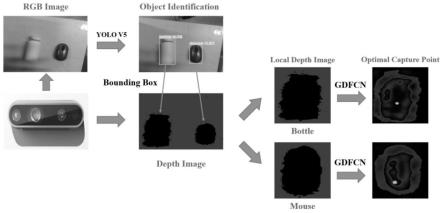
一种基于深度学习的夜间行人检测算法
1技术领域
1.本发明属于目标检测技术领域。具体涉及一种基于深度学习的夜间行人检测算法。
2
背景技术:
2.(1)目标检测算法
3.行人检测是从图像或者视频中检测是否存在行人的技术,是计算机视觉领域的一个重要分支,在汽车辅助驾驶、视频监控及智能机器人等相关领域发挥重要作用,具有巨大的应用价值。
4.行人检测属于目标检测的子任务,目标检测算法可以直接用于检测行人。传统目标检测算法基于人工设计的特征提取器,提取haar、hog等特征用于检测行人。近年来,深度学习飞速发展,各种基于深度学习的目标检测算法层出不穷,主流目标检测算法有两类,一类为两阶段的目标检测算法,这类算法具备较好的检测精度,但检测速度较慢,代表算法有:r-cnn(regions with convolutional neural network features)、fast rcnn(fast regions with convolutional neural network features)、faster rcnn(fast regions with cnn features),另一类是以ssd(single shot multibox detecter)、yolo(you only look once)、yolov2(you only look once version2)、yolov3(you only look once version3)和yolov4(you only look once version4)等算法为代表的单阶段目标检测算法,这类算法实现了较快的检测速度,但检测精度不如两阶段目标检测算法。
5.相较于已有目标检测算法,yolov4算法实现了精度和速度的良好平衡,在应用于一般场景下的行人检测时,也实现了较好的检测性能。但是在夜间等低光照场景下,yolov4算法仍与其他深度学习算法一样,具有较大的检测缺陷,亟待改进。
6.(2)弱光照图像增强算法
7.弱光照图像增强算法的目的是提高低光场景下捕获数据的视觉感知质量以获取到更多信息并加以利用,是图像处理领域中的研究热点,在自动驾驶、安防等人工智能相关行业中具有十分广阔的应用前景。传统的低光照图像增强算法需要复杂的数学技巧和繁琐的数学推导,整个过程较为复杂,不利于实际应用。随着大规模数据集的相继诞生,基于深度学习的弱光照图像增强算法应运而生。zero-dce算法是基于深度学习的弱光照图像增强算法的代表算法之一,该算法能够在各种各样的光照条件下对图像进行增强,且不依赖于配对数据,具备强大的泛化能力。
3
技术实现要素:
8.本发明的目的是提供一种基于深度学习的夜间行人检测算法,在保证检测速度的基础上,解决现有算法在夜间场景下的技术缺陷,例如因弱光照导致的无法将行人与背景区分,输出特征图间信息交互不充分等。
9.本发明的技术方案:
10.基于深度学习的夜间行人检测算法,步骤如下:
11.步骤一、构建夜间行人数据集;
12.步骤二、对yolov4算法的网络结构进行改进,得到适用于行人检测的yolov4改进算法;
13.步骤三、使用夜间行人数据集训练算法模型;
14.步骤四、待检测rgb图像的大小设置为416*416,输入到zero-dce网络,进行光照增强;
15.步骤五、针对zero-dce网络输出的增强图像,采用改进yolov4网络输出最终的行人检测结果,检测结果包括待分类图像中目标区域的位置以及对应的类别,类别标注设置为person;
16.其中,改进yolov4的网络结构包括特征提取主干网络、spp模块、特征融合网络、多分类器模块。改进yolov4中特征提取主干网络是由两个cspdarknet53网络共同组建的双主干网络(double-cspdarknet53),网络输出特征图大小分别为104*104、52*52、26*26、13*13;所述spp模块采用13*13大小的特征图作为输入,增强该特征图的感受野;然后对yolov4算法的特征融合网络进行改进,增强不同输出特征图间的信息交互;最后,使用多分类器模块对不同尺度的特征进行分类检测,完成整个检测过程。
