一种贝叶斯优化的rf与lightgbm疾病预测方法
技术领域
1.本发明涉及疾病预测技术领域,具体涉及一种贝叶斯优化的rf与lightgbm疾病预测方法。
背景技术:
2.生物医学领域是人工智能的重要应用领域,随着人类微生物组计划、人肠道宏基因组学计划的相继开展,研究表明,肠道微生物具有调节宿主免疫、代谢、内分泌和神经等生物学功能,正常微生态失调可以导致多种疾病的发生,利用肠道微生物数据构建疾病预测模型是研究热点之一。高通量测序技术产生的大量复杂且高维的微生物组数据,为研究微生物菌群与人体之间的相互关系提供了新的契机,但同时也使传统的统计学方法难以满足这些数据分析的需求。
3.从理论方面讲,传统的统计方法已经不适用于高通量测序技术产生的大量复杂、高维且稀疏的微生物组数据分析,近年来,机器学习在微生物组数据分析领域已经得到广泛应用并取得一定成果,包括利用贝叶斯网络、随机森林等算法对直肠癌进行预测,利用k近邻算法建立了2型糖尿病的预测模型等。但目前国内外学者利用机器学习算法与深度学习算法构建的疾病预测模型在预测性能方面仍有改进空间。
4.从现实方面讲,虽然关于人类微生物组的数据有很多,但是将这些数据转换为生物学和临床上有意义的原理仍然是一个重大挑战。因此,探索适用于微生物组数据分析的机器学习算法可以为疾病的诊断进行辅助分析,提高模型性能,对于疾病的临床检测,诊断和治疗具有十分重要的现实意义。
技术实现要素:
5.有鉴于此,本发明提供一种贝叶斯优化的rf与lightgbm疾病预测方法,利用贝叶斯优化算法与随机森林和lightgbm相结合,在提高了模型的性能和泛化能力同时,能够准确地对疾病预测进行风险侦测。
6.为了达到上述目的,本发明所采用的技术方案是:一种贝叶斯优化的rf与lightgbm疾病预测方法,包括以下步骤:
7.s1、获取包含多个带有标签值的原始样本的原始数据集,构造微生物相对丰度矩阵,采用最大互信息系数进行特征选择,对数据集进行过滤并划分数据集,将数据集分为训练数据集和测试数据集;
8.s2、利用smote方法对训练数据集进行过采样处理,获得平衡的数据集;
9.s3、用贝叶斯优化算法选择随机森林和lightgbm学习器的最优超参数;
10.s4、用所选的最优超参数分别代入随机森林与lightgbm算法训练模型;
11.s5、分别在训练集上进行10折交叉验证、在测试集进行模型预测性能评估。
12.进一步的,所述步骤s1中的特征选择包括以下步骤:
13.s11、对于随机变量x和y所构成的二维散点图构建网格尺度r
×
c划分;
14.s12、计算所划分的各个网格里的互信息公式:
[0015][0016]
将最大的互信息值按照下列公式进行归一化处理:
[0017][0018]
s13、用多种不同的划分方式中最大的归一化互信息值做为最大互信息系数:
[0019]
mic(x;y)=maxr×
c<f(n)
n(x;y)
ꢀꢀꢀꢀꢀꢀ
(3)
[0020]
其中,f(n)=n
0.6
,n为样本数量,x为一个物种,y是样本的健康或者患病状态,n(x;y)是随机变量的x和y归一化后的最大互信息,mic(x;y)是随机变量的x和y的最大互信息,r、c是对于随机变量x和y所构成的二维散点图构建的网格尺度,p(x,y)是x和y的联合概率分布函数,p(x)和p(y)分别是x和y的边缘概率分布函数、max为最大值函数。
[0021]
进一步的,所述步骤s2中的预处理包括以下步骤:
[0022]
s21、smote先在特征空间上获取所有少数类样本x;
[0023]
s22、对于每个少数类样本x
i,raw
,找到其k个少数类近邻,并从这k个近邻中随机的选择一个样本x
i,rand
;
[0024]
s23、连接少数类样本x
i,raw
与随机样本x
i,rand
,此连接线段上的随机一点x
i,new
即为新合成的样本:
[0025]
x
i,new
=x
i,raw
rand(0,1)
×
(x
i,raw-x
i,rand
)
ꢀꢀꢀ
(4)
[0026]
其中,x
i,raw
