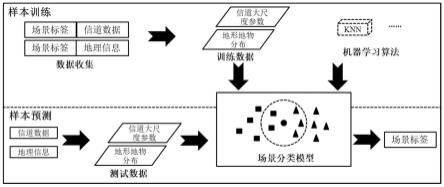
1.本发明属于电波传播技术领域,特别涉及一种利用无线信道大尺度衰落特性和地理信息的机器学习辅助的通信场景分类方法。
背景技术:
2.场景分类被认为是第五代和第六代移动通信系统中极具潜力的技术之一,一般的场景分类又分为视距传播(line-of-sight,los)和非视距传播(non-line-of-sight,nlos)识别、无线通信场景分类和室内室外检测。无线通信场景分类对信道模型校正、网络规划都有着极大的推动作用,尤其是毫米波信道模型。由于毫米波波长与环境中的物理散射体尺寸接近,毫米波信道特性受通信环境影响巨大。在毫米波信道建模过程中,需要充分考虑场景因素的影响,可以通过通信场景分类提取场景因子作为毫米波模型的校正项。
技术实现要素:
3.发明目的:针对上述现有技术中的问题,提出了一种基于大尺度衰落特性和地理信息的机器学习辅助的通信场景分类方法。利用多源信息,将信道大尺度特性与地理信息相结合,使用机器学习分类算法实现了高精度、低复杂度的无线通信场景分类框架,获取大尺度信道参数相比于获取小尺度参数需要更少的信道测量的工作量以及计算复杂度,在信道模型校正、网络规划、移动用户定位等通信领域有着很大的应用价值。
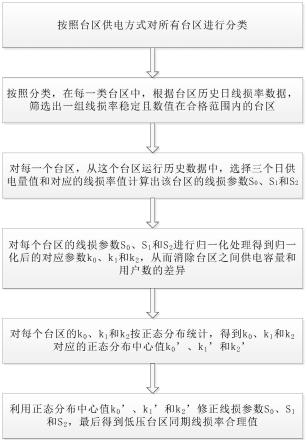
4.技术方案:基于多源信息的机器学习辅助通信场景分类方法,包括以下步骤:
5.步骤1:根据基站和测量点的经纬度坐标,计算测量点到基站之间的距离;
6.步骤2:分析不同场景在700mhz频率下测得的路测数据,对路测数据进行筛选;
7.步骤3:根据步骤2中计算出的中值拟合每个场景下的基于自由空间参考的路径损耗(close-in,ci)模型,并拟合浮动截距模型和自由空间路径损耗模型作为参考;
8.步骤4:根据步骤3得到的路径损耗模型,提取路径损耗因子和阴影衰落标准差等大尺度参数;
9.步骤5:利用地理信息系统,从高精度地图中统计出各种地形以及不同高度的建筑物的面积,计算出每项占该场景总面积的比例;
10.步骤6:采用特征权重量化等数据预处理方法,经过数据预处理后得到一个包含二维特征的数据集,其中样本被分为三类:密集城区,一般城区和郊区,降低数据维度,提取包含信道大尺度特性和地理信息的特征数据;
11.步骤7:采用机器学习分类算法,将带标签的预处理后的数据作为输入特征,实线无线通信场景分类;
12.步骤8:绘制分类结果的混淆矩阵,进一步分析不同场景下的分类性能。
13.进一步的,所述步骤1中,对于两点经纬度坐标a(lona,lata)、b(lonb,latb),按照0度经线基准,东经取经度的正值,西经取经度负值,北纬取90减纬度值,南纬取90加纬度值,经过上述处理过后的两点计为a'(mlona,mlata)和b'(mlonb,mlatb),设r为地球半径,
14.c=sin(mlata)*sin(mlatb)*cos(mlona-mlonb) cos(mlata)*cos(mlatb)
15.则两点的距离为
16.d=r*arc(c)*π/180
17.进一步的,所述步骤2中,对一段路径上的大量信道数据按一定的比例随机选取,根据国际电信联盟建议随机选取50%数据量并计算出中值。
18.进一步的,所述步骤3中,根据步骤2计算出的中值,采用最小二乘法拟合每个场景的路径损耗模型,并绘制自由空间下的路径损耗曲线作为参考,横轴采用对数距离。
19.进一步的,所述步骤6中,采用特征权重量化方法,先将每个特征的样本进行均值归0,用所有样本减去样本的均值从而不改变样本的分布,然后计算样本点映射后的方差,根据方差大小赋予所有特征不同的权重,将多维特征映射到更低维度上。
20.进一步的,所述步骤7中,机器学习分类算法选用k最邻近(k-nearest neighbour,knn)算法;knn算法采用距离判决,从待分类点的距离最近k个邻居中统计这些邻居样本所属的标签,将待分类点归为标签做多的那一类。knn算法需要对输入特征进行归一化,同时也需要确定合适的k值。
21.为了实现上述目的,本发明还采用的技术方案是:基于大尺度衰落特性和地理信息的机器学习辅助的通信场景分类方法在有明显城市化进程差距的多个省份的应用,包括如下步骤:
22.步骤1:根据基站和测量点的经纬度坐标,计算测量点到基站之间的距离;
23.步骤2:分析不同场景下测量得到的700mhz频率的路测数据,采用选取50%概率的中值算法对数据进行筛选;
