1.本发明涉及疾病诊断技术领域,特别涉及一种小样本胃部肿瘤诊断系统。
背景技术:
2.胃部肿瘤是常见的消化系统疾病,可分为恶性肿瘤和良性肿瘤。其中,胃良性肿瘤仅占胃部肿瘤的2%。因此,胃部肿瘤的早发现、早治疗具有临床上的重要意义。胃肿瘤很少出现症状,若肿瘤表现有溃疡,可出现胃部不适、疼痛、甚至出血等症状。因此胃镜的检查尤为重要。结合患者主诉和胃镜结果是诊断胃部肿瘤的有效手段。然而,分析患者主诉和胃镜图片均依赖于医生经验,且会耗费大量时间和精力。基于人工智能技术的主诉文本-胃镜图片分类方法可以减轻医生负担,辅助医生诊断,降低胃部肿瘤漏诊的概率。
3.在人工智能领域,基于单张图片或一段主诉文本的分类方法通常用于各类疾病的判断(如基于胃镜图片判断是否有胃部肿瘤等)。这种人工智能方法是使用机器学习算法从单张图像或一段文本中提取潜在特征的过程。目前最为广泛使用的人工智能方法是将该问题建模为输入一张图像或一段文本,并输出一个标签的问题。在胃部肿瘤诊断方面,标签可分为“有肿瘤”和“无肿瘤”两种。
4.现有技术只能以单张图片或一段文本作为输入,以图片输入为例,现有技术分为以下几个步骤:(1)专业人员以有/无胃部肿瘤为标签,标注大量胃镜图片,每张图片作为一个样本,获得多个带有标注样本的标注语料;(2)基于深度学习网络训练标注语料,获得分类模型;(3)使用分类模型对某个未知标签的图片进行预测,获得该张图片的标签(有/无胃部肿瘤)。预测过程中,每次输入分类模型的是单张图片。
5.以文本输入的现有技术步骤与上述类似,区别仅在于其使用一段主诉文本作为一个样本。
6.其中,第(2)步的深度学习网络一般采用卷积神经网络或基于注意力的transformer(变换器)网络。通常地,深度学习网络由文本/图像编码器层和全连接层组成。编码器层负责提取文本或图像的特征,一般由一系列的卷积层、激活层、池化层、自注意力层等组成。常用的文本编码器层包括transformer、bert(bidirectional encoder representation from transformer,基于变换器的双向编码表示网络)、gpt(generative pre-training transformer,生成预训练变换器网络)等,常用的图像编码器层包括vgg(visual geometry group,视觉几何组网络)、inceptionnet(初始网络)、residual net(残差网络)、dense net(密集网络)、efficient net(效率网络)等。全连接层负责将文本或图像的特征映射到待分类的类别。输入一段文本或一张图片,通过模型中一系列的卷积层、激活层、池化层、自注意力层等对图像进行编码,获得文本或图像的特征;最后通过全连接实现样本的分类。
7.综上所述,现有技术存在以下问题:1)由于部分患者并无明显症状,且胃部肿瘤在一些图片中上表现不明显,专业医生往往需要结合患者主诉和多张胃镜图片综合判断。然而,现有技术只能从单一文本或单
张图像的角度判断病情,既无法处理多张胃镜图片的输入,也无法处理胃镜图像和主诉文本的同时输入。
8.2)通过现有技术构建的模型通常有大量的参数需要学习,因此其极度依赖大量的已标注胃镜病例,而标注病例需要花费高昂的人力和物力。
9.因此,现有技术的缺陷导致现有的人工智能预测模型成本很高,对胃部肿瘤的诊断正确率却不够高。
技术实现要素:
10.本发明要解决的技术问题是提供一种成本低、诊断准确率高的小样本胃部肿瘤诊断系统。
