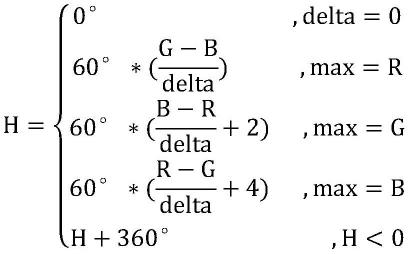
1.本发明涉及电子信息领域,涉及到一种新的导盲方法,将前方拍摄的景像转化成声音。涉及一种低成本的图像转声音的导盲技术,服务于盲人。
背景技术:
2.盲人由于先天性的疾病或者后天的意外事故,被夺去了视力。从这时开始,他们只能靠触觉和听觉去感受整个世界。对于盲人来说,成千上万种图像信息对他们来讲都是无用的,而且相对于在屋内的生活,户外出行对他们来说更是一件比较艰难的事情,在道路两旁或者过马路时还容易发生危险。所以一些科学家开始在电子辅助行走这个领域进行研究,一部分研究都是以定位为主,比如根据卫星信号能得知自己身处的地点,去一个目的地的导航等,但是这些设备无法处理一些意外情况。另一部分虽然可以处理一些意外情况,但是其设备价格昂贵,无法普及到所有盲人。众所周知,导盲犬也是服务于盲人的,但是导盲犬自身就是百里挑一,通过层层筛选才能选出,甚至还要提前预约,由于数量不多,预约早已排了长队。
3.盲人虽失去了看世界的能力,但是他们的耳朵相对来讲会更加敏锐,所以引发了一种思考,是否可以通过跨媒体信息转化的思想,将前方图像转化成声音,让盲人根据听声音判断正前方的情况。本发明提出一种新的图像转声音方法,将前方景像转化成声音,通过盲人人耳去听,判断前方有无障碍物。实验表明,该方法实现简单,有良好的应用推广价值。其次设计一种新的低成本导盲装置,实现简单,服务于低收入盲人。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种新的图像转声音方法,通过人耳判断前方情况,解决户外出行时前方出现障碍物会有潜在危险的问题。同时设计一种新的低成本导盲装置,服务于低收入盲人群体。所述方法如下:
5.一种图像转声音方法,具体流程有:
6.①
将图像的rgb颜色空间通过公式转化成hsv颜色空间,使图像中的颜色更加符合人的视觉特性。转化公式如下:
7.max=max(r,g,b)
8.min=min(r,g,b)
9.delta=max-min
[0010][0011][0012][0013]
其中:h、s、v对应色调、饱和度和明度值。max和min分别代表r、g、b的最大值和最小值,delta作为中间量,方便计算。
[0014]
②
图像到声音的转化
[0015]
要使图像信息与声音信息可以一一对应,为了解决此问题,所以本方法中使用的声音信号的表达式为正弦波这里a代表幅度、f代表频率、代表初始相位。
[0016]
将h、s、v三个图像特征映射到声音的正弦波的三个参数幅度、频率和初始相位中。h取值范围为0-360,s取值范围为0-1,v的取值范围为0-1。
[0017]
图像信息向声音信息进行映射,图像信息的h值映射到声音信号的正弦波的初始相位,图像信息的s值映射到声音信号的正弦波的幅度,图像信息的v值映射到声音信号的正弦波的频率。映射方法为:通过计算得到的h、s、v的值直接赋给a、f、从而确定了每种声音参数。
[0018]
图像三个分量信息向声音三个参数信息进行映射,根据不同的映射方法,最终可以得到6种不同的声音,分别为:
[0019]
i:h值映射到正弦波的幅度,s值映射到正弦波的频率,v值映射到正弦波的初始相位。
[0020]
ii:h值映射到正弦波的幅度,s值映射到正弦波的初始相位,v值映射到正弦波的频率。
[0021]
iii:h值映射到正弦波的频率,s值映射到正弦波的幅度,v值映射到正弦波的初始相位。
[0022]
iv:h值映射到正弦波的频率,s值映射到正弦波的初始相位,v值映射到正弦波的幅度。
[0023]
v:h值映射到正弦波的初始相位,s值映射到正弦波的频率,v值映射到正弦波的幅度。
[0024]
vi:h值映射到正弦波的初始相位,s值映射到正弦波的幅度,v值映射到正弦波的频率。
[0025]
映射方法为:通过计算得到的h、s、v的值直接赋给a、f、从而确定了每种声音参
数。
[0026]
通过客观评价方法,确定效果最佳的映射。
[0027]
6种映射方法,每个像素点得到的声音的数学表达式如下,映射顺序与
②
中相同:
[0028][0029][0030][0031][0032][0033][0034]
其中:h
i,j
、s
i,j
和v
i,j
均为第j列的第i个像素通过计算得到的h、s、v值,t表示最后总的波形时间,n为原图像像素的总列数。
[0035]
③
列叠加
[0036]
得到每个像素点所对应的声音后,需要对相同列上的声音进行叠加。将每一列m个像素所对应的声音进行叠加操作,最终每一列均合成一个时间长度为t/n的波形ca(t),6种映射方法公式如下:
[0037][0038][0039][0040][0041][0042][0043]
