1.本发明属于计算机视觉技术领域,尤其涉及一种多类信息融合的连续场景目标识别方法、电子设备及存储介质。
背景技术:
2.目标识别作为计算机视觉和人工智能的重要组成部分,在如智能机器人、工业检测、无人驾驶、视频监控等领域有着广泛的应用。早期的算法利用灰度、颜色、纹理、形状等基本视觉和传统机器学习分类方法实现目标识别。近年来开始快速发展的深度学习目标识别方法打破了传统目标识别方法人工提取视觉特征的局限,使得识别速率和精度都得到大幅提升。经过多年发展,yolo(you only look once)算法、ssd(single shot multibox detector)算法、rcnn(region convolutional neural network)算法成为当前最为流行的深度学习目标识别算法,各有其特点和适用环境。
3.尽管深度学习目标识别算法取得了巨大的成功,但当遇到目标识别的一些传统难题时,如光照条件差、目标形态异常、目标尺度大范围改变等图像质量不佳问题,识别结果的准确性和稳定性仍然难以保证。仅采用单一信息来源和识别模型难以解决上述难题,因此,人们试图通过扩展用于目标识别的信息来源进一步提升目标识别的性能,信息融合理论被广泛应用于目标识别。
4.已有的关于目标识别的信息融合研究使用的信息大多来自于同一时刻的一个或多个传感器,使用方法大多属于数据层信息融合和特征层信息融合,具体可参见hong yang,yasheng zhang,wenzhe ding.a fast recognition method for space targets in isar images based on local and global structural fusion features with lower dimensions[j].international journal of aerospace engineering,2020(4).;chen,b.,x.pei,and z.chen."research on target detection based on distributed track fusion for intelligent vehicles."sensors(basel,switzerland)20.1(2020).;wang chang,wang xu.building change detection from multi-source remote sensing images based on multi-feature fusion and extreme learning machine[j].international journal of remote sensing,2021,42(5a6):2246-2257.。但是,对于智能机器人、无人驾驶、视频监控等目标识别的应用场景而言,图像是连续采集的,图像之间存在关联;场景具有一些较为稳定的先验特征,这意味着场景中还有更多信息可用于提升目标识别的性能。
技术实现要素:
[0005]
本发明的目的在于提供一种连续场景目标识别方法、电子设备及存储介质,以解决图像质量不佳导致目标识别结果的准确性和稳定性难以保证的问题。
[0006]
本发明是通过如下的技术方案来解决上述技术问题的:一种连续场景目标识别方法,包括以下步骤:
[0007]
构建并训练目标识别模型;
[0008]
利用训练后的所述目标识别模型对获取的当前帧图像进行目标识别,得到初步识别结果,所述初步识别结果包括当前帧图像中所有目标及其类别、位置和置信度;
[0009]
对当前帧图像中各目标与第一图像序列中已识别目标进行关联,确定当前帧图像中的已识别目标和未识别目标;所述第一图像序列是由当前帧图像之前的第1帧至第e
t
帧之间的所有图像构成的序列;
[0010]
对当前帧图像中的所有目标赋予身份标识代码;
[0011]
