一种基于dmstfa的多分类器设备故障诊断方法
技术领域
1.本发明涉及一种设备故障诊断方法,尤其是涉及一种基于dmstfa的多分类器设备故障诊断的方法。
背景技术:
2.故障诊断在研究监测数据与机器健康状态之间的关系中起着重要作用,准确的故障诊断一直是工程师和科学家的研究前沿。传统的基于模型的方法仅依赖故障频率下不同信号的阈值来确定故障的存在,这些模型只能描述一些具有明确信号特征的故障类型,而在现实中,故障往往更为复杂。例如,在故障的早期阶段,特征可能不太明确;同时可能发生多个故障,这可能会修改故障特征,并由于耦合效应创建新特征。因此,数据本身可能存在许多独特的特征或模式,而人类几乎不可能通过手动观察或解释来识别这些复杂的特征。基于机器学习的算法,包括人工神经网络(ann)、主成分分析(pca)、支持向量机(svm)等可以更全面地解析数据,并应用所学知识做出有关故障存在的智能决策。为了在多种操作条件和嘈杂环境下获得更好的性能,基于深度学习的方法越来越受欢迎,例如自动编码器(ae)、深层信念网络(dbn)、卷积神经网络(cnn)等,深度学习有助于从收集的数据中自动学习故障特征,大量实验证明,基于深度学习的方法比基于机器学习的方法具有更高的泛化性能。但基于机器学习和深度学习的设备故障诊断方法都基于一个必要的假设:来自实验室(源域)的训练数据集样本应该与来自工程场景(目标域)的测试数据集样本具有相同的分布。但是不同场景下的机器设备通常在不同的工况下运行,例如负载、速度和温度,这意味着在不同的工作条件下,数据的分布可能会显著不同,那么基于训练数据集的学习模型在实际应用中部署到测试数据集时,泛化能力较弱,进一步影响模型在测试集上的决策。
3.这个问题可以通过诊断知识在不同场景或者不同条件下重用的想法来解决,例如,实验室设备数据集的诊断知识可能有助于识别工程场景中设备的健康状态,这恰恰是迁移学习的域适应问题可以实现的。作为迁移学习的一个子领域,无监督领域自适应可以通过学习两个领域的共享特征来缓解标记训练样本和未标记测试样本的不一致分布,它的核心想法是,既然源域和目标域数据不同,那么把数据都映射到一个特征空间,在特征空间找一个度量准则使源域数据和目标域数据特征分布接近,那么基于源域特征训练的分类器就可以用在目标域上。对于故障诊断,由于在不同的应用场景或不同的工作条件下故障特征具有固有的相似性,这两个领域中存在的共享特征允许迁移学习具有一定的可行性,具有一定的实际意义。
4.综上所述,寻找一种有效的基于域适应的设备故障诊断方法,以增强源域的训练模型在目标域上的泛化能力,尤其是当二者具有较大的分布差异时,成为了目前亟需解决的问题。
技术实现要素:
5.为解决上述技术问题,本发明提出一种基于dmstfa的多分类器设备故障诊断方
法,显著提高了设备故障诊断模型在目标域上的诊断准确率,即使当工作条件具有较大差异时,也可以实现对设备故障的智能诊断。
6.本发明的技术方案包括如下步骤:
7.步骤一:按不同工况将数据分为源域与目标域数据;
8.步骤二:构建设备故障诊断神经网络模型,初始化其参数;
9.所述的设备故障诊断神经网络由三个部分组成:特征提取器,三个分类器和一个域判别器;具体地,特征提取器包含一个由多层卷积构成的主干网络,三个由单层卷积和池化层构成的特征子空间网络;三个分类器结构相同,每个分类器由一个全连接隐藏层和一个softmax层组成;域判别器由一个全连接隐藏层和带有逻辑回归的二分类器组成;主干网络用于提取设备数据的低维信号特征,特征子空间网络用于将低维特征映射到不同的空间并从多个角度提取高维特征,卷积层后均有批归一化和relu层;池化层均选用平均值池化策略,进行特征降采样,置于每个特征子空间的卷积层后,并与全连接隐藏层相连接,最后通过softmax层输出每个类别上的概率值;