④
最终输出
[0044]
最后将图像的每列得到的声音,按照在图像中从左到右的顺序,将分开的几段合成波形首尾相连,最终合成一段时间为t的声音。
[0045]
(1)设计了一种低成本的导盲装置,具体流程如下:
[0046]
①
首先给嵌入式硬件板子通电,使嵌入式硬件板子和摄像头可以正常工作。其次图像采集模块通过摄像头对正前方3米景物,每5秒进行1次采集并将采集图像送到图像转声音模块。
[0047]
②
图像转声音模块将采集图像转化为一段声音的形式输出。
[0048]
③
将生成的声音片段进行播放,通过耳机传到人耳中,人耳根据听声音判断前方有无障碍物,从而达到导盲的效果。
[0049]
④
若导盲装置已完成相应的工作,则将导盲装置断电从而停止工作。
[0050]
本装置通过摄像头采集正前方3米左右的景物,同时送入采集图像进行图像到声音的转化,得到声音片段后,通过耳机将声音送到人耳中。人耳听此声音片段,判断出正前方障碍物的有无情况,达到户外导盲的目的。使用了c 语言编写实现了图转声算法以及设计搭建新导盲装置,实现导盲的目的。
附图说明
[0051]
图1:图转声方法的流程图。
[0052]
图2:导盲装置流程图。
具体实施方式
[0053]
(1)将用到的硬件头戴式支架、摄像头、嵌入式硬件板子、移动电源和耳机搭建成新导盲装置。
[0054]
(2)装备后首先给嵌入式硬件板子通电,使嵌入式硬件板子和摄像头可以正常工作。其次采集图像模块通过摄像头对正前方3米景物每5秒进行1次采集并将图像送到图像转声音模块。
[0055]
(3)图像转声音模块将正前方的图像转化成一段声音的形式输出。此模块具体步骤如下:
[0056]
①
将图像的rgb颜色空间通过公式转化成hsv颜色空间,使图像中的颜色更加符合人的视觉特性。转化公式如下:
[0057]
max=max(r,g,b)
[0058]
min=min(r,g,b)
[0059]
delta=max-min
[0060][0061][0062][0063]
其中:h、s、v对应色调、饱和度和明度值。max和min分别代表r、g、b的最大值和最小值,delta作为中间量,方便计算。
[0064]
②
图像到声音的转化
[0065]
要使图像信息与声音信息可以一一对应,为了解决此问题,所以本方法中使用的声音信号的表达式为正弦波这里a代表幅度、f代表频率、代表初
始相位。
[0066]
将h、s、v三个图像特征映射到声音的正弦波的三个参数幅度、频率和初始相位中。h取值范围为0-360,s取值范围为0-1,v的取值范围为0-1。
[0067]
图像信息向声音信息进行映射,图像信息的h值映射到声音信号的正弦波的初始相位,图像信息的s值映射到声音信号的正弦波的幅度,图像信息的v值映射到声音信号的正弦波的频率。映射方法为:通过计算得到的h、s、v的值直接赋给a、f、从而确定了每种声音参数。
[0068]
图像三个分量信息向声音三个参数信息进行映射,根据不同的映射方法,最终可以得到6种不同的声音,分别为:
[0069]
i:h值映射到正弦波的幅度,s值映射到正弦波的频率,v值映射到正弦波的初始相位。
[0070]
ii:h值映射到正弦波的幅度,s值映射到正弦波的初始相位,v值映射到正弦波的频率。
[0071]
iii:h值映射到正弦波的频率,s值映射到正弦波的幅度,v值映射到正弦波的初始相位。
[0072]
iv:h值映射到正弦波的频率,s值映射到正弦波的初始相位,v值映射到正弦波的幅度。
[0073]
v:h值映射到正弦波的初始相位,s值映射到正弦波的频率,v值映射到正弦波的幅度。
[0074]
vi:h值映射到正弦波的初始相位,s值映射到正弦波的幅度,v值映射到正弦波的频率。
[0075]
映射方法为:通过计算得到的h、s、v的值直接赋给a、f、从而确定了每种声音参数。
[0076]
下面通过人耳评价或客观评价方法,确定上述6种映射中的最佳映射。
[0077]
人耳评价:
[0078]
一.测试图像的采集
[0079]
需要测试图转声方法的判断效果,对每种方法的判断准确率有一个初步的认识,也为了后续搭建导盲装置时选取效果最佳的算法。所以需要采集一些图像数据。采集的工具以方便为主,所以选用了手机。
[0080]
采集的图像分为四类,根据背景像素颜色数目,超过5种颜色就认定背景复杂,低于或等于5种颜色就认定为背景简单。分类如下:
[0081]
i:背景复杂有障碍物。
[0082]
ii:背景简单有障碍物。
[0083]
iii:背景复杂无障碍物。
[0084]
iv:背景简单无障碍物。
[0085]
采集的障碍物离自身过远或者不在正前方均不考虑。所以测试图像的采集为正前方3米及以内有无障碍物的情况,若用手机在离地面高1.6米处拍照时,手机的拍摄角度与竖直方向的夹角为60
