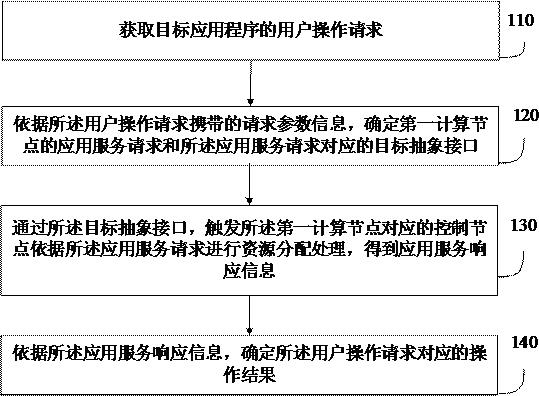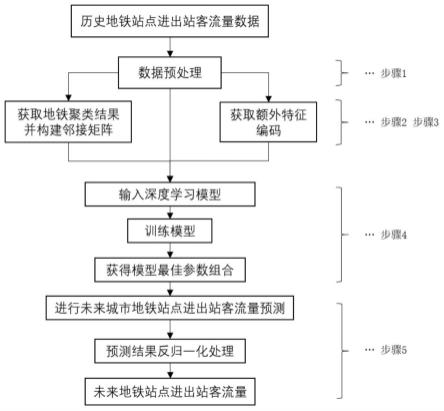
1.本发明涉及机器学习领域,更具体的说是涉及城市地铁进出站客流量预测方法。
背景技术:
2.随着居民生活水平的不断提高,城市中的汽车保有量逐年增高。城市中道路交通承载压力也随着汽车数量的增长而增加,城市道路交通常常会出现拥挤的情况。许多城市居民选择更加方便快捷的城市轨道交通作为出行的方式。作为一种高效且相对环保低碳的城市轨道交通,地铁出行一直受到极大关注。与此同时,由于地铁各个站点以及列车的承载能力有限,往往在高峰时段出现客流拥堵的情况,导致城市居民出行不便。针对地铁客流量预测问题,研究方法主要分为统计学习方法、机器学习方法以及深度学习方法。通过学习历史数据中地铁进出站客流量的变化趋势特征,实现对未来客流量的预测。
技术实现要素:
3.有鉴于此,本发明提供了一种城市地铁进出站客流量预测方法,包含一种基于城市地铁客流量时间序列形状特征的地铁站点聚类方法、额外特征编码方法,包含地铁客流量级独热编码方法和时间戳独热编码方法以及基于图卷积循环神经网络和注意力机制的深度学习模型实现对未来地铁客流量的预测。
4.为了实现上述目的,本发明采用如下技术方案:
5.一种城市地铁进出站客流量预测方法,包括以下步骤:
6.获取历史地铁站点进出站客流量数据;
7.对客流量数据进行预处理;
8.将预处理后的客流量数据输入到深度学习模型中,对深度学习模型进行训练;
9.利用训练好的模型预测未来城市地铁站点进出站客流量。
10.可选的,对客流量数据进行预处理的具体步骤如下:
11.获取历史数据中地铁客流量时间序列数据的均值;
12.将周工作日与周末客流量时间序列数据的均值做差,得到周工作日与周末客流量变化的差异时间序列;
13.对差异时间序列计算相似度,得到各个地铁站点间的相似度;
14.基于各个地铁站点间的相似度,使用k-means聚类方法进行聚类,并根据聚类结果构建邻接矩阵。
15.可选的,对客流量数据进行预处理还包括:
16.对地铁站点进出站客流量级进行编码,对地铁进出站客流量时间戳特征进行编码;客流量级编码结果和客流量时间戳特征编码结果共同构成额外特征。
17.可选的,对地铁进出站客流量时间戳特征进行编码具体如下:所述时间戳特征分为日时间特征以及周时间特征;日时间特征根据一日的时间间隔的数量进行编码,周时间特征根据所在周工作日和周末进行独热编码。
18.可选的,对地铁站点进出站客流量级进行编码具体如下:根据各地铁站点的客流量,通过所有地铁站点历史客流量均值以及方差将地铁站点分为若干个不同的流量等级,根据不同的流量等级对地铁站点进行独热编码。
19.可选的,还包括对地铁客流量时间序列数据归一化,归一化的公式如下:
[0020][0021][0022]
x
max
和x
min
分别代表地铁客流量的最大值和最小值,μ
x
和σ
x
分别代表地铁客流量的均值和方差。
[0023]
可选的,模型训练过程使用的损失函数为平均绝对误差。
[0024]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种城市地铁进出站客流量预测方法,具有以下有益效果:
[0025]
1.本发明通过收集各城市地铁站点各时刻的历史进出站客流量来预测未来各站点的进出站客流量。
[0026]
2.本发明提出一种有效的城市地铁站点客流量时间序列聚类方法,将城市地铁站点按其所在区域功能性进行聚类。
[0027]
3.本发明基于独热编码方式提出改良的地铁客流量级编码和时间戳信息编码作为额外特征通过嵌入技术嵌入深度学习模型。
[0028]
4.本发明提出一种带有多头注意力机制的深度图卷积循环神经网络充分提取城市地铁站点客流量的时空特征,并实现对未来城市地铁进出站客流量的准确预测。