10.步骤三:将源域和目标域数据输入神经网络中,根据dmstfa计算各个特征子空间的域适配损失;
11.所述的dmstfa全称为dynamic multiple sub-structure transferable features alignment,即动态多子空间可转移特征对齐,该方法设计了一个域适配损失用以提取多个子空间上的可转移特征;l
transfer
表示子空间上源域和目标域可转移特征的对齐损失,总的可转移特征对齐损失由源域与目标域在各个子空间上的域间特征差异损失和类别区分度损失组成,这一部分称为域适配部分,l
transfer
计算方法如下:
[0012][0013]
其中n表示特征子空间个数,j表示第j个子空间,表示第j个子空间上源域和目标域的可转移特征对齐损失,其中可转移特征分为两部分,一是源域和目标域的域不变特征,二是源域和目标域的类别区分度特征,因此可转移特征对齐损失相应的由两部分组成,一是域间特征差异损失,该损失用于衡量源域和目标域的域间特征差异,从而指导特征提取器提取源域和目标域的域不变特征,显示地对齐源域和目标域的可转移特征;二是类别区分度损失,该损失用于衡量两个域的特征在某个类别上是否具有区分度,换句话说,该损失用于衡量提取到的特征是否有助于分类器做出准确的预测,从而指导特征提取器提取两个域的类别区分度特征,特别地,由于源域和目标域的类别一致,因此提取二者的类别区分度特征有助于隐式地对齐源域和目标域的可转移特征。式子如下:
[0014][0015]
式中,表示第j个子空间上源域和目标域的域间特征差异损失,表示第j个子空间上源域和目标域的类别区分度损失,μ表示对齐自适应因子,动态调整特征对齐过程中对齐域不变特征和类别区分度特征的重要性;下面对式中的三个重要组成部分作进一步说明。
[0016]
具体计算如下:
[0017][0018]
式中g(
·
)表示卷积神经网络,用于提取原始输入数据的低维特征,h(
·
)将低维特征映射到不同的特征子空间,dj表示第j个子空间上源域和目标域的mk-mmd距离;以往基于特征差异损失的方法往往将源域和目标域映射到一个低维特征空间上进行特征对齐,这种单一的特征提取方式可能会错过一些重要信息,本发明提出的dmstfa方法可以在多个特征子空间上对齐源域和目标域的分布,通过最小化多个特征子空间的分布差异来学习多个域不变特征。
[0019]
具体计算如下:
[0020][0021]
式中表示分类器对源域或者目标域数据预测输出的概率,c
s,t
表示两个域的类别数量,c表示某个预测输出类别。
[0022]
μ=1-2|d(h(g(x
s,t
))-0.5|(5)
[0023]
式中,d(
·
)表示域判别器对源域或者目标域子空间高维特征的所属领域判别结果,判别输入数据属于源域还是目标域,在网络中判别器的最后一层采用sigmoid激活函数使得判别结果属于[0,1]之间的一个浮点数,当判别结果接近1认为输入数据属于源域,当判别结果接近0认为输入数据属于目标域,当判别结果接近0.5认为输入特征代表源域和目标域的域不变特征,因为此时域判别器已分不清输入数据属于源域还是目标域,因此μ∈[0,1],当μ
→
0,表示没有提取到域不变特征,此时更应该关注域间特征差异损失,当μ
→
1,表示已经提取到域不变特征,此时更应该关注类别区分度损失。因此,对齐自适应因子μ根据实际提取到的特征情况,动态地调节两个损失的重要性,指导特征提取器提取更多可转移特征,并取得良好的特征对齐效果。
[0024]
步骤四:计算每个子空间的特征相似性权重;
[0025]
步骤五:根据相似性权重,组合多个分类器的输出,并计算分类损失;
[0026]
步骤六:将各个特征空间上的域适配损失和分类损失相加,得到总损失函数值,然后进行迭代训练更新模型参数,得到最终模型;
