一种片内执行机器学习算法的uwb芯片及方法
技术领域
1.本发明实施例涉及超宽带(uwb,ultra wide band)芯片设计技术领域,尤其涉及一种片内执行机器学习算法的uwb芯片及方法。
背景技术:
2.当前,uwb射频芯片包括接收路径和发射路径两个部分,对于接收路径部分来说,接收端天线接收到uwb无线信号后,通过接收端射频前端电路完成对该uwb无线信号所进行的放大、下变频等操作;接着,通过模数转换器(adc,analog-to-digital converter)将经过放大、下变频等操作的uwb无线信号由模拟信号转换为数字信号,并送入接收解调器。在接收解调器内,数据经过相关器、前导符号(preamble)检测器、帧起始定界符(sfd,start frame delimiter)检测器和物理层帧头(phr,physical layer header)和物理层服务数据单元(psdu,physical layer service data unit)解码器,被解码出来;随后,经过串行外设接口(spi,serial peripheral interface)接口送入芯片外部的arm处理器;同时,与上述处理过程并行地进行信道冲击响应(cir,channel impulse response)和时间戳计算,并将时间戳结果也送入芯片外部的arm处理器;在计算cir的同时,还需要将计算的中间结果存入cir存储器,arm处理器从cir存储器读出cir数据,再发送至个人计算机(pc,personal computer)端,在pc端完成神经网络计算,对时间戳进行校正。
3.在具体实施过程中,cir存储器中的数据量为6kb,spi速度设定为20mbps,那么arm处理器通过spi接口从cir存储器中读取数据至少需要耗费2.4ms,而一帧uwb数据帧的长度传输耗时一般在200us以内。所以当前在具体实施过程中,arm处理器读取cir存储器的时间将远远大于传输uwb数据帧的时间,由此限制了整个uwb通信系统只能离线处理数据,无法实时进行机器学习的计算,从而增加了定位延迟。
技术实现要素:
4.有鉴于此,本发明实施例期望提供一种片内执行机器学习算法的uwb芯片及方法;能够在uwb芯片内在线完成关于机器学习的神经网络计算,无需将cir存储器中的数据通过arm处理器传输至pc机,从而能够在片上实时完成时间戳校正,降低了定位延迟。
5.本发明实施例的技术方案是这样实现的:第一方面,本发明实施例提供了一种片内执行机器学习算法的uwb芯片,所述uwb芯片包括:神经网络计算部分和arm处理核;所述神经网络计算部分,经配置为读取所述uwb芯片上已有的cir存储器中的cir数据;根据所述cir数据利用已训练完毕的神经网络算法进行计算,获得uwb接收信号所对应目标的非视距nlos判定值以及校正数据;所述arm处理核,经配置为根据由所述神经网络计算部分传输的nlos判定值和校正数据对从所述uwb芯片上已有的时间戳计算单元传输的时间戳数据进行校正,获得校正后的时间戳。
6.第二方面,本发明实施例提供了一种片内执行机器学习算法的方法,所述方法应用于第一方面所述的uwb芯片,所述方法包括:通过所述uwb芯片中的神经网络计算部分读取所述uwb芯片上已有的cir存储器中的cir数据;通过所述神经网络计算部分根据所述cir数据利用已训练完毕的神经网络算法进行计算,获得uwb接收信号所对应目标的非视距nlos判定值以及校正数据;通过所述uwb芯片中的arm处理核根据由所述神经网络计算部分传输的nlos判定值和校正数据对从所述uwb芯片上已有的时间戳计算单元传输的时间戳数据进行校正,获得校正后的时间戳。
7.本发明实施例提供了一种片内执行机器学习算法的uwb芯片及方法;通过在uwb芯片内部集成神经网络计算部分与arm处理核,使得能够在片上完成机器学习计算,无需将片上数据传输至芯片外部,提高了数据传输速率,降低了处理延时和定位延时,相较于当前常规方案能够实现实时的高精度定位。
附图说明
8.图1为常规方案中的一种示例性的uwb芯片及周边电路架构示意图;图2为本发明实施例提供的一种片内执行机器学习算法的uwb芯片的组成示意图;图3为本发明实施例提供的神经网络模型的结构示意图;图4为本发明实施例提供的另一种片内执行机器学习算法的uwb芯片的组成示意图;图5为本发明实施例提供的神经网络计算单元的示例性结构示意图;图6为本发明实施例提供的示例性的网络系统组成示意图;图7为本发明实施例提供的一种片内执行机器学习算法的方法流程示意图。