11.为了解决上述问题,本发明提供了一种小样本胃部肿瘤诊断系统,包括:预训练模型和真实训练模型,所述预训练模型和真实训练模型均包括文本编码器、图像编码器、全连接层、模板层、融合层、概率分布输出层、映射层、分类层;所述预训练模型采用无标注的预训练病例样本进行预训练,训练图像编码器和全连接层,所述预训练病例样本包括主诉文本和胃镜图像不匹配的不匹配病例样本,以及主诉文本和胃镜图像匹配的匹配病例样本;所述真实训练模型采用预训练模型训练后的图像编码器和全连接层,并对文本编码器和训练后的全连接层进行真实训练;所述真实训练模型采用标注过的真实训练病例样本进行真实训练,所述真实训练病例样本为主诉文本和胃镜图像匹配的匹配病例样本;所述文本编码器用于生成主诉文本浅层特征序列集合;所述图像编码器用于获取胃镜图像的图像特征序列集合;所述全连接层用于重塑图像特征序列的维度得到与主诉文本浅层特征相同维度的图像特征序列集合;所述模板层用于构造包含可学习遮蔽字符的任务提示模板,并将所述主诉文本浅层特征序列集合和图像特征序列集合输入所述任务提示模板,得到病例样本的任务提示;所述融合层用于构建位置向量并与所述任务提示模板相加后输入所述文本编码器,得到包含主诉文本特征和多张胃镜图像特征的多模态特征;所述概率分布输出层用于选取多模态特征中遮蔽字符的特征,并得到遮蔽字符输出为各字符的概率分布;所述映射层用于将标签空间中的每个标签映射至所述文本编码器词汇表中的一个字符;所述分类层用于根据映射构造概率分布的子集,并选取其中概率最高的元素所对应的标签作为预测分类结果;其中,所述预训练病例样本的标签空间为{不匹配,匹配},所述真实训练病例样本的标签空间为{有胃部肿瘤,无胃部肿瘤}。
12.作为本发明的进一步改进,所述文本编码器包括嵌入层,所述嵌入层用于接收主诉文本,并生成主诉文本浅层特征序列集合。
13.作为本发明的进一步改进,所述预训练模型和真实训练模型均包括归一化层,所述归一化层用于将胃镜图像归一化到统一的色彩空间和维度尺寸,并依次输入所述图像编码器,得到图像特征集合序列集合。
14.作为本发明的进一步改进,所述全连接层用于重塑图像特征序列的维度使图像特征序列变成二维序列,以得到与主诉文本浅层特征相同维度的图像特征序列集合。
15.作为本发明的进一步改进,所述全连接层得到的与主诉文本浅层特征相同维度的
图像特征序列集合为:其中,,;表示m张胃镜图像中的第i张胃镜图像;表示图像编码器获取的图像特征序列集合中的第i张胃镜图像的图像特征序列;w1和b1分别表示全连接层中可学习的第一权重参数和第一偏置参数;表示维度重塑。
16.作为本发明的进一步改进,所述任务提示模板为:[lrn0] [mask] [lrn1] s
’ꢀ
[lrn2] i
’ꢀ
[sep]其中,[mask]表示可学习遮蔽字符;[sep]表示可学习间隔字符;[lrn0]、[lrn1]、[lrn2]表示不同的可学习提示字符;s’表示主诉文本浅层特征序列槽位;i’表示图像特征序列槽位。
[0017]
作为本发明的进一步改进,所述概率分布输出层用于选取多模态特征中遮蔽字符的特征,并得到遮蔽字符输出为各字符的概率分布,包括:所述概率分布输出层用于选取多模态特征中遮蔽字符的特征,并通过文本编码器的词汇输出层和softmax分类器,得到遮蔽字符输出为各字符的概率分布。
[0018]
作为本发明的进一步改进,遮蔽字符输出为各字符的概率分布为:其中,p为遮蔽字符输出为各字符的概率分布;softmax表示softmax分类器的softmax函数;w2和b2分别表示全连接层中可学习的第二权重参数和第二偏置参数;表示遮蔽字符的特征。
[0019]
作为本发明的进一步改进,所述预训练模型和真实训练模型在训练时均采用交叉熵损失函数。
[0020]
本发明的有益效果:本发明小样本胃部肿瘤诊断系统以病例为样本单位,将每个病例的主诉文本和多张胃镜图片同时作为样本的输入,综合判断是否存在胃部肿瘤。为调和不同编码器提取的文本特征和图像特征间的语义鸿沟,本发明采用“预训练-真实训练”式的二阶段模型训练方法,在预训练中可使用大量无标注的主诉文本-胃镜图像对在模型上做自监督的图文匹配任务,将图像特征投射到文本特征所在的向量空间,缩小图文两种模态间的语义鸿沟,提升真实训练模型在真实训练中的性能。