[0027]
步骤七:设备故障诊断时将目标域数据输入最终模型,得到设备故障诊断结果。
[0028]
作为优选,所述步骤一具体为:根据设备运转速度将传感器采集数据分成有标签的源域数据和无标签的目标域数据其中s表示源域,t表示目标域,i表示源域或目标域的第i个样本,
ns
表示源域样本数,n
t
表示目标域样本数;源域和目标域数据工况条件均不相同,即源域和目标域数据具有不同的分布。
[0029]
作为优选,为了利用源域和目标域域间特征差异的信息,域适配部分提供一个反映多个特征子空间上源域和目标域的相似性权重,以重新加权多个分类器。所述的相似性权重计算如下:
[0030][0031]
式中,wj表示第j个子空间上源域和目标域的相似性权重,表示第j个子空间上源域和目标域的域间特征差异损失,n表示子空间个数,如果某个子空间上的两个域彼此相似,则反映在更低的域间特征差异损失和更高的权重wj。
[0032]
作为优选,所述的步骤二中的设备故障诊断神经网络参数初始化采用正态分布随机初始化方法,通过adam算法更新其参数。
[0033]
作为优选,所述组合多分类器的输出,具体为:多分类器策略在每个特征子空间上分别建立源分类器,利用域适配部分的权重来评估每个空间上源和目标之间的相似性,对各个分类器进行加权以学习目标故障分类器,分类器第c类的输出如下:
[0034][0035]
式中vi是将输入连接到第i个输出神经元的第i个权重,cs表示源域类别数量,wj表示第j个子空间上源域和目标域的相似性权重。
[0036]
作为优选,所述的第j个子空间上源域和目标域的mk-mmd距离dj计算如下:
[0037][0038]
作为优选,所述步骤五中,分类损失计算如下:
[0039][0040]
式中s表示源域,i表示源域的第i个样本,ns表示源域样本数,j采用交叉熵损失函数,表示源域的第i个样本的数据,表示源域的第i个样本的数据标签,表示组合分类器对第i个样本的预测输出。
[0041]
作为优选,所述的将各个特征空间上的域适配损失和分类损失相加,得到总损失函数值,具体为:
[0042][0043]
式中s表示源域,i表示源域的第i个样本,ns表示源域样本数,j采用交叉熵损失函数,表示源域的第i个样本的数据,表示源域的第i个样本的数据标签,表示组合分类器对第i个样本的预测输出。
[0044]
本发明的有益效果是:本发明提出了针对差异较大的工况条件下dmstfa的多分类器方法,将可转移特征分为域不变特征和类别区分度特征,利用设计的域适配损失衡量多个特征空间上源域与目标域的域间特征分布偏差和多个分类器上源域和目标域的类间特征分布偏差,通过对齐自适应因子动态指导特征提取网络对提取域不变特征和类别区分度特征进行重要性分配,使源域和目标域特征具有更好的对齐效果;从多角度对源域和目标
域的相似性进行评估,利用设计的相似性权重对多分类器结果重新加权以学习更准确的目标故障分类器,充分利用各个特征子空间上学习到的信息并重点关注了最大相似性所对应空间提取到的特征的重要性;统计多个特征子空间上的域适配损失,并根据相似性权重组合各个子空间对应的分类器的输出计算分类损失,二者相加得到总损失函数值,通过反向传播迭代更新优化模型参数。基于深度学习模型强大的学习能力学习源域和目标域的特征表示,进一步的,dmstfa的多分类器方法从多个角度衡量源域和目标域的可转移特征分布偏差,并组合多分类器的结果,增强了模型在具有较大分布差异的目标域上的泛化能力,显著提高了设备故障诊断模型诊断准确率,解决了单一空间上域适应算法对具有较大差异的目标域泛化能力不强的问题,从而实现对设备故障的智能诊断。
附图说明
[0045]
图1为本发明方法的流程图;
[0046]
图2为本发明的神经网络整体结构图;
[0047]
