1.本发明涉及自然语言理解中的方面级情感分析,具体是一种多任务学习的双目标实体情感分析方法,可广泛应用于各个领域的方面级情感分析任务中。
背景技术:
2.方面级情感分类的目的是预测多个目标实体在句子或者文档中的极性,它是一项细粒度情感分析的任务,与传统的情感分析任务不同,它是在目标实体上做极性分析(一般为积极、消极、中性三个分类)。方面级情感分类常用在评论人的评论句子中,如:商场购物评论、餐饮评论、电影评论等。方面级情感分类,通常在一个句子中有两个方面词及其相关的情感取向,例如句子"prices are higher to dine but their food is quite good",对于目标实体“prices”它是消极的,但对于目标实体“food”它是积极的。
3.随着人工神经网络技术的不断发展,各种神经网络如long short-term memory(lstm)、deep memory network和google ai language提出的bidirectional encoder representations from transformers(bert)语言模型被应用于方面极性分类,从而为其提供端到端的分类方法,而无需任何特征工程工作。然而,当句子中有多个目标实体时,方面极性分类任务需要区分不同方面的情绪。因此,与只有一个整体情感取向的文档级情感分析相比,方面极性分类任务更加复杂,面临的主要挑战是:在对不同目标实体进行情感分析时,如何突出与其相关的情感表达而抑制与它不相关的情感表达。为了实现这一目标,目前针对方面极性分类的深度学习方法提出了多种以方面为中心的情感语义学习方法,例如:基于注意力的语义学习、位置衰减、左右语义学习、方面连接与全局语义学习等,但每种方法都存在一定程度的不相关情感表达的影响。为彻底解决多目标情感分析中不相关情感表达的影响,本发明提出一种多任务学习的双目标实体情感分析方法,通过语境分断符使得情感句子中两个目标实体的情感表达相互分离。
技术实现要素:
4.本发明公开了一种多任务学习的双目标实体情感分析方法,通过句子语境分断符识别与左右实体情感极性分类的多任务学习,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型,以更有效的方法解决方面级情感分析问题。
5.为实现上述目的,本发明的技术方案为:
6.一种多任务学习的双目标实体情感分析方法,其特征在于包括以下步骤:
7.s1.通过句子语境分断符识别与左右实体情感极性分类的多任务学习,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型;
8.s2.使用步骤s1所训练的神经网络模型识别情感句子中的语境分断符;
9.s3.在步骤s1所训练的神经网络模型中,以步骤s2得到的语境分断符所对应的位置对情感句子的语义表示进行分离,得到左子句语义表示和右子句语义表示,然后分别对
左子句语义表示和右子句语义表示进行情感分析,最终得到双目标实体的情感极性;
10.所述情感句子是指包含左、右两个目标实体的多情感表达句子;
11.所述语境分断符是指在情感句子中位于左右两个目标实体之间、使得两个目标实体的情感表达相互分离的字词;
12.所述神经网络模型是指一种基于bert语言模型的神经网络结构;所述bert语言模型是指google ai language提出的bidirectional encoder representations from transformers(bert)语言模型。
13.进一步的,所述步骤s1具体包括:
14.s1.1 bert语言模型的输入序列s是由情感句子sen={
…
,t1,w1,w2,
…
,wn,t2,
…
}与bert编码符号所组成,如下所示:
[0015][0016]
mid={w1,w2,...,wn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0017]
其中,[cls]是bert分类符的编码,[sep]是bert结束符的编码,t1是待分析的左目标实体,t2是待分析的右目标实体,mid={w1,w2,...,wn}是左右目标实体t1和t2之间的中间字词序列,
“…”
代表省略的字词序列,m是输入序列s的长度,dw是bert中字符编码的维度,n是中间字词序列mid的长度,所述“字词”是指文本经bert的分词器tokenzier分离出的语言片段;
[0018]
s1.2将输入序列s送入bert语言模型进行处理,得到情感句子sen的句子语义表示c
sen
,如下所示:
[0019][0020]
其中,表示bert语言模型,是bert语言模型的第i个隐藏状态,db是bert语言模型的隐藏单元数;
[0021]
s1.3按照对应关系,从c
sen
中抽取出中间字词序列mid={w1,w2,...,wn}所对应的中间语义表示c
mid
,如下所示:
[0022][0023]
其中,表示中间语义提取,是第i个中间字词wi在c
sen
中所对应的隐藏状态;
[0024]
s1.4对中间语义表示c
mid
执行一个softmax线性变换,进行语境分断符的识别,计算过程如下所示:
[0025][0026][0027][0028]
其中,公式(5)和(6)是对中间语义表示c
mid
