1.本发明涉及图像处理技术领域,具体是一种基于分段策略和多头卷积注意力的视频人脸识别方法。
背景技术:
2.在视频人脸识别领域有所突破,将大大提高视频监控、智能安防、移动支付等技术的效率。视频是具有时间顺序的图像集合,视频在进行人脸识别时有以下不利因素:模糊、遮挡、光线变化,甚至是镜头远近都有影响,这导致视频序列个别帧质量过于低下。目前较为主流的视频人脸识别方案有两种:第一类方案旨在从视频序列中挑选出质量较高、人脸特征较为明显的帧,并用于后续特征提取及识别,但被丢弃的视频帧也有着丰富的位置信息和结构信息;第二类方案则运用视频序列所有的帧进行特征提取,并应用相关手段进行特征融合,然而这类方法针对质量较高且视频序列较短的数据效果较好,当视频序列质量较差且冗长时,这类方案由于噪声的影响,识别效率将大幅降低。
3.当人脸视频较长时,前几帧与后几帧的面部姿态、面部大小等变化较大,往往生成不利于特征提取及融合的噪声。如何高效地提取人脸视频的特征表示并去除冗余噪声对识别任务尤为重要。现有模型通常在特征提取网络上进行相应改进,但很少会对如何输入数据这一过程进行优化,一次性输出过多视频帧往往会加重网络的负担并影响特征提取的质量。而针对过长的视频运用传统的注意力机制,也加大了模型的计算复杂度,降低视频人脸识别的效率。
4.所以,需要一个新的技术方案解决上述问题。
技术实现要素:
5.本发明的目的是针对现有技术不足,而提供一种基于分段策略和多头卷积注意力的视频人脸识别方法。这种方法能高效地提取长视频数据的有用特征及信息、能够去冗余噪声,并提升视频人脸识别的准确率。
6.实现本发明目的的技术方案是:
7.一种基于分段策略和多头卷积注意力的视频人脸识别方法,包括如下步骤:
8.1)对视频人脸数据集进行预处理:采用人脸检测网络逐帧对人脸视频数据集中人脸视频序列进行检测,将人脸视频数据集中人脸视频序列中的图像裁剪成尺寸固定为224
×
224的人脸视频帧图像,得到输入视频帧图像集{tn},n∈n
*
,n
*
为数据集中视频帧数量;
9.2)对步骤1)中得到的视频帧图像集进行分段线性映射、位置嵌入操作:将包含n帧的视频图像集{tn}分为s段,每段视频帧包含n=n/s个图像、将视频帧序列化、将每帧图像tn∈rh×w×c重塑,首先将每帧图像tn分辨率设置为(h
×
w),h=w,接着对tn进行降维,得到图像t
p,n
∈r
(h
×
w)
·c,其中,n表示第n个视频帧,c为通道数,符号
·
表示矩阵点乘,采用可训练的线性映射将扁平化处理后的图像t
p,n
进行映射及位置嵌入操作φ(
·
),得到每帧人脸图像的特征图集合fn=φ(t
p,n
)、记为fn={f0,f1,f2,...,fn}∈r
(h
×
w)
·c×d,其中φ(
·
)表示线性映
射和位置嵌入操作,d为模型使用的恒定隐藏向量的尺寸;
10.3)深度特征提取:采用分段视频人脸编码器,结合多头卷积注意力对步骤2)中具有位置信息的特征图集合fn进行深度特征提取,将特征图集合fn输入至分段视频人脸编码器e,人脸编码器e第一层为多头卷积注意力模块,该模块有两个阶段,分别为e1和e2,e1用卷积神经网络来生成每一帧视频帧的查询向量qn、相关向量kn、值向量vn,即{qn,kn,vn}=e1(fn),然后第二阶段e2计算视频帧每个值向量vn的分数sn,sn由下式计算得出:
[0011][0012]
其中,qn、kn分别为第n帧的查询向量和相关向量,为多头卷积注意力头数,(
·
)
t
为矩阵的转置,然后将视频帧每个值向量vn的分数sn与值向量vn进行元素级相乘,即sn·vn
,并将结果进行归一化后再求和,最终得到第i段视频帧的整体特征表示si=e2(qn,kn,vn),si由下式计算得出:
[0013][0014]
其中,softmax(
·
)为归一化运算,sn为第n帧的分数,本例中,多头卷积注意力模块输出的特征图再利用前馈网络强化该特征表示的表达能力,最后得到的分段视频人脸特征为{s1,s2,s3};
[0015]
4)识别:采用人脸识别网络对步骤3)中得到的视频帧整体特征表示进行识别,即将si输入至现有的人脸识别网络、记为r1,得到预测标签即其中,i表示第i段视频序列;
[0016]