对当前帧图像中目标的置信度以及该目标在第二图像序列中的置信度进行融合,得到当前帧图像中目标的修正置信度;所述第二图像序列是由当前帧图像之前的第1帧至第l帧之间的所有图像构成的序列,l为当前帧图像中目标首次出现的图像帧数;
[0012]
根据当前帧图像中目标的修正置信度确定该目标的最终识别结果。
[0013]
进一步地,采用deepsort算法对当前帧图像中各目标与第一图像序列中已识别目标进行关联,确定当前帧图像中的已识别目标和未识别目标。
[0014]
进一步地,对当前帧图像中的所有目标赋予身份标识代码的具体实现过程为:
[0015]
对当前帧图像中的已识别目标赋予与第一图像序列中对应目标相同的身份标识代码,第一图像序列中对应目标是指与当前帧图像中的已识别目标关联的目标;
[0016]
对当前帧图像中的未识别目标赋予新的身份标识代码。
[0017]
进一步地,对当前帧图像中目标的置信度以及该目标在第二图像序列中的置信度进行融合的具体实现过程为:
[0018]
若当前帧图像中的目标首次出现在当前帧图像或当前帧图像之前的第k帧图像中,且k<m,其中m为最小时间序列长度,则视为当前帧图像中的该目标首次出现在当前帧图像之前的第m帧图像中,并根据当前帧图像中该目标首次出现的位置及置信度对该目标在第k 1帧图像至第m帧图像中的置信度进行赋值;
[0019]
若当前帧图像中的目标首次出现在当前帧图像之前的第k帧图像中,且k≥m,则视为当前帧图像中的该目标首次出现在当前帧图像之前的第k帧图像中;
[0020]
对当前帧图像中的该目标的置信度以及该目标在当前帧图像之前的第1帧图像至第l帧图像中的置信度进行融合,得到该目标的修正置信度;其中,当k<m时,l=m;当k≥m时,l=k。
[0021]
进一步地,对第k 1帧图像至第m帧图像中的该目标的置信度进行赋值的具体实现过程为:
[0022]
若当前帧图像中的目标首次在对应图像中出现时位于该图像的高置信度区域,则将当前帧图像的目标的置信度赋值给该目标在当前帧图像之前的第k 1帧图像至第m帧图像中的置信度;
[0023]
否则将0赋值给该目标在当前帧图像之前的第k 1帧图像至第m帧图像中的置信度。
[0024]
进一步地,所述高置信度区域包括第一子区域、第二子区域和第三子区域;
[0025]
所述第一子区域是以点为中心,以r为半径的圆;
[0026]
所述第二子区域是由点(0,h)、(0,h-pa)、(si,h-pa)、(si,h)构成的矩形;
[0027]
所述第三子区域是由点(w,h)、(w,h-pa)、(w-si,h-pa)、(w-si,h)构成的矩形;
[0028]
其中,w为图像的宽度,h为图像的高度,r为w和h中较小值的0.1~0.4倍,si为w的0.1~0.4倍,pa为w的0.1~0.8倍。
[0029]
进一步地,当前帧图像中目标的修正置信度的计算公式为:
[0030][0031][0032]
其中,为目标的修正置信度,a为基本贡献度系数,其取值范围为0~1;b为遗忘系数,其取值范围为0~1;p
t
为目标在第t帧图像中的置信度;s为目标首次出现帧k至当前帧的图像序列中该目标的置信度大于0的图像所占的比重;c是倍增系数,其取值范围为1.5~12;d为倍增调节因子,其取值范围为2~20;uz为比例倍增阈值,其取值范围为0.3~1;co为时长倍增阈值,其取值为最小时间序列长度m的1~5倍。
[0033]
进一步地,根据当前帧图像中目标的修正置信度确定该目标的最终识别结果的具体实现过程为:
[0034]
若当前帧图像中目标的修正置信度大于设定阈值,则输出当前帧图像中的该目标作为最终识别结果;否则认为当前帧图像中不存在该目标。
[0035]
本发明还提供一种电子设备,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行如上所述连续场景目标识别方法的步骤。
[0036]
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质为非易失性存储介质或非瞬态存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行如上所述连续场景目标识别方法的步骤。