具体实施方式
9.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
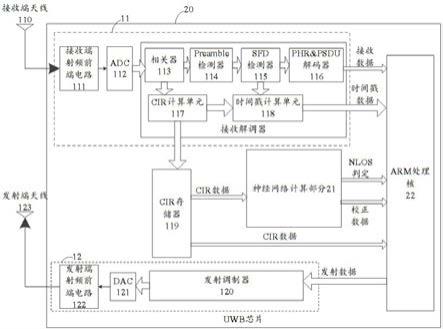
10.参见图1,其示出了目前常规方案中的一种示例性的uwb芯片及周边电路架构示意。图1包括uwb芯片100、arm处理器200和执行离线神经网络计算的pc 300。对于uwb芯片来说,如虚线框所示,包括接收路径部分11、发射路径部分12以及用于与芯片外部进行数据传输的spi接口13。
11.对于图1中所示出的接收路径部分11,基于接收信号的信号流走向,依次可以包括:接收端天线110、接收端射频前端电路111、adc 112、相关器113、preamble检测器114、sfd检测器115、phr&psdu解码器116、cir计算单元117、时间戳计算单元118和cir存储器119;详细来说,如图1所示,相关器113、preamble检测器114、sfd检测器115、phr&psdu解码器116、cir计算单元117、时间戳计算单元118和cir存储器119组成了接收路径部分11中的接收解调器。
12.对于图1中所示出的发射路径部分12,基于发射信号的信号流走向,依次可以包括:发射解调器120、数模转换器(dac,digital-to-analog converter)121、发射端前端电
路122以及发射端天线123。基于上述如图1所示的发射路径部分12的示例性组成结构,在一些示例中,通过spi接口13接收由arm处理器200传输的待发射的发射数据之后,经过发射调制器120调制;接着,通过dac 121将调制后的发射数据转换为模拟发射信号之后,利用发射端射频前端电路122对模拟发射信号进行滤波、放大等操作,最终通过发射端天线123向自由空间辐射。
13.基于上述图1所示出的接收路径部分11的示例性组成结构,在一些示例中,接收端天线111在接收到uwb无线信号后,通过接收端射频前端电路111完成对该uwb无线信号所进行的放大、下变频等操作;接着,通过adc 112将上述经过放大、下变频等操作后的uwb无线信号由模拟信号转换为数字信号,从而获得接收数据并送入接收解调器。在接收解调器内,接收数据依次经过相关器113、preamble检测器114、sfd检测器115和phr&psdu解码器116,进行解码,并将解码后的接收数据经过spi接口13送入芯片外部的arm处理器200;同时,与上述处理过程并行实施的,接收数据经相关器113处理后,依次通过cir计算单元117和时间戳计算单元118分别进行cir计算和时间戳计算,并将最终获得的时间戳数据也经过spi接口13送入芯片外部的arm处理器200;此外,在进行cir计算的同时,还需要将计算的中间结果,也就是cir数据存入cir存储器,如此,arm处理器200也通过spi接口13从cir存储器119中读取该cir数据并发送至pc 300,pc 300可以根据cir数据完成神经网络计算,对由时间戳计算单元118所计算获得的时间戳数据进行校正。
14.基于图1所示的uwb芯片及周边电路架构示意,目前常规方案在进行时间戳数据校正过程中,需要通过spi接口13将uwb芯片内所获得数据传输至外部的arm处理器200以及pc 300进行离线的神经网络计算。这部分阐述内容中涉及的数据传输通常所需的耗时达到毫秒级,但是uwb数据帧在芯片内的传输时间通常为200us。由此可知,由于uwb芯片内的数据传输至外部所需的耗时远大于uwb数据帧在芯片内的传输时间,增加了进行高精度定位的延迟,无法实现实时的高精度定位。基于此,本发明实施例期望能够在uwb芯片内实现关于机器学习的神经网络计算,减少芯片与外部进行数据传输的情况,从而降低了定位延迟,能够实现实时的高精度定位。