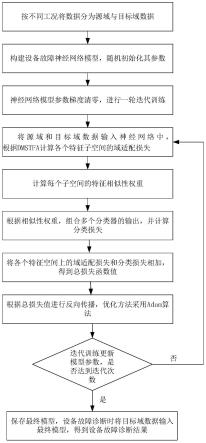
图3为本发明dmstfa多分类器算法总体流程图;
具体实施方式
[0048]
下面结合附图对本发明作进一步详细说明。
[0049]
如图1所示,本发明包含以下步骤。
[0050]
1)按不同工况将数据分为源域与目标域数据;
[0051]
2)构建设备故障诊断神经网络模型,随机初始化其参数;
[0052]
3)神经网络模型参数梯度清零,进行一轮迭代训练;
[0053]
4)将源域和目标域数据输入神经网络中,根据dmstfa计算各个特征子空间的域适配损失;
[0054]
5)计算每个子空间的特征相似性权重;
[0055]
6)根据相似性权重,组合多个分类器的输出,并计算分类损失;
[0056]
7)将各个特征空间上的域适配损失和分类损失相加,得到总损失函数值;
[0057]
8)根据总损失值进行反向传播,优化方法采用adam算法;
[0058]
9)迭代训练更新模型参数,判断是否达到迭代次数,保存最终模型;
[0059]
10)设备故障诊断时将目标域数据输入最终模型,得到设备故障诊断结果。
[0060]
所述步骤1)根据设备转速将传感器采集数据分成有标签的源域数据和无标签的目标域数据其中s表示源域,t表示目标域,i表示源域或目标域的第i个样本,ns表示源域样本数,n
t
表示目标域样本数;源域和目标域数据工况条件均不相同,即源域和目标域数据具有不同的分布。
[0061]
所述步骤2)中的设备故障诊断模型整体结构示意图如图2所示,具体构建步骤如下:
[0062]
设备故障诊断神经网络由三个部分组成:特征提取器,三个分类器和一个域判别器。具体地,特征提取器包含一个由多层卷积构成的主干网络,三个由单层卷积和池化层构成的特征子空间网络;三个分类器结构相同,每个分类器由一个全连接隐藏层和一个softmax层组成;域判别器由一个全连接隐藏层和带有逻辑回归的二分类器组成。主干网络
用于提取设备数据的低维信号特征,特征子空间网络用于将低维特征映射到不同的空间并从多个角度提取高维特征,卷积层后均有批归一化和relu层;池化层均选用平均值池化策略,进行特征降采样,置于每个特征子空间的卷积层后,并与全连接隐藏层相连接,最后通过softmax层输出每个类别上的概率值。设备故障诊断神经网络参数初始化采用正态分布随机初始化方法,通过adam算法更新其参数。
[0063]
所述步骤4)中各个特征子空间的域适配损失由两部分组成,域间特征差异损失和类别区分度损失,二者由一个对齐自适应因子来动态地调节两部分损失的重要性。域间特征差异损失是在三个池化层后计算,主干网络提取到源域和目标域数据的低维特征后输入到三个子空间进一步提取多个角度上的高维特征表示,域间特征差异损失越小说明该空间上源域和目标域具有较高的域间相似特征;类别区分度损失是在三个softmax层后计算,softmax层输出每个类别上的预测概率值,类别区分度损失越小说明该空间上提取的特征具有较高的类别区分度;对齐自适应因子是在域判别器输出之后计算的,以0.5作为临界值衡量提取到的特征是否已经具有最优域不变特征,从而指导特征提取网络对提取域不变特征和类别区分度特征进行重要性分配。一方面,网络优化域适配损失使源域和目标域在多个子空间进行特征对齐;另一方面,域适配损失为之后的多分类器提供了两个域的相似性权重。特征差异损失采用mmd(maximum mean discrepancy,最大均值差异)距离衡量,mmd可以权重在再生希尔伯特空间(rkhs,reproducing kernel hilbert space)中两个分布的距离,mmd距离计算公式如下:
[0064][0065]
其中hk使用内核k表示rkhs,通常使用高斯内核作为内核,φ(*)表示到rkhs的映射,tr表示矩阵的迹,m为系数矩阵,m计算如下:
