1.实施例概括而言涉及机器学习。更具体而言,实施例涉及优化神经网络技术,以便在工业、商业和消费者应用中进行部署。
背景技术:
2.机器学习(machine learning,ml)技术的最新发展,尤其是神经网络,已显示出应用于广泛的计算任务的前景。神经网络,例如深度神经网络,可能涉及复杂的基于矩阵的乘法和卷积操作。一旦经过训练,神经网络就可以作为推理神经网络模型被部署。然而,深度神经网络(和其他神经网络)的高计算复杂性为工业、商业和/或消费者应用中的推理模型的部署提供了挑战。低精度的推理模型已被考虑,但缺乏适当的准确度和/或具有过多的存储器或带宽要求。
附图说明
3.通过阅读以下说明书和所附权利要求,并且通过参考以下附图,实施例的各种优点对于本领域技术人员而言将变得清楚,附图中:
4.图1提供了图示出根据一个或多个实施例的用于优化推理神经网络模型的系统的图;
5.图2a-2c提供了根据一个或多个实施例的非对称量化的各方面的图;
6.图3a-3b提供了根据一个或多个实施例的每输入通道量化的各方面的图;
7.图4提供了图示出根据一个或多个实施例的用于优化推理神经网络模型的系统的图;
8.图5提供了图示出根据一个或多个实施例的用于调节推理神经网络模型的过程的流程图;
9.图6a-6b提供了图示出根据一个或多个实施例的用于优化推理神经网络模型的系统的图;
10.图7提供了图示出根据一个或多个实施例的用于优化推理神经网络模型的过程的流程图;
11.图8提供了图示出根据一个或多个实施例的用于优化推理神经网络模型的示例系统的框图;
12.图9是图示出根据一个或多个实施例的用于优化推理神经网络模型的示例半导体装置的框图;
13.图10是图示出根据一个或多个实施例的示例处理器的框图;并且
14.图11是图示出根据一个或多个实施例的基于多处理器的计算系统的示例的框图。
具体实施方式
15.诸如图像识别和自然语言处理(natural language processing,nlp)之类的应用
可以使用深度学习技术,这是人工智能(artificial intelligence,ai)机器学习的一个子集,其中诸如深度神经网络(deep neural network,dnn)之类的神经网络包含多个中间层,以对输入数据进行复杂操作。由于深度神经网络中涉及的数据量相对较大,所以数据通常可以被组织和处理为n维阵列(例如,张量),这些阵列可被进一步划分为矩阵。在这种情况下,常见的矩阵操作可包括矩阵乘法操作(例如,经由通用矩阵乘法/gemm内核的“matmul”),卷积操作(例如,经由卷积内核),等等。推理神经网络模型可包括低精度量化,如下文所述,并且为部署提供适当优化的性能。
16.参考本文描述的组件和特征(包括但不限于附图和关联的描述),图1根据一个或多个实施例示出了用于利用非对称量化来优化推理神经网络模型的示例系统110的框图。系统110可包括经训练的神经网络模型112、非对称量化模块114、以及推理神经网络引擎116。经训练的神经网络模型112可以是深度神经网络,并且可以根据本领域技术人员已知的神经网络训练过程被训练。经训练的神经网络模型112通常可包括用于处理输入张量或其他输入数据的输入层或阶段,包括用于诸如例如卷积操作或者矩阵乘法操作之类的计算操作的权重的中间层,以及用于处理或呈现输出数据的输出层或阶段。
17.非对称量化模块114可以执行一个或多个过程,用于基于经训练的神经网络模型112来优化推理神经网络模型,例如在推理神经网络引擎116中实现的推理模型。推理神经网络引擎116可以接收输入张量或其他输入数据132,根据推理模型(基于经训练的模型)进行计算或其他操作,并且提供输出张量或其他输出数据136。推理神经网络引擎116可包括输入层量化122、模型权重量化124、以及输出层恢复126。输入张量或其他输入数据132可以作为相对高精度的值(例如浮点值或者高精度整数值)被接收。类似地,输出张量或其他输出数据136可以是相对高精度的值(例如浮点值或者高精度整数值)。浮点值可以例如是64比特浮点值(fp64)或者32比特浮点值(fp32);高精整数值可以例如是64比特或者32比特整数值(int64或者int32)。
18.作为相对高精度值接收的输入张量或其他输入数据132可以被输入层量化122量化为低精度整数值,例如,8比特整数值(int8)。推理模型可以进行计算或其他操作,例如矩阵乘法操作和/或卷积操作,其中适用的内核(例如,gemm或者卷积内核)的权重已经经由模型权重量化124被量化为低精度权重,例如,8比特整数值(int8)。输出层恢复126处理将低精度的整数输出值转换回高精度(例如,浮点)输出值。
19.非对称量化模块114控制如何实现或执行输入层量化122、模型权重量化124和输出层恢复126。输入层量化122可以通过使用非对称量化对输入值进行量化来实现,以使得每个高精度输入值(例如,fp32)根据以下公式被量化为无符号整数值(例如,uint8):
20.(1)
ꢀꢀꢀꢀ
x
uint8
=s
x
*(x
fp32
z)
21.其中x
uint8
是量化后的整数输入值,s
x
是输入缩放因子,x
fp32
是浮点输入值,并且z是偏置或偏移。可以应用舍入函数来向上或向下舍入到最接近的整数值。例如,可以基于输入值x
fp32
的动态范围,设置输入缩放因子s
x
和偏置z,以使得量化后的uint8值适合在0到255的范围内:
22.(2)
23.其中min
fp32
和max
fp32
分别是最小和最大输入(浮点)值。在一些实施例中,可以根据
其他标准来设置输入缩放因子s
x
和偏置z。
24.模型权重量化124可以通过使用对称量化对浮点权重进行量化来实现,以使得每个高精度权重值(例如,fp32)根据以下公式被量化成有符号整数值(例如,int8):
25.(3)w
int8
=sw*w
fp32
。
26.其中w
int8
是量化后的整数权重值,sw是权重缩放因子,并且w
fp32
是浮点权重值。可以应用舍入函数来向上或向下舍入到最接近的整数值。例如,可以基于权重值w
fp32
的动态范围设置权重缩放因子sw,以使得量化后的int8值适合在-128到 127的范围内。模型权重量化124可以在推理模型被建立时被执行一次。
27.可以根据推理模型来计算输出值。例如,推理模型可以经由卷积内核w根据以下公式进行卷积操作:
28.(4)
ꢀꢀꢀꢀyint32
=conv(x
uint8
,w
int8
)
29.其中y
int32
(例如,32比特整数)是整数输出值,conv(x,w)表示涉及输入值x和内核权重w的卷积操作。作为一个示例,输入值x可以表示二维(2d)数据集合(例如,图像),并且内核w可以表示二维(2d)权重集合。
