一种基于gpu的乘客实时交互处理方法和系统
技术领域
1.本发明涉及乘客实时交互领域,尤其涉及一种基于gpu的乘客实时交互处理方法和系统。
背景技术:
2.当前,随着城市轨道交通的快速发展,乘客的出行服务需求日益增加;现有技术虽然有针对公共场所异常声音的识别与定位技术,可通过判定公共场所是否存在异常声音,对大范围、大量乘客进行识别分析并提供服务,但其只能识别枪声、爆炸声、玻璃碎声和尖叫声等异常声音,无法为乘客提供其他方面的需求服务,而现有其他技术均不能满足大量乘客的实时交互,现有技术只能在站内为乘客提供服务,不能提供全出行链的乘客服务。
技术实现要素:
3.针对现有技术的不足,本技术提出了一种基于gpu的乘客实时交互处理方法和系统,现介绍如下:
4.第一方面,提出了一种基于gpu的乘客实时交互处理方法,包括步骤如下:
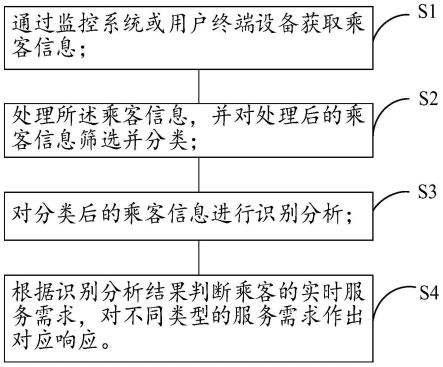
5.步骤s1:通过监控系统或用户终端设备获取乘客信息;
6.步骤s2:处理所述乘客信息,并对处理后的乘客信息筛选并分类;
7.步骤s3:对分类后的乘客信息进行识别分析;
8.步骤s4:根据识别分析结果判断乘客的实时服务需求,对不同类型的服务需求作出对应响应。
9.进一步地,所述对处理后的乘客信息筛选并分类,具体包括:
10.对视频信息通过空域滤波的方法筛选出破损严重、无法识别信息,并通过结合周围像素生成当前像素的值处理所述破损严重、无法识别的信息;
11.对声音信息通过基于声音信息和噪声信息之间的不同特征对两者进行区分。
12.进一步地,所述对分类后的乘客信息进行识别分析包括行为信息识别分析、声音信息识别分析与关键词信息识别分析。
13.所述行为信息识别分析为对分类后的视频信息中的乘客行为信息进行识别分析,以预设的各类异常行为标准对分类后的所述乘客行为信息进行预判断,将预判断为异常的所述乘客行为信息输入对应识别该异常行为的训练后的子深度神经网络,得到异常行为识别结果。
14.进一步地,所述声音信息识别分析具体包括:
15.对分类后得到的声音信息中的环境声音进行识别分析;
16.通过双阈值算法和welch法功率谱估计算法来判定所述环境声音中是否存在异常声音;
17.将异常声音的特征时序信号转换为时频域的谱图;
18.利用异常声音识别技术对所述时频域的谱图进行分类提取和识别分析,得到声音
信息识别结果。
19.进一步地,所述关键词信息识别分析是对分类后得到的乘客信息中具有预设关键词的信息进行识别分析。
20.进一步地,所述子深度神经网络的生成包括如下步骤:
21.步骤s101:获取与乘客行为相关的视频图像信息,然后将所述视频图像信息进行预处理,将预处理后得到的含有异常行为的视频图像信息作为训练特征数据;
22.步骤s102:根据所述训练特征数据对深度神经网络进行训练,得到所述训练特征数据对应的异常判定阈值;
23.步骤s103:计算预设定的目标判定阈值与异常判定阈值之间的实际偏差,并根据所述实际偏差对深度神经网络中的参数进行调整,直至所述实际偏差达到目标阈值,完成训练得到训练后的深度神经网络,所述深度神经网络中包括多个分别与各异常行为对应的子深度神经网络。
24.进一步地,利用异常声音识别技术对所述时频域的谱图进行识别分析,得到声音信息识别结果包括如下步骤:
25.步骤s201:对判定为异常声音的时序信号进行短时傅里叶变换,得到异常声音频谱图;
26.其中,傅里叶变换的长度为2nf点,使得每一帧的信号频谱为傅里叶变换的长度,其声压值为:
27.pdb=20
×
log
10
|x(1:cnf))|
28.式中,nf为傅里叶变换的长度,x为异常声音时序信号的频谱值,pdb表示异常声音时序信号的声压值;
29.步骤s202:将所述异常声音频谱图沿频率轴切分成nb个图像块,将每个异常声音样本的图像块通过列堆栈转换为向量,并把所有异常声音样本得到的向量合并成为矩阵x,x∈rm×n,其中m是每个异常声音样本图像块的大小,n表示异常声音样本的数量;
30.步骤s203:将训练样本矩阵x
′
作为独立成分分析的输入矩阵,分析后得到分离矩阵w,然后将训练样本矩阵x
′
投影到分离矩阵w张成的子空间构成稀疏分解的冗余字典a;
