技术特征:
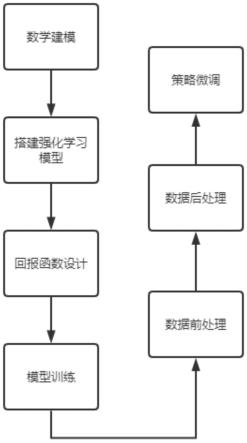
1.一种基于单轴伺服系统的惯量时变振动抑制算法,其特征在于,包括以下步骤:步骤一:数学建模;将机器人单关节电机负载模型抽象为两个刚体、两个旋转副及一个扭簧相连接的力学模型,并分别建立动力学响应方程及变形方程,其动力学响应方程及变形方程分别为:模型,并分别建立动力学响应方程及变形方程,其动力学响应方程及变形方程分别为:模型,并分别建立动力学响应方程及变形方程,其动力学响应方程及变形方程分别为:其中,物理量m表示扭矩,j表示转动惯量,α表示角加速度,b表示旋转阻尼,ω表示角速度,θ表示角度,物理量的下角标分别表示所对应的物体,其中下角标m代表电机,ml代表联轴器,l代表载荷,特别的,k
ml
表示联轴器的等效扭转刚度,表达式为:其中,g
ml
表示联轴器切变模量,j
ml
表示联轴器转动惯量,l
ml
表示联轴器轴长;根据所得动力学响应方程,联立得到积分形式的机器人单关节负载时变系统的动力学表征,其中:联轴器两端的扭转满足如下几何约束:其中,θ
ml
表示联轴器发生扭转变形的角度,α
m
表示电机的角加速度,α
l
表示载荷的角加速度,对系统受力分析可知:对系统受力分析可知:其中,m
m
为电机扭矩,m
ml
表示联轴器扭矩,m
l
表示载荷扭矩,m
in
表示输入扭矩。联立得到机器人单关节负载时变系统的动力学表征;
其中,物理量m表示扭矩,j表示转动惯量,α表示角加速度,b表示旋转阻尼,ω表示角速度,θ表示角度,物理量的下角标分别表示所对应的物体,其中下角标m代表电机,ml代表联轴器,l代表载荷。特别的,m
in
代表输入扭矩,k
ml
表示联轴器的等效扭转刚度。步骤二:搭建强化学习模型;基于强化学习ppo(proximal policy optimization)近端策略优化算法,在网络结构中额外增加lstm(long short-term memory)层,并在练时变惯量的过程,加深网络的层数,并增加了每层网络的节点数,进而得到基于单轴伺服系统的惯量时变振动抑制算法的专用改进型ppo强化学习模型;步骤三:回报函数设计;在距离目标位置超过10度时,远距离惩罚为一个线性函数:far_panalty=(position
–
target)/10;在距离目标位置小于10度时,位置奖励为一个beta函数:pos_reward=beta(0.6,2).pdf[(position
–
target)/10];在距离超出了最大超调范围后,设置有一个超调惩罚,所述超调惩罚随着超调距离的增大而增大,具体为:当超调大于0.0001度时,penalty=0.01
–
100*(position
–
target);当超调大于0.01度时,penalty=0.01 9
–
1000*(position
–
target)。步骤四:对基于ppo算法的改进型强化学习模型进行训练,具体包括:1)数据采集,使用多环境并行的方法增加采样速度;2)重要性采样,将一次采集的样本可以多次更新策略,将原本的on-policy转化为off-policy,具体的实现形式为:那么,梯度表达为如下:3)引入优势函数,定义改进型ppo强化学习模型中每步收益比期望的收益好的部分为
来代替原本的未来期望总回报q,则:a
π(θ)
(s
t
,a
t
)=q
π(θ)
(s
t
,a
t
)-v
π(θ)
(s
t
);其中,q函数为原本的未来期望总回报,v函数为ac网络结构中critic网络对于当前状态价值的估计,将本式带入可得梯度和目标函数为:态价值的估计,将本式带入可得梯度和目标函数为:4)信任域限制;首先,使用了一个估计来代替kl距离的计算:其次,为目标函数引入kl距离作为正则项;5)ppo算法训练过程改进;步骤五:数据前处理;1)使用序列输入,在训练神经网络的过程中,在环境中增加了获取两次决策之间状态的处理,并将过去时刻的状态都进行存储并将这些状态同时输入到强化学习网络中,以加快训练速度;2)对输入进行修正在序列输入的基础上,我们又对输入的状态值进行了修正,主要包括位置修正,速度修正和电流修正。步骤六:数据后处理;1)消除电机速度反向,限制输出电流的增加速度,避免前期电流输出增加过快导致的电机速度反向问题,也不会损失网络本身的良好控制效果;2)加入pid降低末端振荡,在强化学习将机械臂控制到目标位置附近后转换为pid控制,系统会在较短的时间内停止,到达目标位置后电机可以逐渐停止在目标位置处。2.根据权利要求1所述的一种基于单轴伺服系统的惯量时变振动抑制算法,其特征在于,还包括步骤七:策略微调;先使用一个通用的回报函数,训练得到一个整体效果较好的策略,在这个策略的基础上,用一个对超调更敏感的回报函数替代原有的回报函数,增加策略对于超调的抑制,从而得到一个更加稳定的策略网络。3.根据权利要求2所述的一种基于单轴伺服系统的惯量时变振动抑制算法,其特征在于,所述步骤一数学建模中,还包括:1)时变惯量设计,为了更好的模拟复杂机械臂的转动惯量模型,设计了一种可以模拟大多数时变惯量的系统,基于标准二次函数y=ax2 bx c设计,在指定时间段内的函数值随时间t的变化作为时变的惯量值ji,当二阶项系数a=0时,函数变为一阶函数,当二阶项和一阶项系数a=b=0时,函数变为常数函数,即为普通非时变系统定惯量的模型,预先给定惯量的初始范围(jl1,jl2)和最终可到达范围(jl3,jl4),并给出惯量最大可变范围jlc,不
妨取jl1=jl3,jl2=jl4,jlc=jl2-jl1;如果惯量的变化为单调变化,那么可以有额外的条件a*b>0使得在(0,t)时间内函数为单调递增或递减函数;2)泛用性参数泛化,在惯量时变的模型基础上,加入了阻尼泛化,刚度泛化和位置泛化;3)随机初始化状态,对初始状态进行随机初始化从而让系统采集到更多样化的运动轨迹。4.根据权利要求1所述的一种基于单轴伺服系统的惯量时变振动抑制算法,其特征在于,所述步骤四中,ppo算法训练过程改进包括:1)控制频率,使用较低的控制频率,进行算法的快速训和迭代,针对快速控制的时间要求,选择50hz的控制频率,将回报函数及网络参数快速确定到一个较小的范围,在精度无法提升后,将控制频率增加到500hz,进一步提升控制速度和精度;2)控制时间,将控制时间降为原先的3/5;3)设置学习率,将固定的学习率改为随时间指数下降,并且设定一个最小值的学习率函数。
技术总结
本发明公开了一种基于单轴伺服系统的惯量时变振动抑制算法,包括:数学建模、搭建强化学习模型、回报函数设计、对基于改进型PPO强化学习模型的模型进行训练、数据前处理、数据后处理和策略微调等步骤,解决了传统时变振动抑制算法在环境随机量较多的时候,会出现振荡时间过长或到达目标位置时间过慢等缺陷。间过长或到达目标位置时间过慢等缺陷。间过长或到达目标位置时间过慢等缺陷。
技术研发人员:杨庆研 郑军
受保护的技术使用者:聚时科技(上海)有限公司
技术研发日:2022.05.28
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。