17.本发明提供的基于深度学习的夜间行人检测算法法,基于现有的最新yolov4算法和zero-dce弱光照增强算法,保证本发明提出的检测算法同时具备良好的检测性能与较快的检测速度,同时能够解决夜间场景下因弱光照带来的检测难题。在此基础上,将yolov4算法的特征提取主干提取网络改进为双主干形式,称为double-cspdarknet53网络,极大地提高特征提取能力,然后对yolov4算法的特征融合网络进行改进,提出了一种更有效的特征融合网络,解决了不同层特征图之间信息流通不充分带来的检测困难,进而提高yolov4算法在夜间场景下,对行人目标的检测性能。
4附图说明
18.图1为本发明提出的基于深度学习的夜间行人检测算法的具体流程。
19.图2为yolov4改进算法的网络结构。
20.图3为zero-dce算法的网络结构。
5具体实施方式
21.下面将结合本发明中的附图,完整阐述本发明所提出的技术方案。
22.除非特别说明,本文提及的所有相关术语与本发明所属技术领域的相关技术人员所理解的含义一致。
23.如图1所示,本发明提供的一种基于深度学习的夜间行人检测算法,包括以下步骤:
24.步骤一、获取夜间行人数据集。该数据集由nightowls数据集与手动拍摄的弱光照、包含行人的道路图片组成,共计5000张,所有图片均使用图像标注工具(labelimg)标注出行人目标在图片所处位置,类别标注设置为person。容易理解的是,数据集规模可以根据实际应用需求进行扩充或者缩减,数据集规模越大,对检测越有利。数据集中目标类别应分
为行人与非行人(背景),需要指出的是,行人目标计为person,非行人归纳在背景中,不需要进行标注。
25.步骤二、对yolov4算法进行改进,得到适用于行人检测的yolov4改进算法。yolov4算法实现了检测精度与速度的良好平衡,本发明在yolov4算法的基础上,针对夜间场景特点,对yolov4算法进行改进,改进重点为特征提取主干网络与特征融合网络。
26.如图2所示,yolov4改进算法对特征提取主干网络与特征融合网络进行改进,同时使用spp模块与多分类器模块,组成最终的改进算法结构。
27.所述的改进特征提取主干网络由两个cspdarknet53网络组成,称为double-cspdarknet53网络,所述double-cspdarknet53网络具有4个网络输出特征图,大小分别为104*104,52*52,26*26,13*13。需要注意的是,使用的两个cspdarknet网络结构完全相同,包括:根据图2中箭头方向进行连接的darknetconv2d_bn_mish模块以五组resblock_body模块。如图2所示,在doublecspdarknet53网络中,会融合两个cspdarknet53网络的输出特征图,得到增强的输出特征图,其中从第二组resblock_body模块到第五组resblock_body模块,输出特征图大小依次为104*104,52*52,26*26,13*13。本发明在特征提取主干网络部分使用到的各个模块,例如darknetconv2d_bn_mish模块,与原yolov4算法中的对应模块相同,因此不再对其具体结构进行描述。
28.所述spp模块包含4个池化核大小分别为13*13、9*9、5*5、1*1的并行的最大池化层。所述spp模块的作用是对改进特征提取网络中大小为13*13的输出特征图的感受野进行增强,不同池化核会得到不同感受野的特征图,然后将4个处理后的特征图再去通道维度进行拼接,得到spp模块输出特征图。
29.所述改进特征融合网络包含上采样层(上采样层1、上采样层2、跨层上采样层)、融合层(融合层1、融合层2、融合层3、融合层4、融合层5)、下采样层(下采样层1、下采样层2、下采样层3)、卷积层,并根据图2所示数据流向进行依次连接。
30.其中:
31.所述spp模块的输出特征图分别输入到上采样层1与、跨层上采样层与融合层5,将上采样层1输出特征图输入到融合层1,将跨层上采样层的输出特征图输入到融合层2,最后将融合层5输出特征图输入到多分类器模块。
32.所述double-darknet53网络的26*26大小的输出特征图输入到融合层1,将融合层1的输出特征图分别输入到上采样层2与融合层4,将上采样层2的输出特征图输入到融合层2,将融合层4的输出特征图分别输入到多分类器模块与下采样层3,最后将下采样层3的输出特征图输入到融合层5。
33.所述double-darknet53网络的52*52大小的输出特征图输入到融合层2,将融合层2的输出特征图输入到融合层3,将融合层3的输出特征图分别输入到下采样层2与多分类器模块,最后将下采样层2的输出特征图输入到融合层4。