30.在下文中参考图2a-2c图示和描述与非对称量化的一些方面有关的进一步细节。参考本文描述的组件和特征(包括但不限于附图和关联的描述),图2a中示出了图示出根据一个或多个实施例的卷积操作中使用的填充的图。对于卷积操作,可以用值填充(例如,围绕外边界)输入数据集合,以适应涉及沿着外边界的输入值的内核的卷积操作。图2a描绘了二维输入数据集合212,它可以表示例如图像。为了说明,数据集合212被显示为数据值(例如,像素)的16x16集合,但数据集合的尺寸可以是任何大小(并且尺寸不需要是相等大小,而可以是例如32x64)。方框214示出了可用于卷积操作中的内核的轮廓;为了说明,内核大小被显示为3x3的内核,但内核可以是任何大小(并且内核尺寸不需要是相等大小,而可以是例如5x7)。
31.如图2a所示,当内核以左上方数据值为中心时,有一些内核值不与任何输入值重叠。从而,为了进行卷积操作,这些值被添加为“填充”,如图2a所示,该图描绘了带有填充216的二维输入数据。填充数据集合216被显示为一系列额外的数据元素(例如,像素),围绕着数据集合212的外部边界行和列。填充的行和列的数目取决于内核的大小。对于3x3内核的示例,向二维数据集合212的顶部和底部添加单个填充行,并且向二维数据集合212的每一侧添加单个填充列。填充值可以被设置为零,或者可以被设置为恒定值,等等。对于如本文所述的推理引擎,填充值通常可以被设置为零。3x3内核可如何覆盖填充数据集合216的示例在图2a中被显示为一系列的方框218a-218i。更一般地,沿着输入的每个边界要被添加作为填充的行或列的数目等于trunc(k/2),其中k是内核大小,并且trunc()表示结果的截断(例如,对于3x3内核,k=3)。
32.一旦推理模型的所有卷积和/或其他计算操作完成,输出值就可被转换(即,解量化)以恢复到高精度(例如,浮点)值。通过非对称量化模块114,输出层恢复126可以通过根据以下公式将整数输出值转换为高精度输出值(例如,fp32)而被作为恢复函数来实现:
33.(5)
ꢀꢀꢀꢀyfp32
=s
x
*sw*[y
int32-z*w
acc
]
[0034]
其中,y
fp32
是高精度浮点输出值,y
int32
是从推理模型输出的整数值,s
x
和sw分别是输入和权重缩放因子,并且w
acc
是权重累积表。权重累积表w
acc
被定义为:
[0035]
(6a)
[0036][0037]
其中w
int8
是适用的内核索引i=(kh
start
,kh
end
)和j=(kw
start
,kw
end
)的范围内的整数内核权重的集合。
[0038]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图2b图示了根据一个或多个实施例的权重累积表(w
acc
)222。如图所示,作为一个示例,权重累积表222对应于3x3内核,单位跨度,其中在输入数据集合的边界行/列周围添加单行填充(例如图2a中的填充数据集合216所示)。单位跨度指的是,在卷积期间,内核每次被移位单个索引值。
[0039]
如图2b所示,w
acc 222的左上角元素,wacc[0,0],对应于图2a中经由方框218a覆盖的内核。向右移动,w
acc 222的下一个元素wacc[0,1]对应于经由方框218b覆盖的内核,并且w
acc 222的下一个元素wacc[0,2]对应于经由方框218c覆盖的内核。类似地,w
acc 222的元素wacc[1,0]对应于经由方框218d覆盖的内核,元素wacc[1,1]对应于经由方框218e覆盖的内核,元素wacc[1,2]对应于经由方框218f覆盖的内核,并且移动到权重累积表的底部,元素wacc[2,0]对应于经由方框218g覆盖的内核,元素wacc[2,1]对应于经由方框218h覆盖的内核,并且元素wacc[2,2]对应于经由方框218i覆盖的内核。将会理解,w
acc
值wacc[0,0]、wacc[0,2]、wacc[2,0]和wacc[2,2]各自对应于卷积中的单个点,在该处内核以各个角输入值之一为中心。还将会理解,w
acc
值wacc[0,1]对应于卷积中的点,在该处内核以输入值的顶行为中心(除了角落值以外),wacc[2,1]对应于卷积中的点,在该处内核以输入值的底行为中心(除了角落值以外),wacc[1,0]对应于卷积中的点,在该处内核以输入值的最左列为中心(除了角落值以外),并且wacc[1,2]对应于卷积中的点,在该处内核以输入值的最右列为中心(除了角落值以外)。最后,还将会理解,w
acc
值wacc[1,1]对应于卷积中的点,在该处内核以除了边界值以外的任何输入值为中心。输出层的坐标可以对应于输入层(即,输入数据集合)的坐标,而没有填充。可以基于内核大小、跨度和输出数据集合的大小(例如,尺寸)来生成输出层的输出坐标到权重累积表的索引的映射(例如,以反映权重累积表的值到如上所述的数据集合的坐标的应用),以使得能够根据公式5快速计算高精度输出值y
fp32
。在表224中示出了权重累积表222的值的排列,其中个体表元素的位置大致对应于到各个输出坐标的映射。使用以上参考图2b所描述的权重累积表允许有效地忽略涉及填充数据元素的计算,从而进一步提高执行计算的效率和速度。
[0040]
根据上述公式(6),权重累积表222中的每个条目被计算为与用灰色显示的w
acc 222的每个元素的个体方框相对应的个体内核权重的总和。例如,wacc[0,0]是用灰色显示的4个内核权重之和,wacc[0,1]是用灰色显示的6个内核权重之和,wacc[1,1]是用灰色显示的所有9个内核权重之和,等等。图2c图示了用于权重范围为1至5的示例3x3内核232的权重累积表234的示例,并且权重累积表234的相应值是基于内核232的值来计算的。例如,值wacc[1,1]是内核中的所有权重的总和,这对于示例内核232而言是17,如相应的权重累积表234中所示(中心值是wacc[1,1])。
[0041]
如上文参考图2a-2c描述的图和示例所示,3x3内核大小导致权重累积表有9个元素。例如,在内核大小为5x5的情况下,相应的权重累积表将包括25个元素。在跨度比单位跨
度长的那些情况下,权重累积表值和从输出坐标到权重累积表的索引的映射可以被相应地调整。
[0042]
在一些实施例中,推理模型可具有多个内部级别,例如,多个卷积级别,对于每个级别使用不同的内核。在这种情况下,每个级别可具有单独的每级别权重累积表,并且可以通过添加每个每级别权重累积表的个体元素来构造聚合权重累积表(将被用于计算输出值)。例如,聚合权重累积表的元素可被计算为:
[0043]
(6b)
[0044][0045]
其中,wn()是级别n的每级别权重累积表,l是内部级别的总数,并且(i,j)是每个每级别权重累积表的索引。可以例如如上文公式6a中所记载那样来计算每个每级别权重累积表wn()。
[0046]
更一般而言,在输入是具有多个通道的张量的情况下,相应的权重累积表将具有额外的维度,这样,权重累积表将具有在额外维度中延伸的层级的条目集合,对于每个通道有一个层级相对应。例如:如果输入张量是具有颜色值的图像,具有3个通道,例如红色通道、绿色通道和蓝色通道,并且如果内核大小为5x5(单位跨度),则相应的权重累积表将是5x5x3矩阵,这样,权重累积表将在额外的矩阵维度(这里是第三维度)中具有3个集合(或者层级)的5x5条目,其中对于每个通道将对应有一个集合(或者层级)的5x5条目。
[0047]
在输入是多通道张量的情况下,在一些实施例中,推理引擎的额外优化可以通过在每个通道的基础上考虑到每个通道的输入值的相对动态范围来执行。图3a中显示的是一个图表,它对于具有两个输入通道c1(标签312)和c2(标签316)的示例张量,描绘了每个输入通道的值的范围。如该示例中所示,输入通道c1的输入值范围从-8.0(标签314)到 1.0(标签315),并且输入通道c2的输入值范围从-1.0(标签318)到 1.0(标签319)。如果使用上文参考图1、图2a-2c描述的输入量化,则两个通道将被应用有相同的缩放因子和相同的偏置,从而使得通道之一的量化可能相对于另一个通道被压缩或者不平衡。然而,可以通过执行每输入通道量化来考虑到每个通道的动态范围,其中量化是为每个输入通道单独计算的,导致了精度的提高。
[0048]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图4根据一个或多个实施例示出了用于利用非对称量化与每输入通道量化相组合来优化推理神经网络模型的示例系统410的框图。系统410可包括经训练的神经网络模型112(如上所述)、非对称量化模块114(如上所述)、每输入通道量化模块415、以及推理神经网络引擎416。每输入通道量化模块415可以与非对称量化模块114相结合执行一个或多个过程,用于基于经训练的神经网络模型112来优化推理神经网络模型,例如在推理神经网络引擎416中实现的推理模型。推理神经网络引擎416可以接收多通道输入张量或其他多通道输入数据432,根据推理模型(基于经训练的模型)进行计算或其他操作,并且提供输出张量或其他输出数据436。推理神经网络引擎416可包括输入层量化422、模型权重量化424、以及输出层恢复426。输入张量或其他输入数据432可以作为相对高精度的值(例如浮点值或者高精度整数值)被接收。类似地,输出张量或其他输出数据436可以是相对高精度的值(例如浮点值或者高精度整数
值)。浮点值可以例如是64比特浮点值(fp64)或者32比特浮点值(fp32);高精度整数值可以例如是64比特或者32比特整数值(int64或者int32)。
[0049]
作为相对高精度值接收的输入张量或其他输入数据432可以在每通道基础上被输入层量化422量化为低精度整数值,例如,8比特整数值(int8)。推理模型可以进行计算或其他操作,例如矩阵乘法操作和/或卷积操作,其中适用的内核(例如,gemm或者卷积内核)的权重已经经由模型权重量化424被量化为低精度权重,例如,8比特整数值(int8)。输出层恢复426处理将低精度的整数输出值转换回高精度(例如,浮点)输出值(例如,浮点)
[0050]
非对称量化模块114与每输入通道量化模块415相结合控制如何实现或执行输入层量化422、模型权重量化424和输出层恢复426。输入层量化422可以通过使用非对称量化在每通道基础上对输入值进行量化来实现,以使得每个高精度输入值(例如,fp32)根据以下公式被量化为无符号整数值(例如,uint8):
[0051]
(7)这里是输入通道c的量化整数输入值,是输入通道c的输入缩放因子,是输入通道c的浮点输入值,并且是输入通道c的偏置或偏移。可以应用舍入函数来向上或向下舍入到最接近的整数值。对于每个输入通道c,可以对于输入基于输入值的动态范围来设置输入缩放因子和偏置以使得量化后的uint8值适合在0-255的范围内:
[0052]
(8)以及其中和分别是输入通道c的最小和最大输入(浮点)值。在一些实施例中,可以基于训练输入数据420来确定每通道的最小和最大输入值和该输入数据可以是用于训练经训练的神经网络模型112的数据。
[0053]
作为一个示例,图3b示出了使用上述公式(7)和(8)中的公式对图3a中反映的输入值在每通道基础上计算的量化输入值。对于通道1(c1),如图3a所示,最小值314是(-8.0),最大值315是 1.0。对于通道c1在图3b中示出了缩放因子、偏置和量化值(图表322)。列xfp(标签324)示出了浮点输入值,并且列xuint8(标签328)示出了相应的量化值,其范围从0到255。如图表322中所示,对于通道c1,输入值0.0被量化为227。对于通道2(c2),如图3a所示,最小值318是(-1.0),最大值319是 1.0。对于通道c2在图3b中示出了缩放因子、偏置和量化值(图表332)。列xfp(标签334)示出了浮点输入值,并且列xuint8(标签338)示出了相应的量化值,其范围从0到255。如图表332中所示,对于通道c2,输入值0.0被量化为128。
[0054]
返回到图4,模型权重量化424可以通过使用对称量化在每通道基础上对浮点权重进行量化来实现,以使得每个高精度权重值(例如,fp32)根据以下公式被量化成有符号整数值(例如,int8):
[0055]
(9)其中是输入通道c的量化整数权重值,是输入通道c的权重缩放因子,并且是输入通道c的浮点权重值。可以应用舍入函数来向上或向下舍入到最接近的整数值。每通道权重缩放因子可以通过以下公式
来确定:
[0056]
(10)其中
[0057]
(11)从而,每通道权重缩放因子的计算方式可以保证乘法的结果可以沿着输入通道被累积,并且结果的缩放比例是s
xw
。如公式11所示,它不比按张量的缩放因子s
x
小,因此更理想。模型权重量化424可以在推理模型被建立时被执行一次。
[0058]
如上文参考图1所述,可根据推理模型来计算输出值。例如,对于每个输入通道,推理模型可以经由卷积内核w根据以下公式进行卷积操作:
[0059]