执行softmax线性变换的计算过程,是一个用于语境分断符识别的可学习的参数向量,是一个偏置参数,表
示向量的点积运算,是中间字词序列mid对应的语境分断置信分数向量,w为一个中间字词,ρ(w|c
mid
,θ)表示中间字词w为语境分断符的预测概率,表示返回使得ρ(w|c
mid
,θ)为最大值的中间字词,w
*
为计算得出的语境分断符,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数;
[0029]
s1.5以语境分断符w
sp
作为分隔符,形成两个由1、0组成的掩码矩阵,将句子语义表示c
sen
分离成左子句语义表示c
left
和右子句语义表示c
right
,计算过程如下所示:
[0030][0031][0032][0033][0034][0035][0036]
其中,mask
l
为用于分离左子句语义的掩码矩阵,maskr为用于分离右子句语义的掩码矩阵,为一个全1向量,为一个全0向量,tonkeni∈sen为句子sen中的第i个字词,函数求指定字词在句子sen中的位置编号,为mask
l
中的第i列向量,i∈[1,m]且为整数,为maskr中的第j列向量,j∈[1,m]且为整数,表示逐元素相乘;
[0037]
s1.6分别在左子句语义表示c
left
和右子句语义表示c
right
上执行一个多头自注意力的编码过程,得到左子句语义编码c'
left
和右子句语义编码c'
right
,计算过程如下所示:
[0038][0039][0040]
其中,mhsa()x表示输入的多头注意力mha(q,k,v);
[0041]
s1.7分别对左子句语义编码c'
left
和右子句语义编码c'
right
执行平均池化操作,得到左子句情感向量z
l
和右子句情感向量zr,计算过程如下:
[0042][0043][0044]
其中,avepooling(c)表示对参数执行按列求平均值的池化操作;
[0045]
s1.8分别对左子句情感向量z
l
和右子句情感向量zr执行softmax的线性变换,进行情感极性的概率计算,并得出最终的情感极性,计算过程如下:
[0046][0047][0048][0049][0050][0051][0052]
其中,是情感极性的表示矩阵,是一个偏置向量,dk是情感极性的个数,y是情感极性的集合,y是一个情感极性,分别是z
l
和zr所对应的情感极性置信分数向量,ρ(y|z
l
,θ)、ρ(y|zr,θ)分别表示z
l
和zr在情感极性y上的预测概率,y
l
、yr分别为最终评定的左情感极性和右情感极性,分别为最终评定的左情感极性和右情感极性,分别表示返回使得ρ(y|z
l
,θ)和ρ(y|zr,θ)为最大值的情感极性,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数。
[0053]
更进一步的,所述步骤s1中,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型的联合训练方法为:
[0054]
(1)分别使用交叉熵损失误差计算语境分断符识别的损失函数和双目标实体情感分析的损失函数,计算过程如下:
[0055][0056][0057][0058]
其中,ω是双目标实体情感分析任务的训练句子的集合,|ω|表示集合ω的大小,是ω中第i个训练句子的语境分断符的字词标签,是ω中第i个训练句子的中间语义表示,表示,分别是ω中第i个训练句子的左情感极性标签和右情感极性标签,分别是ω中第i个训练句子的左子句情感向量和右子句情感向量,ψ
mid
(θ)是进行语境分断符识别训练时使用的损失函数,ψ
l
(θ)是进行左目标实体情感分析训练时使用的损失函数,ψr(θ)是进行右目标实体情感分析训练时使用的损失函数;
[0059]
(2)使用如下的公式(27)计算联合训练句子语境分断符识别与双目标实体情感极
性分类的联合损失函数
[0060][0061]
其中,α1和α2是两个权重参数;
[0062]
(3)联合训练目标是最小化公式(27)计算的联合损失误差。
[0063]
为彻底解决多目标情感分析中不相关情感表达的影响,本发明提出一种多任务学习的双目标实体情感分析方法,通过语境分断符使得情感句子中两个目标实体的情感表达相互分离。首先,通过句子语境分断符识别与左右实体情感极性分类的联合学习,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型。其次,使用所训练的神经网络模型识别情感句子中的语境分断符。再者,以得到的语境分断符所对应的位置对情感句子的语义表示进行分离,得到左子句语义表示和右子句语义表示,然后分别对左子句语义表示和右子句语义表示进行情感分析,得到双目标实体的情感极性。
[0064]
本发明具有以下优点:
[0065]
(1)通过一个广泛预训练与任务微调的bert语言模型,为情感句子动态编码,可有效克服方面级情感分析语料集过小的问题;
[0066]
(2)通过语境分断符使得情感句子中两个目标实体的情感表达相互分离,彻底解决多目标情感分析中不相关情感表达的影响;
[0067]
(3)通过语境分断符将双目标实体情感分析转换为两个独立的单目标实体情感分析,大幅度地提高了双目标实体情感分析的性能;
[0068]