34.所述double-darknet53网络的104*104大小的输出特征图输入到下采样层1,将下采样层1的输出特征图输入到融合层3。
35.关于改进特征融合网络中未具体说明的数据输入输出的层,只需依据数据流向(见图2中箭头方向)依次传递数据信息。为完成网络中的数据信息正常传递,改进特征融合网络中包含大量卷积层,值得注意的是,卷积层使用方式与yolov4算法相同,因此这里不进
一步赘述。
36.本发明提出的改进特征融合网络中,通过3次上采样操作将不同层特征图连接,完成语义信息的向上传递,例如13*13大小的输出特征图分别以2倍上采样、4倍上采样与26*26大小的输出特征图、52*52大小的输出特征图进行拼接,26*26大小的输出特征图则通过2倍上采样与52*52大小的输出特征图进行拼接,最终形成密集连接网络结构,实现特征重用。在上采样之后,以大小为104*104的输出特征图为起点,进行下采样,旨在向下传递细节信息,容易理解的是,整个下采样过程共包含3次下采样操作,下采样率均为2,如104*104的输出特征经2倍下采样后,大小变为52*52,再与52*52大小的输出特征图进行拼接,以此类推,完成整个下采样过程。
37.所述多分类器模块包含三个yolo_head分类器,分别用于所述改进特征融合模块的三个大小分别为52*52、26*26、13*13的输出特征图。需要注意的是,三个yolo_head分类器的结构与原yolov4算法中提供的yolo_head结构相同,因此对yolo_head分类器的具体结构不再赘述。
38.所述yolo_head分类器分别采用52*52、26*26、13*13三个尺度的融合特征层的输出特征图与对应的logistic分类器进行行人检测。以13*13大小的特征图为例,将待检测图片分割为由13*13个单元格组成的图片,根据行人目标的真值框所处单元格位置,决定由哪个单元格对该目标进行检测。其中,每个单元格对应三个不同大小的预测框,共计13*13*3=507个。当检测结果的类别置信度不小于设置好的阈值(一般取0.5)时,将保留符合条件的预测框,最后通过非极大值抑制(nms)算法对预测框进行筛选,保留最佳预测框,剔除冗余预测框。综上,yolov4改进算法最多可以检测(52*52) (26*26) (13*13)=3549个目标,共计生成3549*3=10647个预测框。
39.值得注意的是,yolov4改进算法与yolov4算法相同,使用不同尺度特征图预测不同大小目标。其中最浅层特征图(52*52)具有较为丰富的细节信息,适用于检测小型目标,最深层特征图(13*13)具有较为丰富的语义信息,适用于检测大型目标,中间层特征图(26*26)实现了语义信息和细节信息的平衡,适用于检测中型目标。这样的检测方式使得本发明的yolov4改进算法适用范围大,对各尺度的行人目标均具有良好的检测性能。
40.步骤三、使用所述夜间行人数据集对本发明提出的yolov4改进算法进行训练,得到适用于夜间行人检测的网络模型。
41.本发明在训练时,按照9∶1的比例将夜间行人数据集划分为训练集和测试集。容易理解的是,训练集中包含的4000张图片用于迭代训练得到网络模型,其本质是利用损失函数指导训练过程中的网络模型参数调整,当损失函数的值不再下降时,模型训练完成。然后使用测试集计算map值(平均精度),对训练结果进行验证。
42.本发明使用多尺度训练的方法提高改进算法的检测性能,使改进算法能够适应不同尺度的行人目标。同时,在训练过程采取以下技巧提高训练效果。
43.(1)mosaic数据增强方法。将一个批次内的4张图片进行组合,得到一张具有更丰富的信息的图片用于检测。
44.(2)ciou。与iou不同,ciou会了让目标框的回归更为稳定,将目标与候选框之间的距离、重叠率与惩罚项等因素均纳入考虑范围。ciou的公式如下:
[0045][0046]
式中,iou是真值框与候选框的交并比,ρ2(b,b
gt
)分别代表预测框与真值框的中心点之间的欧式距离,c是指将预测框与真值框包含在内的最小闭包区域的对角线距离。α与v如下:
[0047][0048][0049]
其中w
gt
、h
gt
、w、h依次为真值框和预测框的宽、高。
[0050]
ciou损失函数如下:
[0051][0052]
(3)余弦退火学习率。初始学习率设置为0.001,在整个训练过程中,学习率随着余弦曲线进行增加或者衰减。
[0053]
