1.本技术实施例涉及网络安全领域,具体涉及对流量或日志数据进行分类的方法、系统、装置及介质。
背景技术:
2.相关技术中,针对于网络攻击的防火墙手段包括:为web应用防火墙(web application firewall,简称waf)配置策略规则,若访问流量命中策略,则将该访问流量拦截,若访问流量没有命中策略,则将该访问流量放行。但是,使用上述方法必须提前明确所有访问流量是否异常,从而不能够对未知的访问流量进行防护,进而降低了信息系统的安全性能。
3.因此,如何提高信息系统的安全性成为需要解决的问题。
技术实现要素:
4.本技术实施例提供了对流量或日志数据进行分类的方法、系统、装置及介质,通过本技术的一些实施例至少能够对访问流量进行监控,捕获访问流量中的异常流量,从而提高了系统的安全性。
5.第一方面,本技术提供了对流量或日志数据进行分类的方法,应用于安全设备,所述方法包括:获取至少一条待检测数据,其中,所述至少一条待检测数据为流量数据或日志数据;根据预设的多个特征和所述至少一条待检测数据,获得多组目标特征,其中,一条待检测数据对应一组目标特征;将所述多组目标特征输入到目标检测模型中,并且通过所述目标检测模型对所述多组目标特征进行分类,获得针对所述至少一条待检测数据的分类结果。
6.因此,与相关技术中必须明确访问流量数据的异常情况,并且基于该异常情况进行策略配置的方法不同的是,本技术实施例基于目标检测模型对待检测数据进行分类,能够对访问流量进行监控,捕获访问流量中的异常流量,从而提高了系统的安全性。
7.结合第一方面,在本技术的一种实施方式中,所述根据预设的多个特征和所述至少一条待检测数据,获得多组目标特征,包括:将所述至少一条待检测数据进行结构化,获得至少一组结构化数据,其中,一条待检测数据对应一组结构化数据,所述一组结构化数据中的每个结构化数据包括索引和目标数据;基于所述预设的多个特征和所述至少一组结构化数据,获得所述多组目标特征,其中,所述每个结构化数据对应一组目标特征。
8.因此,本技术实施例通过将至少一条待检测数据进行结构化,并且明确其特征,能够明确待检测数据中的数据特征(例如,是否包含固定字符串),从而能够提升分类的准确性。
9.结合第一方面,在本技术的一种实施方式中,所述一组结构化数据中包括第一结构化数据,其中,所述第一结构化数据属于所述一组结构化数据中的任意一条;所述基于所述预设的多个特征和所述至少一组结构化数据,获得所述多组目标特征,包括:将所述第一
结构化数据与所述预设的多个特征中的各特征进行比对,获得与所述第一结构化数据对应的一组目标特征。
10.结合第一方面,在本技术的一种实施方式中,在所述将所述多组目标特征输入到目标检测模型中之前,所述方法还包括:获取样本数据,其中,所述样本数据包括被标注为正常的第一样本数据以及被标注为异常的第二样本数据;将所述样本数据对应的样本特征输入到待训练的检测模型中进行训练,获得所述目标检测模型。
11.因此,本技术实施例通过样本数据对待训练的检测模型进行训练,能够获得目标检测模型,从而能够在待检测数据的异常情况未知的情况下,对访问的流量数据进行监控。
12.结合第一方面,在本技术的一种实施方式中,在所述获取样本数据之前,所述方法还包括:获取历史数据,其中,所述历史数据无标签;将所述历史数据输入到所述目标排序模型中,并且通过所述目标排序模型对所述历史数据进行排序,获得排序结果,其中,所述目标排序模型被配置为获得所述历史数据对应的历史特征,并且根据所述历史特征对所述历史数据属于异常流量的概率进行排序;根据所述排序结果得到所述样本数据。
13.因此,本技术实施例通过对无标签的历史数据进行排序,能够在样本数据的标签未知的情况下,获得样本数据的标签。
14.结合第一方面,在本技术的一种实施方式中,在所述将所述样本数据对应的样本特征输入到待训练的检测模型中进行训练之后,所述方法还包括:获得目标规则树,其中,所述目标规则树用于表征对至少一条待检测数据进行分类的规则。
15.因此,本技术实施例通过获取目标规则树,能够明确目标检测模型对待检测数据的判断规则。
16.第二方面,本技术提供了一种对流量或日志数据进行分类的系统,所述系统包括:安全设备,被配置为获取至少一条待检测数据,并且根据所述至少一条待检测数据执行如第一方面任意实施例所述的方法,获得流量分类结果;控制设备,被配置为根据所述流量分类结果对所述至少一条待检测数据进行放行或拦截。
