1.本发明一般涉及机器学习技术领域,具体涉及一种命名实体识别方法、装置、设备及存储介质。
背景技术:
2.随着人工智能算法技术的不断发展,命名实体识别(named entity recognition,ner)任务已经越来越多地应用到各个不同领域中。其中,命名实体识别,是用于识别文本中具体特定意义的实体的类型和位置,从而为文本中的各个文本添加ner标签。
3.目前,相关技术中采用命名实体识别模型并结合词典修正的方式来实现命名实体识别并输出结果。然而,对于一个文本语句中存在两个文本内容相同但实体类型不同的实体情况,采用该方案会仅得到一个实体类型的结果,导致得到识别结果准确度低。
技术实现要素:
4.鉴于现有技术中的上述缺陷或不足,期望提供一种命名实体识别方法、装置、设备及存储介质。
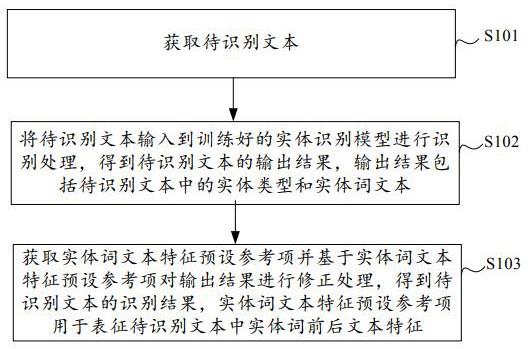
5.第一方面,本技术实施例提供了一种命名实体识别方法,该方法包括:获取待识别文本;将所述待识别文本输入到训练好的实体识别模型进行识别处理,得到所述待识别文本的输出结果,所述输出结果包括所述待识别文本中的实体类型和实体词文本;获取实体词文本特征预设参考项并基于所述实体词文本特征预设参考项对所述输出结果进行修正处理,得到所述待识别文本的识别结果,所述实体词文本特征预设参考项用于表征所述待识别文本中实体词前后文本特征。
6.在其中一个实施例中,基于所述实体词文本特征预设参考项对所述输出结果进行修正处理,得到所述待识别文本的识别结果,包括:采用预设词典对所述实体词文本进行修正处理,得到中间结果,所述预设词典包括与所述待识别文本相对应的标准领域分词词典和词频分词词典;基于所述中间结果和待识别文本中实体词前后文本特征,对所述实体类型进行修正处理,得到所述待识别文本的识别结果。
7.在其中一个实施例中,基于所述中间结果和待识别文本中实体词前后文本特征,对所述实体类型进行修正处理,得到所述待识别文本的识别结果,包括:基于所述待识别文本中实体词前后文本特征,确定特征标识和前后文本特征与所述实体词文本之间的结构关系;根据所述特征标识、前后文本特征与所述实体词文本之间的结构关系和所述中间结果,对所述实体类型进行修正处理,得到所述待识别文本的识别结果。
8.在其中一个实施例中,采用预设词典对所述实体词文本进行修正处理,得到中间结果,包括:
按照所述词频分词词典中不同词语的出现频率,对所述实体词文本进行修正;根据所述标准领域分词词典,选择多种待确认分词方式中的一种该方式作为中间结果。
9.在其中一个实施例中,将所述待识别文本输入到实体识别模型进行识别处理,得到所述待识别文本的输出结果,包括:将所述待识别文本输入实体识别模型,通过向量化处理模块得到所述待识别文本的特征向量;将所述特征向量通过特征提取模块进行特征提取,得到所述待识别样本的属性信息,所述属性信息包括待识别样本的词性和语言结构;基于所述待识别样本的属性信息,通过识别模块进行处理,得到所述待识别文本的输出结果。
10.在其中一个实施例中,基于所述待识别样本的属性信息,通过识别模块进行处理,得到所述待识别文本的输出结果,包括:将所述待识别样本的属性信息通过所述识别模块中的全连接层进行处理,得到全连接向量;采用激活函数对所述全连接向量进行处理,得到所述待识别样本的预测结果集合,所述预测结果集合包括多个标签种类;将多个所述预测结果集合中相同标签种类对应的概率值的最大值作为所述待识别文本的输出结果。
11.在其中一个实施例中,所述实体识别模型的训练过程包括:获取历史文本数据,将所述历史文本数据分为训练集和验证集;利用所述训练集对待构建的实体识别模型进行训练,得到待验证的实体识别模型;利用所述验证集中对所述待验证的实体识别模型,按照损失函数最小化对所述待验证的实体识别模型进行优化处理,得到实体识别模型。
12.第二方面,本技术提供了一种命名实体识别装置,该装置包括:获取模块,用于获取待识别文本;识别模块,用于将所述待识别文本输入到训练好的实体识别模型进行识别处理,得到所述待识别文本的输出结果,所述输出结果包括所述待识别文本中的实体类型和实体词文本;修正模块,用于获取实体词文本特征预设参考项并基于所述实体词文本特征预设参考项对所述输出结果进行修正处理,得到所述待识别文本的识别结果,所述实体词文本特征预设参考项用于表征所述待识别文本中实体词前后文本特征。