[0037]
有益效果
[0038]
与现有技术相比,本发明的优点在于:
[0039]
本发明所提供的一种连续场景目标识别方法、电子设备及存储介质,该方法将当前图像中目标的置信度与时间序列内图像中目标的置信度进行融合,以得到目标的修正置信度,扩充了当前帧目标识别的信息来源,有效抑制了单帧或部分图像质量不佳(例如光照条件不佳、图像模糊、目标尺寸改变、目标尺度过小等)对目标识别带来的影响,显著提高了目标识别的准确性和稳定性。
附图说明
[0040]
为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一个实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0041]
图1是本发明实施例中连续场景目标识别方法流程图;
[0042]
图2是本发明实施例中场景1图像;
[0043]
图3是本发明实施例中场景2图像;
[0044]
图4是本发明实施例中场景3图像;
[0045]
图5是本发明实施例中场景4图像;
[0046]
图6是本发明实施例中图像中高置信度区域示意图;
[0047]
图7是本发明实施例中在场景2第4帧图像下两种不同方法的目标识别结果,其中图(a)为yolo v3的目标识别结果,图(b)为本发明方法的目标识别结果;
[0048]
图8是本发明实施例中在场景4第7帧图像下两种不同方法的目标识别结果,其中图(a)为yolo v3的目标识别结果,图(b)为本发明方法的目标识别结果。
具体实施方式
[0049]
下面结合本发明实施例中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
下面以具体地实施例对本技术的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
[0051]
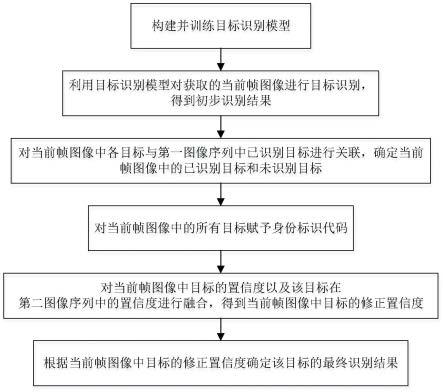
如图1所示,针对有道路的连续场景,例如城市、车间等,本发明实施例所提供的一种连续场景目标识别方法,包括以下步骤:
[0052]
步骤1:构建并训练目标识别模型。
[0053]
本实施例中,目标识别模型为yolo v3模型,采用符合yolo v3标注格式的数据集作为训练样本,应用标准的yolo v3训练流程训练yolo v3模型。
[0054]
本实施例使用的训练样本来源于公开数据集“urban object detection”。该数据集共包含图片108917张。为保证本发明有益效果评估的准确性,使用过的训练样本不能在目标识别性能评估中再次使用。因此,训练模型之前,从该数据集中抽取8000张图片排除在训练样本以外,预留用于最终的精度对比。训练过程中,训练集、验证集和测试集按照3:1:1的比例随机分配,训练完成时得到的目标识别模型可以长期使用,在环境和识别要求没有显著改变的条件下无需再次重复训练。
[0055]
yolo v3模型的训练过程为现有技术,可参见redmon,j.and a.farhadi."yolov3:an incremental improvement."arxiv e-prints(2018).。
[0056]
步骤2:当前帧图像中目标的识别
[0057]
获取当前帧图像,利用步骤1训练后的目标识别模型对当前帧图像进行目标识别,得到初步识别结果,初步识别结果包括当前帧图像中所有目标及其类别、位置和置信度。
[0058]
本发明仅在连续场景中使用,本实施例总共使用四个连续场景的图片验证本发明方法的有益效果,如图2~5所示:场景1(图2)和场景2(图3)来源于“urban object detection”数据集的预留图片;场景3(图4)和场景4(图5)来源于数据集“bdd100k”。场景1包含15帧连续图像,共出现58个目标;场景2包含15帧连续图像,共出现43个目标;场景3包含20帧连续图像,共出现83个目标;场景4包含20帧连续图像,共出现107个目标。