31.步骤s204:将所述训练样本信号向分离矩阵w张成的子空间投影得到y,则训练样本的稀疏特征由冗余字典a中原子线性表示为:
[0032][0033]
计算残差得到训练样本的类别结果:
[0034][0035]
上式中y为训练样本频谱图投影到分离矩阵w张成的子空间的表示,表示训练样本优化结果中第i个训练样本的系数,而表示由第i个训练样本重建的稀疏特征则ri表示矩阵x
′
对应的训练样本与第i个训练样本的差距;
[0036]
步骤s205:判定y与的差距是否小于等于第一阈值,若是,则判定第i个训练样本与待识别训练样本一致,训练样本识别成功。
[0037]
进一步地,将所述视频图像信息进行预处理,具体步骤包括:
[0038]
步骤s301:分别对每一帧视频图像信息中的所有乘客提取人体骨骼关键点;
[0039]
步骤s302:通过分析处理前后帧视频图像信息之间每个人体骨骼关键点的坐标变化,以此获取到乘客的动作信息;
[0040]
步骤s303:对所述乘客的动作信息进行分析判断,若判断出所述乘客的动作信息属于异常行为信息,则提取出含有异常行为信息的视频图像信息。
[0041]
第二方面,提出了一种基于gpu的乘客实时交互处理系统,包括:信息获取模块、信息处理模块、信息识别分析模块、需求响应模块,所述模块依次顺序连接;
[0042]
所述信息获取模块,用于通过监控系统或用户终端设备获取乘客信息;
[0043]
所述信息处理模块,用于处理所述乘客信息,并对处理后的乘客信息筛选并分类;
[0044]
所述信息识别分析模块,用于对分类后的乘客信息进行识别分析;
[0045]
所述需求响应模块,用于根据识别分析结果判断乘客的实时服务需求,对不同类型的服务需求作出对应响应。
[0046]
有益技术效果:
[0047]
为了满足当下日益增加的客户出行需求服务,本技术提出了一种基于gpu的乘客实时交互处理系统及方法,作为一种基于乘客智能感知与乘客智能交互的系统来分析乘客的出行服务需求,本技术实现了实时的、全出行链的乘客服务;其通过不同的算法对不同的乘客信息进行识别分析,提高了识别精度,能更精准的为乘客提供服务;通过算法的优化和硬件的提升,本技术在满足大量乘客的服务需求时做到了实时交互效率上的大幅提升。
附图说明
[0048]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0049]
图1为本发明实施例所示的一种基于gpu的乘客实时交互处理方法的流程示意图;
[0050]
图2为本发明实施例所示的一种基于gpu的乘客实时交互处理系统的原理框图。
具体实施方式
[0051]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0052]
针对当下日益增加的乘客出行服务需求,还没有一种方法实现针对大范围大量乘客实时的、全出行链的乘客服务,本技术方案是一种基于声音智能分析、视频智能分析的乘客智能感知,以及基于移动互联终端、机器人、多功能智能互动终端等的乘客智能交互,来分析乘客的出行服务需求,配置gpu(graphics processing unit,图形处理器)进行数据的快速处理,以提供秒级的乘客服务需求响应的发明。
[0053]
第一方面,本发明实施例提供了一种基于gpu的乘客实时交互处理方法,如图1所
示,包括步骤如下:
[0054]
步骤s1:通过监控系统或用户终端设备获取乘客信息;
[0055]
步骤s2:处理所述乘客信息,并对处理后的乘客信息筛选并分类;
[0056]
步骤s3:对分类后的乘客信息进行识别分析;
[0057]
步骤s4:根据识别分析结果判断乘客的实时服务需求,对不同类型的服务需求作出对应响应。
[0058]
在步骤s1中,通过监控系统或用户终端设备获取乘客信息,具体到本实施例,主要通过城市轨道交通站内的监控系统以及乘客的手机等设备来获取关于乘客的视频、声音等信息;通过对移动互联终端、机器人、多功能智能交互终端的数据进行挖掘来获取乘客的搜索词/关键词、车/机票等信息。
[0059]
在步骤s2中,具体到本实施例,首先分别处理获取到的乘客信息;
[0060]
优选的,具体处理内容包括将乘客信息格式标准化、删除重复乘客信息、储存乘客信息;
[0061]