是第i个原始样本,x
i,rand
是从第i个的k个少数类近邻中随机选择的随机样本,x
i,new
是由第i个合成的新少数类样本,rand(0,1)表示生成一个在(0,1)内的随机数,且这个随机数属于实数。
[0027]
进一步的,所述步骤s3中的贝叶斯优化包括以下步骤:
[0028]
s31、选择树结构概率密度估计(tpe)作为概率代理模型进行贝叶斯优化,tpe算法的概率分布定义如式(5)所示:
[0029][0030]
其中,l(x)为观测值{x(i)}形成的密度,其对应的风险损失值y=f(x(i)),且y《y
*
,g(x)为使用除{x(i)}外剩余的观测值形成的密度;
[0031]
tpe算法选择y
*
作为当前观测风险值y的某个分位数γ,满足p(y《y
*
)=γ,通过tpe算法的l(x)和g(x),将超参数集合划分为风险小和风险大的两部分;
[0032]
s32、根据ei采集函数选取下一个超参数,通过最大期望提升进一步优化,最大期望提升ei的定义如式6所示:
[0033][0034]
为了能获得最大期望提升,通过评估每一个超参数x,在每次迭代中,算法将返回具有最大ei的超参数值:
[0035][0036]
s33、重复上述过程,不断利用代理模型的后验分布选择超参数,直到得到最优解。
[0037]
进一步的,所述步骤s1中数据集70%作为训练集,30%作为测试集。
[0038]
进一步的,所述步骤s1中微生物相对丰度矩阵的每列代表一个物种,矩阵的每行代表一个健康或者患病的样本,将健康与患病分别标为0与1。
[0039]
进一步的,所述步骤s5中将训练集进行10折交叉验证,并取独立重复10次结果的平均值来评估模型的泛化性能。
[0040]
与现有技术相比,本发明的有益效果是:
[0041]
本发明中利用贝叶斯优化算法与随机森林和lightgbm相结合,构建疾病预测模型,在提高了模型的性能和泛化能力同时,能够准确地对疾病预测进行风险侦测;
[0042]
本发明利用最大互信息系数、smote方法过采样少数类样本对数据进行预处理,提高了数据的有效性和准确率;利用贝叶斯优化算法选择贝叶斯算法以及lightgbm算法的全局最优超参数超参数,避免网格搜索针对非凸问题易得到局部最优以及参数过多耗时长的问题,降低了模型的训练误差,缩短了训练时间;结合了两种方法进行了交叉验证,提高了模型的性能和泛化能力;
[0043]
本发明中进一步提高了该疾病预测模型的预测精准度,bo_rf方法的各项性能指标都明显有所提升,预测性能更好。
附图说明
[0044]
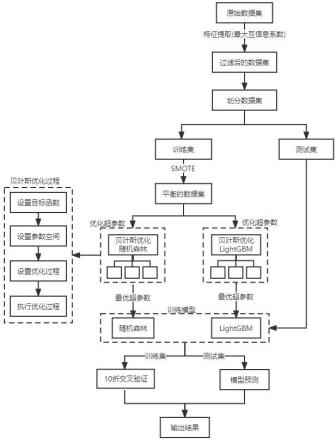
图1是本发明疾病预测方法的流程示意图;
具体实施方式
[0045]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0046]
具体实施方式:
[0047]
实施例1:
[0048]
一种贝叶斯优化的rf与lightgbm疾病预测方法,包括以下步骤:
[0049]
s1、获取包含多个带有标签值的原始样本的原始数据集,构造微生物相对丰度矩阵,采用最大互信息系数进行特征选择,对数据集进行过滤并划分数据集,将数据集分为训
练数据集和测试数据集;所述特征选择包括以下步骤:
[0050]
s11、对于随机变量x和y所构成的二维散点图构建网格尺度r
×
c划分;
[0051]
s12、计算所划分的各个网格里的互信息公式:
[0052][0053]
将最大的互信息值按照下列公式进行归一化处理:
[0054][0055]
s13、用多种不同的划分方式中最大的归一化互信息值做为最大互信息系数:
[0056]
mic(x;y)=maxr×
c<f(n)
n(x;y)
ꢀꢀꢀꢀꢀꢀ
(3)
[0057]
其中,f(n)=n
0.6
,n为样本数量,x为一个物种,y是样本的健康或者患病状态,n(x;y)是随机变量的x和y归一化后的最大互信息,mic(x;y)是随机变量的x和y的最大互信息,r、c是对于随机变量x和y所构成的二维散点图构建的网格尺度,p(x,y)是x和y的联合概率分布函数,p(x)和p(y)分别是x和y的边缘概率分布函数、max为最大值函数。