[0059]
步骤3:当前帧图像与第一图像序列的关联
[0060]
本实施例中,采用deepsort算法对当前帧图像中各目标与第一图像序列中已识别目标进行关联(可参见balaji,v.,raymond j.w.,and pritam,c.(2018).deepsort:deep convolutional networks for sorting haploid maize seeds.bmc bioinformatics.19,85-93.doi:10.1186/s12859-018-2267-2.),确定当前帧图像中的已识别目标和未识别目标;第一图像序列是由当前帧图像之前的第1帧至第e
t
帧之间的所有图像构成的序列。
[0061]
设当前帧图像为第0帧,当前帧图像的前一帧则为第1帧,第1帧的前一帧则为第2帧,依次类推到第e
t
帧,第1帧至第e
t
帧构成第一图像序列。如果当前帧图像中的某个目标与第一图像序列中某一图像的某个目标关联,则当前帧图像中的该目标为已识别目标,即在第一图像序列中已出现过的目标,否则为未识别目标,即在第一图像序列中未出现过的目标,是新目标。基于此,将当前帧图像中的所有目标区分为已识别目标和未识别目标。
[0062]
步骤4:身份标识代码的标注或赋予
[0063]
第一图像序列中的目标已被识别,且赋予身份标识代码,设第一图像序列中有n个目标被识别,且这j个目标对应的身份标识代码为idj(j=1,2,...,n),则对当前帧图像中的所有目标赋予身份标识代码分为两种:一种是对当前帧图像中的已识别目标进行身份标识代码的赋予,另一种是对当前帧图像中的未识别目标进行身份标识代码的赋予。
[0064]
由于当前帧图像中的已识别目标t
i0
与第一图像序列中的某个目标关联,则认为当前帧图像中的已识别目标t
i0
与第一图像序列中的目标为同一目标,并将目标的身份标识代码idj赋给已识别目标t
i0
,已识别目标t
i0
与目标具有相同的身份标识代码idj,其中,t
i0
为当前帧图像中的第i个已识别目标;为第一图像序列中的第j个目标,目标位于第n帧图像中,1≤n≤et,本实施例中et设为3。基于此,给当前帧图像中的所有已识别目标赋予第一图像序列中已有的身份标识代码。
[0065]
由于当前帧图像中的未识别目标与第一图像序列中的目标均无关联,则认为当前帧图像中的未识别目标为当前帧中出现的新目标,将新的身份标识代码赋予给该未识别目标,n=n 1。基于此,给当前帧图像中的所有未识别目标赋予新的身份标识代码。
[0066]
当前帧图像中的所有目标(包括已识别目标和未识别目标)均被赋予身份标识代码。
[0067]
步骤5:置信度融合确定修正置信度
[0068]
为了扩充当前帧图像中目标识别的信息来源,需要利用当前帧之前帧中的置信度信息,将当前帧图像中目标的置信度与该目标在当前帧之前帧中的置信度进行融合,来得到更为准确的修正置信度。此处,当前帧图像中的目标是指被赋予身份标识代码的目标,即包括了已识别目标和未识别目标。置信度融合的具体实现过程为:
[0069]
步骤5.1:若当前帧图像中的目标t
i0
首次出现在当前帧图像之前的第k帧图像中,且k<m,其中m为最小时间序列长度,则视为当前帧图像中的目标t
i0
首次出现在当前帧图像之前的第m帧图像中,并根据当前帧图像中目标t
i0
首次出现的位置及置信度对目标t
i0
在第k 1帧图像至第m帧图像中的置信度进行赋值。本实施例中,m=3。
[0070]
对于当前帧图像中的之前未识别目标,其首次出现在当前帧图像中,即k=0;对于当前帧图像中的之前已识别目标,其首次出现至少是在当前帧的前一帧,即k≥1。当最小时
间序列长度为m且k<m时,第k 1帧至第m帧图像中缺失目标t
i0
,因此根据目标t
i0
的置信度在第k 1帧至第m帧图像中填补目标t