(4)dropblock正则化。dropout是一种按照设置的概率将网络中的部分神经元屏蔽,防止神经网络过拟合的方法。dropblock则是dropout在卷积层上的扩展,dropblock将屏蔽部分神经元的思想应用于卷积层,完成特征增强。
[0054]
步骤四、将输入图像大小设置为416*416,使用zero-dce算法对输入图像进行光照增强。zero-dce是一种低光照图像增强算法,以弱光照图像作为输入,把产生的高阶曲线作为输出,然后这些曲线被用作对输入的变化范围的像素级调整,从而获得一个增强的图像。
[0055]
zero-dce算法包括如下三个部分:
[0056]
(1)光增强曲线
[0057]
(a)一阶曲线。如下式所示。
[0058]
le(i(x);α)=i(x) αi(x)(1-i(x))
[0059]
其中x为像素坐标;le(i(x);α)为增强输出;α∈[-1,1]为可训练的曲线参数。一阶曲线会对每个像素都归一化,并且所有操作都是逐像素进行。
[0060]
(b)高阶曲线。高阶曲线主要是解决一阶曲线增强不足的问题。如下所示:
[0061]
len(x)=le
n-1
(x) αnle
n-1
(x)(1-le
n-1
(x))
[0062]
其中x为像素坐标;len(x)为增强输出;le
n-1
(x)为输入;αn∈[-1,1]为可训练的曲线参数;n代表迭代次数,一般取8。
[0063]
(c)逐像素曲线。当网络预测结果是一个α的map时,亮度调节曲线如下所示:
[0064]
len(x)=le
n-1
(x) anle
n-1
(x)(1-le
n-1
(x))
[0065]
其中,an为由可训练参数αn组成的map。
[0066]
(2)深度曲线估计网络
[0067]
深度曲线估计网络用于学习光增强曲线中的可训练曲线参数,获得增强图像。如图3所示,该网络是一个简单的7层卷积神经网络,没有bn与下采样,全部由卷积核大小为3*3的32通道的卷积层与relu激活层组成。
[0068]
(3)无参考损失函数
[0069]
zero-dce算法包含4种无参考损失函数。
[0070]
(a)空间一致性损失(spatial consistency loss)
[0071]
用于约束输入图像与增强图像相邻区域的梯度,保持图像的空间一致性。如下所示:
[0072][0073]
其中:k为局部区域的数量,ω(i)是以区域i为中心的四个相邻区域(top,down,left,right)。y和i分别为增强图像和输入图像的局部区域平均强度值。
[0074]
(b)曝光控制损失(exposure control loss)
[0075]
用于约束曝光水平。将增强图像转化为灰度图,分级为若干16x16patches,计算patch内平均值。
[0076][0077]
其中:其中m为16
×
16的不重叠局部区域的数量。y为增强图像中局部区域的平均强度值。
[0078]
(c)色彩恒常性损失(color constancy loss)
[0079]
用于约束潜在色彩偏差,建立三通道之间联系,要让增强后的颜色尽可能相关。
[0080][0081]
其中:其j
p
代表增强图像通道p的平均强度,(p,q)代表一对通道。
[0082]
(d)光照平滑损失(illumination smoothness loss)
[0083]
用于相邻像素之间的单调关系。
[0084][0085]
其中:n为迭代次数,分别代表水平和垂直方向的梯度操作。
[0086]
综上,总损失函数为:
[0087][0088]
步骤五、检测行人目标。针对zero-dce网络输出的增强图像,采用改进yolov4网络输出最终的行人检测结果,检测结果包括待分类图像中行人目标的位置以及对应的类别,类别标注为person。另外,非行人目标属于背景,不需要进行标注。
[0089]
针对不同应用场景,可以采用摄像头实时采集的视频信息,按帧截取待检测图像,并对所得图像进行裁剪或者填充,使其缩放到416*416大小,作为本发明提出的检测算法的输入。
[0090]
需要说明的是,本发明对如何展示目标检测结果不做任何限制,使用者按照自身需求完成最终结果的展示。
[0091]
以上对本发明的描述较为具体,但并不能理解为对发明专利范围的限制。需要指出的是,对于本领域的普通技术人员而言,在不脱离本发明提供的思路的前提下,可根据自身需求做出相应改进,这些均属于本发明申请的保护范围。因此,具体的保护范围因以所附的权利要求为准。