5)损失函数进行训练:利用步骤4)中得到的预测标签和分段损失训练网络为步骤3)中得到的每段视频序列的整体人脸视频特征图赋予权重,网络采用以下损失函数进行训练:
[0017][0018]
其中,yi表示数据标签,是步骤4)中人脸识别网络r1针对每段视频帧的预测标签,wi是一个可随着网络一同训练的分段权重,为了得到分段权重wi,将每段的独立损失定义为则分段权重wi由下式得到:
[0019][0020]
经过分段损失的约束,网络自适应地进行参数调整及优化,得到最优的视频人脸识别模型;
[0021]
6)完成人脸识别:采用步骤5)中训练好的模型完成人脸识别任务,将经过分段的人脸视频帧输入到步骤5)得到的模型中,输出经过分段特征提取及整体融合的人脸视频特征图s=f(s1,s2,...,ss),其中,f(
·
)表示利用分段权重进行的融合操作,s为分段数,再采用现有的人脸识别网络完成最终的视频人脸识别任务。
[0022]
步骤2)中所述的线性映射及位置嵌入操作φ(
·
)公式为:
[0023][0024]
其中,位置嵌入向量d为模型使用的恒定隐藏向量的尺寸,n为视频帧的序号,(h
×
w)是每帧图像的分辨率,c为通道数,符号
·
表示矩阵点乘,t
class
为每个分段序列中各个视频帧的分类标志位。
[0025]
步骤1)中采用的人脸检测网络为mtcnn网络。
[0026]
步骤4)中所述的人脸识别网络r1为vgg-face网络。
[0027]
步骤6)中所述的人脸视频特征图s具体由下式融合:
[0028][0029]
式中,wi为第i段人脸视频帧的分段权重,si为第i段人脸视频帧的特征表示。
[0030]
步骤6)中对人脸视频特征图s进行识别的人脸识别网络为vgg-face网络。
[0031]
本技术方案采用分段策略对视频序列进行映射,并嵌入位置及特征信息,以避免序列跨度较长而引起的面部变化对特征提取的影响,而利用多头卷积注意力设计的分段视频人脸编码器能够有效地提取视频的上下文信息并进行特征融合,且大幅降低了视频人脸识别模型的计算复杂度,定义分段损失函数训练网络,以减小低质量帧对模型识别准确率的影响,加强了模型处理冗长视频序列的能力,这样得到的整体视频人脸特征表示能够较大的提高识别准确率。
[0032]
这种方法采用将长序列人脸视频序列进行分段的策略,结合多头卷积注意力高效地提取长视频数据的有用特征及信息、能够去冗余噪声,从而学习更具鲁棒性的特征,并提升了视频人脸识别的准确率。
附图说明
[0033]
图1为实施例的流程示意图;
[0034]
图2为实施例中分段视频人脸编码器示意图;
[0035]
图3为实施例中多头卷积注意力模块特征提取过程示意图。
具体实施方式
[0036]
下面结合附图和实施例对本发明的内容作进一步地说明,但不是对本发明的限定。
[0037]
实施例:
[0038]
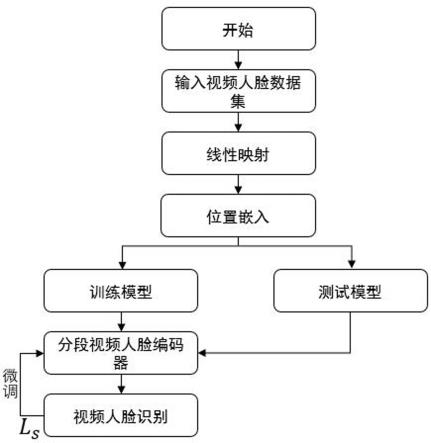
参照图1,一种基于分段策略和多头卷积注意力的视频人脸识别方法,包括如下步骤:
[0039]
1)对视频人脸数据集进行预处理:采用人脸检测网络逐帧对人脸视频数据集中人脸视频序列进行检测,将人脸视频数据集中人脸视频序列中的图像裁剪成尺寸固定为224
×
224的人脸视频帧图像,得到输入视频帧图像集{tn},n∈n
*
,n
*
为数据集中视频帧数量,本例采用多任务卷积神经网络mtcnn(multi-task convolutional neural network,简称mtcnn)逐帧对ijb-a和ytf数据集中人脸视频序列进行检测,在本例中,人脸视频数据集都
是从监控探头或是非配合情况下拍摄得到的,在预处理数据集的阶段,首先采用多任务卷积神经网络来检测每张视频帧中的人脸区域,得到时间连续且尺寸固定的人脸视频帧图像集,每帧大小为224
×
224,将图像集的帧数更改,本例将帧数设置为36帧;
[0040]
2)对步骤1)中得到的视频帧图像集进行分段线性映射、位置嵌入操作:将包含n帧的视频图像集{tn}分为s段,每段视频帧包含n=n/s个图像、将视频帧序列化、将每帧图像tn∈rh×w×c重塑,首先将每帧图像tn分辨率设置为(h
×
w),h=w,接着对tn进行降维,得到图像t
p,n