13.第三方面,本技术实施例提供一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,该处理器执行该程序时实现如上述第一方面的命名实体识别方法。
14.第四方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序用于实现如上第一方面的命名实体识别方法。
15.本技术实施例中提供的命名实体识别方法、装置、设备及存储介质,通过获取待识
别文本,将待识别文本输入到训练好的实体识别模型进行识别处理,得到待识别文本的输出结果,该输出结果包括待识别文本中的实体类型和实体词文本,然后获取实体词文本特征预设参考项并基于实体词文本特征预设参考项对输出结果进行修正处理,得到待识别文本的识别结果,该实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。与现有技术相比,该技术方案一方面,由于通过训练好的实体识别模型进行识别处理,得到输出结果,从而为后续修正处理提供了全面且准确的指导信息,另一方面,通过实体词文本特征预设参考项对输出结果进行修正处理,结合了待识别文本中实体词前后文本特征,进而精准地对于一个语句中存在两个相同文本实体词的情况进行识别,使得能够对待识别文本的命名实体识别的准确度更高。
附图说明
16.通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:图1为本技术实施例提供的命名实体识别的应用系统的系统架构图;图2为本技术实施例提供的命名实体识别方法的流程示意图;图3为本技术实施例提供的命名实体识别的结构示意图;图4为本技术实施例提供的确定待识别文本的识别结果的方法示意图;图5为本技术实施例提供的训练实体识别模型方法的流程示意图;图6为本技术实施例提供的命名实体识别装置的结构示意图;图7为本技术另一实施例提供的命名实体识别装置的结构示意图;图8为本技术实施例示出的一种计算机设备的结构示意图。
具体实施方式
17.下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与发明相关的部分。
18.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。为了便于理解,下面对本技术实施例涉及的一些技术术语进行解释:人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
19.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件主要包括计算机视觉、语音处理技术、自然语言技术以及机器学习/深度学习等几大方向。
20.机器学习(machine learning,ml)是一门多领域交叉学科,涉及概率论、统计学、
逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎么模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习使人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
21.可以理解的是,基于自然语言的人机自动应答系统,是自然语言理解的一个重要应用。命名实体识别是自然语言理解的一个重要组成部分,它主要通过发现和标记自然语言文本中的命名实体。目前,相关技术中采用命名实体识别模型并结合词典修正的方式来实现命名实体识别并输出结果,具体是通过将待识别文本经过命名实体模型进行识别得到模型识别结果,并通过词典对模型识别结果进行修正得到最终的识别结果。然而,对于一个文本语句中存在两个文本内容相同但实体类型不同的实体,采用该方案会仅得到一个任意实体类型的结果,导致得到识别结果准确度低。