17.第三方面,本技术提供了一种对流量或日志数据进行分类的装置,应用于安全设备,所述装置包括:数据获取模块,被配置为获取至少一条待检测数据,其中,所述至少一条待检测数据为流量数据或日志数据;特征获取模块,被配置为根据预设的多个特征和所述至少一条待检测数据,获得多组目标特征,其中,一条待检测数据对应一组目标特征;分类模块,被配置为将所述多组目标特征输入到目标检测模型中,并且通过所述目标检测模型对所述多组目标特征进行分类,获得针对所述至少一条待检测数据的分类结果。
18.结合第三方面,在本技术的一种实施方式中,所述特征获取模块被配置为:将所述至少一条待检测数据进行结构化,获得至少一组结构化数据,其中,一条待检测数据对应一组结构化数据,所述一组结构化数据中的每个结构化数据包括索引和目标数据;基于所述预设的多个特征和所述至少一组结构化数据,获得所述多组目标特征,其中,所述每个结构化数据对应一组目标特征。
19.结合第三方面,在本技术的一种实施方式中,所述一组结构化数据中包括第一结构化数据,其中,所述第一结构化数据属于所述一组结构化数据中的任意一条;所述特征获取模块被配置为:将所述第一结构化数据与所述预设的多个特征中的各特征进行比对,获得与所述第一结构化数据对应的一组目标特征。
20.结合第三方面,在本技术的一种实施方式中,分类模块被配置为:获取样本数据,其中,所述样本数据包括被标注为正常的第一样本数据以及被标注为异常的第二样本数据;将所述样本数据对应的样本特征输入到待训练的检测模型中进行训练,获得所述目标检测模型。
21.结合第三方面,在本技术的一种实施方式中,分类模块被配置为:获取历史数据,其中,所述历史数据无标签;将所述历史数据输入到所述目标排序模型中,并且通过所述目标排序模型对所述历史数据进行排序,获得排序结果,其中,所述目标排序模型被配置为获得所述历史数据对应的历史特征,并且根据所述历史特征对所述历史数据属于异常流量的概率进行排序;根据所述排序结果得到所述样本数据。
22.结合第三方面,在本技术的一种实施方式中,分类模块被配置为:获得目标规则树,其中,所述目标规则树用于表征对至少一条待检测数据进行分类的规则。
23.第四方面,本技术提供了对流量或日志数据进行分类的装置,包括:处理器、存储器和总线;所述处理器通过所述总线与所述存储器相连,所述存储器存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,用于实现如第一方面任意实施例所述方法。
24.第五方面,本技术提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被执行时实现如第一方面任意实施例所述方法。
附图说明
25.图1为本技术实施例示出的对流量或日志数据分类的系统组成示意图;图2为本技术实施例示出的对流量或日志数据分类的方法流程图之一;图3为本技术实施例示出的一种请求报文示意图;图4为本技术实施例示出的一种响应报文示意图;图5为本技术实施例示出的对流量或日志分类的方法流程图之二;图6为本技术实施例示出的一种对流量或日志分类的装置组成示意图;图7为本技术实施例示出的另一对流量或日志分类的装置组成示意图。
具体实施方式
26.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本技术的一部分实施例,而不是全部实施例。通常在此处附图中描述和示出的本技术实施例的组件可以以各种不同的配置来布置和设计。因此,以下对附图中提供的本技术的实施例的详情描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护范围。
27.本技术实施例可以应用于对访问流量数据进行异常识别的场景,为了改善背景技术中的问题,在本技术的一些实施例中,通过目标检测模型对目标特征(通过对访问流量数据进行特征衍生获得)进行分类,确认访问流量数据是正常流量或者是异常流量。例如,在本技术的一些实施例中,首先,获取至少一条待检测数据,然后,将至少一条待检测数据进