∈r
(h
×
w)
·c,其中,n表示第n个视频帧,c为通道数,符号
·
表示矩阵点乘,采用可训练的线性映射将扁平化处理后的图像t
p,n
进行映射及位置嵌入操作φ(
·
),得到每帧人脸图像的特征图集合fn=φ(t
p,n
)、记为fn={f0,f1,f2,...,fn}∈r
(h
×
w)
·c×d,其中φ(
·
)表示线性映射和位置嵌入操作,d为模型使用的恒定隐藏向量的尺寸,本例中,输入为36帧视频片段,分为3段,每段视频帧包含12张图像,将视频帧序列化,将每帧图像tn∈rh×w×c重塑,首先将tn分辨率设置为(h
×
w),本例中,h=w=224;
[0041]
3)深度特征提取:采用分段视频人脸编码器,结合多头卷积注意力对步骤2)中具有位置信息的特征图集合fn进行深度特征提取,如图2所示,分段视频人脸编码器主要包括多头卷积注意力模块和前馈网络,即将特征图集合fn输入至分段视频人脸编码器e,人脸编码器e第一层为多头卷积注意力模块,如图3所示,该模块有两个阶段,分别为e1和e2,e1用卷积神经网络来生成每一帧视频帧的查询向量qn、相关向量kn、值向量vn,即{qn,kn,vn}=e1(fn),然后第二阶段e2计算视频帧每个值向量vn的分数sn,sn由下式计算得出:
[0042][0043]
其中,qn、kn分别为第n帧的查询向量和相关向量,为多头卷积注意力头数,(
·
)
t
为矩阵的转置,然后将视频帧每个值向量vn的分数sn与值向量vn进行元素级相乘,即sn·vn
,并将结果进行归一化后再求和,最终得到第i段视频帧的整体特征表示si=e2(qn,kn,vn),si由下式计算得出:
[0044][0045]
其中,softmax(
·
)为归一化运算,sn为第n帧的分数,本例中,多头卷积注意力模块输出的特征图再利用前馈网络强化该特征表示的表达能力,最后得到的分段视频人脸特征为{s1,s2,s3};
[0046]
4)识别:采用人脸识别网络对步骤3)中得到的视频帧整体特征表示进行识别,即将si输入至现有的人脸识别网络、记为r1,得到预测标签即其中,i表示第i段视频序列;
[0047]
5)损失函数进行网络训练:利用步骤4)中得到的预测标签和分段损失训练网络为步骤3)中得到的每段视频序列的整体人脸视频特征图赋予权重,网络采用以下损失函数进行训练:
[0048][0049]
其中,yi表示数据标签,是步骤4)中人脸识别网络r1针对每段视频帧的预测标
签,wi是一个可随着网络一同训练的分段权重,为了得到分段权重wi,将每段的独立损失定义为则分段权重wi由下式得到:
[0050][0051]
经过分段损失的约束,网络自适应地进行参数调整及优化,得到最优的视频人脸识别模型,本例中,分段权重随着网络一同训练,进一步简化了模型并提高了算法性能,避免过于冗长的视频帧对特征提取的负面影响,加快了模型的训练,三个分段视频人脸编码器参数不共享;
[0052]
6)完成人脸识别:采用步骤5)中训练好的模型完成人脸识别任务,将经过分段的人脸视频帧输入到步骤5)得到的模型中,输出经过分段特征提取及整体融合的人脸视频特征图s=f(s1,s2,...,ss),其中,f(
·
)表示利用分段权重进行的融合操作,s为分段数,再采用现有的人脸识别网络完成最终的视频人脸识别任务。
[0053]
步骤2)中所述的线性映射及位置嵌入操作φ(
·
)公式为:
[0054][0055]
其中,位置嵌入向量d为模型使用的恒定隐藏向量的尺寸,n为视频帧的序号,(h
×
w)是每帧图像的分辨率,c为通道数,符号
·
表示矩阵点乘,t
class
为每个分段序列中各个视频帧的分类标志位。
[0056]
步骤1)中采用的人脸检测网络为mtcnn网络。
[0057]
步骤4)中所述的人脸识别网络r1为vgg-face网络。
[0058]
步骤6)中所述的人脸视频特征图s具体由下式融合:
[0059][0060]
式中,wi为第i段人脸视频帧的分段权重,si为第i段人脸视频帧的特征表示。
[0061]
步骤6)中对人脸视频特征图s进行识别的人脸识别网络为vgg-face网络。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