(4)通过将包含更多目标实体的情感句子转换为多个双目标实体情感句子,本发明的方法可以应用到各种类型的方面级情感分析任务中。
附图说明
[0069]
图1是本发明的方法流程示意图。
具体实施方式
[0070]
以下结合具体实施例对本发明作进一步说明,但本发明的保护范围不限于以下实施例。
[0071]
设包含左目标实体t1和右目标实体t2的情感句子sen={
…
,t1,w1,w2…
,wn,t2,
…
},则通过以下步骤分析双目标实体t1和t2的情感:
[0072]
s1.通过句子语境分断符识别与左右实体情感极性分类的多任务学习,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型;
[0073]
s2.使用步骤s1所训练的神经网络模型识别情感句子中的语境分断符;
[0074]
s3.在步骤s1所训练的神经网络模型中,以步骤s2得到的语境分断符所对应的位置对情感句子的语义表示进行分离,得到左子句语义表示和右子句语义表示,然后分别对左子句语义表示和右子句语义表示进行情感分析,最终得到双目标实体的情感极性;
[0075]
所述情感句子是指包含左、右两个目标实体的多情感表达句子;
[0076]
所述语境分断符是指在情感句子中位于左右两个目标实体之间、使得两个目标实
体的情感表达相互分离的字词;
[0077]
所述神经网络模型是指一种基于bert语言模型的神经网络结构;所述bert语言模型是指google ai language提出的bidirectional encoder representations from transformers(bert)语言模型。
[0078]
进一步的,所述步骤s1具体包括:
[0079]
s1.1 bert语言模型的输入序列s是由情感句子sen={
…
,t1,w1,w2,
…
,wn,t2,...}与bert编码符号所组成,如下所示:
[0080][0081]
mid={w1,w2,...,wn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0082]
其中,[cls]是bert分类符的编码,[sep]是bert结束符的编码,t1是待分析的左目标实体,t2是待分析的右目标实体,mid={w1,w2,...,wn}是左右目标实体t1和t2之间的中间字词序列,
“…”
代表省略的字词序列,m是输入序列s的长度,dw是bert中字符编码的维度,n是中间字词序列mid的长度,所述“字词”是指文本经bert的分词器tokenzier分离出的语言片段;
[0083]
s1.2将输入序列s送入bert语言模型进行处理,得到情感句子sen的句子语义表示c
sen
,如下所示:
[0084][0085]
其中,表示bert语言模型,是bert语言模型的第i个隐藏状态,db是bert语言模型的隐藏单元数;
[0086]
s1.3按照对应关系,从c
sen
中抽取出中间字词序列mid={w1,w2,...,wn}所对应的中间语义表示c
mid
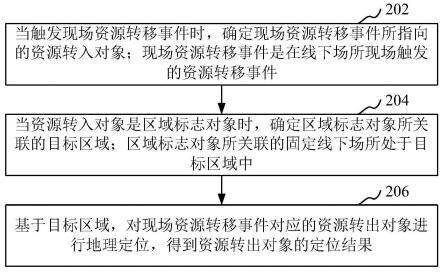
,如下所示:
[0087][0088]
其中,表示中间语义提取,是第i个中间字词wi在c
sen
中所对应的隐藏状态;
[0089]
s1.4对中间语义表示c
mid
执行一个softmax线性变换,进行语境分断符的识别,计算过程如下所示:
[0090][0091][0092][0093]
其中,是一个用于语境分断符识别的可学习的参数向量,是一个偏置参数,表示向量的点积运算,是中间字词序列mid对应的语境分断置信分数向量,w为一个中间字词,ρ(w|c
mid
,θ)表示中间字词w为语境分断符的预测概率,表示返回使得ρ(w|c
mid
,θ)为最大值的中间字词,w
*
为计算得出的
语境分断符,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数;
[0094]
s1.5以语境分断符w
sp
作为分隔符,形成两个由1、0组成的掩码矩阵,将句子语义表示c
sen
分离成左子句语义表示c
left
和右子句语义表示c
right
,计算过程如下所示:
[0095][0096][0097][0098][0099][0100][0101]
其中,mask
l
为用于分离左子句语义的掩码矩阵,maskr为用于分离右子句语义的掩码矩阵,为一个全1向量,为一个全0向量,tonkeni∈sen为句子sen中的第i个字词,函数求指定字词在句子sen中的位置编号,为mask
l
中的第i列向量,i∈[1,m]且为整数,为maskr中的第j列向量,j∈[1,m]且为整数,表示逐元素相乘;
[0102]
s1.6分别在左子句语义表示c
left
和右子句语义表示c
right
上执行一个多头自注意力的编码过程,得到左子句语义编码c'
left
和右子句语义编码c'
right
,计算过程如下所示:
[0103][0104][0105]
其中,mhsa()x表示输入的多头注意力mha(q,k,v);
[0106]
s1.7分别对左子句语义编码c'
left
和右子句语义编码c'
right
执行平均池化操作,得到左子句情感向量z
l
和右子句情感向量zr,计算过程如下:
[0107][0108][0109]