其次将处理后的乘客信息进行筛选;
[0062]
优选的,本实施例通过去除噪声信息进行筛选,具体包括:
[0063]
对视频信息通过空域滤波的方法筛选出破损严重、无法识别信息,并通过结合周围像素生成当前像素的值处理所述破损严重、无法识别的信息;
[0064]
所述空域滤波技术是本领域技术人员常规技术手段,本实施例不再赘述;
[0065]
对声音信息通过基于声音信息和噪声信息之间的不同特征对两者进行区分,本实施例中通过采用lstm(long short-term memory,长短期记忆网络)网络模型区分声音信息中的噪声信息,并去除所述噪声信息;所述lstm网络模型也是本领域技术人员常规技术手段,此处不再赘述;
[0066]
最后对处理后的乘客信息进行分类;
[0067]
优选的,本实施例主要将视频信息、声音信息、搜索词和车票信息等进行区分。
[0068]
在步骤s3中,对分类后的乘客信息进行识别分析,具体到本实施例,所述对分类后的乘客信息进行识别分析包括行为信息识别分析、声音信息识别分析与关键词信息识别分析。
[0069]
本实施例中,所述行为信息识别分析为对分类后的视频信息中的乘客行为信息进行识别分析,以预设的各类异常行为标准对分类后的所述乘客行为信息进行预判断,将预判断为异常的所述乘客行为信息输入对应识别该异常行为的训练后的子深度神经网络,得到异常行为识别结果。
[0070]
进一步地,所述子深度神经网络的生成包括如下步骤:
[0071]
步骤s101:获取与乘客行为相关的视频图像信息,然后将所述视频图像信息进行预处理,将预处理后得到的含有异常行为的视频图像信息作为训练特征数据;
[0072]
步骤s102:根据所述训练特征数据对深度神经网络进行训练,得到所述训练特征数据对应的异常判定阈值;
[0073]
步骤s103:计算预设定的目标判定阈值与异常判定阈值之间的实际偏差,并根据所述实际偏差对深度神经网络中的参数进行调整,直至所述实际偏差达到0.1,完成训练得到训练后的深度神经网络,所述深度神经网络中包括多个分别与各异常行为对应的子深度
神经网络。
[0074]
具体到本实施例中进行识别的子深度神经网络是通过获取与乘客行为相关的实时视频图像数据,然后将实时视频图像数据进行预处理,将得到的含有异常行为的乘客行为视频图像数据作为对应的训练特征数据;
[0075]
根据训练特征数据对深度神经网络进行训练,得到训练特征数据对应的异常判定阈值,本实施例异常判定阈值是训练集自身的y,所述训练集为大量视频图像信息组成;
[0076]
计算预设定的目标判定阈值与异常判定阈值之间的实际偏差,所述预设定的目标判定阈值在本实施例中为在训练集得到的网络里输入第i个训练样本对应的矩阵后得到的y,并根据所述实际偏差对所述深度神经网络中的参数进行调整;直至实际偏差达到0.1,完成训练得到训练后的深度神经网络,得到与各异常行为对应的所述训练后的深度神经网络中的子深度神经网络。
[0077]
在任一基于本方法的实施例中,应该理解的是所述子深度神经网络分别与各个异常行为进行对应,包括但不限于与抽烟、斗殴、呼救、攀爬扶梯、扒门等行为对应的子深度神经网络。
[0078]
进一步的,应该理解到处理视频图像数据,就是将可能含有异常行为的视频信息提取。
[0079]
进一步地,将所述视频图像信息进行预处理,具体步骤为:
[0080]
步骤s301:分别对每一帧视频图像信息中的所有乘客提取人体骨骼关键点;
[0081]
步骤s302:通过分析处理前后帧视频图像信息之间每个人体骨骼关键点的坐标变化,以此获取到乘客的动作信息;
[0082]
步骤s303:对所述乘客的动作信息进行分析判断,若判断出所述乘客的动作信息属于异常行为信息,则提取出含有异常行为信息的视频图像信息。
[0083]
本实施例中,所述将视频图像数据进行预处理是在获取到实时视频图像之后,分别对每一帧图像中的所有乘客,提取人体骨骼关键点;通过分析处理前后帧图像之间每个人体骨骼关键点的坐标变化,获取到乘客的动作信息,进而判断是否发生异常行为,具体就是当乘客的骨骼关键点坐标变化至与预设的“呼救”、“抽烟”等异常行为一致时被认定为异常;并提取可能含有异常行为的视频图像信息,本实施例中就是将判定为异常行为的视频信息保存,待进一步处理。