°
—70
°
即可。
[0086]
二.多种映射方法的测试
[0087]
图像的三个分量映射到正弦波的三个分量,一共有6种映射方式。在用人耳进行每种映射方法测试之前,测试者需要先进行训练:给出正前方图片中有障碍物所映射成的声音例子和正前方图片中无障碍物所映射的声音例子供测试者听。随后让测试者进行测试,通过听声音,他们判断结果只能为0或1,其中0为有障碍物,1为无障碍物。
[0088]
根据对所有声音的判断结果计算每种映射方法的判断准确率,最终挑选出最佳映射方法。
[0089]
客观评价:
[0090]
一.客观评价模型
[0091]
客观评价模型用到了基于长短期记忆循环神经网络lstm模型。
[0092]
二.客观评价模型的结构
[0093]
lstm模型本身就是一个结构的多个复制组成,属于循环神经网络。此模型设置为4层,每一层结构中包括两个激活函数模块,设置为tanh函数,和3个循环激活函数模块,设置为sigmoid函数,损失函数同样使用交叉熵函数,迭代器选用adam,adam是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。
[0094]
三.数据集的选择
[0095]
声音数据则为
②
中的6种图转声方法对图片转化得到。除此之外,由于需要用到神经网络的模型,数据量太少会导致模型训练差,导致结果不准确。所以使用了数据增强的方法来扩充数据集。选取了3种对原图像数据增强的方法,分别是对比度的增加、亮度的增加和水平翻转。图像数据增加后,再通过图转声算法转换成声音文件。
[0096]
此实验对所有的声音样本进行标记。标记的方法如下:
[0097]
i:将这些声音依次标号后然后进行打乱。
[0098]
ii:将全部声音分为10份,判断的人年龄在20-30岁共10人。每人首先会听到3段有障碍物的声音和3段无障碍物的声音示例,训练他们用人耳区分有无障碍物的声音。随后让他们对客观评价方法需要评价的图转声数据集,通过人耳听觉进行有无障碍物的判断,若认为有障碍物则将此声音标记为0,若认为无障碍物,则将此声音标记为1。
[0099]
iii:全部声音判断结束后,回收结果,并进行统计。
[0100]
四.模型输入
[0101]
选取了4种声音特征:梅尔倒谱系数特征mfcc、将音调之间的距离和关系表现在空间中的音乐格子图tonnetz、色度频率和梅尔频谱。将上文的声音数据的四种特征值相结合作为网络模型的输入。
[0102]
五.训练模型
[0103]
将所有样本数据分为训练集、验证集、测试集,按照6:2:2的比例。在训练过程中,当迭代次数增加时,如果其损失函数不再降低,则训练停止。根据模型对测试集的判断结果并与样本原始标记进行比较,可以计算出客观评价算法与人耳的匹配程度。
[0104]
客观评价与主观评价的吻合度为0.75。建议采用客观评价模型。
[0105]
综上,此客观评价模型的训练已完成,再通过此模型测试主观评价测试用到的图片数据,找到效果最佳的映射。
[0106]
6种映射方法,每个像素点得到的声音的数学表达式如下,映射顺序与
②
中相同:
[0107][0108][0109][0110][0111][0112][0113]
其中:h
i,j
、s
i,j
和v
i,j
均为第j列的第i个像素通过计算得到的h、s、v值,t表示最后总的波形时间,n为原图像像素的总列数。
[0114]
③
列叠加
[0115]
得到每个像素点所对应的声音后,需要对相同列上的声音进行叠加。将每一列m个像素所对应的声音进行叠加操作,最终每一列均合成一个时间长度为t/n的波形ca(t),6种映射方法公式如下:
[0116][0117][0118][0119][0120][0121][0122]
④
最终输出
[0123]
最后将图像的每列得到的声音,按照在图像中从左到右的顺序,将分开的几段合成波形首尾相连,最终合成一段时间为t的声音。
[0124]
(4)设计了一种低成本的导盲装置,具体流程如下:
[0125]
①
首先给嵌入式硬件板子通电,使嵌入式硬件板子和摄像头可以正常工作。其次图像采集模块通过摄像头对正前方3米景像,每5秒进行1次采集并将采集图像送到图像转声音模块。
[0126]
②
图像转声音模块将采集图像转化为一段声音的形式输出。
[0127]
③
将生成的声音片段进行播放,通过耳机传到人耳中,人耳根据听声音判断前方有无障碍物,从而达到导盲的效果。
[0128]
④
若导盲装置已完成相应的工作,则将导盲装置断电从而停止工作。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。