1技术领域
1.本发明属于目标检测技术领域。具体涉及一种基于深度学习的夜间行人检测算法。
2
背景技术:
2.(1)目标检测算法
3.行人检测是从图像或者视频中检测是否存在行人的技术,是计算机视觉领域的一个重要分支,在汽车辅助驾驶、视频监控及智能机器人等相关领域发挥重要作用,具有巨大的应用价值。
4.行人检测属于目标检测的子任务,目标检测算法可以直接用于检测行人。传统目标检测算法基于人工设计的特征提取器,提取haar、hog等特征用于检测行人。近年来,深度学习飞速发展,各种基于深度学习的目标检测算法层出不穷,主流目标检测算法有两类,一类为两阶段的目标检测算法,这类算法具备较好的检测精度,但检测速度较慢,代表算法有:r-cnn(regions with convolutional neural network features)、fast rcnn(fast regions with convolutional neural network features)、faster rcnn(fast regions with cnn features),另一类是以ssd(single shot multibox detecter)、yolo(you only look once)、yolov2(you only look once version2)、yolov3(you only look once version3)和yolov4(you only look once version4)等算法为代表的单阶段目标检测算法,这类算法实现了较快的检测速度,但检测精度不如两阶段目标检测算法。
5.相较于已有目标检测算法,yolov4算法实现了精度和速度的良好平衡,在应用于一般场景下的行人检测时,也实现了较好的检测性能。但是在夜间等低光照场景下,yolov4算法仍与其他深度学习算法一样,具有较大的检测缺陷,亟待改进。
6.(2)弱光照图像增强算法
7.弱光照图像增强算法的目的是提高低光场景下捕获数据的视觉感知质量以获取到更多信息并加以利用,是图像处理领域中的研究热点,在自动驾驶、安防等人工智能相关行业中具有十分广阔的应用前景。传统的低光照图像增强算法需要复杂的数学技巧和繁琐的数学推导,整个过程较为复杂,不利于实际应用。随着大规模数据集的相继诞生,基于深度学习的弱光照图像增强算法应运而生。zero-dce算法是基于深度学习的弱光照图像增强算法的代表算法之一,该算法能够在各种各样的光照条件下对图像进行增强,且不依赖于配对数据,具备强大的泛化能力。
3
技术实现要素:
8.本发明的目的是提供一种基于深度学习的夜间行人检测算法,在保证检测速度的基础上,解决现有算法在夜间场景下的技术缺陷,例如因弱光照导致的无法将行人与背景区分,输出特征图间信息交互不充分等。
9.本发明的技术方案:
10.基于深度学习的夜间行人检测算法,步骤如下:
11.步骤一、构建夜间行人数据集;
12.步骤二、对yolov4算法的网络结构进行改进,得到适用于行人检测的yolov4改进算法;
13.步骤三、使用夜间行人数据集训练算法模型;
14.步骤四、待检测rgb图像的大小设置为416*416,输入到zero-dce网络,进行光照增强;
15.步骤五、针对zero-dce网络输出的增强图像,采用改进yolov4网络输出最终的行人检测结果,检测结果包括待分类图像中目标区域的位置以及对应的类别,类别标注设置为person;
16.其中,改进yolov4的网络结构包括特征提取主干网络、spp模块、特征融合网络、多分类器模块。改进yolov4中特征提取主干网络是由两个cspdarknet53网络共同组建的双主干网络(double-cspdarknet53),网络输出特征图大小分别为104*104、52*52、26*26、13*13;所述spp模块采用13*13大小的特征图作为输入,增强该特征图的感受野;然后对yolov4算法的特征融合网络进行改进,增强不同输出特征图间的信息交互;最后,使用多分类器模块对不同尺度的特征进行分类检测,完成整个检测过程。
17.本发明提供的基于深度学习的夜间行人检测算法法,基于现有的最新yolov4算法和zero-dce弱光照增强算法,保证本发明提出的检测算法同时具备良好的检测性能与较快的检测速度,同时能够解决夜间场景下因弱光照带来的检测难题。在此基础上,将yolov4算法的特征提取主干提取网络改进为双主干形式,称为double-cspdarknet53网络,极大地提高特征提取能力,然后对yolov4算法的特征融合网络进行改进,提出了一种更有效的特征融合网络,解决了不同层特征图之间信息流通不充分带来的检测困难,进而提高yolov4算法在夜间场景下,对行人目标的检测性能。