[0084]
进一步地,所述声音信息识别分析具体包括:
[0085]
对分类后得到的声音信息中的环境声音进行识别分析;
[0086]
通过双阈值算法和welch法功率谱估计算法来判定所述环境声音中是否存在异常声音;
[0087]
将异常声音的特征时序信号转换为时频域的谱图;
[0088]
利用异常声音识别技术对所述时频域的谱图进行分类提取和识别分析,得到声音信息识别结果。
[0089]
进一步地,利用异常声音识别技术对所述时频域的谱图进行识别分析,得到声音信息识别结果包括如下步骤:
[0090]
步骤s201:对判定为异常声音的时序信号进行短时傅里叶变换,得到异常声音频谱图;
[0091]
其中,傅里叶变换的长度为2nf点,使得每一帧的信号频谱为傅里叶变换的长度,其声压值为:
[0092]
pdb=20
×
log
10
|x(1:(nf))|
[0093]
式中,nf为傅里叶变换的长度,x为异常声音时序信号的频谱值,pdb表示异常声音信号的声压值;
[0094]
步骤s202:将所述异常声音频谱图沿频率轴切分成nb个图像块,将每个异常声音样本的图像块通过列堆栈转换为向量,并把所有异常声音样本得到的向量合并成为矩阵x∈rm×n,其中m是每个异常声音样本频谱图的大小,n表示异常声音样本的数量;nb为切分的图像块数量,nf为傅里叶变化的长度,r为实数空间。
[0095]
步骤s203:将训练样本矩阵x
′
作为独立成分分析的输入矩阵,分析后得到分离矩阵w,然后将训练样本矩阵x
′
投影到分离矩阵w张成的子空间构成稀疏分解的冗余字典a;
[0096]
步骤s204:将所述训练样本信号向分离矩阵w张成的子空间投影得到y,则训练样本的稀疏特征由冗余字典a中原子线性表示为:
[0097][0098]
为满足ax
′
=y约束下最小的元素模值;
[0099]
计算残差得到训练样本的类别结果:
[0100][0101]
上式中y为训练样本频谱图投影到分离矩阵w张成的子空间的表示,表示训练样本优化结果中第i个训练样本的系数,而表示由第i个训练样本重建的稀疏特征则ri表示矩阵x
′
对应的训练样本与第i个训练样本的差距;
[0102]
步骤s205:判定y与的差距是否小于等于第一阈值,若是,则判定第i个训练样本与待识别训练样本一致,训练样本识别成功。
[0103]
本实施例声音信息识别分析是通过双阈值算法和welch(韦尔奇)法估计功率谱来判定声音信息是否存在异常声音;所述双阈值算法和welch(韦尔奇)法均为本领域技术人员所用常规技术,此处不再赘述。
[0104]
然后将异常声音特征时序信号转换为时频域的谱图,利用听觉感知的稀疏编码声音识别技术解决异常声音的特征提取及分类识别问题,
[0105]
异常声音识别方法为通过独立成分分析((independent component analysis,ica)、稀疏表达分类(sparse representation-based classifier,src)等图像处理方法对异常声音进行分类识别,具体步骤如下:
[0106]
①
对异常声音的时序信号进行短时傅里叶变换(short-time fourier transform,stft)。使用汉明窗作为滑动窗,傅里叶变换的长度为2nf点,这样就可以得到长度为傅里叶变换长度的的每一帧的信号频谱,其声压值为:
[0107]
pdb=20
×
log
10
|x(1:(nf))|;
[0108]
式中,nf为傅里叶变换的长度,x为异常声音时序信号的频谱值,pdb表示异常声音
时序信号的声压值;
[0109]
②
将异常声音的频谱图沿频率轴切分成nb个图像块。将每个异常声音样本的图像块通过列堆栈转换为向量,并把所有异常声音样本得到的向量合并成为矩阵x∈rm×n,其中m是每个异常声音样本频谱图的大小,n表示异常声音样本的数量。
[0110]
③
将训练样本矩阵x
′
作为独立成分分析的输入矩阵,分析后得到分离矩阵w,然后将训练样本矩阵x
′
投影到分离矩阵w张成的子空间构成稀疏分解的冗余字典a。其中独立成分分析,就是一种将多元信号分离为加性子分量的方法;具体做法就是先标准化,即对输入数据,本示例为训练样本矩阵x
′
,进行去除均值处理,再白化;即对x