附图说明
[0029]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0030]
图1为本发明的整体流程示意图;
[0031]
图2为本发明的地铁站点聚类流程图;
[0032]
图3为本发明的额外特征编码流程图;
[0033]
图4为本发明的模型整体架构图;
[0034]
图5为本发明的图卷积循环神经网络图;
[0035]
图6为本发明的局部空间特征图卷积门控循环模块图;
[0036]
图7为本发明的全局空间特征自适应图扩散卷积模块图;
[0037]
图8为本发明的局部空间特征图卷积模块图;
[0038]
图9为本发明的多头注意力机制模块图。
具体实施方式
[0039]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0040]
本发明实施例公开了一种基于聚类算法和基于图卷积循环神经网络和注意力机制的深度学习模型的城市地铁进出站客流量预测方法。此方法主要的主要流程如图1所示,其中主要包括五个步骤:
[0041]
步骤1是对数据进行预处理,将获取到历史城市地铁站点进出站客流量数据进行归一化处理,归一化处理的方式主要有min-max归一化以及z-score 归一化的处理方式,如公式(1)-(2)所示。其中,x
max
和x
min
分别代表地铁客流量的最大值和最小值,μ
x
和σ
x
分别代表地铁客流量的均值和方差。
[0042][0043][0044]
数据在进行归一化处理后,将被分为训练数据、验证数据和测试数据。模型主要通过训练数据来训练模型,验证数据来确定模型的最佳参数组合,最后通过测试数据来验证模型的性能。
[0045]
步骤2是基于城市地铁客流量时间序列形状特征的地铁站点聚类,此方法主要的主要流程如图2所示。首先,获取各地铁站点进出站客流时间序列周工作日和周末的平均客流量并获取各地铁站点的周工作日和周末的客流量变化差异时间序列。将地铁进出站的历史客流量时间序列分为周工作日和周末两类,分别计算周工作日和周末的每个时刻的客流量均值。通过均值的计算,可以获取周工作日以及周末两种平均客流量的时间序列。由于各个地铁站点的进出站客流存在不同的行为模式,本方法将对进站和出站历史平均客流量时间序列进行分别计算。以第j个地铁站点的进站客流量时间序列为例,第i个周工作日的进站客流量时间序列数据可以表示为其中,表示第j个地铁站点第i个工作日第k个时刻的进站客流量,则进站客流量周工作日的平均客流量时间序列数据可以表示为同理,周末进站平均客流量时间序列数据可以表示为将周工作日的平均客流量时间序列减去周末进站平均客流量时间序列得到进站客流量差异时间序列,即对于每一个城市地铁站点,通过上述方法都可以获得进出站客流量差异时间序列。本发明通过k-means聚类方法对得到的客流量差异时间序列进行聚类。首先要计算待聚类的时间序列间的相似度,可以通过欧式距离d
euclidean
、余弦距离d
cosine
和皮尔森系数d
pearson
方法来计算时间序列间的相似度。具体公式如(3)-(5)所示:
[0046]
[0047][0048][0049]
确定了待聚类时间序列两两之间的相似度,得到一个相似度矩阵。每一行代表当前站点的时间序列与其他各个站点时间序列的相似度矩阵,最后通过k-means聚类算法对时间序列进行聚类。
[0050]
为了使得本发明提出的深度学习模型能够更好地提取城市地铁客流量时间序列中的空间特征,聚类的结果将用于城市地铁站点的邻接矩阵的构建。对于在同一个簇中的地铁站点,为这些站点两两添加邻接关系从而建立两个地铁站点之间的虚拟连接。新构建的邻接矩阵包含具有客流量变化相似的城市地铁站点的邻接信息。具有聚类邻接信息的邻接矩阵可以表示为a