15.基于以上阐述,参见图2,其示出了本发明实施例提供的一种片内执行机器学习算法的uwb芯片20的组成,从图2中可以看出,该uwb芯片20除了包括图1中uwb芯片100所包含由接收端天线110、接收端射频前端电路111、adc 112、相关器113、preamble检测器114、sfd检测器115、phr&psdu解码器116、cir计算单元117、时间戳计算单元118和cir存储器119构成的接收路径部分11,以及由发射解调器120、dac 121、发射端前端电路122和发射端天线123构成的发射路径部分12以外,还包括神经网络计算部分21和arm处理核22;对于神经网络计算部分21,经配置为读取cir存储器119中的cir数据;根据所述cir数据利用已训练完毕的神经网络算法进行计算,获得uwb接收信号所对应目标的非视距(nlos,non-line-of-sight)判定值以及校正数据;所述arm处理核22,经配置为根据由神经网络计算部分21传输的nlos判定值和校正数据对从时间戳计算单元118传输的时间戳数据进行校正,获得校正后的时间戳。
16.通过图2所示的结构,uwb芯片20内部集成有神经网络计算部分21与arm处理核22,使得能够在片上完成机器学习计算,无需将片上数据传输至芯片外部,提高了数据传输速率,降低了处理延时和定位延时,相较于当前常规方案能够实现实时的高精度定位。
17.对于图2所示的结构,在一些示例中,由于图2所示的结构中包括arm处理核22,所以与图1所示的结构相比,phr&psdu解码器116进行解码所得到的解码后的接收数据、时间戳计算单元118所计算获得的时间戳数据均无需通过外部接口进行传输。在本发明实施例中,其余各组件(比如phr&psdu解码器116、发射调制器120、cir存储器119以及uwb芯片20内其他需要与arm处理核22进行交互的组件)与arm处理核22之间可以通过诸如高级高性能总线(ahb,advanced high performance bus)等类型的片上系统总线进行交互,从而提高数据传输速率,降低定位延时。
18.对于图2所示的结构,在一些示例中,神经网络计算部分21优选通过直接存储器访问(dma,direct memory access)的方式直接从cir存储器119中读取所述cir数据。可以理解地,设定数据宽度为192bit,频率为125mhz时钟的实施环境下,dma的读取带宽可以达到24gbps,是目前常规方案的1000倍左右,因此,当uwb芯片内集成神经网络计算部分21之后,cir数据的传输时间不再是uwb系统定位所耗费时长的瓶颈。
19.对于图2所示的结构,在一些示例中,由于cir数据需要向神经网络计算部分21以及arm处理核22传输,因此,与图1所示结构不同的,cir存储器119可以设置于接收解调器之外,从而便于神经网络计算部分21通过dma的方式进行数据读取。
20.结合图2所示的结构,神经网络计算部分21集成在uwb芯片上,因此,需要将执行机器学习的神经网络模型进行配置,从功能上来说,本发明实施例所采用的神经网络模型的结构如图3中的虚线框所示,依次可以包括:输入层、卷积层、池化层、卷积层、全连接层和输出层。详细来说,cir数据通过输入层输入至神经网络模型,经过卷积、池化、全连接等计算操作,最终输出nlos判定值和校正数据。在具体实施过程中,各层的拓扑结构、卷积核的尺寸以及权值的大小等模型阐述可以由模型训练结果决定。进一步来说,对于神经网络模型的功能实现,核心是对cir数据和权值进行相乘后再进行累加运算,因此,参见图4,神经网络计算部分21包括:权值存储器211以及神经网络计算单元212;详细来说,权值存储器211可以接收由arm处理器22传输的权值数据并进行存储,此外,还能够将存储的权值数据传输至神经网络计算单元212,可以理解地,该权值数据可以由预先对神经网络模型进行训练所得;神经网络计算单元212,经配置为利用cir数据以及权值数据通过已训练完毕的神经网络模型进行计算,得到nlos判定值以及校正数据。
21.可以理解地,神经网络模型的核心是一个由多个乘加器构成的计算阵列。因此,对于上述示例,在具体实施过程中,参见图4,神经网络计算单元212可以包括:cir数据缓存器2121、乘累加计算阵列2122、权值缓存器2123、运算控制器2124以及计算结果缓存器2125;其中,cir数据缓存器2121,经配置为基于所述运算控制器2124的调度,将从cir存储器119接收到的cir数据进行缓存,并传输至乘累加计算阵列2122;权值缓存器2123经配置为基于所述运算控制器2124的调度,将从权值存储器211接收到的权值数据进行缓存,并传输至乘累加计算阵列2122;乘累加计算阵列2122,经配置为基于运算控制器2124的调度将接收到的cir数据以及权值数据进行乘累加运算,获得包括nlos判定值以及校正数据的运算结果,并将所述运算结果传输至计算结果缓存器2125进行缓存;所述计算结果缓存器2125,经配置为基于运算控制器2124的调度将所缓存的运算结果(即图2或图4中所示出的nlos判定值以及校正数据)传输至arm处理核22。