i0
的置信度,设在第k 1帧至第m帧图像中目标t
i0
的置信度分别为以扩充目标t
i0
的信息来源。
[0071]
本实施例中,根据目标t
i0
首次出现的位置和目标t
i0
的置信度对目标t
i0
在第k 1帧图像至第m帧图像中的置信度进行赋值,具体为:
[0072]
若当前帧图像中的目标t
i0
首次在对应图像(即第k帧)中出现时位于该图像的高置信度区域,则将当前帧图像的目标t
i0
的置信度赋值给目标t
i0
在第k 1帧至第m帧图像的置信度,即均为
[0073]
若当前帧图像中的目标t
i0
首次在对应图像(即第k帧)中出现时位于该图像的非高置信度区域,将0赋值给目标t
i0
在当前帧图像之前的第k 1帧图像至第m帧图像的置信度,即均为0。
[0074]
对于像素尺寸为w
×
h的图像,高置信度区域包括第一子区域、第二子区域和第三子区域;第一子区域是以点为中心,以r为半径的圆;第二子区域是由点(0,h)、(0,h-pa)、(si,h-pa)、(si,h)构成的矩形;第三子区域是由点(w,h)、(w,h-pa)、(w-si,h-pa)、(w-si,h)构成的矩形,如图6所示。其中,[
·
]为取整,w为图像的宽度,h为图像的高度,r为w和h中较小值的0.1~0.4倍,si为w的0.1~0.4倍,pa为w的0.1~0.8倍。以图像左上角为原点,水平向右为x轴正方向,竖直向下位y轴正方向。
[0075]
示例性的,每帧图像的像素尺寸均为1280pixel
×
720pixel,即w=1280pixel,h=720pixel;参数r=135pixel,pa=457pixel,si=460pixel。
[0076]
高置信度区域以外的其他区域均为非高置信度区域。
[0077]
步骤5.2:若当前帧图像中的目标t
i0
首次出现在当前帧图像之前的第k帧图像中,且k≥m,则视为当前帧图像中的目标t
i0
首次出现在当前帧图像之前的第k帧图像中。此时,当前帧至第k帧图像中目标t
i0
至少出现两次。
[0078]
步骤5.3:对当前帧图像中的目标t
i0
的置信度以及目标t
i0
在当前帧图像之前的第1帧图像至第l帧图像中的置信度进行融合,得到目标t
i0
的修正置信度
[0079]
l为当前帧图像中目标t
i0
首次出现的图像帧数,目标t
i0
首次出现的帧不同,l不同,由步骤步骤5.1和5.2可知,当k<m时,l=m;当k≥m时,l=k。目标t
i0
在第1帧至第l帧图像中的置信度分别若第1帧至第l帧图像中的某些图像中未出现目标t
i0
,则将这些图像中目标t
i0
的置信度设为0。修正置信度具体计算公式为:
[0080]
[0081][0082][0083]
其中,为目标t
i0
的修正置信度,a为基本贡献度系数,其取值范围为0~1;b为遗忘系数(其作用是随着时间的推移逐渐降低某帧图像中的目标识别结果在后续帧的置信度融合时的权重),其取值范围为0~1,b
t
为遗忘系数的指数;为目标t
i0
在第t帧图像中的置信度,当t=0(即当前帧)时,s为目标t
i0
首次出现帧k(即真实的首次出现帧)至当前帧的图像序列中该目标t
i0
的置信度大于0的图像所占的比重;c是倍增系数,其取值范围为1.5~12;d为倍增调节因子,其取值范围为2~20;uz为比例倍增阈值,其取值范围为0.3~1;co为时长倍增阈值,其取值为最小时间序列长度m的1~5倍。本实施例中,a=1/3、b=2/3、c=3、d=8、uz=0.5、co取为最小时间序列长度m的3倍。示例性的,若目标t
i0
首次出现帧k=3,从首次出现帧k至当前帧共有4帧图像,假设其中两帧图像中目标t
i0
的置信度大于0,则s=2/4。所有目标的置信度取值范围为0~1。
[0084]
步骤6:最终识别结果的确定。
[0085]
根据当前帧图像中目标的修正置信度确定该目标的最终识别结果,具体实现过程为:
[0086]
若当前帧图像中目标t
i0
的修正置信度大于设定阈值p,则输出当前帧图像中的目标t