其中,avepooling(c)表示对参数执行按列求平均值的池化操作;
[0110]
s1.8分别对左子句情感向量z
l
和右子句情感向量zr执行softmax的线性变换,进行情感极性的概率计算,并得出最终的情感极性,计算过程如下:
[0111][0112]
[0113][0114][0115][0116][0117]
其中,是情感极性的表示矩阵,是一个偏置向量,dk是情感极性类别的个数,y是情感极性类别的集合,y是一个情感极性,分别是z
l
和zr所对应的情感极性置信分数向量,ρ(y|z
l
,θ)、ρ(y|zr,θ)分别表示z
l
和zr在情感极性y上的预测概率,y
l
、yr分别为最终评定的左情感极性和右情感极性,分别为最终评定的左情感极性和右情感极性,分别表示返回使得ρ(y|z
l
,θ)和ρ(y|zr,θ)为最大值的情感极性,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数。
[0118]
更进一步的,所述步骤s1中,联合训练一个具有句子语境分断符自动识别与双目标实体情感极性自动分类的神经网络模型的联合训练方法为:
[0119]
(1)分别使用交叉熵损失误差计算语境分断符识别的损失函数和双目标实体情感分析的损失函数,计算过程如下:
[0120][0121][0122][0123]
其中,ω是双目标实体情感分析任务的训练句子的集合,|ω|表示集合ω的大小,是ω中第i个训练句子的语境分断符的字词标签,是ω中第i个训练句子的中间语义表示,表示,分别是ω中第i个训练句子的左情感极性标签和右情感极性标签,分别是ω中第i个训练句子的左子句情感向量和右子句情感向量,ψ
mid
(θ)是进行语境分断符识别训练时使用的损失函数,ψ
l
(θ)是进行左目标实体情感分析训练时使用的损失函数,ψr(θ)是进行右目标实体情感分析训练时使用的损失函数;
[0124]
(2)使用如下的公式(27)计算联合训练句子语境分断符识别与双目标实体情感极性分类的联合损失函数
[0125][0126]
其中,α1和α2是两个权重参数;
[0127]
(3)联合训练目标是最小化公式(27)计算的联合损失误差。
[0128]
本实施例通过语境分断符使得情感句子中两个目标实体的情感表达相互分离,彻底解决多目标情感分析中不相关情感表达的影响。
[0129]
应用实例
[0130]
1.实例环境
[0131]
本实例使用google ai language在文献“devlin j,chang mw,lee k,toutanova k(2019)bert:pre-training of deep bidirectional transformers for language understanding.in:proceedings of the 2019conference of naacl,pp 4171
–
4186”中提出并开发的bert-base版本作为bert编码层的预训练模型,该bert模型包括12层transformers,768个隐藏单元,12个多头,以及总参数=110m);本实例采用的多头注意力来源于文献“vaswani a,shazeer n,parmar n,uszkoreit j,jones l,gomez an,kaiser l,polosukhin i(2017)attention is all you need.in:31st conference on neural information processing systems(nips 2017),pp 5998
–
6008”中,设置了注意力的头数为12;为了最小化损失值,本实例使用了adam optimizer优化器,并将学习率设置为2e-5,batch size大小设置为16;在训练期间,本实例将epochs设置为10。
[0132]
2.数据集
[0133]
本实例使用在国际上广泛使用的semeval-2014task 4数据集作为评测基准,该数据集于2014年在第八届国际语义评估研讨会上所公布。它提供了来自餐厅(rest)和笔记本电脑(lap)领域的两个评论数据集。semeval-2014task 4数据集中的每个样本由一个评论句子、一些观点目标和对观点目标的相应情感极性组成。数据集详细情况如表1所示。
[0134]
表1数据集详细情况
[0135][0136]
3.对比方法
[0137]
本实例将本发明的模型与5个非bert的方法和4个基于bert的方法进行比较,对比方法如下所示:
[0138]
(1)非bert的方法
[0139]
·
mennet[1]使用多层记忆网络结合注意力来捕捉每个上下文词对方面极性分类的贡献。
[0140]
·
ian[2]采用两个lstm网络分别获取特定方面和上下文的特征,然后交互生成它们的注意力向量,最后将这两个注意力向量连接起来进行方面极性分类。
[0141]
·
tnet-lf[3]使用cnn网络从基于双向lstm网络的单词表示中提取重要特征,并提出一种基于相关性的机制来生成句子中单词的特定目标表示。该模型还采用了位置衰减技术。
[0142]
·
mcrf-sa[4]提出了一个基于多个crf的简洁注意力模型,该模型可以提取特定于方面的意见跨度。该模型还采用了位置衰减和方面连接技术。
[0143]
·