22.具体来说,以图5所示的神经网络计算单元212的示例性结构为例,乘累加计算阵
列2122由3
×
3的乘加器构成,接收解调器接收完成一帧数据后,在运算控制器2124的调度下,将当前计算所需数据量的cir数据和权值数据分别从cir存储器119和权值存储器211转移到cir数据缓存器2121和权值缓存器2123;随后乘累加计算阵列2122在运算控制器2124的调度下分别读取cir数据缓存器2121和权值缓存器2123中的三路cir数据以及三路权值数据,并分别进行乘累加运算,运算完成后的三路运算结果存放在计算结果缓存器2125中。在完成一次运算之后,运算控制器2124就可以按照前述过程再调度获取下一次计算需要的cir数据和权值数据,再进行乘累加操作。反复进行这样的操作,直到针对该帧数据的计算完成,即完成了整个神经网络模型各功能的计算实现,输出最终的计算结果供arm处理核22读取。
23.结合图2和图4所示的结构,在一些示例中,神经网络计算部分21或者神经网络计算单元212中的神经网络模型需要提前进行训练和参数配置。本发明实施例中,针对神经网络模型的训练以及参数配置通常需要借助外部的训练服务器完成,继续参见图4,所述接收解调器内还包括特征值存储器23,经配置为存储边缘uwb设备在信号接收过程中根据设定的特征值类型获取对应的特征值数据;其中,所述特征值类型包括:接收解调器内计算的距离、首达径的幅度、首达径的一次谐波的幅度、首达径的二次谐波的幅度、首达径的三次谐波的幅度、preamble的累加次数、首达径的能量估计、接收信号rx能量估计、噪声估计以及噪声最大值;将所述特征值数据传输至arm处理核22,以供arm处理核22将所述特征值数据以及从cir存储器119所读取的cir数据通过uwb无线链路发送至服务器端,以使得所述服务器端根据所述特征值数据以及所述cir数据对所述神经网络模型进行训练。
24.对于上述示例,具体来说,由于神经网络模型的训练过程通常会在芯片外部甚至在uwb设备外部的服务器端进行,具体训练所需的网络系统架构如图6所示。结合图4与图6,详细来说,设定uwb芯片20设置在边缘uwb设备中,由于神经网络模型的训练需要上述示例中所述的特征值数据,那么在具体实施时,边缘uwb设备会在接收到一帧数据的过程中,对于上述特征值的计算,并在数据帧接收完毕后,将这些特征值数据存储在特征值存储器23。arm处理核22将会读取特征值存储器23内的特征值数据和cir存储器119内的cir数据,可以理解地,在实施过程中,可以通过ahb总线等片上系统总线进行传输;随后,边缘uwb设备通过uwb无线链路将特征值数据和cir数据发送至服务器端,具体可以是服务器端的uwb设备;最后服务器端的uwb设备将特征值数据和cir数据通过通信网络或其他传输方式发送至具有强大计算能力的训练服务器,进行神经网络的训练。
25.当训练服务器训练完成后,训练服务器把训练所得到的神经网络模型权值数据下发至服务器端的uwb设备,随后服务器端的uwb设备通过uwb无线链路了发送至各个边缘uwb设备,边缘uwb设备中uwb芯片20通过arm处理核22将权值存储于权值存储器211以供神经网络计算部分212在执行神经网络计算过程中使用,从而完成芯片20中关于神经网络模型的配置操作,从而完成了神经网络模型的训练和配置工作。
26.对于上述方案,详细来说,设定图2或图4所示的uwb芯片20设置于边缘uwb设备,在边缘uwb设备接收到一帧数据的过程中,可以通过芯片20中的cir计算单元117计算获得cir数据并存储在cir存储器119中。在接收完一帧数据后,芯片20可以开启神经网络计算单元212。cir数据经过dma传输至神经网络计算单元212中的cir数据缓存器2121,权值存储器