24.步骤3:根据步骤2中计算出的中值使用最小二乘法拟合每个场景下的基于自由空间参考的路径损耗(close-in,ci)模型,并拟合浮动截距模型和自由空间路径损耗模型作为参考;
25.步骤4:根据步骤3得到的700mhz频率下的路径损耗模型,计算路径损耗因子和阴影衰落标准差等大尺度参数;
26.步骤5:利用gis中的高精度地图统计出各种地形以及不同高度的建筑物的面积,计算出每项占该场景总面积的比例;
27.步骤6:先将每个省的样本特征根据其最大值和最小值进行标准化,再采用特征权重量化技术,提取较少的综合指标分别代表信道大尺度特性和地理信息,降低数据维度;
28.步骤7:采用knn算法,将带标签的预处理后的数据集作为输入特征,实现无线通信场景分类;
29.步骤8:绘制分类结果的混淆矩阵,进一步分析不同场景下的分类性能。
30.作为本发明的一种改进,所述步骤7中,使用加权k最近邻(weighted knn,wknn)算法,在knn算法的基础上为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重。在给近邻分配权重时,通常用到反比例函数和高斯函数。wknn在处理数值型数据时,并不是对这k个数据简单的求平均,而是加权平均,通过将每一项的值乘以对应权重,然后将结果累加。求出总和后,除以所有权重之和。
31.即本方法可以对多省份进行无线通信场景分类,也可以对单一省份进行分类。当对单一省份内的通信场景进行分类时,可以将原始数据权重量化后提取特征输入到分类器
中;当对有明显城市化进程差距的多个省份混合的通信场景进行分类时,需要预先对每个省份的数据根据设定的标准值进行特征标准化,使得人为定义的城区类别有相对准确的衡量标准,平衡不同省份间城市化进程差异给场景定义所带来的误差。
32.有益效果:与现有技术相比,本发明具有以下有益效果:(1)本发明在特征的选取中采用无线信道大尺度参数,不需要更加复杂的信道小尺度参数,降低了信道测量的设备需求,减少了信道测量的工作量和数据处理的计算复杂度;(2)本发明在特征的选取中采用大尺度参数结合地理信息的多源数据作为分类器的输入,避免因为单一属性的特征在特定场景下存在的偶然性,利用多源信息的通信场景分类方法提高了场景分类的准确率。
附图说明
33.图1为本发明基于大尺度衰落特性和地理信息的机器学习辅助的场景分类方法框架;
34.图2为某密集城区场景使用选取50%概率中值拟合的路径损耗模型示意图;
35.图3为某一般城区场景使用选取50%概率中值拟合的路径损耗模型示意图;
36.图4为某郊区场景使用选取50%概率中值拟合的路径损耗模型示意图;
37.图5为knn对单一省份样本分类结果示意图;
38.图6为knn对多个省份样本分类结果示意图;
39.图7为knn对多个省份样本分类结果混淆矩阵示意图;
40.图8为knn与wknn在不同k值下的性能对比图。
具体实施方式
41.以下将结合附图和实施例,对本发明进行较为详细的说明。
42.实施例1
43.在本发明具体实施例中,通过信道测量获得了浙江省700mhz频率下10处场景的路测数据,并利用地理信息系统高精度地图统计各个场景的地形地物面积占比,其中包括4个密集城区场景,3个普通城区场景,3个郊区场景。然后对信道数据和地形分布进行数据预处理,提取典型特征输入knn分类器中分类。本例应理解实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。本发明实施例中未详细说明的均为现有技术。
44.如图1所示的分类方法框架,本发明提出的基于大尺度衰落特性和地理信息的场景分类方法,包括以下步骤:
45.步骤1:经纬度坐标转换成距离,按照转换公式计算出测量点到基站的距离。
46.步骤2:统计每个测量点或一段测量路径上的数据量,随机产生从1到该数据量范围内一半的正数作为数据索引,来随机选取50%的测量数据,并计算中值。
47.步骤3:根据步骤1计算的每个测量点到基站的距离以及步骤2得到的该处测量数据的中值,使用最小二乘法拟合该场景的路径损耗模型,密集城区、一般城区和郊区的拟合结果如图2、图3和图4所示,灰色线条表示自由空间路径损耗,黑色实线是拟合出的ci模型,黑色虚线是拟合出的fi模型。
48.步骤4:根据步骤3拟合得到的700mhz路径损耗模型,提取路径损耗因子和阴影衰
落标准差等信道大尺度参数,该10个场景的大尺度信道参数如表1所示;
49.步骤5:特征提取降低数据维度:采用特征权重量化,针对信道大尺度参数和地理地形分布信息,步骤如下:
50.s1:对每个特征进行中心化:
51.s2:计算协方差矩阵及其特征向量,按照特征值排序;