i0
作为最终识别结果;否则认为当前帧图像中不存在目标t
i0
。本实施例中,p取值范围为0.03~0.9。
[0087]
步骤7:对当前帧图像中的下一个目标重复执行步骤5和6,直到完成当前帧图像中所有目标的识别。
[0088]
步骤8:对下一帧图像重复执行步骤2~6,直到完成连续场景中所有图像的目标识别。
[0089]
将设定阈值p分别取为0.05和0.3,本发明方法与基础深度学习目标识别模型(yolo v3)精度对比如表1和表2所示。
[0090]
表1设定阈值p为0.05时两种方法的误检率和漏检率
[0091][0092]
表2设定阈值p为0.3时两种方法的误检率和漏检率
[0093][0094]
由表1可知,当设定阈值p取为0.05时,在四个场景中本发明方法的性能均显著优于yolo v3算法,各场景中各类目标的误检率平均比yolo v3算法低3.19%,漏检率平均比yolo v3算法低12.49%。其中,在场景4中person的目标识别性能提高最为显著,漏检率和误检率分别降低了16%和8%。由表2可知,当设定阈值p取0.3时,在四个场景中本发明方法的性能同样均显著优于yolo v3算法,各场景中各类目标的漏检率平均比yolo v3算法低9.36%。其中,在场景1中traffic signal的目标识别性能提高最为显著,漏检率降低13.2%。无论设定阈值p取为0.05还是0.3,在所有场景中本发明方法的两个性能评价指标均未出现低于yolo v3算法的情况。因此本发明方法能在基本目标识别模型的基础上大幅提升目标识别性能。
[0095]
图7(a)是场景2中第4帧图像在设定阈值0.3条件下yolo v3算法的目标识别结果,图7(b)是同等条件下本发明方法的识别结果。由图7可知,由于距离较远,yolo v3算法未能识别图像中间位置的汽车和交通灯,出现了漏检,而使用本发明方法则能避免。图8(a)是场景4中第7帧图像在设定阈值0.05条件下yolo v3算法的目标识别结果,图8(b)是同等条件下本发明方法的识别结果,由图8可知,由于图像光照条件差,yolo v3算法在图像中间偏右的轿车顶部错误地识别到一人目标,使用本发明方法则可避免出现这一误检。本发明方法大幅提升目标识别算法性能的原因在于扩充了信息来源,单帧图像质量对识别结果的影响得到了削弱。
[0096]
本发明方法通过将时间序列图像的单帧目标识别信息(即当前帧)和场景先验信息(当前帧之前的帧)与当前帧目标识别结果相融合,扩充了当前帧识别信息的来源,能有效抑制单帧或部分图像质量不佳对目标识别带来的影响,显著提高了目标识别的准确性;
本发明方法是一个具有广泛适用性的多类信息融合框架,所有能输出目标类别、位置信息和置信度的目标识别方法均能使用这一信息融合框架提升性能;融合多类信息修正识别结果步骤中,目标在时间序列图像中自出现以来的所有单帧目标的置信度均以一定的权重纳入到目标置信度的修正中(得到修正置信度),时间序列信息融合充分;通过设置遗忘系数,随着时间的推移逐渐降低某帧的目标识别结果在后续帧置信度融合时的权重,使离当前帧最近的信息在信息融合过程中发挥更大的作用;将时间序列信息融合面临的边界处理问题转变成场景先验信息融入的接口,巧妙的实现了两类完全不同性质信息的有机融合;依据目标首次出现在时间序列图像中所处的区域给时间序列信息融合缺失的单帧图像目标识别置信度赋值,以非常简单而可靠的方式实现了场景先验信息的有效利用;通过设置倍增函数,使得在图像序列中一致性较好的信息得到增强;在统一的框架上设置了单帧基本贡献度系数、遗忘系数、倍增系数、倍增调节因子、比例倍增阈值、时长倍增阈值等数量众多的参数依据具体应用环境调节,保障了本发明的实用性。
[0097]
以上所揭露的仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或变型,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。