22.基于上述缺陷,本技术实施例提供了一种命名实体识别方法、装置、设备及存储介质,与现有技术相比,一方面,由于通过训练好的实体识别模型进行识别处理,得到输出结果,从而为后续修正处理提供了全面且准确的指导信息,另一方面,通过实体词文本特征预设参考项对输出结果进行修正处理,结合了待识别文本中实体词前后文本特征,进而精准地对于一个语句中存在两个相同文本实体词的情况进行识别,使得能够对待识别文本的命名实体识别的准确度更高。
23.本技术实施例提供的方案涉及人工智能的自然语言处理以及机器学习等技术,具体通过下述实施例进行说明。
24.图1是本技术实施例提供的一种命名实体识别方法的实施环境架构图。如图1所示,该实施环境架构包括:终端100和服务器200。
25.终端100可以是各类ai应用场景中的终端设备。例如,终端100可以是智能电视、智能电视机顶盒等智能家居设备,或者终端100可以是智能手机、平板电脑以及电子书阅读器等移动式便携终端,或者,该终端100可以是智能眼镜、智能手表等智能可穿戴设备,本实施例对此不进行具体限定。
26.其中,终端100中可安装有基于自然语言处理的ai应用。比如,该ai应用可以是智能搜索、智能问答等应用。
27.服务器200可以是一台服务器,也可以是由若干台服务器构成的服务器集群,或者服务器200可以包含一个或多个虚拟化平台,或者服务器200可以是一个云计算服务中心。
28.其中,服务器200可以是为上述终端100中安装的ai应用提供后台服务的服务器设备。
29.终端100与服务器200之间通过有线或无线网络建立通信连接。可选的,上述的无线网络或有线网络使用标准通信技术和/或协议。网络通常为因特网、但也可以是任何网络,包括但不限于局域网(local area network,lan)、城域网(metropolitan area network,man)、广域网(wide area network,wan)、移动、有线或者无线网络、专用网络或者虚拟专用网络的任何组合。
30.上述基于自然语言处理的ai应用系统在提供ai应用服务的过程中,可以通过实体识别模型和实体词文本特征预设参考项对待识别文本进行识别,并根据识别结果提供ai应
用服务。其中,上述实体识别模型可以设置在服务器200中,由服务器训练以及应用;或者,上述实体识别模型也可以设置在终端100中,并由服务器200训练及更新。
31.为了便于理解和说明,下面通过图2至图8详细阐述本技术实施例提供的命名实体识别方法、装置、设备及存储介质。
32.图2所示为本技术实施例的命名实体识别方法的流程示意图,该方法可以由计算机设备执行,该计算机设备可以是上述图1所示系统中的服务器200或者终端100,或者,该计算机设备也可以是终端100和服务器200的结合。如图2所示,该方法包括:s101、获取待识别文本。
33.具体的,该待识别文本是指需要进行命名实体识别的文本。其种类可以是一个,也可以是多个,例如该待识别文本可以是用户的某个语句,也可以是某篇文章的内容,其中,待识别文本中可以包括多个字或者多个词,也可以是由一个或者多个词构成的句子、段落。
34.本技术实施例中,上述待识别文本可以通过通过云端获取,也可以是通过数据库或区块链获取,还可以是通过外部设备导入获取待待识别文本。
35.s102、将待识别文本输入到训练好的实体识别模型进行识别处理,得到待识别文本的输出结果,输出结果包括待识别文本中的实体类型和实体词文本。
36.需要说明的是,实体识别模型是通过对样本数据进行训练,从而学习到具备实体类型和实体词文本识别能力的网络结构模型。实体识别模型是输入为待识别文本,输出为包括待识别文本中的实体类型和实体词文本,且具有对待识别文本进行命名实体识别的能力,是能够预测实体类型和实体词文本的神经网络模型。实体识别模型可以包括多层网络结构,不同层的网络结构对输入其的数据进行不同的处理,并将其输出结果传输至下一网络层,直至通过最后一个网络层进行处理,得到输出结果。可选的,上述实体识别模型包括bert模型,其中,bert(bidirectional encoder representation from transformers)模型是一个词向量模型,bert模型能够提取待识别文本的文本信息。