211中所存储的权值也将会传输至权值缓存器2123;接着,通过已经配置好的神经网络模型完成卷积、池化、全连接等神经网络计算,得到是否是nlos非视距的判定结果和校正数据,并送入arm处理核22。arm处理核22结合nlos判定结果和校正数据对接收解调器中时间戳计算单元118计算获得的时间戳数据进行校正,从而得到更加准确的测距结果。举例来说,对时间戳修正的方法和神经网络有关,一般的,优选将时间戳数据减去校正数据即得到修正后的时间戳数据,当然也可以结合其他统计学方法做更加复杂的校正。由于测量的距离误差等于时间误差乘光速:δs=δt*c,那么将时间戳数据进行校正后,降低了时间误差,所以提高了测距的精度和定位的精度。
27.基于前述技术方案相同的发明构思,参见图7,其示出了本发明实施例提供的一种片内执行机器学习算法的方法,该方法可以应用于前述图2或图4所示出的uwb芯片20结构,该方法可以包括:s701:通过所述uwb芯片中的神经网络计算部分读取所述uwb芯片上已有的cir存储器中的cir数据;s702:通过所述神经网络计算部分根据所述cir数据利用已训练完毕的神经网络算法进行计算,获得uwb接收信号所对应目标的非视距nlos判定值以及校正数据;s703:通过所述uwb芯片中的arm处理核根据由所述神经网络计算部分传输的nlos判定值和校正数据对从所述uwb芯片上已有的时间戳计算单元传输的时间戳数据进行校正,获得校正后的时间戳。
28.对于上述方案,在一些示例中,如图4所示,所述神经网络计算部分包括:权值存储器以及神经网络计算单元;相应地,所述根据所述cir数据利用已训练完毕的神经网络算法进行计算,获得uwb接收信号所对应目标的非视距nlos判定值以及校正数据,包括:通过所述权值存储器接收由所述arm处理核传输的权值数据并进行存储;并且,将存储的权值数据传输至所述神经网络计算单元;通过所述神经网络计算单元利用所述cir数据以及所述权值数据通过已训练完毕的神经网络模型进行计算,得到所述nlos判定值以及校正数据。
29.对于上述方案,在一些示例中,如图4所示,所述神经网络计算单元包括:cir数据缓存器、乘累加计算阵列、权值缓存器、运算控制器以及计算结果缓存器;相应地,所述通过所述神经网络计算单元利用所述cir数据以及所述权值数据通过已训练完毕的神经网络模型进行计算,得到所述nlos判定值以及校正数据,包括:通过所述cir数据缓存器基于所述运算控制器的调度,将从所述cir存储器接收到的cir数据进行缓存,并传输至所述乘累加计算阵列;通过所述权值缓存器基于所述运算控制器的调度,将从所述权值存储器接收到的权值数据进行缓存,并传输至所述乘累加计算阵列;通过所述乘累加计算阵列基于所述运算控制器的调度将接收到的cir数据以及权值数据进行乘累加运算,获得包括nlos判定值以及校正数据的运算结果,并将所述运算结果传输至所述计算结果缓存器进行缓存;通过所述计算结果缓存器基于所述运算控制器的调度将所缓存的运算结果传输至所述arm处理核。
30.对于上述方案,在一些示例中,如图4所示,所述uwb芯片还包括特征值存储器;相
应地,所述方法还包括:通过所述特征值存储器存储边缘uwb设备在信号接收过程中根据设定的特征值类型获取对应的特征值数据;其中,所述特征值类型包括:接收解调器内计算的距离、首达径的幅度、首达径的一次谐波的幅度、首达径的二次谐波的幅度、首达径的三次谐波的幅度、preamble的累加次数、首达径的能量估计、接收信号rx能量估计、噪声估计以及噪声最大值;通过所述特征值存储器将所述特征值数据传输至所述arm处理核,以供所述arm处理核将所述特征值数据以及从所述cir存储器所读取的cir数据通过uwb无线链路发送至服务器端,以使得所述服务器端根据所述特征值数据以及所述cir数据对所述神经网络模型进行训练。
31.可以理解地,上述片内执行机器学习算法的方法的示例性技术方案,与前述图2或图4所示的片内执行机器学习算法的uwb芯片20的技术方案属于同一构思,因此,上述对于片内执行机器学习算法的方法的技术方案未详细描述的细节内容,均可以参见前述图2或图4所示的片内执行机器学习算法的uwb芯片20方法的技术方案的描述。本发明实施例对此不做赘述。
32.需要说明的是:本发明实施例所记载的技术方案之间,在不冲突的情况下,可以任意组合。
33.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