[0021]
其次,本发明只需使用少量的标注病例样本进行模型训练,以减少标注病例所需的人力物力。为了使模型能在少样本环境下正常训练和预测,本发明使用任务提示模板和预测遮蔽字符的方式完成分类任务,以减少模型训练的参数量及其所需的标注样本的数量。使得本发明具有成本低、诊断准确率高的优点。
[0022]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
[0023]
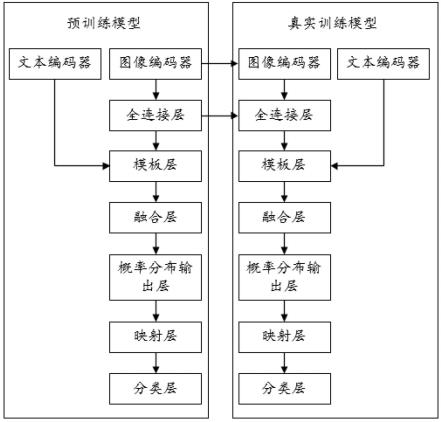
图1是本发明优选实施例中小样本胃部肿瘤诊断系统的示意图。
具体实施方式
[0024]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0025]
如图1所示,本发明优选实施例公开了一种小样本胃部肿瘤诊断系统,包括:预训练模型和真实训练模型,所述预训练模型和真实训练模型均包括文本编码器、图像编码器、全连接层、模板层、融合层、概率分布输出层、映射层、分类层。
[0026]
所述预训练模型采用无标注的预训练病例样本进行预训练,训练图像编码器和全连接层,所述预训练病例样本包括主诉文本和胃镜图像不匹配的不匹配病例样本,以及主诉文本和胃镜图像匹配的匹配病例样本。
[0027]
所述真实训练模型采用预训练模型训练后的图像编码器和全连接层,并对文本编码器和训练后的全连接层进行真实训练;所述真实训练模型采用标注过的真实训练病例样本进行真实训练,所述真实训练病例样本为主诉文本和胃镜图像匹配的匹配病例样本。
[0028]
在一些实施例中,预训练病例样本的构建如下:随机选择一部分收集到的病例样本(包含主诉文本和胃镜图像),随机交换其中的主诉文本,构造不匹配病例样本。任意不匹配病例样本中的主诉文本和胃镜图像均不匹配,对应分类标签y为“不匹配”。同时,保留一定数量的匹配病例样本(即不做任何操作的病例样本)一同作为预训练中使用的样本,其对应分类标签y为“匹配”。任意预训练病例样本均包含模型输入x和对应的真实标签y两个部分。设由m张胃镜图像和一段含有n个字符的主诉文本组成,即。
[0029]
所述文本编码器用于生成主诉文本浅层特征序列集合;具体地,所述文本编码器包括嵌入层,所述嵌入层用于接收主诉文本,并生成主诉文本浅层特征序列集合:其中,,embedding表示嵌入层;si表示主诉文本的第i个字符,。可选地,文本编码器采用预训练的生物医药文本编码器,单个字符si的浅层特征的维度为768。
[0030]
所述图像编码器用于获取胃镜图像的图像特征序列集合;在一些实施例中,所述预训练模型和真实训练模型均包括归一化层,所述归一化层用于将胃镜图像归一化到统一的色彩空间和维度尺寸(可选地,维度尺寸为3*224*224),并依次输入所述图像编码器,得到图像特征集合序列集合。
[0031]
其中,表示m张胃镜图像中的第i张胃镜图像,;visionencoder表示图像编码器;可选地,图像编码器选用预训练的residual network(resnet),每个图像特征序列的维度为7*7*2048。
[0032]
所述全连接层用于重塑图像特征序列的维度得到与主诉文本浅层特征相同维度的图像特征序列集合;具体地,所述全连接层用于重塑图像特征序列的维度使图像特征序列变成二维序列,以得到与主诉文本浅层特征相同维度的图像特征序列集合。可选地,所述全连接层得到的与主诉文本浅层特征相同维度的图像特征序列集合为:其中,,;表示m张胃镜图像中的第i张胃镜图像;表示图像编码器获取的图像特征序列集合中的第i张胃镜图像的图像特征序列;w1和b1分别表示全连接层中可学习的第一权重参数和第一偏置参数;表示维度重塑。可选地,每个图像特征序列的维度为49*768。