37.其中,上述实体识别模型可以包括:串联相接的输入层、融合层、字嵌入层、卷积层、全连接层、输出层等,每个层对应的功能不同。
38.可选的,在将待识别文本输入至训练好的实体识别模型之前,还可以对待识别文本进行预处理,例如进行分词处理,以确定命名基础。分词的作用是将一句话中的多个字有效的划分为一个或多个词,具体分词的方式较多,可以基于机械匹配法、特征词库法、约束矩阵法、语法分析法等以确定一个或多个词语。
39.在对待识别文本进行预处理,得到预处理后的结果后,然后将其输入训练好的实体识别模型中进行识别处理,具体地,可以通过向量化处理模块得到待识别文本的特征向量,然后将特征向量通过特征提取模块进行特征提取,得到待识别样本的属性信息,该属性信息包括待识别样本的词性和语言结构,并基于待识别样本的属性信息,通过识别模块进行处理,得到待识别文本的输出结果。
40.本技术实施例中,上述向量化处理模块用于将不同的分词进行向量化处理,得到对应的特征向量,然后将特征向量通过特征提取模块进行特征提取,得到待识别样本的属性信息。上述特征提取模块可以把抽象存在的文字转换为数学公式操作的向量,充分描述字符级、词级、句子级甚至句间关系特征。上述识别模块可以包括全连接层和激活函数,能够对特征提取模块输出的待识别文本的属性信息进行分类,从而得到待识别文本的输出结
果,该预测结果为待识别文本对应的实体类型,还可以包括实体词文本。其中,上述属性信息包括待识别文本的词性和语言结构。
41.其中,向量化处理模块为将语义空间关系转化为向量空间关系,即将语义文本转化为计算机设备能够进行处理的向量。
42.具体的,在获取到待识别文本并对其进行预处理得到待识别文本的字或词后,可以将该待识别文本的字或词输入到训练好的实体识别模型中,通过向量化处理模块得到待识别文本的特征向量,然后通过特征提取模块进行特征提取,得到待识别文本的属性信息,并将待识别样本的属性信息通过识别模块中的全连接层进行处理,得到全连接向量,采用激活函数对全连接向量进行处理,得到待识别样本的预测结果集合,预测结果集合包括多个标签种类,将多个预测结果集合中相同标签种类对应的概率值的最大值作为待识别文本的输出结果。可选的,可以将该预测结果集合中的标签种类对应的概率值进行从大到小排序,取其最大值为该待识别文本的标签种类。
43.具体的,该识别模块可以包括但不限于全连接层和激活函数。全连接层可以包括一层,或者也可以包括多层。全连接层主要是用于对待识别文本的属性信息进行分类的作用。
44.其中,上述激活函数可以是softmax函数,激活函数的作用是用来加入非线性因素,因为线性模型的表达能力不够,能够把输入的连续实值变换为0和1之间的输出。
45.本技术实施例中通过获取待识别文本,并将待识别文本输入到训练好的实体识别模型进行识别处理,从而得到包括待识别文本中的实体类型和实体词文本的输出结果,能够为后续修正处理提供全面且准确的指导信息。
46.s103、获取实体词文本特征预设参考项并基于实体词文本特征预设参考项对输出结果进行修正处理,得到待识别文本的识别结果,实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。
47.需要说明的是,上述实体词文本特征预设参考项是指待识别文本中实体词相关的特征。其中,该实体词文本特征预设参考项可以包括待识别文本中实体词前后文本特征,以及待识别文本中实体词前后文本与实体词之间的关系。
48.其中,上述待识别文本中实体词前后文本特征可以包括前后文本类型、前后文本特征标识等。
49.进一步地,请参见图3所示,可以获取待识别文本3-1,将待识别文本3-1输入到训练好的实体识别模型3-2进行识别处理,得到待识别文本的输出结果3-3,并获取实体词文本特征预设参考项3-4并基于实体词文本特征预设参考项3-4对输出结果3-3进行修正处理,得到待识别文本的识别结果3-5,实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。