(12)其中(例如,32比特整数)是整数输出值,并且conv(x,w)表示对于通道c的涉及输入值x和内核权重w的卷积操作。一旦推理模型的所有卷积和/或其他计算操作完成,输出值就可被转换(即,解量化)以恢复到高精度(例如,浮点)值。通过非对称量化模块114和每输入通道量化模块415,输出层恢复426可以通过根据以下公式将整数输出值转换为高精度输出值(例如,fp32)而被作为恢复函数来实现:
[0060]
(13)
ꢀꢀꢀꢀyfp32
=s
x
*sw*[y
int32-z*w
acc
]
[0061]
其中y
fp32
是高精度浮点输出值,y
int32
是从推理模型输出的整数值,s
x
和sw分别是输入和权重缩放因子,并且w
acc
是如上所述的对于每个通道具有一个层级的多维权重累积表。
[0062]
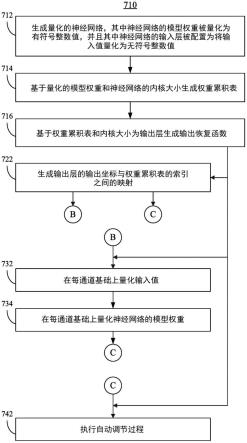
在一些实施例中,推理模型的额外优化可以通过混合精度自动调谐来完成。参考本文描述的组件和特征(包括但不限于附图和关联的描述),图5提供了图示出根据一个或多个实施例的用于调节推理神经网络模型的过程510的流程图。混合精度自动调节可被应用到在推理引擎116(图1)或者推理引擎416(图4)中实现的推理模型。调节过程可包括完成模型的一系列测试运行,以确定是否可以通过对量化中使用的精度做出改变来提高模型准确度。该过程以推理模型的当前状态开始(块512)。在块514,运行推理模型并且获得对结果的准确度的确定。在块516,将结果与准确度标准进行比较。准确度标准可包括例如均值平均精度(mean average precision,map)。其他准确度标准可被用于块516的准确度测试,例如,下文描述的最优均方误差(optimal mean squared error,omse)过程。如果结果的准确度通过了准确度标准评估,那么该过程在块530处继续(如下所述)。如果结果的准确度没有通过块516的准确度标准评估,那么该过程继续进行到块518。
[0063]
在块518,确定输入和/或权重的另一精度是否可供选择。例如,可以选择int16量化作为int8量化的替代。作为另一示例,可以将精度复原到浮点(例如fp32或者fp16)作为替代选择。如果在块518有另一个精度可供选择,则该过程继续进行到块520,在那里推理模型的精度被调整为替代选择,并且该过程返回到块514,在那里模型被再次运行,并且调整后的精度被应用。如果在块518没有另一个精度可供选择(例如,已尝试了所有可能的替代精度),则该过程继续进行到块522。在一些实施例中,可用精度的确定(块518)和精度的调整(块520)可以对于推理模型在逐个算法的基础上被执行;在这种情况下,一旦对特定算法进行了所有可用精度调整,该过程就继续进行到块522。
[0064]
在块522,确定是否已应用了所有算法(例如,对于推理模型的特定层)。如果是,则该过程继续进行到块524,在那里选择另一层并且为该层调整精度,并且该过程返回到块514,在那里再次运行模型,并且应用调整的精度。在一些实施例中,调节过程可以从最后一层开始,并且一旦该层的所有算法都已被应用,则该过程可以“回落”到先前层,并且精度可以被调度,例如调整到fp32。如果在块522确定还没有应用所有的算法,则该过程继续进行到块526。
[0065]
在块526,可以分析张量数据并且应用新算法。要应用的新算法可以是基于内核实现的,或者可以是神经网络模型的替代算法。然后该过程返回到块514,在那里再次运行模型,并且应用新的算法。
[0066]
在块530,该过程已经从块516继续,在那里准确度标准评估已经通过。所做的任何调整(例如,在块520对精度的调整)可以被包含到更新后的推理模型中,该模型可以被实现在推理引擎中,并且调节过程510退出。
[0067]
图6a-6b图示了用于推理神经网络模型优化的替代系统,其中包含混合精度自动调节。参考本文描述的组件和特征(包括但不限于附图和关联的描述),图6a根据一个或多个实施例示出了用于利用非对称量化和自动调节来优化推理神经网络模型的示例系统610的框图。图6a包括如图1所示和上文参考图1所描述的优化系统,并且可包括自动调节模块616。自动调节模块616可以执行上文参考图5描述的自动调节过程。自动调节模块616可以从推理引擎116接收数据,并且可结合非对称量化模块114一起操作,以在运行测试以及在一旦测试完成后应用模型更新时应用替代的精度等等。
[0068]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图6b根据一个或多个实施例示出了用于利用非对称量化与每输入通道量化和自动调节相组合来优化推理神经网络模型的示例系统620的框图。图6b包括如图4所示和上文参考图4所描述的优化系统,并且可包括自动调节模块626。自动调节模块626可以执行上文参考图5描述的自动调节过程。自动调节模块626可以从推理引擎416接收数据,并且可结合非对称量化模块414和每输入通道量化模块415一起操作,以在运行测试以及在一旦测试完成后应用模型更新时应用替代的精度等等。
[0069]
量化度量可被用于确定推理模型或者推理引擎的性能,例如通过评估准确度。例如,量化度量可以被包含作为上述混合精度自动调节过程的一部分。在设计(例如,训练后)阶段中,验证数据集可被用作推理神经网络模型的评估或测试的一部分。然而,在生产或部署中,验证数据集可能无法用作推理模型评估或测试的一部分。因此,另一个度量,最优均方误差(omse)可被用于在生产或部署中评估或测试推理模型,并且也可在设计过程期间被使用。可以计算出omse来指示出如上所述的整数量化(例如,有符号/无符号int8)和浮点表示(例如,fp32)之间的差异。
[0070]
可以假设或理解,数据分布遵循拉普拉斯分布,这是诸如dnn之类的神经网络中的典型正态分布。令x是具有概率密度函数f(x)的fp32精度随机变量。在不失一般性的情况下,可以假设或理解已执行了预处理步骤,以使得张量中的平均值为零,例如:
[0071][0072]
对于int8量化,张量值可以被均匀地量化到从0到255的256个离散值。fp32张量的优化最大值α可以通过量化算法来计算出来。对于任何裁剪函数clip(x,α)可以被
定义如下。
[0073]
(14)
[0074]
两个相邻量化值之间的量化步长
△
可以被确立为
△
=2α/256,并且x和它的量化版本q(x)之间的omse可以根据以下公式来确定:
[0075]
(15)(15)
[0076]
将这种omse的表述对照均值平均精度(map)进行评估,并且在下面的表格1中列出了结果。对于omse评估,使用了dnn模型,ssd-mobilenetv1(来自mlperf推理轨道,一种性能基准)。如上所述应用了量化,并且采用了如上所述的调节过程,以提供一系列的样本测试运行。