man[5]在多层转换器编码器之上构建了两个具有位置函数的注意力:一个用于
生成上下文和方面之间关系的交互式注意力,以及一个基于转换器编码器的方面到上下文的局部注意力。
[0144]
(2)基于bert的方法
[0145]
·
bert-base[6]是google ai language开发的bertbase版本,采用单句输入方式:“[cls] 评论句 [sep]”进行方面极性分类。
[0146]
·
bert-spc[7]是预训练bert模型在句子对分类(spc)任务中的应用。bert-spc应用于方面极性分类任务的输入方式是:“[cls] 评论句 [sep] 方面目标 [sep]”。
[0147]
·
aen-bert[7]在bert编码器之上构建了两个多头注意力机制:一个多头自注意力机制来建模上下文,一个方面到上下文多头注意力机制来建模方面目标。
[0148]
·
man-bert是man[5]模型的变体。本实例使用bert模型来替换man[5]中的transformer编码器。
[0149]
其中,上述关联的文献分别为:
[0150]
1.tang d,qin b,liu t(2016)aspect level sentiment classification with deep memory network.in:empirical methods in natural language processing,pp 214
–
224
[0151]
2.ma d,li s,zhang x,wang h(2017)interactive attentions networks for aspect-level sentiment classification.in:proceedings of the 26th international joint conference on artificial intelligence,melbourne,australia,19-25august 2017,pp 4068-4074
[0152]
3.li x,bing l,lam w,shi b(2018)transformation networks for target-oriented sentiment classification.in proceedings of acl,pp 946-956
[0153]
4.xu l,bing l,lu w,huang f(2020)aspect sentiment classification with aspect-specific opinion spans.in proceedings of emnlp 2020,pp 3561-3567
[0154]
5.xu q,zhu li,dai t,yan c(2020)aspect-based sentiment classification with multi-attention network.neurocomputing,388(3):135-143
[0155]
6.devlin j,chang mw,lee k,toutanova k(2019)bert:pre-training of deep bidirectional transformers for language understanding.in:proceedings of the 2019conference of naacl,pp 4171
–
4186
[0156]
7.song y,wang j,jiang t,liu z,rao y(2019)attentional encoder network for targeted sentiment classification.in:arxiv preprint arxiv:1902.09314
[0157]
4.实例对比结果
[0158]
本实例通过在数据集上报告准确度accuracy(acc)和宏平均macro-average f1(m-f1)来评估各种模型。
[0159]
表2实验结果,其中带符号“ ”的来自原始论文,带符号“*”的来自文献[5],其他的来自我们的实验,粗体值表示最好的
[0160][0161]
表2的实验结果表明,本发明提出的一种多任务学习的双目标实体情感分析方法,在笔记本和餐厅两个数据集实现了最佳准确度accuracy(acc)和宏平均macro-average f1(m-f1)结果,显著超过了所有同类方法的结果,这充分说明了本发明方法是可行和优秀的。
[0162]
5.示例
[0163]
对于包含双目标实体“prices”和“food”的情感句子"prices are higher to dine but their food is quite good",本实例模型首先识别出语境分断符为“but”,然后得到左子句“prices are higher to dine”的语义表示与右子句“their food is quite good”的语义,最后对左子句语义和右子句语义分别进行情感分析,得到左目标实体“prices”的情感极性为“负面”、右目标实体“food”的情感极性为“正面”。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。