50.进一步地,在上述实施例的基础上,图4为本技术实施例提供的命名实体识别方法的流程示意图,该命名实体识别方法可以应用于计算机设备,如图4所示,该文本分类方法可以包括以下步骤:s201、采用预设词典对实体词文本进行修正处理,得到中间结果,预设词典包括与待识别文本相对应的标准领域分词词典和词频分词词典。
51.上述预设词典可以是记载有待识别词语单位的参考命名词典,参考命名词典可以
理解为命名实体识别词典,通常,参考命名词典可以是预先准备多个,且这些参考命名词典均是不同领域的,或者是同一领域中收集了不同方面的词语。通过使用不同类别的参考命名词典,能够使一个句子(预先获取的待识别文本)得到充分的分析,从而使得确定的命名实体识别结果更为精确。并且可以通过对不同领域的命名实体识别词典进行多级的划分,实现更为精确的识别。例如,可以将实体识别词典分为自然科学和社会科学,还可以将命名实体词典的自然科学种类分为生物、电学、化学等。在确认记载有待识别词语单位的参考命名词典的时候,可以根据待识别词语单位在某个词典中的出现频率来确定是否使用这个领域的词典作为“记载有待识别文本的参考命名词典”。
52.上述标准领域词典是由使用者提供的,是根据不同领域对应的实体词预先设置的词典。例如可以包括采矿领域、仪器测试领域、航空航天领域、工业制造领域、电影电视领域、文学作品领域等。
53.在采用预设词典对实体词文本进行修正处理时,可以按照词频分词词典中不同词语的出现频率,对实体词文本进行修正,并根据标准领域分词词典,选择多重待确认分词方式中的一种方式作为中间结果。
54.s202、基于中间结果和待识别文本中实体词前后文本特征,对实体类型进行修正处理,得到待识别文本的识别结果。
55.具体的,在确定出中间结果后,可以基于待识别文本中实体词前后文本特征,确定特征标识和前后文本特征与所述实体词文本之间的结构关系,并根据特征标识、实体词文本之间的结构关系和中间结果,对实体类型进行修正处理,得到待识别文本的识别结果。
56.其中,在基于根据特征标识、实体词文本之间的结构关系和中间结果的过程中,例如当对同一实体词文本确定出的实体类型包括时间实体和影片名实体两个实体类型时,且确定出的时间实体的前后文本特征中对应的实体词前后文本类型为动词类型,而确定出的影片名实体对应的实体词前后文本类型为名词类型,从而根据处理规则将多余的实体类型对应的实体词文本删除,得到需要的实体类型对应的实体词文本,进而得到待识别文本的识别结果。
57.需要说明的是,上述处理规则可以是用户预先根据实际需求自定义设置的,例如可以是仅需识别电影名实体,还可以是仅需识别天气实体,也可以是仅需识别出时间实体等。
58.示例性地,获取的待识别文本为“后天去看电影后天”,然后采用预设分词算法对其进行分词处理,得到分词结果,该分词结果例如是“后天”、“去”、“看”、“电影”,并将分词结果输入训练好的实体识别模型进行识别处理,得到输出结果,该输出结果包括待识别文本中的实体类型和实体词文本,其中,实体类型包括时间实体和电影名实体,实体词包括“后天”。然后采用预设词典对实体词文本进行修正处理,得到中间结果,并基于待识别文本中实体词前后文本特征,该前后文本特征包括实体词前后文本特征“去”和“电影”,确定特征标识和前后文本特征与所述实体词文本之间的结构关系,即“去”对应的特征标识为动词类型,“电影”对应的特征标识为名词类型,根据用户预设的需求对实体类型通过算法进行匹配和对比修正处理,得到待识别文本的识别结果,例如对于时间实体“后天”和影片名实体“后天”,对于观影意图而言实际只需要识别出后面的后即可,即确定出影片名实体“后天”为待识别文本的识别结果。
59.本技术实施例中提供的命名实体识别方法,通过获取待识别文本,将待识别文本输入到训练好的实体识别模型进行识别处理,得到待识别文本的输出结果,该输出结果包括待识别文本中的实体类型和实体词文本,然后获取实体词文本特征预设参考项并基于实体词文本特征预设参考项对输出结果进行修正处理,得到待识别文本的识别结果,该实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。与现有技术相比,该技术方案一方面,由于通过训练好的实体识别模型进行识别处理,得到输出结果,从而为后续修正处理提供了全面且准确的指导信息,另一方面,通过实体词文本特征预设参考项对输出结果进行修正处理,结合了待识别文本中实体词前后文本特征,进而精准地对于一个语句中存在两个相同文本实体词的情况进行识别,使得能够对待识别文本的命名实体识别的准确度更高。