[0077]
结果被总结在下面的表格1中:
[0078][0079]
表格1:omse与map作为量化评估度量
[0080]
表格1中示出的是一组数字,标题如下:
[0081]
·
#-表示样本测试运行编号(范围从1到30)
[0082]
·
map-表示根据map标准使用验证数据集进行的评估
[0083]
·
omse-表示根据上述omse过程进行的评估,使用校准图像作为输入数据集合。
[0084]
更高的map%(得分)表示更好的性能,而更低的omse值(得分)表示更好的性能。例如,第1号测试运行具有评估结果map=70.88%,并且omse=0.098;第2号测试运行具有评估结果map=71.65%,并且omse=0.094;并且第3号测试运行具有评估结果map=71.09%,并且omse=0.099。omse的评估结果大致跟踪了map的结果,从而,在许多(虽然不是全部)情况下,具有更好的omse性能的测试运行也具有更好的map性能。例如,第2号测试运行在map和omse度量下都具有最好的性能。因此,结果表明,上述的omse评估过程是评估量化推理神经网络模型的性能的有效方式。
[0085]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图7是图示出根据一个或多个实施例的用于优化推理神经网络模型的方法710的流程图。
[0086]
在块712,可以生成量化的神经网络,其中神经网络的模型权重可以被量化为有符号整数值,并且其中神经网络的输入层可以被配置为将输入值量化为无符号整数值。
[0087]
在块714,可以基于量化的模型权重和神经网络的内核大小来生成权重累积表。
[0088]
在块716,可以基于权重累积表和内核大小来生成输出恢复函数。
[0089]
在一些实施例中,在块722,可以生成输出层的输出坐标和权重累积表的索引之间
的映射。可以如上文参考图2a-2c所描述那样确定该映射。
[0090]
在一些实施例中,方法710可以额外地或替代地实现上文参考图3a-3b和图4所描述的每输入通道量化的一些方面。在块732,可以在每通道基础上量化输入值,这可以经由配置神经网络的输入层来实现。在块734,可以在每通道基础上量化神经网络的模型权重。
[0091]
在一些实施例中,在块742,系统可以额外地或替代地执行自动调节过程。该自动调节过程可包括上文参考图5和图6a-6b描述的混合精度自动调节的一些或所有方面。
[0092]
上文参考图1-图7(包括图1和图7)描述的系统和方法可以按任何数目的方式来实现,包括执行软件指令的硬件(例如,处理器)。作为一个示例,在一个或多个实施例中,上文参考图1-图7(包括图1和图7)描述的系统和方法可以经由一个或多个执行软件指令的可缩放处理器来实现。可缩放处理器可包括具有深度学习(deep learning,dl)提升的硬件加速支持(其中包括用于整数操作的扩展指令集)。
[0093]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图8示出了图示出根据一个或多个实施例的用于优化推理神经网络模型的示例计算系统10的框图。系统10一般可以是电子设备/平台的一部分,具有计算和/或通信功能(例如,服务器、云基础设施控制器、数据库控制器、笔记本计算机、桌面型计算机、个人数字助理/pda、平板计算机、可转换平板设备、智能电话,等等)、成像功能(例如,相机、摄像机)、媒体播放功能(例如,智能电视/tv)、可穿戴功能(例如,手表、眼镜、头饰、鞋类、珠宝)、车辆功能(例如,汽车、卡车、摩托车)、机器人功能(例如,自主机器人),等等,或者这些的任何组合。在图示的示例中,系统10可包括主机处理器12(例如,中央处理单元/cpu),其具有可与系统存储器20相耦合的集成存储器控制器(integrated memory controller,imc)14。主机处理器12可包括任何类型的处理设备,例如,微控制器、微处理器、risc处理器、asic,等等,以及关联的处理模块或电路。系统存储器20可包括诸如ram、rom、prom、eeprom、固件、闪存之类的任何非暂态机器或计算机可读存储介质,诸如pla、fpga、cpld之类的可配置逻辑,使用诸如asic、cmos或ttl技术之类的电路技术的固定功能硬件逻辑,或者适合用于存储指令28的其任何组合。
[0094]
系统10还可包括输入/输出(i/o)子系统16。i/o子系统16可与例如一个或多个输入/输出(i/o)设备18、网络控制器(例如,有线和/或无线nic)和存储装置22进行通信。存储装置22可包括任何适当的非暂态机器或计算机可读存储器类型(例如,闪存、dram、sram(静态随机访问存储器)、固态驱动器(solid state drive,ssd)、硬盘驱动器(hard disk drive,hdd)、光盘,等等)。存储装置22可包括大容量存储装置。在一些实施例中,主机处理器12和/或i/o子系统16可经由网络控制器24与存储装置22(全部或者其一部分)通信。在一些实施例中,系统10还可包括图形处理器26。
[0095]
主机处理器12、i/o子系统16和/或图形处理器26可以执行从系统存储器20和/或存储装置22取回的程序指令28,以执行上述过程的一个或多个方面,包括本文参考图1和图2a-2c描述的用于非对称量化的过程,本文参考图3a-3b和图4描述的用于每输入通道量化的过程,以及本文参考图5和图6a-6b描述的用于混合精度自动调节的过程。主机处理器12和/或i/o子系统16可以执行从系统存储器20和/或存储装置22取回的程序指令28,以执行本文参考图7描述的用于优化推理神经网络模型的过程的一个或多个方面。
[0096]
可以用一种或多种编程语言的任何组合来编写用于执行上文描述的过程的计算机程序代码并且将其实现为程序指令28,所述编程语言包括面向对象的编程语言,比如
java、javascript、python、smalltalk、c 等等,和/或传统的过程式编程语言,比如“c”编程语言或者类似的编程语言。此外,程序指令28可包括汇编指令、指令集体系结构(instruction set architecture,isa)指令、机器指令、机器相关指令、微代码、状态设置数据、用于集成电路的配置数据、个性化电子电路和/或硬件原生的其他结构组件(例如,主机处理器、中央处理单元/cpu、微控制器、微处理器,等等)的状态信息。
[0097]
主机处理器12和i/o子系统16可作为包在实线中示出的片上系统(system on chip,soc)11一起实现在半导体管芯上。soc 11因此可作为用于优化推理模型的计算装置来进行操作。在一些实施例中,soc 11还可包括系统存储器20、网络控制器24和/或图形处理器26(包在虚线中示出)中的一个或多个。