行特征衍生,获得多组目标特征,最后,将多组目标特征输入到目标检测模型中,得到待检测数据的分类结果,即待检测数据是正常流量还是异常流量。
28.图1提供了本技术一些实施例中的对流量或日志数据进行分类的系统组成示意图,该系统包括发送源设备110、安全设备120和控制设备130。具体的,发送源设备110向安全设备120发送至少一条待检测数据,安全设备120基于目标检测模型对至少一条待检测数据进行分类,得到分类结果,例如,确认待检测数据是正常流量还是异常流量,之后将分类结果发送到控制设备130中。控制设备130根据分类结果对待检测数据进行相对应的处理,例如,若分类结果显示待检测数据是正常流量,则允许该流量数据进行访问,若分类结果显示待检测数据是异常数据,则拦截该流量数据。
29.需要说明的是,发送源设备110是发送至少一条待检测数据的外网设备。例如,假设内网是安全的,则发送源设备110是指外网设备。对于内网的大小本技术的实施例不做限制。例如,内网可能是一个大学对应的网络,有可能是一家公司对应的网络,还可能是一座城市对应的网络等,如果内网是一所大学的网络, 则发送源设备110就是所有试图访问校园内网的所有外网设备。
30.与本技术实施例不同的是相关技术中,对内网的防护大多是基于策略规则的。由于攻击方与防御方信息不对称,导致了策略规则的更新永远慢于攻击者的新攻击手法。传统的流量数据检测系统在大量数据日志上使用启发式和静态签名来检测威胁和异常,但这意味着相关人员需要了解哪些是正常的数据日志,从而不能够对未知的访问流量进行防护,进而降低了内网系统的安全性能。
31.下面以安全设备为例示例性阐述本技术一些实施例提供的对网络流量数据进行分类的方法。可以理解的是,本技术实施例的对网络流量数据进行分类的方法的技术方案可以应用于任何安全设备上。
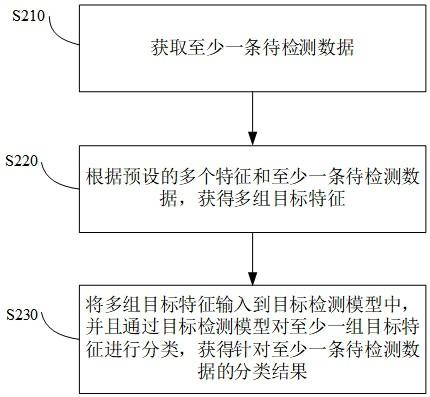
32.至少为了解决背景技术中的问题,如图2所示,本技术一些实施例提供了一种流量数据分类的方法,该方法包括:s210,获取至少一条待检测数据。
33.可以理解的是,作为本技术一具体实施例,至少一条待检测数据为流量数据或日志数据。作为本技术另一具体实施例,至少一条待检测数据为流量数据和日志数据。其中,流量数据可以是从网络中获取得到的,日志数据可以是直接从日志中获取得到的。本技术实施例对待检测数据的来源不进行限定。
34.例如,待检测数据是想要访问内网的访问流量,该内网由安全设备以及控制设备进行保护,也就是说,若访问流量想要访问内网,必须先由安全设备判断其是正常数据,再由控制设备进行放行。
35.例如,至少一条待检测数据是由安全设备进行实时监听获得的。也就是说,安全设备对外网的发送源设备进行监听,当存在流量数据访问时,安全设备获取待检测数据,之后对其进行分类。至少一条待检测数据也可以是预存在安全设备中的,当需要对其进行分类时,再获取该至少一条待检测数据。
36.s220,根据预设的多个特征和至少一条待检测数据,获得多组目标特征。
37.在本技术s220的一种实施方式中,获得多组目标特征的步骤如下所示:s2201,将至少一条待检测数据进行结构化,获得至少一组结构化数据。
38.可以理解的是,一条待检测数据对应一组结构化数据,一组结构化数据中的每个结构化数据包括索引和目标数据。
39.也就是说,将待检测数据进行参数解析,获得使用索引和目标数据进行表征的结构化数据,也可以将每个结构化数据称为一个键值对,索引是键值对中的键(key),目标数据为键值对中的值(value),一个键值对表征为“key:value”,例如,一个键值对为“connection: keep-alive”。若目标数据中还存在键值对,则继续对其进行解析,直至目标数据中不存在键值对,得到如下所示的目录树结构:key:valuekey1:value1key2:value2key2.1:value2.1其中,上述整体的目录树结构对应一条待检测数据,也就是说,一条待检测数据能够结构化成上述的一个目录树结构(即一组结构化数据)。具体的,首先,将一条待检测数据进行结构化获得一个键值对key:value,然后,由于value中可能还存在键值对,需要继续对value进行解析,所以获得了key1:value1和key2:value2,最后,由于value2中还存在键值对,因此,继续对value2进行解析获得了key2.1:value2.1,之后确定没有可以继续进行解析的目标数据之后,获得目录树结构。