[0058]
最大互信息系数(maximal information coefficient,mic)是在互信息的基础之上,利用网格化分方法克服了互信息对于连续变量离散化的方式敏感的问题,是一种归一化的最大互信息,具有高鲁棒性,低计算复杂度的优点。
[0059]
s2、利用smote方法对训练数据集进行预处理,获得平衡的数据集,所述预处理包括以下步骤:
[0060]
s21、smote先在特征空间上获取所有少数类样本x;
[0061]
s22、对于每个少数类样本x
i,raw
,找到其k个少数类近邻,并从这k个近邻中随机的选择一个样本x
i,rand
;
[0062]
s23、连接少数类样本x
i,raw
与随机样本x
i,rand
,此连接线段上的随机一点x
i,new
即为新合成的样本:
[0063]
x
i,new
=x
i,raw
rand(0,1)
×
(x
i,raw-x
i,rand
)
ꢀꢀꢀꢀ
(4)
[0064]
其中,x
i,raw
是第i个原始样本,x
i,rand
是从第i个的k个少数类近邻中随机选择的随机样本,x
i,raw
是由第i个合成的新少数类样本,rand(0,1)表示生成一个在(0,1)内的随机数,且这个随机数属于实数。
[0065]
smote(synthetic minority over-sampling technique)即合成少数类样本的过采样技术,是通过对训练集里的少数类别样本进行插值来合成新的同类别样本的过采样方法。
[0066]
s3、用贝叶斯优化算法选择随机森林和lightgbm学习器的最优超参数,所述贝叶斯优化包括以下步骤:
[0067]
s31、选择树结构概率密度估计(tpe)作为概率代理模型进行贝叶斯优化,tpe算法的概率分布定义如式(5)所示:
[0068][0069]
其中,l(x)为观测值{x(i)}形成的密度,其对应的风险损失值y=f(x(i)),且y《y
*
,g(x)为使用除{x(i)}外剩余的观测值形成的密度;
[0070]
tpe算法选择y
*
作为当前观测风险值y的某个分位数γ,满足p(y《y
*
)=γ,通过tpe算法的l(x)和g(x),将超参数集合划分为风险较小和风险较大的两部分;
[0071]
s32、根据ei采集函数选取下一个超参数,通过最大期望提升进一步优化,最大期望提升ei的定义如式6所示:
[0072][0073]
为了能获得最大期望提升,超参数x在l(x)的概率要尽可能大,而在g(x)的概率要尽可能小。通过评估每一个超参数x,在每次迭代中,算法将返回具有最大ei的超参数值:
[0074][0075]
s33、重复上述过程,不断利用代理模型的后验分布选择超参数,直到得到最优解。
[0076]
对已给定优化的目标函数,贝叶斯优化使用概率代理模型的后验概率分布来构造采集函数,并使用该采集函数选取最有可能使得目标函数达到最优值的超参数加以评估,从而快速找到超参数的最优解,避免目标函数不必要的评估;随机森林(random forest,rf)方法简单、计算开销小,易于实现;lightgbm(light lradient boosting machine)用基于梯度的单边采样进行数据选择和互斥特征捆绑进行特征选择,该算法与传统的梯度提升决策树算法相比,准确度更高,训练速度也更快,且占用内存较小。
[0077]
s4、用所选的最优超参数分别代入随机森林与lightgbm算法训练模型;
[0078]
s5、分别在训练集上进行10折交叉验证、在测试集进行模型预测性能评估。
[0079]
进一步的,所述步骤s1中数据集70%作为训练集,30%作为测试集。
[0080]
进一步的,所述步骤s1中微生物相对丰度矩阵的每列代表一个物种,矩阵的每行代表一个健康或者患病的样本,将健康与患病分别标为0与1。
[0081]
