1.本发明涉及基于图文多模态门控增强的文本平行句对抽取方法,属于自然语言处理技术领域。
背景技术:
2.从互联网海量文本中爬取和整理平行句对是提升机器翻译性能的重要工作之一。网络信息中存在大量伪平行的句对,因此需要从海量伪平行句对中抽取双语平行句对。目前,主流平行句对抽取方法大都基于句子级语义相似性来进行,因此容易出现语义相近但完全不平行的句对,如表1(不平行的词语用斜体标出)。这样的低质量句对严重影响了后续机器翻译的性能,因此研究平行句对抽取方法对提升平行句对的质量,提高机器翻译性能具有重要的意义和价值。
3.表1:不平行表
[0004][0005]
目前主流平行句对抽取方法主要基于使用预训练模型获取句子级表示然后转化为二分类方式的方法,基本可以分为三类,依次为:依赖传统方法,增强训练策略以及使用多语言预训练模型。传统的方法主要基于句法特征、转换或关系提取,该方法认为需要将提取出的信息融入句子表征来提升模型效果。第二类基于训练策略的方式,accarcciccek等人证明,在分类任务中正负例的比例会影响最后模型效果,且负例多余正例更有利于模型性能的提升,由此引出了如何构造高质量负例的问题。使用模糊匹配等算法构建了高质量负例成功提升了最终模型性能,其实验结果表明在合理构建训练数据后,模型仍然有一定的提升空间。在自然语言处理任务中,bert提出后,刷新了多项任务记录,在平行句对抽取中也是如此。使用多语言预训练模型可以将不同语言的信息编码到同一语义空间,这一过程可以将更多语言信息融入到模型,利用多语言模型实现的不同语言在同一语义空间的"对齐"可以提升模型性能,实验证明使用多语言预训练模型可以提升最后的评价分数。预训练语言模型仅仅可以实现句子级的语义对齐,对词粒度的直接对齐考虑不足。因此基于多语言预训练模型的方法仍然有存在提升空间。
[0006]
表1中,英语-越南语伪平行句(第一,二列)对语义信息基本一致,但是词级粒度存在较大的不一致,因此基于预训练模型的语义对齐判别方法会将其判别为平行句对,但是
上例中明显词级粒度存在较大的差异,如何保证句子级语义一致的情况下,考虑词级对齐问题,是伪平行句对需要解决的重要问题之一。
技术实现要素:
[0007]
本发明提供了基于图文多模态门控增强的文本平行句对抽取方法,能解决英语-越南语平行句对抽取问题中词级匹配不准确的问题、解决了图像融入文本中图像噪声过大问题;本发明以语言无关的图像信息作为跨语言语义对齐的锚点,融合图像表征,实现跨语言句对的语义对齐的方法。通过对源语言目标语言分别融合其关联的图像信息,提升跨语言表征和对齐的性能,借助语言无关的图像信息,增强伪平行句对在句子级和词级语义对齐的能力,进而最终提升伪平行句对抽取的性能。
[0008]
本发明的技术方案是:基于图文多模态门控增强的文本平行句对抽取方法,所述方法的具体步骤如下:
[0009]
step1、建立多语言图像检索标签库,将不同语种文本进行分词后进行检索语义相关图像,得到图像编号;
[0010]
step2、使用文本预训练模型得到不同语种文本的文字表征,然后使用resnet50提取step1中得到的语义相关图像表征,接着用多模态门控将对应的文本和图像进行融合,得到两种语言的多模态表征;
[0011]
step3、将step2得到的不同语种多模态表征进行拼接,然后将拼接后的表征送入前馈神经网络层并且经过sigmoid函数进行映射,从而将平行句对抽取任务转化为分类任务后得到平行句对预测结果。
[0012]
作为本发明的进一步方案,所述step1的具体步骤如下:
[0013]
step1.1、使用已有图像数据集的文字描述标注句子中的名词和动词作为该图像匹配关键词,建立标签检索库表示一对训练语料句对,其中i代表第i个平行句对,α,β,分别代表不同语种,定义v={{i0,i1,i2...ij},j=0,1,2...n}代表图像数据集,其中每张图像ij都有对应的不同语种图像描述句对遍历数据集v,对每张图像不同语种图像描述句对使用词性标注pos工具提取名词和动词作为该图像的标签,记作其中n表示该图像标签个数,对应的
[0014]
step1.2、进行语义相关图像检索:假设输入某一语种句子使用分词工具将该句子进行分词,得到其中m为句子中词的个数,遍历图像数据集,可得,第j个图像对应α语言标签为其中将和进行最大公共子集算法lcs计算,得到最大子集元素个数s,则对应的图像ij作为检索得到的语义相关图像,记作利用相同的方式得到β语言句子语义相关图像
[0015]
作为本发明的进一步方案,所述step2的具体步骤如下:
[0016]
step2.1、用预训练模型提取文本表征:根据公式(1)(2)得到
[0017][0018]
[0019]
其中,对于α语言,为预训练提取文本表征中代表句子级语义特征的[cls]向量,最终用该向量表示第i句对α语言句子的表征,记作
[0020]
相应的对于β语言,为预训练提取文本表征中代表句子级语义特征的[cls]向量,最终用该向量表示第i句对β语言句子的表征,记作最终得到文字表征表示一对训练语料句对,其中i代表第i个平行句对,分别代表不同语种句子;z为句子的特征个数;