40.具体的,待检测数据可以是超文本传输协议(hyper text transfer protocol,http)的请求报文及响应报文,在获取请求报文及响应报文之后,对其进行标准化得到相对应的标准化后的数据。
41.作为本技术一具体实施例,如图3所示,待检测数据为http的请求报文310,对请求报文310进行标准化的具体步骤包括:将请求行拆分为请求方法、请求网址、报文协议以及版本,将请求报头标准化为键值对的结构(即键值对可以表征为“键:值”),并且将请求正文标准化为键值对的结构。另外,还需要在请求报头和请求正文之间添加空行作为间隔。
42.作为本技术另一具体实施例,如图4所示,待检测数据为http的响应报文410,对响应报文410进行标准化的具体步骤包括:将响应行拆分为报文协议、版本、状态码以及状态描述,将响应报头标准化为键值对的结构,并且将响应正文标准化为键值对(即键值对可以表征为“键:值”)的结构。另外,可以在响应报头和响应正文之间添加空行作为间隔。
43.可以理解的是,状态码以及状态描述能够表征对于请求报文的回应,例如,状态描述为确定收到请求报文。
44.s2202,基于预设的多个特征和至少一组结构化数据,获得多组目标特征。
45.在本技术s2202的一种实施方式中,以一组结构化数据中的包括的第一结构化数据为例,描述s2202中的实施方式,其中,第一结构化数据为一组结构化数据中的任意一条。例如,一组结构化数据包括:key:value、key1:value1、key2:value2和key2.1:value2.1,则第一结构化数据为key1:value1。
46.具体的,将第一结构化数据与预设的多个特征中的各特征进行比对,获得与第一结构化数据对应的一组目标特征。也就是说,需要预先存储预设的多个特征,其中,该预设的多个特征是用于明确各结构化数据对应的目标特征的多个判断条件,将第一结构化数据与上述多个判断条件进行比对,从而明确第一结构化数据的多个目标特征(即一组目标特
征)。可以理解的是,本技术以第一结构化数据为例,示例性的描述获得目标特征的方法,一组结构化数据中的所有结构化数据与上述第一结构化数据的处理方式相同,最终能够获得多组目标特征。
47.作为本技术一具体实施例,在获得目标特征的过程中,将各结构化数据中的分割字符(例如,“;”“、”“,”)作为不同参数进行拆分,将拆分后的参数与多个判断条件进行比对,并且记录目标特征。
48.具体的,预设的多个特征包括:目标数据(value)的数据类型以及长度(长度范围)、是否包含固定字符串、是否包含某些固定目录结构、是否包含固定ip、是否包含固定网址、是否包含时间、是否包含日期、是否包含特殊编码(如unicode、utf-8等)、是否包含特定数字、是否包含某些特定字符串、是否包含结构化查询语言(structured query language,sql)语句,对于sql语句预期的执行结果行为进行提取,以及识别异常查询的sql语句、提取不同级别下的索引(key)的数量及种类、索引(key)是否是特定字符串、提取目标数据(value)为目录结构的情况下,目录后的参数特征。
49.例如,第一结构化数据为“key1:value1”,那么其对应的多个目标特征包括:value1的数据类型为字符类型以及长度为3、不包含某些固定字符串、不包含固定网址等。可以理解的是,第一结构化数据的多个目标特征(即一组目标特征)与预设的多个特征的个数相同。
50.s230,将多组目标特征输入到目标检测模型中,并且通过目标检测模型对多组目标特征进行分类,获得针对至少一条待检测数据的分类结果。
51.在本技术的一种实施方式中,在s230之前需要对待训练的检测模型进行训练,具体步骤如下所示:s2301,获取历史数据,其中,历史数据无标签。
52.也就是说,对待训练的检测模型进行训练之前需要先获得带有标签的样本数据,在不明确存储的历史数据(例如,http/https请求数据)是正常数据还是异常数据(即历史数据无标签)的情况下,执行s2302将历史数据进行排序。