4附图说明
18.图1为本发明提出的基于深度学习的夜间行人检测算法的具体流程。
19.图2为yolov4改进算法的网络结构。
20.图3为zero-dce算法的网络结构。
5具体实施方式
21.下面将结合本发明中的附图,完整阐述本发明所提出的技术方案。
22.除非特别说明,本文提及的所有相关术语与本发明所属技术领域的相关技术人员所理解的含义一致。
23.如图1所示,本发明提供的一种基于深度学习的夜间行人检测算法,包括以下步骤:
24.步骤一、获取夜间行人数据集。该数据集由nightowls数据集与手动拍摄的弱光照、包含行人的道路图片组成,共计5000张,所有图片均使用图像标注工具(labelimg)标注出行人目标在图片所处位置,类别标注设置为person。容易理解的是,数据集规模可以根据实际应用需求进行扩充或者缩减,数据集规模越大,对检测越有利。数据集中目标类别应分
为行人与非行人(背景),需要指出的是,行人目标计为person,非行人归纳在背景中,不需要进行标注。
25.步骤二、对yolov4算法进行改进,得到适用于行人检测的yolov4改进算法。yolov4算法实现了检测精度与速度的良好平衡,本发明在yolov4算法的基础上,针对夜间场景特点,对yolov4算法进行改进,改进重点为特征提取主干网络与特征融合网络。
26.如图2所示,yolov4改进算法对特征提取主干网络与特征融合网络进行改进,同时使用spp模块与多分类器模块,组成最终的改进算法结构。
27.所述的改进特征提取主干网络由两个cspdarknet53网络组成,称为double-cspdarknet53网络,所述double-cspdarknet53网络具有4个网络输出特征图,大小分别为104*104,52*52,26*26,13*13。需要注意的是,使用的两个cspdarknet网络结构完全相同,包括:根据图2中箭头方向进行连接的darknetconv2d_bn_mish模块以五组resblock_body模块。如图2所示,在doublecspdarknet53网络中,会融合两个cspdarknet53网络的输出特征图,得到增强的输出特征图,其中从第二组resblock_body模块到第五组resblock_body模块,输出特征图大小依次为104*104,52*52,26*26,13*13。本发明在特征提取主干网络部分使用到的各个模块,例如darknetconv2d_bn_mish模块,与原yolov4算法中的对应模块相同,因此不再对其具体结构进行描述。
28.所述spp模块包含4个池化核大小分别为13*13、9*9、5*5、1*1的并行的最大池化层。所述spp模块的作用是对改进特征提取网络中大小为13*13的输出特征图的感受野进行增强,不同池化核会得到不同感受野的特征图,然后将4个处理后的特征图再去通道维度进行拼接,得到spp模块输出特征图。
29.所述改进特征融合网络包含上采样层(上采样层1、上采样层2、跨层上采样层)、融合层(融合层1、融合层2、融合层3、融合层4、融合层5)、下采样层(下采样层1、下采样层2、下采样层3)、卷积层,并根据图2所示数据流向进行依次连接。
30.其中:
31.所述spp模块的输出特征图分别输入到上采样层1与、跨层上采样层与融合层5,将上采样层1输出特征图输入到融合层1,将跨层上采样层的输出特征图输入到融合层2,最后将融合层5输出特征图输入到多分类器模块。
32.所述double-darknet53网络的26*26大小的输出特征图输入到融合层1,将融合层1的输出特征图分别输入到上采样层2与融合层4,将上采样层2的输出特征图输入到融合层2,将融合层4的输出特征图分别输入到多分类器模块与下采样层3,最后将下采样层3的输出特征图输入到融合层5。
33.所述double-darknet53网络的52*52大小的输出特征图输入到融合层2,将融合层2的输出特征图输入到融合层3,将融合层3的输出特征图分别输入到下采样层2与多分类器模块,最后将下采样层2的输出特征图输入到融合层4。
34.所述double-darknet53网络的104*104大小的输出特征图输入到下采样层1,将下采样层1的输出特征图输入到融合层3。