[0098]
i/o设备18可包括一个或多个输入设备,比如触摸屏、键盘、鼠标、光标控制设备、触摸屏、麦克风、数字相机、视频记录器、摄像机、生物计量扫描器和/或传感器;输入设备可用于输入信息和与系统10和/或与其他设备进行交互。i/o设备18还可包括一个或多个输出设备,比如显示器(例如,触摸屏、液晶显示器/lcd、发光二极管/led显示器、等离子面板,等等)、扬声器和/或其他视觉或音频输出设备。输入和/或输出设备可用于例如提供用户界面。
[0099]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图9示出了图示出根据一个或多个实施例的用于优化推理神经网络模型的示例半导体装置30的框图。半导体装置30可例如被实现为芯片、管芯或者其他半导体封装。半导体装置30可包括由例如硅,蓝宝石,砷化镓等等构成的一个或多个衬底32。半导体装置30还可包括由耦合到(一个或多个)衬底32的例如(一个或多个)晶体管阵列和其他集成电路(ic)组件构成的逻辑34。逻辑34可实现上文参考图8描述的片上系统(soc)11。逻辑34可以实现上述过程的一个或多个方面,包括本文参考图1和图2a-2c描述的用于非对称量化的过程,本文参考图3a-3b和图4描述的用于每输入通道量化的过程,以及本文参考图5和图6a-6b描述的用于混合精度自动调节的过程。逻辑34可以实现本文参考图7描述的用于优化推理神经网络模型的过程的一个或多个方面。
[0100]
可利用任何适当的半导体制造工艺或技术来构造半导体装置30。逻辑34可至少部分被实现在可配置逻辑或固定功能硬件逻辑中。例如,逻辑34可包括被定位(例如,嵌入)在(一个或多个)衬底32内的晶体管沟道区域。从而,逻辑34和(一个或多个)衬底32之间的界面可能不是突变结。逻辑34也可被认为包括在(一个或多个)衬底34的初始晶圆上生长的外延层。
[0101]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图10是根据一个或多个实施例图示出示例处理器核心40的框图。处理器核心40可以是用于任何类型的处理器的核心,例如微处理器、嵌入式处理器、数字信号处理器(digital signal processor,dsp)、网络处理器、或者其他执行代码的设备。虽然在图10中只图示了一个处理器核心40,但处理元件或者可包括多于一个图10中所示的处理器核心40。处理器核心40可以是单线程核心,或者对于至少一个实施例,处理器核心40可以是多线程的,因为其对于每个核心可包括多于一个硬件线程情境(或者说“逻辑处理器”)。
[0102]
图10还图示了与处理器核心40相耦合的存储器41。存储器41可以是本领域技术人员已知的或者以其他方式可获得的各种存储器(包括存储器层次体系的各种层)中的任何
一者。存储器41可包括要被处理器核心40执行的一个或多个代码42指令。代码42可以实现上述过程的一个或多个方面,包括本文参考图1和图2a-2c描述的用于非对称量化的过程,本文参考图3a-3b和图4描述的用于每输入通道量化的过程,以及本文参考图5和图6a-6b描述的用于混合精度自动调节的过程。代码42可以实现本文参考图7描述的用于优化推理神经网络模型的过程的一个或多个方面。处理器核心40遵循由代码42指示的指令的程序序列。每个指令可进入前端部分43并且被一个或多个解码器44处理。解码器44可生成诸如预定格式的固定宽度微操作之类的微操作作为其输出,或者可生成其他指令、微指令或者反映原始代码指令的控制信号。图示的前端部分43还包括寄存器重命名逻辑46和调度逻辑48,它们一般分配资源并且对与转换指令相对应的操作进行排队以便执行。
[0103]
处理器核心40被示为包括具有一组执行单元55-1至55-n的执行逻辑50。一些实施例可包括专用于特定功能或功能集合的若干个执行单元。其他实施例可只包括一个执行单元或者可执行特定功能的一个执行单元。图示的执行逻辑50执行由代码指令指定的操作。
[0104]
在由代码指令指定的操作的执行完成之后,后端逻辑58让代码42的指令引退。在一个实施例中,处理器核心40允许指令的无序执行,但要求指令的有序引退。引退逻辑59可采取本领域技术人员已知的各种形式(例如,重排序缓冲器之类的)。这样,处理器核心40在代码42的执行期间被变换,至少就由解码器生成的输出、被寄存器重命名逻辑46利用的硬件寄存器和表格以及被执行逻辑50修改的任何寄存器(未示出)而言。
[0105]
虽然在图10中没有图示,但处理元件可包括与处理器核心40一起在芯片上的其他元件。例如,处理元件可包括与处理器核心40一起的存储器控制逻辑。处理元件可包括i/o控制逻辑和/或可包括与存储器控制逻辑相集成的i/o控制逻辑。处理元件也可包括一个或多个缓存。
[0106]
参考本文描述的组件和特征(包括但不限于附图和关联的描述),图11是根据一个或多个实施例图示出基于多处理器的计算系统60的示例的框图。多处理器系统60包括第一处理元件70和第二处理元件80。虽然示出了两个处理元件70和80,但要理解系统60的实施例也可只包括一个这样的处理元件。
[0107]
系统60被图示为点到点互连系统,其中第一处理元件70和第二处理元件80经由点到点互连71耦合。应当理解,图11中所示的任何或所有互连可被实现为多点分支总线,而不是点到点互连。
[0108]
如图11所示,处理元件70和80的每一者可以是多核处理器,包括第一和第二处理器核心(即,处理器核心74a和74b和处理器核心84a和84b)。这种核心74a、74b、84a、84b可被配置为以与上文联系图10所述类似的方式来执行指令代码。
[0109]
每个处理元件70、80可包括至少一个共享缓存99a、99b。共享缓存99a、99b可存储被处理器的一个或多个组件利用的数据(例如,指令),所述组件例如分别是核心74a、74b和84a、84b。例如,共享缓存99a、99b可以在本地缓存存储器62、63中存储的数据,供处理器的组件更快速访问。在一个或多个实施例中,共享缓存99a、99b可包括一个或多个中间级别缓存,例如第2级(l2)、第3级(l3)、第4级(l4)或其他级别的缓存,最后一级缓存(last level cache,llc),和/或这些的组合。
[0110]
虽然被示为只具有两个处理元件70、80,但要理解实施例的范围不限于此。在其他实施例中,一个或多个额外的处理元件可存在于给定的处理器中。或者,处理元件70、80中