[0066][0067]
mmd的思想是基于源域和目标域的样本,通过寻找在样本空间上的映射函数φ,然
后求不同分布的样本在φ上的函数值的均值,把两个均值作差可以得到源域和目标域数据分布对应于φ上的均值距离。mmd作为检验统计量,可以判断两个分布是否相同。如果mmd距离足够小,可以认为两个分布相同,否则就认为它们有较大偏差。但是,对于实际应用,每个内核的参数选择对于特征映射的最终性能至关重要。为了更好地选择高斯内核参数,采用mk-mmd(multi-kernel maximum mean discrepancy,多核最大均值差异)代替mmd,mk-mmd是使用m个核的凸组合提供映射的有效估计,内核选取计算方法如下:
[0068][0069]
式中u表示第u个内核,βu表示第u个内核加权参数,d表示内核个数。利用mk-mmd可以计算源域与单目标域之间的特征映射均值距离值,以此距离作为单一空间上目标域损失函数值,计算方法如下:
[0070][0071]
通过mk-mmd迭代优化模型,使得模型具有源域和目标域的域不变性表示能力。
[0072]
所述步骤4)中的dmstfa全称为dynamic multiple sub-structure transferable features alignment,即动态多子空间可转移特征对齐,该方法设计了一个域适配损失用以提取多个子空间上的可转移特征;另外,根据各个子空间的特征差异损失设计了一个权重来表示源域和目标域的相似性,以自适应地组合多个分类器的输出;设备
[0073]
故障诊断神经网络总损失函数值计算如下:l=lc λl
transfer
(5)
[0074]
其中lc表示源多分类器组合输出的分类损失,l
transfer
表示子空间上对齐源域和目标域可转移特征的损失,λ表示权衡两部分的权重参数,总的可转移特征对齐损失由源域与目标域在各个子空间上的可转移特征对齐损失组成,l
transfer
计算方法如下:
[0075][0076]
其中n表示特征子空间个数,j表示第j个子空间,l
jtransfer
表示第j个子空间上源域和目标域的可转移特征对齐损失,本方法认为可转移特征分为两部分,一是源域和目标域的域不变特征,二是两个域的类别区分度特征,因此可转移特征对齐损失相应的由两部分组成,一是域间特征差异损失,该损失用于衡量源域和目标域的特征差异,从而指导特征提取器提取源域和目标域的域不变特征,二是类别区分度损失,该损失用于衡量两个域的特征在某个类别上是否具有区分度,从而指导特征提取器提取两个域的类别区分度特征。式子如下:
[0077][0078]
式中,l
jmmd
表示第j个子空间上源域和目标域的特征差异损失,l
jdis
表示第j个子空间上源域和目标域的类别区分度损失,μ表示对齐自适应因子,动态调整特征对齐过程中对齐域不变特征和类别区分度特征的重要性。下面对式中的三个重要组成部分作进一步说明。
[0079]
i.l
jmmd
具体计算如下:
[0080][0081]
式中g(
·
)表示卷积神经网络,用于提取原始输入数据的低维特征,h(
·
)将低维
特征映射到不同的特征子空间,dj表示第j个子空间上源域和目标域的mk-mmd距离;以往基于特征差异损失的方法往往将源域和目标域映射到一个低维特征空间上进行特征对齐,这种单一的特征提取方式可能会错过一些重要信息,本发明提出的dmstfa方法可以在多个特征子空间上对齐源域和目标域的分布,通过最小化多个特征子空间的分布差异来学习多个域不变特征。
[0082]
ii.l
jdis
具体计算如下:
[0083]
式中表示分类器对源域或者目标域数据预测输出的概率,由网络中的softmax层提供,c
s,t
表示两个域的类别数量,c表示某个预测输出类别。
[0084]
iii.μ=1-2|d(h(g(x