35.关于改进特征融合网络中未具体说明的数据输入输出的层,只需依据数据流向(见图2中箭头方向)依次传递数据信息。为完成网络中的数据信息正常传递,改进特征融合网络中包含大量卷积层,值得注意的是,卷积层使用方式与yolov4算法相同,因此这里不进
一步赘述。
36.本发明提出的改进特征融合网络中,通过3次上采样操作将不同层特征图连接,完成语义信息的向上传递,例如13*13大小的输出特征图分别以2倍上采样、4倍上采样与26*26大小的输出特征图、52*52大小的输出特征图进行拼接,26*26大小的输出特征图则通过2倍上采样与52*52大小的输出特征图进行拼接,最终形成密集连接网络结构,实现特征重用。在上采样之后,以大小为104*104的输出特征图为起点,进行下采样,旨在向下传递细节信息,容易理解的是,整个下采样过程共包含3次下采样操作,下采样率均为2,如104*104的输出特征经2倍下采样后,大小变为52*52,再与52*52大小的输出特征图进行拼接,以此类推,完成整个下采样过程。
37.所述多分类器模块包含三个yolo_head分类器,分别用于所述改进特征融合模块的三个大小分别为52*52、26*26、13*13的输出特征图。需要注意的是,三个yolo_head分类器的结构与原yolov4算法中提供的yolo_head结构相同,因此对yolo_head分类器的具体结构不再赘述。
38.所述yolo_head分类器分别采用52*52、26*26、13*13三个尺度的融合特征层的输出特征图与对应的logistic分类器进行行人检测。以13*13大小的特征图为例,将待检测图片分割为由13*13个单元格组成的图片,根据行人目标的真值框所处单元格位置,决定由哪个单元格对该目标进行检测。其中,每个单元格对应三个不同大小的预测框,共计13*13*3=507个。当检测结果的类别置信度不小于设置好的阈值(一般取0.5)时,将保留符合条件的预测框,最后通过非极大值抑制(nms)算法对预测框进行筛选,保留最佳预测框,剔除冗余预测框。综上,yolov4改进算法最多可以检测(52*52) (26*26) (13*13)=3549个目标,共计生成3549*3=10647个预测框。
39.值得注意的是,yolov4改进算法与yolov4算法相同,使用不同尺度特征图预测不同大小目标。其中最浅层特征图(52*52)具有较为丰富的细节信息,适用于检测小型目标,最深层特征图(13*13)具有较为丰富的语义信息,适用于检测大型目标,中间层特征图(26*26)实现了语义信息和细节信息的平衡,适用于检测中型目标。这样的检测方式使得本发明的yolov4改进算法适用范围大,对各尺度的行人目标均具有良好的检测性能。
40.步骤三、使用所述夜间行人数据集对本发明提出的yolov4改进算法进行训练,得到适用于夜间行人检测的网络模型。
41.本发明在训练时,按照9∶1的比例将夜间行人数据集划分为训练集和测试集。容易理解的是,训练集中包含的4000张图片用于迭代训练得到网络模型,其本质是利用损失函数指导训练过程中的网络模型参数调整,当损失函数的值不再下降时,模型训练完成。然后使用测试集计算map值(平均精度),对训练结果进行验证。
42.本发明使用多尺度训练的方法提高改进算法的检测性能,使改进算法能够适应不同尺度的行人目标。同时,在训练过程采取以下技巧提高训练效果。
43.(1)mosaic数据增强方法。将一个批次内的4张图片进行组合,得到一张具有更丰富的信息的图片用于检测。
44.(2)ciou。与iou不同,ciou会了让目标框的回归更为稳定,将目标与候选框之间的距离、重叠率与惩罚项等因素均纳入考虑范围。ciou的公式如下:
[0045][0046]
式中,iou是真值框与候选框的交并比,ρ2(b,b
gt
)分别代表预测框与真值框的中心点之间的欧式距离,c是指将预测框与真值框包含在内的最小闭包区域的对角线距离。α与v如下:
[0047][0048][0049]
其中w
gt
、h
gt
、w、h依次为真值框和预测框的宽、高。
[0050]
ciou损失函数如下:
[0051][0052]
(3)余弦退火学习率。初始学习率设置为0.001,在整个训练过程中,学习率随着余弦曲线进行增加或者衰减。
[0053]
(4)dropblock正则化。dropout是一种按照设置的概率将网络中的部分神经元屏蔽,防止神经网络过拟合的方法。dropblock则是dropout在卷积层上的扩展,dropblock将屏蔽部分神经元的思想应用于卷积层,完成特征增强。