[0021]
step2.2、使用resnet50提取语义相关图像表征,其中对应第i句对α语言的图像可得图像表征对应第i句对β语言的图像可得到图像表征
[0022][0023][0024]
由此得到文字表征和图像表征
[0025]
step2.3、将step2.2得到的文本表征和图像表征根据公式(5)进行计算,得到门控参数λ
α
,公式(5)假设当前语种为α,相对应的对于语言β,公式(6)能得到门控参数λ
β
,其中,w为线性层参数;
[0026][0027][0028]
接着,根据公式(7)、(8)将公式(5)、(6)得到的参数和对应图像表征点乘,得到图文门控去噪后的图像表征
[0029][0030][0031]
最后,将得到的图像表征与文字表征融合,得到两种语言的多模态表征,采用加性融合策略,融合过程如下式(9)、(10);
[0032][0033][0034]
作为本发明的进一步方案,所述step3的具体步骤如下:
[0035]
step3.1、将step2得到多模态表征向量给出公式(11)拼接向量,得到向量ui,接着给出公式(12)进行线性变化得到特征向量,最后给出公式(13)将特征输入sigmoid函数得到最终分数进行损失计算;
[0036][0037]
a=relu(wui b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0038]
p(y=1|a)=sigmoid(a b)
ꢀꢀꢀ
(13)。
[0039]
本发明的有益效果是:
[0040]
1.本发明通过融合图像模态,提升双语句子级和词级语义表征的能力,实现了高质量伪平行句对的抽取;
[0041]
2.本发明基于词级相似度匹配的方法,实现了双语文本相关联图像信息的检索,为后续的图文融合提供数据基础;
[0042]
3.本发明借助多模态门控,实现噪声图像中有效图像表征的融合,提升了文本的语义表征能力;
[0043]
4.本发明对英语-越南语、英语-德语伪平行句对抽取任务进行实验,实验结果证明了本发明所提方法的有效性,伪平行句对抽取性能提升。
附图说明
[0044]
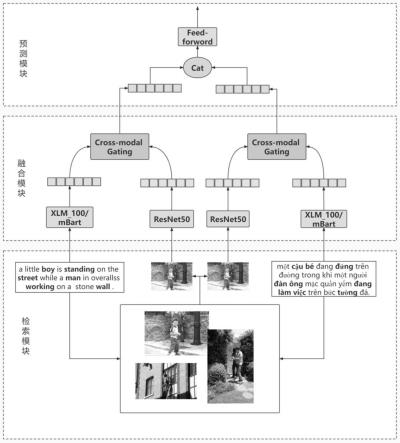
图1为本发明中的流程框图。
具体实施方式
[0045]
实施例1:如图1所示,基于图文多模态门控增强的文本平行句对抽取方法,所述方法的具体步骤如下:
[0046]
step1、建立多语言图像检索标签库,将不同语种文本进行分词后进行检索语义相关图像,得到图像编号;
[0047]
step2、使用文本预训练模型得到不同语种文本的文字表征,然后使用resnet50提取step1中得到的语义相关图像表征,接着用多模态门控将对应的文本和图像进行融合,得到两种语言的多模态表征;
[0048]
step3、将step2得到的不同语种多模态表征进行拼接,然后将拼接后的表征送入前馈神经网络层并且经过sigmoid函数进行映射,从而将平行句对抽取任务转化为分类任务后得到平行句对预测结果。
[0049]
作为本发明的进一步方案,所述step1的具体步骤如下:
[0050]
step1.1、使用已有图像数据集的文字描述标注句子中的名词和动词作为该图像匹配关键词,建立标签检索库表示一对训练语料句对,其中i代表第i个平行句对,α,β,分别代表不同语种,定义v={{i0,i1,i2...ij},j=0,1,2...n}代表图像数据集,其中每张图像ij都有对应的不同语种图像描述句对遍历数据集v,对每张图像不同语种图像描述句对使用词性标注pos工具提取名词和动词作为该图像的标签,记作其中n表示该图像标签个数,对应的
[0051]
step1.2、基于词级相似度匹配进行语义相关图像检索:假设输入某一语种句子使用分词工具将该句子进行分词,得到其中m为句子中词的个数,遍历图像数据集,可得,第j个图像对应α语言标签为其中将和进行最大公共子集算法lcs计算,得到最大子集元素个数s,利用最大子集元素个数作为词级相似度评价标准,对应的图像ij作为检索得到的语义相关图像,记作利用相同的方式得到β语言句子语义相关图像如遇到最大个数相同的选项时,选检索到的第一张图像作为最后结果。
[0052]
作为本发明的进一步方案,所述step2的具体步骤如下:
[0053]
step2.1、用预训练模型提取文本表征:根据公式(1)(2)得到
[0054][0055][0056]
其中,对于α语言,为预训练提取文本表征中代表句子级语义特征的[cls]向量,最终用该向量表示第i句对α语言句子的表征,记作
[0057]
相应的对于β语言,为预训练提取文本表征中代表句子级语义特征的[cls]向量,最终用该向量表示第i句对β语言句子的表征,记作最终得到文字表征表示一对训练语料句对,其中i代表第i个平行句对,分别代表不同语种句子;z为句子的特征个数;
[0058]
step2.2、使用resnet50提取语义相关图像表征,其中对应第i句对α语言的图像可得图像表征对应第i句对β语言的图像可得到图像表征