进一步的,所述步骤s5中将训练集进行10折交叉验证,并取独立重复10次结果的平均值来评估模型的泛化性能。
[0082]
实施例2
[0083]
首先,构造微生物相对丰度矩阵。构建疾病预测模型需要各个样本的微生物含量与患病状态的信息,因此利用原始数据集中的微生物相对物种丰度数据,构造出各个疾病数据集的微生物相对丰度矩阵,矩阵的每列代表一个物种,矩阵的每行代表一个健康或者患病的样本,将健康与患病分别标为0与1,处理后的数据集信息如表1。
[0084]
表1疾病与肠道微生物数据集信息
[0085][0086]
所用的原始肠道微生物数据集包括肝硬化、直肠癌、炎症性肠病等5种疾病的6个宏基因组数据集。
[0087]
该数据集共包含232个样本,其中114个健康样本,118个患病样本,肠道微生物所包含的物种个数为542。coiorectal数据集中共包含121个样本,其中73个健康样本,48个患病样本,肠道微生物包含的物种个数是503。ibd数据集中共包含110个样本,其中85个健康样本,25个患病样本,肠道微生物包含的物种个数是443。obesity数据集共包含253个样本,其中89个健康样本,164个患病样本,肠道微生物包含的物种个数是465。t2d数据集共包含344个样本,其中健康样本174个,患病样本170个,肠道微生物包含的物种个数是572。wt2d数据集共包含96个样本,其中43个健康样本,53个患病样本,肠道微生物包含的物种个数是381。
[0088]
其次,mic法特征选择。微生物组所研究的样本通常包含很多特征,且样本数一般远少于特征数,并不是所有的微生物在健康个体与患病个体中都存在显著差别,因此通过特征选择过滤掉与健康状态弱相关或者无关的物种,降低学习任务的难度,从而有效的提高算法性能。选用最大信息系数作为衡量特征与健康状态之间关联程度的指标。x为一个物种,y是样本的健康或者患病状态,0代表健康,1代表患病;
[0089]
特征x与类别变量y之间的最大信息系数为:
[0090]
mic(x;y)=maxr×
c<f(n)
n(x;y)
[0091]
选择阈值为0.1,即选择mic≥0.1的物种作为后续建模的物种,经过特征选择后的数据信息如表2。
[0092]
表2特征提取后的数据信息
[0093][0094]
第三,smote过采样。由表1可知,colorectal、ibd、obesity这三个数据集的多数类样本与少数类样本的比例分别为1.52、3.4、1.84,正反样本的类别不平衡,因此首先按照训练集:测试集=7:3划分数据集,从表3可以看出colorectal、ibd、obesity数据集的训练集中类别比例不平衡,然后用smote方法对训练集的少数类别进行过采样处理,过采样后的数据集信息如表3。
[0095]
表3 smote过采样后的数据信息
[0096][0097]
由表3知,各数据集经过smote优化后的多数类样本与少数类样本的比例平衡。cirrhosis、t2d、wt2d三个数据的训练集过采样后保持不变,colorectal、ibd、obesity三个数据的训练集过采样少数类样本后,类别比例基本平衡。
[0098]
第四、贝叶斯优化分类学习器超参数。先用贝叶斯优化算法得到lightgbm算法与random forest算法超参数的最优值,两种算法优化的超参数如表4,表5所示。
[0099]
表4贝叶斯优化算法优化lightgbm算法的超参数
[0100][0101]
表5贝叶斯优化算法优化random forest算法的超参数
[0102][0103][0104]
第五,贝叶斯选择的超参数分别代入随机森林与lightgbm分类器。将贝叶斯优化的超参数分别带入随机森林与lightgbm算法,将训练集进行10折交叉验证并取独立重复10次结果的平均值来评估模型的泛化性能,测试集用来检测模型的预测性能。
[0105]