[0054]
步骤四、将输入图像大小设置为416*416,使用zero-dce算法对输入图像进行光照增强。zero-dce是一种低光照图像增强算法,以弱光照图像作为输入,把产生的高阶曲线作为输出,然后这些曲线被用作对输入的变化范围的像素级调整,从而获得一个增强的图像。
[0055]
zero-dce算法包括如下三个部分:
[0056]
(1)光增强曲线
[0057]
(a)一阶曲线。如下式所示。
[0058]
le(i(x);α)=i(x) αi(x)(1-i(x))
[0059]
其中x为像素坐标;le(i(x);α)为增强输出;α∈[-1,1]为可训练的曲线参数。一阶曲线会对每个像素都归一化,并且所有操作都是逐像素进行。
[0060]
(b)高阶曲线。高阶曲线主要是解决一阶曲线增强不足的问题。如下所示:
[0061]
len(x)=le
n-1
(x) αnle
n-1
(x)(1-le
n-1
(x))
[0062]
其中x为像素坐标;len(x)为增强输出;le
n-1
(x)为输入;αn∈[-1,1]为可训练的曲线参数;n代表迭代次数,一般取8。
[0063]
(c)逐像素曲线。当网络预测结果是一个α的map时,亮度调节曲线如下所示:
[0064]
len(x)=le
n-1
(x) anle
n-1
(x)(1-le
n-1
(x))
[0065]
其中,an为由可训练参数αn组成的map。
[0066]
(2)深度曲线估计网络
[0067]
深度曲线估计网络用于学习光增强曲线中的可训练曲线参数,获得增强图像。如图3所示,该网络是一个简单的7层卷积神经网络,没有bn与下采样,全部由卷积核大小为3*3的32通道的卷积层与relu激活层组成。
[0068]
(3)无参考损失函数
[0069]
zero-dce算法包含4种无参考损失函数。
[0070]
(a)空间一致性损失(spatial consistency loss)
[0071]
用于约束输入图像与增强图像相邻区域的梯度,保持图像的空间一致性。如下所示:
[0072][0073]
其中:k为局部区域的数量,ω(i)是以区域i为中心的四个相邻区域(top,down,left,right)。y和i分别为增强图像和输入图像的局部区域平均强度值。
[0074]
(b)曝光控制损失(exposure control loss)
[0075]
用于约束曝光水平。将增强图像转化为灰度图,分级为若干16x16patches,计算patch内平均值。
[0076][0077]
其中:其中m为16
×
16的不重叠局部区域的数量。y为增强图像中局部区域的平均强度值。
[0078]
(c)色彩恒常性损失(color constancy loss)
[0079]
用于约束潜在色彩偏差,建立三通道之间联系,要让增强后的颜色尽可能相关。
[0080][0081]
其中:其j
p
代表增强图像通道p的平均强度,(p,q)代表一对通道。
[0082]
(d)光照平滑损失(illumination smoothness loss)
[0083]
用于相邻像素之间的单调关系。
[0084][0085]
其中:n为迭代次数,分别代表水平和垂直方向的梯度操作。
[0086]
综上,总损失函数为:
[0087][0088]
步骤五、检测行人目标。针对zero-dce网络输出的增强图像,采用改进yolov4网络输出最终的行人检测结果,检测结果包括待分类图像中行人目标的位置以及对应的类别,类别标注为person。另外,非行人目标属于背景,不需要进行标注。
[0089]
针对不同应用场景,可以采用摄像头实时采集的视频信息,按帧截取待检测图像,并对所得图像进行裁剪或者填充,使其缩放到416*416大小,作为本发明提出的检测算法的输入。
[0090]
需要说明的是,本发明对如何展示目标检测结果不做任何限制,使用者按照自身需求完成最终结果的展示。
[0091]
以上对本发明的描述较为具体,但并不能理解为对发明专利范围的限制。需要指出的是,对于本领域的普通技术人员而言,在不脱离本发明提供的思路的前提下,可根据自身需求做出相应改进,这些均属于本发明申请的保护范围。因此,具体的保护范围因以所附的权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。