53.可以理解的是,https为超文本传输安全协议(hyper text transfer protocol over securesocket layer,https)。
54.s2302,将历史数据输入到目标排序模型中,并且通过目标排序模型对历史数据进行排序,获得排序结果。
55.可以理解的是,目标排序模型被配置为获得历史数据对应的历史特征,并且根据历史特征对历史数据属于异常流量的概率进行排序。
56.也就是说,使用集成的目标排序模型,首先,对历史数据进行结构化,并且将结构化后的历史数据与预设的多个特征进行比对,获得历史特征。然后,将历史特征分别输入到多个学习器中进行排序,相对应的获得多个排序结果。最后,采取加权投票机制,将多个排序结果按照预设权重进行计算获得排序结果。
57.需要说明的是,多个学习器包括主成分分析学习器(principal components analysis,pca)、最小协方差行列式学习器(minimum covariance determinant,mcd)、 一类支持向量机学习器(one-class support vector machine,ocsvm)、 最近邻学习器(k-nearestneighbor,knn)和孤立森林学习器(isolation forest,iforest)。多个学习器的预
设权重分别为:iforest对应的预设权重为0.4、ocsvm对应的预设权重为0.3、knn对应的预设权重为0.2、pca对应的预设权重为0.05以及mcd对应的预设权重为0.05。
58.例如,历史数据包括a、b和c三条,对应的历史特征包括特征a、特征b和特征c,将特征a、特征b和特征c分别输入到多个学习器中进行排序,每一个学习器输出的是异常值得分,即异常排序,例如,iforest输出的异常值得分为特征a-9分,特征b-5分,特征c-1分。虽然多个学习器都会输出异常排序,但是异常值得分的量纲是不同的,因此首先需要将每个学习器输出的异常值得分去量纲,如下公式(1)所示: z=(x-u)/s(1)其中,z表示去除量纲之后的异常值,x表示任意一个异常值得分,u表示异常值得分的均值,s表示标准差。
59.之后,将预设权重相对应的乘以每个去除量纲之后的异常值,获得权重异常值,将每条历史流量对应的权重异常值相加,再将相加之后的数值进行排序,获得排序结果。因此加权投票机制相较单一的异常值检测算法具有更强的泛化能力。
60.s2303,根据排序结果得到样本数据。
61.在s2302中获得排序结果之后,选取前1%的历史数据作为正样本,选取后10%的历史数据作为负样本。
62.s2304,获取样本数据。
63.可以理解的是,样本数据包括被标注为正常的第一样本数据以及被标注为异常的第二样本数据。
64.需要说明的是,样本数据包括两部分的数据,一部分是通过s2301-s2303中的方法获得的,另一部分是已经标记有标签的样本数据。
65.s2305,将样本数据对应的样本特征输入到待训练的检测模型中进行训练,获得目标检测模型。
66.具体的,因为考虑目标检测模型输出的分类结果需要极强的解释性,所以选用待训练的决策树模型对带有标签的样本数据进行分类学习,可以理解的是,输入待训练的决策树模型的是样本数据对应的流量特征,模型训练过程中80%的数据作为训练集,20%的数据作为测试集。因此,选择有监督模型而不使用无监督模型的原因是,相较无监督模型有监督模型更加稳定。
67.可以理解的是,待训练的检测模型可以是待训练的决策树模型,还可以是其他具备对样本数据进行分类功能的模型,本技术对分类算法不作限制。
68.在本技术的一种实施方式中,对待训练的检测模型进行训练之后还会生成目标规则树,目标规则树是用于表征对至少一条待检测数据进行分类的规则。
69.在本技术的一种实施方式中,在获得目标检测模型之后,将多组目标特征输入到目标检测模型中,并且通过目标检测模型对多组目标特征进行分类,获得针对至少一条待检测数据的分类结果,其中,分类结果包括该流量数据是正常流量,或者该流量数据是异常流量。
70.上文描述了本技术的一种对网络流量数据进行分类的方法流程,下文将描述对网络流量数据进行分类的具体实施例。
71.本技术通过机器学习算法,自动识别http/https请求中正常及异常参数,建立正