的一个或多个可以是除了处理器以外的元件,例如加速器或者现场可编程门阵列。例如,(一个或多个)额外的处理元件可包括与第一处理器70相同的(一个或多个)额外处理器,与第一处理器70异构或非对称的(一个或多个)额外处理器,加速器(例如,图形加速器或者数字信号处理(dsp)单元),现场可编程门阵列,或者任何其他处理元件。在处理元件70、80之间,就包括体系结构特性、微体系结构特性、热特性、功率消耗特性等等在内的价值度量的范围而言,可以有多种差异。这些差异可实际上将其自身展现为处理元件70、80之间的非对称性和异构性。对于至少一个实施例,各种处理元件70、80可存在于相同的管芯封装中。
[0111]
第一处理元件70还可包括存储器控制器逻辑(mc)72和点到点(p-p)接口76和78。类似地,第二处理元件80可包括mc 82和p-p接口86和88。如图11所示,mc 72和82将处理器耦合到各自的存储器,即存储器62和存储器63,存储器62和存储器63可以是在本地附接到各个处理器的主存储器的一部分。虽然mc 72和82被示为集成到处理元件70、80中,但对于替换实施例,mc逻辑可以是在处理元件70、80之外的分立逻辑,而不是集成在其中。
[0112]
第一处理元件70和第二处理元件80可分别经由p-p互连76和86耦合到i/o子系统90。如图11所示,i/o子系统90包括p-p接口94和98。此外,i/o子系统90包括接口92来将i/o子系统90与高性能图形引擎64耦合。在一个实施例中,总线73可用于将图形引擎64耦合到i/o子系统90。或者,点到点互连可耦合这些组件。
[0113]
进而,i/o子系统90可经由接口96耦合到第一总线65。在一个实施例中,第一总线65可以是外围组件互连(peripheral component interconnect,pci)总线,或者诸如快速pci总线或另一种第三代i/o互连总线之类的总线,虽然实施例的范围不限于此。
[0114]
如图11所示,各种i/o设备65a(例如,生物计量扫描仪、扬声器、相机、传感器)可耦合到第一总线66,以及可将第一总线65耦合到第二总线67的总线桥66。在一个实施例中,第二总线67可以是低引脚数(low pin count,lpc)总线。各种设备可耦合到第二总线67,例如包括键盘/鼠标67a、(一个或多个)通信设备67b、和数据存储单元68(例如,盘驱动器或者其他大容量存储设备),其中该数据存储单元68在一个实施例中可包括代码69。图示的代码69可以实现上述过程的一个或多个方面,包括本文参考图1和图2a-2c描述的用于非对称量化的过程,本文参考图3a-3b和图4描述的用于每输入通道量化的过程,以及本文参考图5和图6a-6b描述的用于混合精度自动调节的过程。代码69可以实现本文参考图7描述的用于优化推理神经网络模型的过程的一个或多个方面。图示的代码69可以与已经论述过的代码42(图10)类似。另外,音频i/o 67c可耦合到第二总线67,并且电池61可向计算系统60供应电力。
[0115]
注意,设想了其他实施例。例如,取代图11的点到点体系结构,系统可实现多点分支总线或者另外的这种通信拓扑。另外,可改为利用比图11所示更多或更少的集成芯片来划分图11的元件。
[0116]
上文描述的用于优化推理神经网络模型的每个系统和方法,以及其每个实施例(包括实现方式),可以被认为是性能增强的,至少在以下程度上是如此:推理神经网络模型可包括低精度非对称量化,如本文所述,并且提供适当优化的性能,用于部署在任何可能数目的环境中,包括具有有限的计算和/或存储器能力的那些。本文描述的技术的优点包括提高计算效率(例如,每秒更多数目的操作),减少存储器访问和降低存储器要求,改进对存储器缓存的使用,所有这些都导致更高的吞吐量和更低的延时。
[0117]
附加注释和示例:
[0118]
示例1包括一种用于优化推理神经网络模型的计算系统,包括处理器和与所述处理器耦合的存储器,所述存储器包括一组指令,所述指令当被所述处理器执行时,使得所述计算系统生成量化的神经网络,其中,所述神经网络的模型权重被量化为有符号整数值,并且其中,所述神经网络的输入层被配置为将输入值量化为无符号整数值,基于量化的模型权重和所述神经网络的内核大小来生成权重累积表,并且基于所述权重累积表和所述内核大小来为所述神经网络的输出层生成输出恢复函数。
[0119]
示例2包括如示例1所述的计算系统,其中,为了生成输出恢复函数,所述指令当被执行时,使得所述计算系统生成所述神经网络的输出层的输出坐标和所述权重累积表的索引之间的映射。
[0120]
示例3包括如示例1所述的计算系统,其中,所述神经网络的输入层被配置为在每通道基础上量化输入值,并且所述神经网络的模型权重是在每通道基础上被量化的。
[0121]
示例4包括如示例3所述的计算系统,其中,所述权重累积表包括第三维度,所述第三维度的每个层级的值对应于每个相应的通道。
[0122]
示例5包括如示例1所述的计算系统,其中,所述神经网络包括多个内部层,并且其中,所述权重累积表是基于多个每层权重累积表来生成的,每个每层权重累积表对应于所述神经网络的多个内部层之一。
[0123]
示例6包括如示例1至5中的任一项所述的计算系统,其中,所述指令当被执行时,还使得所述计算系统执行自动调节过程,所述自动调节过程包含量化度量。
[0124]
示例7包括一种用于优化推理神经网络模型的半导体装置,包括一个或多个衬底,以及与所述一个或多个衬底耦合的逻辑,其中,所述逻辑被至少部分实现在可配置逻辑或者固定功能硬件逻辑之中的一个或多个中,与所述一个或多个衬底耦合的所述逻辑生成量化的神经网络,其中,所述神经网络的模型权重被量化为有符号整数值,并且其中,所述神经网络的输入层被配置为将输入值量化为无符号整数值,基于量化的模型权重和所述神经网络的内核大小来生成权重累积表,并且基于所述权重累积表和所述内核大小来为所述神经网络的输出层生成输出恢复函数。
[0125]
示例8包括如示例7所述的半导体装置,其中,为了生成输出恢复函数,与所述一个或多个衬底耦合的所述逻辑生成所述神经网络的输出层的输出坐标和所述权重累积表的索引之间的映射。
[0126]
示例9包括如示例7所述的半导体装置,其中,所述神经网络的输入层被配置为在每通道基础上量化输入值,并且所述神经网络的模型权重是在每通道基础上被量化的。
[0127]
示例10包括如示例9所述的半导体装置,其中,所述权重累积表包括第三维度,所述第三维度的每个层级的值对应于每个相应的通道。
[0128]
示例11包括如示例7所述的半导体装置,其中,所述神经网络包括多个内部层,并且其中,所述权重累积表是基于多个每层权重累积表来生成的,每个每层权重累积表对应于所述神经网络的多个内部层之一。