60.在其中一个实施例中,上述实施例中确定输出结果时包括预先训练好的实体识别模型,以下为对实体识别模型的训练过程的训练过程的描述。请参考图5,该方法可以包括:s301、获取历史文本数据,将历史文本数据分为训练集和验证集。
61.需要说明的是,上述该历史文本数据可以是多个,也可以是一个,其中,每个历史文本数据可以包括至少一个字或词,例如该历史文本数据可以包括多个字或词。
62.具体的,在获取到历史文本数据后,可以将历史文本数据按照一定比例随机分为训练集和验证集,其中,训练集用于对初始实体识别模型进行训练,以得到训练好的实体识别模型,验证集用于对训练好的实体识别模型进行验证,以验证实体识别模型性能的好坏。
63.s302、利用训练集对待构建的实体识别模型进行训练,得到待验证的实体识别模型。
64.s303、利用验证集中对待验证的实体识别模型,按照损失函数最小化对待验证的实体识别模型进行优化处理,得到实体识别模型。
65.在将历史文本数据分为训练集和验证集之后,将训练集输入待构建的实体识别模型中,该待构建的实体识别模型包括多个相连的向量化处理模块、特征提取模块和识别模块,可以先对训练集通过特征向量化处理模块进行处理得到初始词向量,并将初始词向量输入至待构建的实体识别模型中的特征提取模块中,得到对应的结果,并将该结果输入至识别模块中,从而得到待识别文本的输出结果。利用训练集对待构建的向量化处理模块、特征提取模块和识别模块进行训练,得到待验证的向量化处理模块、特征提取模块和识别模块。
66.计算机设备在训练实体识别模型的过程中,利用验证集中对待验证的向量化处理模块、特征提取模块和识别模块,按照损失函数最小化对待验证的向量化处理模块、特征提取模块和识别模块进行优化处理,得到向量化处理模块、特征提取模块和识别模块,根据该验证集输入待验证的实体识别模型中得到的结果和标注结果之间的差异,对待构建的实体识别模型中的参数进行更新,以实现对实体识别模型进行训练的目的,其中,上述标注结果可以是人工对历史文本数据进行标注得到的结果,可以包括历史文本数据对应的实体类型和实体词文本。
67.可选的,上述对待验证的实体识别模型中的参数进行更新,可以是对待构建的实体识别模型中的权重矩阵以及偏置矩阵等矩阵参数进行更新。其中,上述权重矩阵、偏置矩阵包括但不限于是待验证的实体识别模型中的自注意力层、前馈网络层、全连接层中的矩
阵参数。
68.本技术实施例中,可以使用损失函数计算验证集输入待验证的实体识别模型中得到的结果和标签结果的损失值,从而对待验证的实体识别模型中的参数进行更新。可选的,损失函数可以使用交叉熵损失函数,归一化交叉熵损失函数,其中,通过损失函数对待验证的实体识别模型中的参数进行更新时,可以是根据损失函数确定待验证的实体识别模型未收敛时,通过调整模型中的参数,以使得待验证的实体识别模型收敛,从而得到实体识别模型。待验证的实体识别模型收敛,可以是指待验证的实体识别模型对验证集的输出结果与训练数据的标注结果之间的差值小于预设阈值,或者,输出结果与训练数据的标注结果之间的差值的变化率趋近于某一个较低值。当计算的损失函数较小,或者,与上一轮迭代输出的损失函数之间的差值趋近于0,则认为待验证的实体识别模型收敛。
69.本实施例中通过训练实体识别模型,使得待识别文本能够通过训练好的实体识别模型进行识别处理,从而能够精准地得到待识别文本的输出结果,从而为后续修正处理提供了全面且精准的指导信息。
