技术特征:
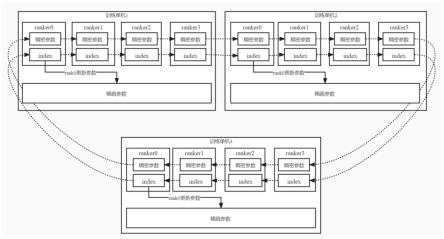
1.一种深度学习模型的训练方法,其特征在于,应用于第一训练器,所述第一训练器部署训练单机上,包括:建立索引;读取训练样本,基于所述索引从所述训练单机本地内存获取稀疏参数,从所述第一训练器本地获取稠密参数;其中,所述训练单机上的第一训练器和各个第二训练器共享所述训练单机本地内存中的稀疏参数;在正向传播过程中根据稠密参数和稀疏参数计算损失值,在反向传播过程中得到稠密参数梯度和稀疏参数梯度;与其他训练器进行稠密参数梯度和稀疏参数梯度的同步,计算出最终的稠密参数梯度和最终的稀疏参数梯度;基于所述最终的稠密参数梯度更新所述第一训练器本地的稠密参数,基于所述最终的稀疏参数梯度更新所述训练单机本地内存的稀疏参数。2.根据权利要求1所述的方法,其特征在于,建立索引包括:调用本地参数服务器框架,对所述稀疏参数进行所述训练单机本地内存映射并根据映射结果建立索引;将所述索引同步至所述训练单机上的其他训练器;其中,主键为所述稀疏参数的标识,键值为所述稀疏参数在所述训练单机本地内存中的存储地址。3.根据权利要求2所述的方法,其特征在于,基于所述索引从所述训练单机本地内存获取稀疏参数,包括:根据分发到所述第一训练器上的训练样本,确定稀疏参数标识;基于所述索引确定所述稀疏参数标识对应的所述稀疏参数在所述训练单机本地内存中的存储地址,从而从所述训练单机本地内存中获取所述稀疏参数。4.根据权利要求1所述的方法,其特征在于,在正向传播过程中根据稠密参数和稀疏参数计算损失值,在反向传播过程中得到稠密参数梯度和稀疏参数梯度,包括:采用所述训练样本并分别利用所述稠密参数和所述稀疏参数训练深度学习模型,从而在正向传播过程中计算得到损失值,在反向传播过程中通过求导得到稠密参数梯度和稀疏参数梯度。5.根据权利要求1所述的方法,其特征在于,与其他训练器进行稠密参数梯度和稀疏参数梯度的同步,计算出最终的稠密参数梯度和最终的稀疏参数梯度,包括:基于环形全局规约算法,与其他训练器进行稠密参数梯度和稀疏参数梯度的同步;对各个训练器上的稠密参数梯度计算平均值,得到最终的稠密参数梯度;同时,根据稀疏参数在各个训练器上的出现频次,计算最终的稀疏参数梯度。6.根据权利要求5所述的方法,其特征在于,根据稀疏参数在各个训练器上的出现频次,计算最终的稀疏参数梯度,包括:对于每个稀疏参数,计算所述稀疏参数在各个训练器上的出现频次;对于每个稀疏参数,对所述各个训练器上的所述稀疏参数梯度求和后,除以所述稀疏参数在所述各个训练器上的出现频次,得到最终的稀疏参数梯度。7.根据权利要求1所述的方法,其特征在于,基于所述最终的稀疏参数梯度更新所述训
练单机本地内存的稀疏参数,包括:通过调用所述本地参数服务器框架,将所述最终的稀疏参数梯度更新到所述训练单机本地内存中。8.一种深度学习模型的训练方法,其特征在于,应用于第二训练器,所述第二训练器部署训练单机上,包括:读取训练样本,从所述训练单机本地内存获取稀疏参数,从所述第二训练器本地获取稠密参数;其中,所述训练单机上的第一训练器和各个第二训练器共享所述训练单机本地内存中的稀疏参数;在正向传播过程中根据稠密参数和稀疏参数计算损失值,在反向传播过程中得到稠密参数梯度和稀疏参数梯度;其中,所述稠密参数存储在所述第二训练器本地,所述稀疏参数存储在所述训练单机本地内存,所述训练单机上的各个第二训练器共享所述训练单机本地内存中的稀疏参数;与其他训练器进行稠密参数梯度和稀疏参数梯度的同步,计算出最终的稠密参数梯度;基于所述最终的稠密参数梯度更新所述第二训练器本地的稠密参数;其中,最终的稀疏参数梯度由所述训练单机上的第一训练器进行计算和更新。9.根据权利要求8所述的方法,其特征在于,从所述训练单机本地内存获取稀疏参数,包括:根据分发到所述第二训练器上的训练样本,确定稀疏参数标识;基于索引确定所述稀疏参数标识对应的所述稀疏参数在所述训练单机本地内存中的存储地址,从而从所述训练单机本地内存中获取所述稀疏参数;其中,在所述索引中,主键为所述稀疏参数的标识,键值为所述稀疏参数在所述训练单机本地内存中的存储地址。10.根据权利要求8所述的方法,其特征在于,在正向传播过程中根据稠密参数和稀疏参数计算损失值,在反向传播过程中得到稠密参数梯度和稀疏参数梯度,包括:采用所述训练样本并分别利用所述稠密参数和所述稀疏参数训练深度学习模型,从而在正向传播过程中计算得到损失值,在反向传播过程中通过求导得到稠密参数梯度和稀疏参数梯度。11.根据权利要求8所述的方法,其特征在于,与其他训练器进行稠密参数梯度和稀疏参数梯度的同步,计算出最终的稠密参数梯度,包括:基于环形全局规约算法,与其他训练器进行稠密参数梯度和稀疏参数梯度的同步;对各个训练器上的稠密参数梯度计算平均值,得到最终的稠密参数梯度。12.一种训练单机,其特征在于,所述训练单机上部署有第一训练器和各个第二训练器,所述训练单机的本地内存中存储有稀疏参数,所述第一训练器的本地和所述第二训练器的本地均存储有稠密参数;其中,所述第一训练器和所述各个第二训练器共享所述训练单机本地内存中的稀疏参数,所述稀疏参数由所述第一训练器更新。13.一种电子设备,其特征在于,包括:一个或多个处理器;
存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,所述一个或多个处理器实现如权利要求1-11中任一所述的方法。14.一种计算机可读介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如权利要求1-11中任一所述的方法。15.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-11中任一项所述的方法。
技术总结
本发明公开了一种深度学习模型的训练方法和训练单机,涉及深度学习技术领域。该方法的一具体实施方式包括:读取训练样本,从训练单机本地内存获取稀疏参数,从第一训练器本地获取稠密参数;训练单机上的第一训练器和各个第二训练器共享训练单机本地内存中的稀疏参数;在正向传播过程中根据稠密参数和稀疏参数计算损失值,在反向传播过程中得到稠密参数梯度和稀疏参数梯度;与其他训练器进行稠密参数梯度和稀疏参数梯度的同步,计算出最终的稠密参数梯度和最终的稀疏参数梯度;基于最终的稠密参数梯度更新第一训练器本地的稠密参数,基于最终的稀疏参数梯度更新训练单机本地内存的稀疏参数。该实施方式能够解决内存不足和参数梯度失效的技术问题。数梯度失效的技术问题。数梯度失效的技术问题。
技术研发人员:邱彩云 包勇军 王文生 张克丰 原武军 贺旭 邢召龙 刘倩欣 刘近光
受保护的技术使用者:北京京东世纪贸易有限公司
技术研发日:2022.05.30
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。