52.s3:根据特征值的大小赋予给个特征固定权重;
53.s4:将每个特征数据乘以权重并累加求和,作为最终的一项输入。
54.步骤6:采用knn分类算法,将预处理后的信道特征和地理信息作为输入,分类结果如图5所示,knn算法步骤如下:
55.s1:预处理数据,对特征进行归一化;
56.s2:计算已知类别数据集中的点与当前点的欧氏距离;
57.s3:按照距离依次排序;
58.s4:选取与当前点距离最小的k个点;
59.s5:返回前k个点出现频率最高的类别作为当前预测点的分类类别。
60.利用提出方法的通信场景分类结果:
61.图5给出了knn算法的分类结果,在同一省份中,由于没有过大的城市化水平差距和地理差异,knn分类器的分类效果比较理想。图中不同的深度的背景颜色用于划分不同类别的分类边界,不同形状的点代表不同类别的样本。
62.表1
[0063][0064]
实施例2
[0065]
在本发明具体实施例中,通过信道测量获得了浙江、上海、福建、济南四个省份在700mhz频率下21处场景的信道数据,并利用gis高精度地图统计各个场景的地形地物面积占比,其中包括11个密集城区,5个普通城区,5个郊区。然后对信道数据和地形分布进行预处理,提取典型特征输入knn分类器和wknn分类器中分类。本例应理解实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种
等价形式的修改均落于本技术所附权利要求所限定的范围。本发明实施例中未详细说明的均为现有技术。
[0066]
步骤1:经纬度坐标转换成距离,按照转换公式计算出测量点到基站的距离。
[0067]
步骤2:统计每个测量点或一段测量路径上的数据量,随机产生从1到该数据量范围内一半的正数作为数据索引,来随机选取50%的测量数据,并计算中值。
[0068]
步骤3:根据步骤1计算的每个测量点到基站的距离以及步骤2得到的该处测量数据的中值,使用最小二乘法拟合该场景的路径损耗模型;
[0069]
步骤4:根据步骤3拟合得到的700mhz路径损耗模型,提取路径损耗因子和阴影衰落标准差等信道大尺度参数;
[0070]
步骤5:特征提取降低数据维度:首先每个省的数据进行特征标准化,设定的标准参考值v1、v2(v1《v2)要能够代表场景划分的边界水平,然后采用特征权重量化技术,针对信道大尺度参数和地理地形分布信息,步骤如下:
[0071]
s1:每个省份内部的特征根据标准参考值进行标准化:
[0072]
s1:对每个特征进行中心化:
[0073]
s2:计算协方差矩阵及其特征向量,按照特征值排序;
[0074]
s3:根据特征值的大小赋予给个特征固定权重;
[0075]
s4:将每个特征数据乘以权重并累加求和,作为最终的一项输入。
[0076]
步骤6:采用knn分类算法,将预处理后的信道特征和地理信息作为输入,其步骤如下:
[0077]
s1:预处理数据,对特征进行归一化:
[0078]
s2:计算已知类别数据集中的点与当前点的欧氏距离;
[0079]
s3:按照距离依次排序;
[0080]
s4:选取与当前点距离最小的k个点;
[0081]
s5:返回前k个点出现频率最高的类别作为当前预测点的分类类别。
[0082]
步骤7:绘制混淆矩阵分析knn算法的分类结果;
[0083]
步骤8:采用wknn分类算法作为改进,将预处理后的信道特征和地理信息作为输入,其算法步骤如下:
[0084]
s1:预处理数据,对特征进行归一化;
[0085]
s2:计算已知类别数据集中的点与当前点的欧氏距离;
[0086]
s3:采用高斯函数对不同距离的样本进行权重优化;
[0087]
s4:按照距离依次排序;
[0088]
s5:选取与当前点距离最小的k个点;
[0089]
s6:返回前k个点出现频率最高的类别作为当前预测点的分类类别。
[0090]
利用提出方法的通信场景分类结果:
[0091]
对于多个省份的数据混合分类时,knn的分类结果如图6所示,混淆矩阵如图7所示,在该实施例中发现,由于不同类别的样本集大小不均衡,密集城区场景样本数量远远大于其他两类样本数量,样本数量对结果的影响大于样本距离的影响。在knn基础上对距离加
以权重的wknn方法可以一定程度上解决这个问题,图8给出了选取不同的k值时knn与wknn两种分类方法的性能,可以看出这种情况下性能得到了优化,由于样本数量较少,优势不够明显。
[0092]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。