70.另一方面,图6为本技术实施例提供的一种命名实体识别装置的结构示意图。该装置可以为终端或服务器内的装置,如图6所示,该装置700包括:获取模块710,用于获取待识别文本;识别模块720,用于将待识别文本输入到训练好的实体识别模型进行识别处理,得到待识别文本的输出结果,输出结果包括待识别文本中的实体类型和实体词文本;修正模块730,用于获取实体词文本特征预设参考项并基于实体词文本特征预设参考项对输出结果进行修正处理,得到待识别文本的识别结果,实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。
71.可选的,请参见图7所示,上述修正模块730,包括:第一修正单元731,用于采用预设词典对实体词文本进行修正处理,得到中间结果,预设词典包括与待识别文本相对应的标准领域分词词典和词频分词词典;第二修正单元732,用于基于中间结果和待识别文本中实体词前后文本特征,对实体类型进行修正处理,得到待识别文本的识别结果。
72.可选的,上述第二修正单元732,具体用于:基于待识别文本中实体词前后文本特征,确定特征标识和前后文本特征与实体词文本之间的结构关系;根据特征标识、实体词文本之间的结构关系和中间结果,对实体类型进行修正处理,得到待识别文本的识别结果。
73.可选的,上述第一修正单元731,具体用于:按照词频分词词典中不同词语的出现频率,对实体词文本进行修正;根据标准领域分词词典,选择多种待确认分词方式中的一种该方式作为中间结果。
74.可选的,上述识别模块720,具体用于:将待识别文本输入实体识别模型,通过向量化处理模块得到待识别文本的特征向量;
将特征向量通过特征提取模块进行特征提取,得到待识别样本的属性信息,属性信息包括待识别样本的词性和语言结构;基于待识别样本的属性信息,通过识别模块进行处理,得到待识别文本的输出结果。
75.可选的,上述识别模块720,还用于:将待识别样本的属性信息通过识别模块中的全连接层进行处理,得到全连接向量;采用激活函数对全连接向量进行处理,得到待识别样本的预测结果集合,预测结果集合包括多个标签种类;将多个预测结果集合中相同标签种类对应的概率值的最大值作为待识别文本的输出结果。
76.可选的,上述实体识别模型的训练过程包括:获取历史文本数据,将历史文本数据分为训练集和验证集;利用训练集对待构建的实体识别模型进行训练,得到待验证的实体识别模型;利用验证集中对待验证的实体识别模型,按照损失函数最小化对待验证的实体识别模型进行优化处理,得到实体识别模型。
77.可以理解的是,本实施例的命名实体识别装置的各功能模块的功能可根据上述方法实施例中的方法具体实现,其具体实现过程可以参照上述方法实施例的相关描述,在此不再赘述。
78.综上所述,本技术实施例提供的命名实体识别装置,一方面,由于通过训练好的实体识别模型进行识别处理,得到输出结果,从而为后续修正处理提供了全面且准确的指导信息,另一方面,通过实体词文本特征预设参考项对输出结果进行修正处理,结合了待识别文本中实体词前后文本特征,进而精准地对于一个语句中存在两个相同文本实体词的情况进行识别,使得能够对待识别文本的命名实体识别的准确度更高。
79.另一方面,本技术实施例提供的计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,该处理器执行该程序时实现如上述的命名实体识别方法。
80.下面参考图8,图8为本技术实施例的终端设备的计算机系统的结构示意图。
81.如图8所示,计算机系统300包括中央处理单元(cpu)301,其可以根据存储在只读存储器(rom)302中的程序或者从存储部分303加载到随机访问存储器(ram)303中的程序而执行各种适当的动作和处理。在ram 303中,还存储有系统300操作所需的各种程序和数据。cpu 301、rom 302以及ram 303通过总线304彼此相连。输入/输出(i/o)接口305也连接至总线304。
82.以下部件连接至i/o接口305:包括键盘、鼠标等的输入部分306;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分307;包括硬盘等的存储部分308;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分309。通信部分309经由诸如因特网的网络执行通信处理。驱动器310也根据需要连接至i/o接口305。可拆卸介质311,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器310上,以便于从其上读出的计算机程序根据需要被安装入存储部分308。
