b’中。
148.步骤3b-计算节点0:使用来自表7c’中的数据与上述步骤2a中的012类似地计算,并且得到的散列值可以存储在表7b’中。
149.最后-表7a
’‑
节点深度0。
150.步骤3-计算rh
a’:使用来自表7b’中的数据与上述步骤2a中的012类似地计算,并且得到的散列值可以存储在表7a’中。
151.查看图10可以看出,rha的计算需要7次散列计算。然而,应当意识到,不需要重新计算节点0、节点041和节点0413,因为它们的散列值相对于rha的先前计算保持不变。所以在这种情况下,重新计算rh
a’可能只需要4次后续计算。可以意识到,这可以比常规merkle树所需的重新计算少得多。应当意识到,针对更复杂的关联散列树重新计算根散列所需的重新计算次数在总散列树计算中的比例可能远低于上述简单情况下的比例。
152.将注意力简要地拉回到图6。当从散列表58’中添加或删除叶子值时,rbp 73可以重新解析表58’以产生新的关联散列树60’。rbp 73可以用新的分支节点、子节点和叶子节点指定来更新分支表74。散列计算器76可以重新计算根散列rh
a’和任何其他所需的分支节点,如上文所述。
153.应当意识到,本发明可以减少计算关联散列树的根散列所需的计算次数。上述计算稀疏散列树的方法意味着可以计算和重新计算根散列,与merkle树相比,减少了计算步骤的数量。
154.可以意识到,为了根据一组叶子散列值动态地计算根散列值,可能只需要提取分支节点,并根据存储在关联存储器中的这种叶子散列值确定分支节点关系。这些分支节点
关系,以及分支节点可以存储在节点表中。然后可以根据分支节点的关系,根据这些分支节点散列值和叶子节点散列值计算分支节点的散列值。可以根据分支节点散列值计算根散列值。将进一步意识到,在任何时候都没有存储的散列树的层次结构。节点、节点关系和计算的节点散列值可以存储在平面存储器表或一组表中,但它们只是根据需要被引用,而不是附加到诸如merkle树的层次结构中。如果叶子散列值发生变化,则可以针对新的根散列值进行新的提取、确定和计算。在存储的计算可以被重用的地方,存储的计算可以从节点表以及写回的任何经更新的结果中被调用。但是,在任何时候都不会存储或使用树结构来计算根散列值。
155.上文描述的实施例可以在任何合适的计算设备上实现。
156.除非另有明确说明,从前面的讨论中可以明显看出,在整个说明书中,使用诸如“处理”、“运算”、“计算”、“确定”等术语的讨论可以指定任何类型的通用计算机(例如客户端/服务器系统、移动计算设备、智能电器、云计算单元或类似的电子计算设备)的动作和/或过程,它们操纵和/或将计算系统的寄存器和/或存储器内的数据转换成计算系统的存储器、寄存器或其他此类信息存储、传输或显示设备内的其他数据。
157.本发明的实施例可以包括用于执行本文中的操作的装置。该装置可以专门针对期望的目的来构造,或者可以包括通常具有至少一个处理器和至少一个存储器的计算设备或系统,由存储在计算机中的计算机程序选择性地激活或重新配置。当由软件指示时,所得到的装置可以将通用计算机变成如本文所讨论的发明元件。指令可以定义发明设备与期望的计算机平台一起操作。这样的计算机程序可以存储在计算机可读存储介质中,例如但不限于任何类型的磁盘,包括光盘、磁光盘、只读存储器(rom)、易失性和非易失性存储器、随机存取存储器(ram)、电可编程只读存储器(eprom)、电可擦写和可编程只读存储器(eeprom)、磁卡或光卡、闪存、钥匙上的磁盘,或适用于存储电子指令并能够耦合至计算机系统总线的任何其他类型的介质。计算机可读存储介质也可以在云存储中实现。
158.一些通用计算机可以包括至少一个通信元件以实现与数据网络和/或移动通信网络的通信。
159.本文中呈现的过程和显示与任何特定的计算机或其他装置没有内在的关联。各种通用系统可以根据本文的教导与程序一起使用,或者其可以证明便于构建用于执行期望方法的更加专用的装置。根据以下描述将出现多种这些系统的期望的结构。此外,并不参考任意特定的编程语言来描述本发明的实施例。将明白的是:多种编程语音可用于实现本文中描述的发明的教导。
160.尽管本文已经说明和描述了本发明的某些特征,但本领域普通技术人员现在将想到许多修改、替换、改变和等价物。因此,应当意识到,所附权利要求意在涵盖落入本发明真正精神内的所有这些修改和变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。