常参数的特征,即对正常参数建立安全基线,例如,针对请求中的url避免了人工重复性工作,在异常标签未知的情况下无需堆砌人力统计公上线项目和页面的参数限制,机器学习算法会生成参数系统的规则引擎。
72.例如,一个正常http请求,目标检测模型可以识别请求中的各种参数异常,如攻击者使用"put"替换"get",或者,系统会识别到参数异常,对该请求进行告警,还可以对正常请求中的参数建立模型,如"get /searchs/keywords/1"中"/searchs/keywords/"的后面只会出现整型数据,那么"/searchs/keywords/test"就会被识别为异常,因为"test"是字符型。
73.因此,本技术的目的在于提供一种基于机器学习的url参数异常检测方法,无论异常标签已知或未知的情况下,均无需堆砌人力统计公上线项目和页面的参数限制,生成参数系统的规则引擎,如 get /searchs/keywords/1 http/1.1是一个键值对(key:value),规则引擎根据特征衍生可以得到,该key为一个特定字符串,类型为字符型,长度为3,内容为”get”,该value为一个特定的字符串,类型为字符类型,长度为28,内容为“/searchs/keywords/1 http/1.1”,包含一个目录地址,目录最后参数为
‘1’
。
74.如图5所示,上述对网络流量数据进行分类的具体实施步骤如下:s501,开始。
75.s502,数据结构化。
76.s503,数据衍生。
77.s504,样本异常标签是否已知,若是,则执行s507,若否,则执行s505无监督集成算法异常排序,之后执行s506根据排序选取异常标签。
78.s507,训练有监督异常分类器,在训练完成之后执行s508生成目标异常分类器(即目标检测模型)以及参数规则引擎(即目标规则树)。
79.s510,部署目标异常分类器以及参数规则引擎上线。在上线之后若需要对目标异常分类器中的参数进行微调,则执行s509修正结果迭代训练模型。
80.s511,使用目标异常分类器对流量进行监控。
81.可以理解的是,上述步骤中的具体内容均已在前文中详细描述,在此不再赘述。
82.因此,本技术提供的方法应用于web防御,有益效果包括:增加了针对未知威胁如0day漏洞的防御手段,能有效的进行识别异常访问并进行阻断。建立正常流量的规则引擎。能识别正常流量以及异常流量。无历史积累经验的冷启动阶段引入无监督异常检测算法,达到了充分利用了历史积累的异常标签未知数据的目的,并且可应用于历史数据异常标签完全未知的情况。从而提高了工作效率,减少了人力堆砌,弱化了专家经验。
83.因此,本技术提供的一种对网络流量数据进行分类的方法相较于现有技术具有以下优点:第一,能够解决冷启动(流量数据标签完全未知)问题,从而不浪费历史积累的标签未知的数据。
84.第二:使用了代表性较强的异常和非异常数据,对异常规则的识别泛化能力强。
85.第三:新规则的添加会相对鲁棒,因为完整的规则引擎均由机器学习模型生成(通过添加训练数据迭代训练生成),因此,不可能会出现与现有规则引擎违背的情况。
86.第四:模型具有较强的解释性。
87.第五:模型框架适用性较强,在数据量一定的情况下无论有标签和无标签的数据量有多少,都可以应用该框架。
88.上文描述了对网络流量数据进行分类的具体实施例,下文将描述对网络流量数据进行分类的装置。
89.如图6所示,一种对流量或日志数据进行分类的装置600,包括:数据获取模块610、特征获取模块620和分类模块630。
90.数据获取模块610,被配置为获取至少一条待检测数据,其中,所述至少一条待检测数据为流量数据或日志数据。
91.特征获取模块620,被配置为根据预设的多个特征和所述至少一条待检测数据,获得多组目标特征,其中,一条待检测数据对应一组目标特征。
92.分类模块630,被配置为将所述多组目标特征输入到目标检测模型中,并且通过所述目标检测模型对所述多组目标特征进行分类,获得针对所述至少一条待检测数据的分类结果。
93.在本技术的一种实施方式中,所述特征获取模块620被配置为:将所述至少一条待检测数据进行结构化,获得至少一组结构化数据,其中,一条待检测数据对应一组结构化数据,所述一组结构化数据中的每个结构化数据包括索引和目标数据;基于所述预设的多个特征和所述至少一组结构化数据,获得所述多组目标特征,其中,所述每个结构化数据对应一组目标特征。