83.特别地,根据本技术的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本技术的实施例包括一种计算机程序产品,其包括承载在机器可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分303从网络上被下载和安装,和/或从可拆卸介质311被安装。在该计算机程序被中央处理单元(cpu)301执行时,执行本技术的系统中限定的上述功能。
84.需要说明的是,本技术所示的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本技术中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本技术中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
85.附图中的流程图和框图,图示了按照本技术各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,前述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
86.描述于本技术实施例中所涉及到的单元或模块可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的单元或模块也可以设置在处理器中,例如,可以描述为:一种处理器,包括:获取模块、识别模块和修正模块。其中,这些单元或模块的名称在某种情况下并不构成对该单元或模块本身的限定,例如,获取模块还可以被描述为“用于获取待识别文本”。
87.作为另一方面,本技术还提供了一种计算机可读存储介质,该计算机可读存储介质可以是上述实施例中描述的电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中的。上述计算机可读存储介质存储有一个或者多个程序,当上述前述程序被一个或者一个以上的处理器用来执行描述于本技术的命名实体识别方法:
获取待识别文本;将所述待识别文本输入到训练好的实体识别模型进行识别处理,得到所述待识别文本的输出结果,所述输出结果包括所述待识别文本中的实体类型和实体词文本;获取实体词文本特征预设参考项并基于所述实体词文本特征预设参考项对所述输出结果进行修正处理,得到所述待识别文本的识别结果,所述实体词文本特征预设参考项用于表征所述待识别文本中实体词前后文本特征。
88.综上所述,本技术实施例中提供的命名实体识别方法、装置、设备及存储介质,通过获取待识别文本,将待识别文本输入到训练好的实体识别模型进行识别处理,得到待识别文本的输出结果,该输出结果包括待识别文本中的实体类型和实体词文本,然后获取实体词文本特征预设参考项并基于实体词文本特征预设参考项对输出结果进行修正处理,得到待识别文本的识别结果,该实体词文本特征预设参考项用于表征待识别文本中实体词前后文本特征。与现有技术相比,该技术方案一方面,由于通过训练好的实体识别模型进行识别处理,得到输出结果,从而为后续修正处理提供了全面且准确的指导信息,另一方面,通过实体词文本特征预设参考项对输出结果进行修正处理,结合了待识别文本中实体词前后文本特征,进而精准地对于一个语句中存在两个相同文本实体词的情况进行识别,使得能够对待识别文本的命名实体识别的准确度更高。
89.以上描述仅为本技术的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本技术中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本技术中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。