最后,实验结果对比与分析,分别运用本技术bo_rf模型与n_estimators设为200,其他超参数保持默认值的随机森林、默认参数的lightgbm以及metaml框架、met2img框架、基于回归的多示例学习—regmil框架、popphy-cnn框架和deepmicro框架,利用同一数据集进行实证分析的框架进行对比,对比结果如表6至11,表中括号内数据为标准差。
[0106]
表6 cirrhosis数据集对比表
[0107][0108][0109]
表7 ibd数据集对比表
[0110][0111]
表8 obesity数据集对比表
[0112][0113][0114]
表9 wt2d数据集对比表
[0115][0116]
表10 crc数据集对比表
[0117][0118][0119]
表11 t2d数据集对比表
[0120][0121]
从数据集角度看,从表7、表8、表10可知,在ibd、obesity、crc数据集中,bo_rf方法的各项性能指标都明显高于其他几种方法,而bo_lgbm方法的各项性能指标也仅低于bo_rf方法,仍高于其他方法。在ibd数据集上,accuracy从0.847(regmil-rf)提升到0.97,precision、recall、f1分别从0.72、0.81、0.75(metaml-rf)提升到0.97,auc从0.890
(metaml-rf)提升到0.993。在obesity数据集上,accuracy从0.655(deepmicro-rf(cae))提升到0.823,precision、recall、f1分别从0.54、0.64、0.54(metaml-rf)提升到0.824、0.823、0.822,auc从0.683(popphy-rf)提升到0.915。在crc数据集上,accuracy、precision、recall、f1、auc分别从0.805、0.82、0.81、0.79、0.873(metaml-rf)提升到0.891、0.894、0.891、0.891、0.95。由表6可知,在cirrhosis数据集中,bo_lgbm方法的precision、recall、f1为0.89,auc为0.953,都略高于其他方法,accuracy最高为regmil-rf的0.928。由表9知,在wt2d数据集中,bo_lgbm方法的accuracy、precision、recall、f1分别为0.767、0.768、0.767、0.767,都高于其他方法,auc最高为deepmicro-rf(cae)的0.829。由表11知,在t2d数据集中,rf方法的各个性能指标都最高,另外5种方法以及本发明的。
[0122]
从算法角度看,bo_rf方法在ibd、obesity、crc数据集上表现的更好,bo_lgbm方法在wt2d、cirrhosis数据集上表现的更好,而t2d相较于其他数据集在各种方法中各指标的提升都较小,说明这个数据集可能存在区别于其他5个数据集的特性。
[0123]
从测试集的预测效果可以看出,在cirrhosis、obesity、wt2d、t2d数据集上bo_rf的预测性能更好,在ibd数据集上bo_lgbm的预测性能更好,而crc数据集上rf的预测性能更好,但是在bo_rf与bo_lgbm相差并不大,且rf在交叉验证中并不如bo_rf,综合看来,bo_rf的性能更好。分析结果显示本专利各项指标和性能均高于现有的同类算法和模型。本专利的研究意义包括理论价值层面与现实方面的实际意义。
[0124]
本发明的疾病预测模型,选择全局最优超参数超参数,避免网格搜索针对非凸问题易得到局部最优以及参数过多耗时长的问题,降低了模型的训练误差,缩短了训练时间,提高了模型的性能和泛化能力,综合性能更好。
[0125]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本发明中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本发明所示的这些实施例,而是要符合与本发明所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。