′
进行主成分分析处理,然后对其进行白化。
[0111]
④
将系统检测到的训练样本经过步骤
①
的频谱图转换后向分离矩阵w张成的子空间投影得到y,则训练样本的稀疏特征由冗余字典a中原子线性表示为:
[0112][0113]
计算残差得到训练样本的类别结果:
[0114][0115]
上式中y为训练样本频谱图投影到分离矩阵w张成的子空间的表示,表示训练样本优化结果中第i个训练样本的系数,而则表示由第i个训练样本重建的稀疏特征则ri表示矩阵x
′
对应的训练样本与第i个训练样本的差距,j为训练样本的数量。
[0116]
⑤
判定y与的差距是否小于等于第一阈值,本实施例第一阈值设置为-0.0864,若是,则得到判定结果,判定异常声音样本i与待识别样本一致,异常声音识别成功。
[0117]
由
④
可知y与的差距越小,i与待识别样本就越接近。
[0118]
进一步地,所述关键词信息识别分析是对分类后得到的乘客信息中具有预设关键词的信息进行识别分析。
[0119]
本实施例中所谓的关键词信息识别分析主要是对分类后的搜索词、车票等信息中具有xx站、卫生间、帮助等预设关键词的信息进行识别分析,通过大数据分析来识别出乘客的服务需求,得到识别结果。
[0120]
应该理解的是所述识别结果包括但不限于车站换乘、卫生间导航、特殊通道(如无障碍坡道)位置、工作人员帮助等。
[0121]
第二方面,本发明实施例提出了一种基于gpu的乘客实时交互处理系统,这是一种基于乘客智能感知与乘客智能交互的系统,通过分析乘客的出行服务需求实时提供响应完成与乘客的智能交互。包括:信息获取模块、信息处理模块、信息识别分析模块、需求响应模块,所述模块依次顺序连接;
[0122]
所述信息获取模块,用于通过监控系统或用户终端设备获取乘客信息;
[0123]
所述信息处理模块,用于处理所述乘客信息,并对处理后的乘客信息筛选并分类;
[0124]
所述信息识别分析模块,用于对分类后的乘客信息进行识别分析;
[0125]
所述需求响应模块,用于根据识别分析结果判断乘客的实时服务需求,对不同类
型的服务需求作出对应响应。
[0126]
应该理解的是在应用本系统的具体实施例中所述响应包括但不限于手机信息弹窗、工作人员帮助、警报系统、站内广播等,由此完成为乘客提供实时的、全出行链的服务。
[0127]
本发明基于乘客智能感知与乘客智能交互,相较于现有技术单一的对乘客行为或声音进行识别分析,本发明通过对乘客的行为、声音、位置和搜索关键词等实时信息进行获取,依靠深度神经网络、声音识别技术、数据挖掘和大数据分析技术的融合,配置gpu对获取到的乘客实时信息进行快速处理、识别、分析,实时精确地判断大量乘客多样化的服务需求,实现在1秒内完成对乘客服务需求的响应。同时,通过对各类信息的获取,本发明可分析出乘客更多类型、更加精确的服务需求,为乘客提供全出行链的服务。相较于现有技术仅能对抽烟、斗殴、呼救、攀爬扶梯等行为信息进行识别,本发明可在实现上述行为识别的基础上,对音乐外放、换乘服务、调节发车间隔、人员服务、危险警示和逃生指引等乘客服务需求进行识别,并及时提供服务。
[0128]
gpu是快速处理视频、声音信息的硬件需求;乘客智能感知是基于声音智能分析、视频智能分析的;乘客智能交互可以理解为通过移动互联终端、机器人、多功能智能互动终端等实现的。
[0129]
本领域普通技术人员可以意识到,结合本文中公开的实施例描述的算法步骤及系统各模块,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
[0130]
在本发明所提供的实施例中,应该理解到,所揭露的方法和系统,可以通过其它的方式实现。例如,以上所描述的系统实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些接口,装置或单元的间接耦合或通讯连接,可以是电性,机械或其它的形式。
[0131]
以上所述实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
[0132]
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。