[0059][0060][0061]
由此得到文字表征和图像表征
[0062]
step2.3、将step2.2得到的文本表征和图像表征根据公式(5)进行计算,得到门控参数λ
α
,公式(5)假设当前语种为α,相对应的对于语言β,公式(6)能得到门控参数λ
β
,其中,w为线性层参数;
[0063][0064][0065]
接着,根据公式(7)、(8)将公式(5)、(6)得到的参数和对应图像表征点乘,得到图文门控去噪后的图像表征
[0066][0067][0068]
最后,将得到的图像表征与文字表征融合,得到两种语言的多模态表征,采用加性融合策略,融合过程如下式(9)、(10);
[0069][0070][0071]
作为本发明的进一步方案,所述step3的具体步骤如下:
[0072]
step3.1、将step2得到多模态表征向量给出公式(11)拼接向量,得到向量ui,接着给出公式(12)进行线性变化得到特征向量,最后给出公式(13)将特征输入
sigmoid函数得到最终分数进行损失计算;
[0073][0074]
a=relu(wui b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0075]
p(y=1|a)=sigmoid(a b)
ꢀꢀꢀ
(13)。
[0076]
为了说明本发明的效果,设置了2组对比实验。第一组实验验证本发明方法有效解决英语-越南语平行句对抽取问题中词级匹配不准确的问题,另一组实验验证图文多模态门控解决了图像融入文本中图像噪声过大问题。
[0077]
1.文本方法对比实验
[0078]
本发明分别使用xlm-100预训练模型和mbart预训练模型提取不同语种文本特征后进行拼接再进行二分类的方法作为基线。分别在越南语-英语,德语-英语语种对进行实验。评价标准为精确度,如下表2,表2中:
[0079]
xlm-100:基于xlm-100预训练模型的文本特征作为基线实验条件。
[0080]
mbart:基于mbart预训练模型的文本特征作为基线实验条件。
[0081]
xlm-100 image_maching gating:基于xlm-100预训练模型的文本特征和本发明中词级相似度匹配算法得到图像经过图文多模态门控去噪后融合的实验条件。
[0082]
mbart image_maching gating:基于mbart预训练模型的文本特征和本发明中词级相似度匹配算法得到图像经过图文多模态门控去噪后融合的实验条件
[0083]
表2为主实验结果
[0084]
模型en-vien-dexlm-10096%97.5%mbart-92.6%xlm-100 mage_maching gating96.8%
↑
98.2%
↑
mbart image_maching gating-92.7%
↑
[0085]
其中,基线模型在两对语言的实验都可以达到较好效果,但在添加图像增强后依旧可以提升模型性能。在基于xlm-100的模型中越南语-英语任务从96%提升至96.8%,德语-英语任务中从97.5%提升至98.2%。
[0086]
表3为实例分析,由表可得,在句子结构相似,但词级信息不平行的情况下,单一文本模态模型会错误判断为平行句对,本发明模型可以正确判断为非平行句对。
[0087]
表3实例分析
[0088][0089]
2.图文多模态门控消融实验
[0090]
为了探究多模态门控的控制噪声能力,本发明进行了门控消融实验。由表4第一二
行可见,没有使用图文多模态门控时,即使加入正确图像信息也会降低模型性能,en-vi任务降低2.2个点,en-de任务降低2.3个点。证明图文多模态门控进行控制前提下融入图像信息可以有效过滤一定噪声,提升模型性能,表4中:
[0091]
xlm-100 image_right gating:基于xlm-100预训练模型的文本特征和正确语义相关图像经过图文多模态门控去噪后融合的实验条件。
[0092]
xlm-100 image_right:基于xlm-100预训练模型的文本特征和正确语义相关图像直接融合的实验条件。
[0093]
mbart image_right gating:基于mbart预训练模型的文本特征和正确语义相关图像经过图文多模态门控去噪后融合的实验条件。
[0094]
mbart image_right:基于mbart预训练模型的文本特征和正确语义相关图像直接融合的实验条件。
[0095]
表4为图文门控消融实验结果
[0096]
模型en-vien-dexlm-100 image_right gating97.2%
↑
98.3%
↑
xlm-100 image_right95%
↓
96%
↓
mbart image_right gating-93.3%
↑
mbart image_right-90.7%
↓
[0097]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。