cluster
,表示地铁站点i和地铁站点j之间的邻接关系。当两个站点处于同一个聚类簇中则存在邻接关系,a
cluster
中的元素如公式(6)所示。通过聚类算法对客流量差异时间序列使用k-means聚类后,得到k个地铁站点簇。每个簇中地铁站点的周工作日与周末间客流量变化趋势相似。同时,为了保留各地铁站点原有的地理邻接关系,原始的邻接矩阵将与聚类得到的邻接矩阵相合并。原始的邻接矩阵只包含当前地铁站最近的的一个邻居站点,为了获取多个相邻的地铁站点的空间信息,本发明提出将相邻k个站点的邻接关系都包含进邻接矩阵构成k-hop邻接矩阵a
k-hop
,其中元素的取值如公式(7)所示,δ表示i,j 站点间相隔站点的数量。为了使得深度学习模型能够更好地通过两种邻接矩阵学习城市地铁客流量的空间特征,最终输入模型的邻接矩阵为 a
comb
=ω1a
cluster
ω2a
k-hop
,其中ω1和ω2是可学习的参数。
[0051][0052][0053]
步骤3是本发明提出的基于独热编码额外特征构建,主要流程如图3所示。主要对各个城市地铁站点的客流量级以及客流量时间序列的时间戳信息进行编码。由于同一个地铁站点的进出站客流量存在差异,所以进出站客流量应该分别考虑。以进站客流量为例,客流量大小量级的确定方法首先将所有地铁站点的进站客流量历史数据求均以及标准差其中n为地铁站点数。地铁客流量级编码是基于独热编码α
flow
=[a1,a2,...,ai,...,a
2(t 1)
],其中ai的取值为0和1,编码长度为l。当第i个地铁站点客流量时,α
flow
中a1到a
t 1-η
的取值为1,其余为0,其中 t 1-η>0。当第i个地铁站点客流量时,α
flow
中a1到a
t η 2
的取值为 1,其余为0,其中t η 2<2(t 1)。对于时间戳独热编码方法,首先给予一周七天一个序列长度为7的独热编码并在最后增加一
位当前时刻编码a
current
,最后的独热编码序列为α
time
=[a1,a2,...,ai,...,a7,a
current
]。周时间特征的独热编码方式以星期二为例,若当前时间为星期二,则a2=1其余位为0,从而实现对一周七天实现编码。日时间特征的编码方式是是基于一日内时间间隔的数量确定的。若历史客流量时间序列数据在一天内被分为r个时间间隔,则第i个时间间隔的通过上述方法,可以得到最终的时间戳独热编码。
[0054]
步骤4为将预处理好的历史数据,邻接矩阵和额外特征输入基于图卷积循环神经网络和注意力机制的深度学习模型。本发明提出的模型主要通过学习历史的客流量时间序列数据以及额外特征,实现对未来城市地铁站点进出站客流量的准确预测。该深度学习模型的整体框架如图4所示,模型的架构是序列到序列的深度学习模型架构,主要由编码器和解码器组成。编码器的输入主要分为两个部分,一个是历史的进出站客流量,一个是额外特征的输入。可以看到通过本发明提出的深度学习模型的输入为x1至xn,这代表模型将学习过去n个时刻的数据,同时地铁客流量级编码作为地铁流量的特征被一起嵌入流量数据并通过图卷积循环神经网络学习地铁各站点客流量变化的空间特征。时间戳编码通过一个全连接层变换维度与初始隐藏状态合并输入图卷积循环神经网络用于学习客流量变化的时间特征。解码器的输入为上个时间步解码器预测的结果。最后的输出为至为模型预测的未来n个时刻的各地铁站点的进出站客流量。对于图卷积循环神经网络,模块整体的架构图如图5所示。图卷积模块主要由两部分组成,分别是局部空间特征图卷积门控循环模块和全局空间特征自适应图扩散卷积模块,分别如图6和图7所示。对于局部空间特征图卷积门控循环模块,模块的架构类似门控循环神经网络,但是在使用了图卷积神经网络实现对输入以及隐藏状态的空间特征提取。局部空间特征图卷积门控循环模块主要包含了重置门和更新门用于对图卷积神经网络提取的空间特征进行重置和更新。其中频域图卷积神经网络的架构图如图8所示,输入和隐藏状态通过n层频域图卷积神经网络模块进行空间特征的提取。频域图卷积神经网络实现了在拓扑图上的卷积操作。在进行频域图卷积操作时,首先要构建图的拉普拉斯矩阵l=d-a,其中d是顶点的度矩阵, a是图的邻接矩阵。拉普拉斯矩阵的常见形式有对称归一化的拉普拉斯矩阵 l