[0033]
所述模板层用于构造包含可学习遮蔽字符的任务提示模板,并将所述主诉文本浅层特征序列集合和图像特征序列集合输入所述任务提示模板,得到病例样本的任务提示;在一些实施例中,所述任务提示模板为:[lrn0] [mask] [lrn1] s
’ꢀ
[lrn2] i
’ꢀ
[sep]其中,[mask]表示可学习遮蔽字符;[sep]表示可学习间隔字符;[lrn0]、[lrn1]、[lrn2]表示不同的可学习提示字符;s’表示主诉文本浅层特征序列槽位;i’表示图像特征序列槽位。
[0034]
具体地,通过逐一提取任务提示模板中可学习字符的文本浅层特征,并在相应位置传入主诉文本浅层特征序列集合和图像特征序列集合,得到对应该病例的任务提示。
[0035]
任务提示包含k个特征,即:其中,k》m n;相邻的图像特征序列之间使用字符[sep]间隔开。
[0036]
所述融合层用于构建位置向量并与所述任务提示模板相加后输入所述文本编码器,得到包含主诉文本特征和多张胃镜图像特征的多模态特征;具体地,构建长度为k的位置向量e
p
(每个位置对应不同的向量),与任务提示相加后输入文本编码器的主干,得到包含主诉文本特征和多张胃镜图像特征的多模态特征h:
其中,textencoder表示文本编码器。
[0037]
所述概率分布输出层用于选取多模态特征中遮蔽字符的特征,并得到遮蔽字符输出为各字符的概率分布;具体地,所述概率分布输出层用于选取多模态特征中遮蔽字符的特征,并通过文本编码器的词汇输出层和softmax分类器,得到遮蔽字符输出为各字符的概率分布。
[0038]
可选地,遮蔽字符输出为各字符的概率分布为:其中,p为遮蔽字符输出为各字符的概率分布;softmax表示softmax分类器的softmax函数;w2和b2分别表示全连接层中可学习的第二权重参数和第二偏置参数;表示遮蔽字符的特征。
[0039]
所述映射层用于将标签空间中的每个标签映射至所述文本编码器词汇表中的一个字符;具体地,根据标签空间y中的每个标签yi,根据训练任务定位一个映射v,将其映射到文本编码器词汇表中的一个字符ci,即:v(yi)=ci其中,,所有v(y)组成了新的标签空间;所述预训练病例样本的标签空间为{不匹配,匹配},定义映射v(匹配)=“对”,v(不匹配)=“错”。
[0040]
所述真实训练病例样本的标签空间为{有胃部肿瘤,无胃部肿瘤},定义映射v(有胃部肿瘤)=
ꢀ“
有”,v(无胃部肿瘤)=
ꢀ“
无”。
[0041]
所述分类层用于根据映射构造概率分布的子集,并选取其中概率最高的元素所对应的标签作为预测分类结果;具体地,构造概率分布p的子集,选取其中概率最高的所对应的yi作为预测分类结果:其中,argmax表示用于取最大值的argmax函数。
[0042]
所述预训练模型和真实训练模型在训练时均采用交叉熵损失函数。
[0043]
具体地,交叉熵损失函数为:其中,表示真实标签y的one-hot编码中的第i个分量,。
[0044]
需要指出的是,所述预训练模型在训练时只训练图像编码器和全连接层,所述真
实训练模型与预训练模型的结构相同,所述真实训练模型采用预训练模型训练后的图像编码器和全连接层,并只对文本编码器(包括嵌入层、主干和词汇输出层)和训练后的全连接层进行真实训练。
[0045]