94.在本技术的一种实施方式中,所述一组结构化数据中包括第一结构化数据,其中,所述第一结构化数据属于所述一组结构化数据中的任意一条;所述特征获取模块620被配置为:将所述第一结构化数据与所述预设的多个特征中的各特征进行比对,获得与所述第一结构化数据对应的一组目标特征。
95.在本技术的一种实施方式中,分类模块630被配置为:获取样本数据,其中,所述样本数据包括被标注为正常的第一样本数据以及被标注为异常的第二样本数据;将所述样本数据对应的样本特征输入到待训练的检测模型中进行训练,获得所述目标检测模型。
96.在本技术的一种实施方式中,分类模块630被配置为:获取历史数据,其中,所述历史数据无标签;将所述历史数据输入到所述目标排序模型中,并且通过所述目标排序模型对所述历史数据进行排序,获得排序结果,其中,所述目标排序模型被配置为获得所述历史数据对应的历史特征,并且根据所述历史特征对所述历史数据属于异常流量的概率进行排序;根据所述排序结果得到所述样本数据。
97.在本技术的一种实施方式中,分类模块630被配置为:获得目标规则树,其中,所述目标规则树用于表征对至少一条待检测数据进行分类的规则。
98.在本技术实施例中,图6所示模块能够实现图1至图5方法实施例中的各个过程。图6中的各个模块的操作和/或功能,分别为了实现图1至图5中的方法实施例中的相应流程。具体可参见上述方法实施例中的描述,为避免重复,此处适当省略详细描述。
99.如图7所示,本技术实施例提供另一对流量或日志数据进行分类的装置700,包括:处理器710、存储器720和总线730,所述处理器通过所述总线与所述存储器相连,所述存储器存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,用于实现如上述所有实施例中任一项所述的方法,具体可参见上述方法实施例中的描述,为避免重复,
此处适当省略详细描述。
100.其中,总线用于实现这些组件直接的连接通信。其中,本技术实施例中处理器可以是一种集成电路芯片,具有信号的处理能力。上述的处理器可以是通用处理器,包括中央处理器(central processing unit,简称cpu)、网络处理器(network processor,简称np)等;还可以是数字信号处理器(dsp)、专用集成电路(asic)、现成可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本技术实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
101.存储器可以是,但不限于,随机存取存储器(random access memory,ram),只读存储器(read only memory,rom),可编程只读存储器(programmable read-only memory,prom),可擦除只读存储器(erasable programmable read-only memory,eprom),电可擦除只读存储器(electric erasable programmable read-only memory,eeprom)等。存储器中存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,可以执行上述实施例中所述的方法。
102.可以理解,图7所示的结构仅为示意,还可包括比图7中所示更多或者更少的组件,或者具有与图7所示不同的配置。图7中所示的各组件可以采用硬件、软件或其组合实现。
103.本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被服务器执行时实现上述所有实施方式中任一所述的方法,具体可参见上述方法实施例中的描述,为避免重复,此处适当省略详细描述。
104.以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
105.以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。