[0129]
示例12包括如示例7至11中的任一项所述的半导体装置,其中,与所述一个或多个衬底耦合的所述逻辑还执行自动调节过程,所述自动调节过程包含量化度量。
[0130]
示例13包括至少一个非暂态计算机可读存储介质,其包括一组指令,用于优化推
理神经网络模型,所述指令当被计算系统执行时,使得所述计算系统生成量化的神经网络,其中,所述神经网络的模型权重被量化为有符号整数值,并且其中,所述神经网络的输入层被配置为将输入值量化为无符号整数值,基于量化的模型权重和所述神经网络的内核大小来生成权重累积表,并且基于所述权重累积表和所述内核大小来为所述神经网络的输出层生成输出恢复函数。
[0131]
示例14包括如示例13所述的至少一个非暂态计算机可读存储介质,其中,为了生成输出恢复函数,所述指令当被执行时,使得所述计算系统生成所述神经网络的输出层的输出坐标和所述权重累积表的索引之间的映射。
[0132]
示例15包括如示例14所述的至少一个非暂态计算机可读存储介质,其中,所述神经网络的输入层被配置为在每通道基础上量化输入值,并且所述神经网络的模型权重是在每通道基础上被量化的。
[0133]
示例16包括如示例15所述的至少一个非暂态计算机可读存储介质,其中,所述权重累积表包括第三维度,所述第三维度的每个层级的值对应于每个相应的通道。
[0134]
示例17包括如示例13所述的至少一个非暂态计算机可读存储介质,其中,所述神经网络包括多个内部层,并且其中,所述权重累积表是基于多个每层权重累积表来生成的,每个每层权重累积表对应于所述神经网络的多个内部层之一。
[0135]
示例18包括如示例13至17中的任一项所述的至少一个非暂态计算机可读存储介质,其中,所述指令当被执行时,还使得所述计算系统执行自动调节过程,所述自动调节过程包含量化度量。
[0136]
示例19包括一种操作用于优化推理神经网络模型的计算装置的方法,包括生成量化的神经网络,其中,所述神经网络的模型权重被量化为有符号整数值,并且其中,所述神经网络的输入层被配置为将输入值量化为无符号整数值,基于量化的模型权重和所述神经网络的内核大小来生成权重累积表,并且基于所述权重累积表和所述内核大小来为所述神经网络的输出层生成输出恢复函数。
[0137]
示例20包括如示例19所述的方法,其中,生成输出恢复函数包括生成所述神经网络的输出层的输出坐标和所述权重累积表的索引之间的映射。
[0138]
示例21包括如示例20所述的方法,其中,所述神经网络的输入层被配置为在每通道基础上量化输入值,并且所述神经网络的模型权重是在每通道基础上被量化的。
[0139]
示例22包括如示例21所述的方法,其中,所述权重累积表包括第三维度,所述第三维度的每个层级的值对应于每个相应的通道。
[0140]
示例23包括如示例19所述的方法,其中,所述神经网络包括多个内部层,并且其中,所述权重累积表是基于多个每层权重累积表来生成的,每个每层权重累积表对应于所述神经网络的多个内部层之一。
[0141]
示例24包括如示例19至23中的任一项所述的方法,还包括执行自动调节过程,所述自动调节过程包含量化度量。
[0142]
示例25包括一种装置,其包括用于执行如权利要求19-24中的任一项所述的方法的装置。
[0143]
从而,本文描述的技术通过非对称量化改善了推理神经网络的性能,这是通过以下方式来实现的:生成量化的神经网络,其中神经网络的模型权重被量化为有符号整数值,
并且其中神经网络的输入层被配置为将输入值量化为无符号整数值,基于量化的模型权重和神经网络的内核大小来生成权重累积表,并且基于权重累积表和内核大小来为神经网络的输出层生成输出恢复函数。该技术还可执行每输入通道量化,并且还可执行混合精度自动调节。本文描述的技术可适用于任何数目的计算环境中,包括服务器、云计算、浏览器、和/或具有部署的推理神经网络的任何环境。
[0144]
实施例适用于与所有类型的半导体集成电路(“ic”)芯片一起使用。这些ic芯片的示例包括但不限于处理器、控制器、芯片组组件、可编程逻辑阵列(programmable logic array,pla)、存储器芯片、网络芯片,片上系统(systems on chip,soc)、ssd/nand控制器asic,等等。此外,在一些附图中,用线条来表示信号导线。某些可能是不同的,以表明更多的构成信号路径,具有数字标注,以表明构成信号路径的数目,和/或在一端或多端具有箭头,以表明主要信息流方向。然而,这不应当被以限制方式来解释。更确切地说,可以联系一个或多个示范性实施例使用这种添加的细节来促进对电路的更容易理解。任何表示的信号线,无论是否具有附加信息,都可实际上包括一个或多个信号,这一个或多个信号可在多个方向上行进并且可利用任何适当类型的信号方案来实现,例如用差动对实现的数字或模拟线路、光纤线路、和/或单端线路。
[0145]
可能给出了示例大小/型号/值/范围,虽然实施例不限于此。随着制造技术(例如,光刻术)随着时间流逝而成熟,预期能够制造具有更小尺寸的器件。此外,为了图示和论述的简单,并且为了不模糊实施例的某些方面,在附图内可能示出或不示出到ic芯片和其他组件的公知电源/接地连接。另外,可能以框图形式示出布置以避免模糊实施例,并且同时也考虑到了如下事实:关于这种框图布置的实现的具体细节是高度依赖于在其内实现实施例的平台的,即,这种具体细节应当完全在本领域技术人员的视野内。在阐述具体细节(例如,电路)以便描述示例实施例的情况下,本领域技术人员应当清楚,没有这些具体细节,或者利用这些具体细节的变体,也可实现实施例。说明书从而应当被认为是说明性的,而不是限制性的。
[0146]
术语“耦合”在本文中可被用于指所涉组件之间的任何类型的关系,无论是直接的还是间接的,并且可应用到电的、机械的、液体的、光的、电磁的、机电的或者其他的连接。此外,除非另外指出,否则术语“第一”、“第二”等等在本文中可只被用于促进论述,而不带有特定的时间或先后意义。
[0147]
就在本技术中和权利要求中使用的而言,由术语
“……
中的一个或多个”联接的项目的列表可意指所列出的术语的任何组合。例如,短语“a、b或c中的一个或多个”可意指a、b、c;a和b;a和c;b和c;或者a、b和c。
[0148]
本领域技术人员从前述描述将会明白,可按各种形式来实现实施例的宽广技术。因此,虽然已联系其特定示例描述了实施例,但实施例的真实范围不应当限于此,因为本领域技术人员在研习了附图、说明书和所附权利要求后,将清楚其他修改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。