sys
和随机游走归一化拉普拉斯矩阵l
rw
,如公式(9)-(10)所示。和分别为l
sys
和l
rw
中第i,j位置的元素,当i=j且顶点i的度不为0时,和均为 1。当i≠j且顶点i和顶点j具有邻接关系时,则分别为和其中d(vi)代表顶点i的度。否则,和均为0。
[0055]
l
sys
=d-1/2
ld-1/2
=i-d-1/2
ad-1/2
ꢀꢀꢀ
(8)
[0056]
l
rw
=d-1
l=i-d-1aꢀꢀꢀ
(9)
[0057]
在得到了拉普拉斯矩阵后,对其进行特征分解得到l=pλp
t
,其中p为列向量为单位特征向量的矩阵,λ为特征值构成的对角矩阵。图上的傅里叶变换可以表示为傅里叶逆变换可以表示为其中x表示图上各顶点的特征。图卷积操作的公式如公式(11)所示,
⊙
表示矩阵的哈德玛积,p
t
g 整体被表示g
θ
(λ)是表示可学习的卷积核。为了减
小计算量,g
θ
(λ)可以很好的通过chebyshev多项式tk(x)的k阶截断展开来拟合。chebyshev多项式的递归定义为tk(x)=2xt
k-1
(x)-t
k-2
(x),其中t0(x)=1,t1(x)=x。是对λ进行放缩得到的,其中λ
max
为l的最大特征值,缩放后元素取值在[-1,1]之间。通过拟合,得到最后的图卷积公式如公式(12)所示,其中
[0058]
(x*g)
gcn
=p((p
t
g)
⊙
(p
t
x))=pg
θ
(λ)p
t
x
ꢀꢀꢀ
(10)
[0059][0060]
由于进出站客流量的变化行为有差异,所以在每一层又细分为进站图卷积神经网络模块和出站图卷积神经网络模块分别提取进出站客流量时间序列的空间特征。残差连接的使用避免了过多层的频域图卷积神经网络模块导致提取的特征过于平滑的问题。局部空间特征图卷积门控循环模块中各中间变量的计算公式如公式(12)-(15)所示,其中u
t
,r
t
和n
t
表示更新门,重置门和得到的新特征,σ和tanh分别是sigmoid和tanh激活函数。地铁进出站客流量预测中未来时间点的信息往往与前几个时间点的信息有关,因此通过门控机制能够选择性地保留地铁进出站客流量时间序列的长期或短期时间依赖。
[0061]ut
=σ(x
t
*g
ux
h
t-1
*g
uh
bu)
ꢀꢀꢀ
(12)
[0062]rt
=σ(x
t
*g
rx
h
t-1
*g
rh
br)
ꢀꢀꢀ
(13)
[0063]nt
=tanh(x
t
*g
nx
u
t
⊙ht-1
*g
nh
bn)
ꢀꢀꢀ
(14)
[0064]ht
=(1-r
t
)
⊙nt
r
t
⊙ht-1
ꢀꢀꢀ
(15)
[0065]
全局空间特征自适应图扩散卷积模块,主要实现了对地铁进出站客流量时间序列和隐藏状态的全局空间特征的自适应提取。该图卷积模块不需要提前设计邻接矩阵,通过两个可学习的向量相乘构成一个可学习参数组成的邻接矩阵l
adptive
=e1e
2t
。通过扩散图卷积操作提取输入和隐藏状态的全局空间特征,扩散图卷积操作如公式(16)所示。为经过图卷积操作后的特征,wk是可学习的参数。该模块最终的输出为从输入和隐藏状态提取的全局空间特征的融合。
[0066][0067]