本发明小样本胃部肿瘤诊断系统以病例为样本单位,将每个病例的主诉文本和多张胃镜图片同时作为样本的输入,综合判断是否存在胃部肿瘤。为调和不同编码器提取的文本特征和图像特征间的语义鸿沟,本发明采用“预训练-真实训练”式的二阶段模型训练方法,在预训练中可使用大量无标注的主诉文本-胃镜图像对在模型上做自监督的图文匹配任务,将图像特征投射到文本特征所在的向量空间,缩小图文两种模态间的语义鸿沟,提升真实训练模型在真实训练中的性能。
[0046]
其次,本发明只需使用少量的标注病例样本进行模型训练,以减少标注病例所需的人力物力。为了使模型能在少样本环境下正常训练和预测,本发明使用任务提示模板和预测遮蔽字符的方式完成分类任务,以减少模型训练的参数量及其所需的标注样本的数量。使得本发明具有成本低、诊断准确率高的优点。
[0047]
为了验证本发明的有效性,在一具体实施例中,本发明收集了内镜中心胃镜检查(包括无痛胃镜、清醒镇静胃镜及普通胃镜检查)患者的胃镜图片和对应的主诉文本。图片拍摄设备主要为 olympus 公司 240、260、290系列以及日本fujinon公司560、580系列内镜。所有图片在白光非放大模式下拍摄,bli、fice、nbi等光学染色及靛胭脂、醋酸染色放大等化学染色暂不做研究。纳入标准:诊断为:胃部肿瘤(良性、恶性均包含在内)和正常胃镜粘膜图片。排除标准:
①
患者小于16岁或者大于95岁;
②
图片异常模糊、伪影、异常失真等影响观察的图片;
③
有大量泡沫、粘液湖或者食物等干扰严重的图片。
[0048]
按照纳入和排除标准,共纳入标注病例样本2000例。标注样本中,有胃部肿瘤和无胃部肿瘤(正常胃)的病例数分别为750例和1250例。每个病例均含有一段主诉文本和1-10张胃镜图片。
[0049]
预训练阶段:将所有标注病例样本全部作为匹配样本,再将这些匹配样本的主诉文本随机打乱,交换,构造4000例不匹配样本。最终得到6000例训练样本,并按9:1的比例随机划分为无交集的训练集和验证集。
[0050]
真实训练阶段:将所有标注病例随机划分为无交集的训练集(40例,其中有胃部肿瘤20例,无胃部肿瘤20例)、验证集(40例,其中有胃部肿瘤20例,无胃部肿瘤20例)和测试集(1920例,其中有胃部肿瘤710例,无胃部肿瘤1210例)。
[0051]
本发明首先进行预训练:使用训练集中的样本对预训练模型进行图文匹配训练和参数更新,然后在验证集上的评估模型性能,选取最合适的超参数并保存最优预训练模型。接着进行真实训练:加载预训练中保存的最优模型参数,使用真实训练集中的样本对真实训练模型进行胃部肿瘤识别训练和参数更新,然后在验证集上的评估模型性能,选取最合适的超参数并保存最优真实训练模型。
[0052]
真实训练模型训练完毕后,将测试集中的待预测样本依次输入真实训练模型,获得胃部肿瘤的诊断结果。同时,邀请2名经验丰富的内镜医师对测试集中的病例(包含主诉文本和胃镜图片)进行判读和诊断。得出模型和2名医师对疾病诊断的整体准确率、灵敏度和阳性预测值。
[0053]
最终得到,本发明的胃部肿瘤诊断整体准确率、灵敏度、阳性预测值都明显优于现
有的单模态人工智能方法,接近经验丰富的内镜医师。具体结果如下:医生的整体准确率为88%,本发明的整体准确率为88.2%。医生的灵敏度为88.4%,本发明的灵敏度为88.3%。医生的阳性预测值为89%,本发明的阳性预测值为89.1%。而单模态人工智能方法的整体准确率、灵敏度、阳性预测值均不足85%。
[0054]
其中,整体准确率=识别正确的病例数/测试集病的实际病例数
×
100%。
[0055]
灵敏度=识别正确某一类别病例数/该类别的实际病例数
×
100%。
[0056]
阳性预测值=识别正确某一类别的病例数/被模型或内镜医师识别成该类别的病例数
×
100%。
[0057]
以上实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。