经过全局空间特征自适应图扩散卷积模块输出的特征将与局部空间特征图卷积门控循环模块的输出相加作为当前图卷积循环神经网络模块的输出和下一个时间点的隐藏状态。在解码器部分,输入为上一个时间点图卷积循环神经网络模块的输出,其余的图卷积操作与编码器相同。在每个时间点的图卷积循环神经网络解码器模块的输出都会与编码器每个时间点的最终输出一同进入多头注意力机制模块,用于当前解码器输出提取与历史编码器输出的长距离依赖关系。多头注意力机制模块如图9所示,主要输入有查询(query),键(key)以及值(value)。在本发明中,当前解码器的输出为查询,编码器的历史输出为键以及值。首先将查询,键以及值作线性变换,然后将变换后的查询,键以及值并行地送入h组的注意力汇聚模块中,注意力汇聚的方法为缩放点积注意力。注意力的计算公式如公式(13)所示,其中q,k和v分别表示查询,键以及值,softmax函数计算了各个键的注意力分数,d为查询和键的长度。最后,将h组的注意力输出进行合并然后通过一个全连接层输出最终的特
征。
[0068][0069]
经过多头注意力机制模块的输出将与额外特征相合并,额外特征包含地铁客流量级编码特征和时间戳编码特征。合并额外特征的目的是为了对编码器输入的额外特征作解码操作。最后将合并后的特征将输入一个全连接层,输出结果实现当前时间步的预测。
[0070]
模型训练的过程将预处理好数据划分为每组时间步长为n([x1...xn]即为一组数据)的训练数据。模型输入的数据为[x1...xn]即为模型预测的第1到第n时刻的城市地铁历史进出站客流量。模型的输出为即为模型预测的第 n 1到第2n的城市地铁进出站客流量。训练过程中,为了模型能过加速收敛又不失泛化能力,采用了课程学习(curriculum learning,cl)机制对模型进行训练。课程学习机制将以一定的概率p决定解码器的输入为上一时刻的模型的输出值还是上一时刻的真实值。当p>ε时,当前时刻解码器的输入为上一时刻解码器的输出,否则为上一时刻的真实值。随着训练轮数的增多,ε的值逐渐减小。目的是让模型在前期通过较多真值的输入学习到了时间序列数据变化的趋势,在后期能够通过解码器本身的输出更好地修正模型本身的误差并在其他时间序列数据上有更好的泛化性能。如果在训练过程中,解码器全部为上一时刻的真值输入,训练好的模型很可能存在过拟合的现象。模型训练的轮数为e。模型训练使用的损失函数为平均绝对误差(mean absolute error),公式如(13)所示。模型使用自适应性矩估计(adaptive moment estimation, adam)优化器进行模型的参数优化,学习率在进行参数优化过程会随着训练轮数的增多而逐渐减少。在训练过程中,在验证数据集上表现最好的模型参数组合将被保存。
[0071]
步骤5是实现对未来城市地铁站点进出站客流量的预测,从步骤4的到的模型最佳参数组合将被用于未来客流量的预测。带预测的数据同样被划分为每组时间步长为n的若干组数据。模型输入的数据为[x1...xn],输出为在获取了模型的预测值之后还需要预测值进行数据反归一化处理得到最终的地铁进出站客流量数据,min-max和z-score反归一化的公式如(18)—(19) 所示。其中,均值以及方差的是从训练数据中得到的。
[0072][0073][0074]
最后,本发明采用平均绝对误差(mean absolute error,mae),均方根误差(root mean square error,rmse)和平均绝对百分比误差(mean absolutepercentage error,mape)衡量模型的性能,如公式(20)-(22)所示。
[0075][0076]
[0077][0078]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0079]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。