s,t
))-0.5|(10)
[0085]
式中,d(
·
)表示域判别器对源域或者目标域子空间高维特征的判别结果,判别输入属于源域还是目标域,在网络中判别器的最后一层采用sigmoid激活函数使得判别结果属于[0,1]之间的一个浮点数,当判别结果接近1认为输入数据属于源域,当判别结果接近0认为输入数据属于目标域,当判别结果接近0.5认为输入特征可以代表源域和目标域的域不变特征,因此μ∈[0,1],当μ
→
0,表示已经没有提取到域不变特征,此时更应该关注域不变特征损失,当μ
→
1,表示已经提取到域不变特征,此时更应该关注类别区分度损失。自适应因子μ可以根据实际提取到的特征情况,动态地调节两个损失的重要性,并取得良好的特征对齐效果。
[0086]
进一步,为了利用源域和目标域特征差异的信息,自适应部分还可以反馈一个反映多个特征子空间上源域和目标域的相似性权重,以重新加权学习分类器。相似性权重计算如下:
[0087][0088]
式中,wj表示第j个子空间上源域和目标域的相似性权重,l
jmmd
表示第j个子空间上源域和目标域的特征差异损失,n表示子空间个数,如果某个子空间上的两个域彼此相似,则反映在更低的特征差异损失l
jmmd
和更高的权重wj。
[0089]
进一步,多分类器策略在每个特征子空间上分别建立源分类器,利用自适应部分的权重来评估每个空间上源和目标之间的相似性,对各个分类器进行加权以学习目标故障分类器,分类器第c类的输出如下:
[0090][0091]
式中vi是将输入连接到第i个输出神经元的第i个权重,cs表示源域类别数量。总的来说,本方法在多个特征空间上进行衡量,重点提高特征差异最小的空间学习能力,同时多源故障分类器由改进的自适应部分提供的相似性分数进行重新加权,以获得更准确地分类结果。总损失函数值计算如下:
[0092][0093]
为更具体直观地说明dmstfa多分类器策略,总体计算流程如图3所示,计算步骤如下:
[0094]
step1:计算各特征子空间上源域和目标域的特征差异损失l
mmd
;
[0095]
step2:计算各特征子空间上分类器对源域和目标域的类别区分度损失l
dis
;
[0096]
step3:计算域判别器对各特征子空间上源域特征和目标域特征的对齐自适应因子μ;
[0097]
step4:计算源域和目标域的相似性权重w,该权重评估了各个特征空间上两个域的相似性,从而充分利用各个子空间上的信息学习分类器;
[0098]
step5:根据相似性权重对各个分类器的输出重新加权得到组合分类器的输出,并计算源域的分类损失lc;
[0099]
step6:根据对齐自适应因子,将各个特征子空间的域间特征差异损失和类别区分度损失相加得到总的域适配损失,最后加上分类损失函数值得到神经网络总损失函数值;
[0100]
step7:根据总损失函数值迭代优化设备故障诊断模型参数,最后得到最终模型。
[0101]
本发明的步骤4)提出了针对差异较大的工况条件下dmstfa的多分类器方法,将可转移特征分为域不变特征和类别区分度特征,利用设计的域适配损失衡量多个特征空间上源域与目标域的域间特征分布偏差和多个分类器上源域和目标域的类间特征分布偏差,通过对齐自适应因子动态指导特征提取网络对提取域不变特征和类别区分度特征进行重要性分配,使源域和目标域特征具有更好的对齐效果;从多角度对源域和目标域的相似性进行评估,利用设计的相似性权重对多分类器结果重新加权以学习更准确的目标故障分类器,充分利用各个特征子空间上学习到的信息并重点关注了最大相似性所对应空间提取到的特征的重要性;统计多个特征子空间上的域适配损失,并根据相似性权重组合各个子空间对应的分类器的输出计算分类损失,二者相加得到总损失函数值,通过反向传播迭代更新优化模型参数。基于深度学习模型强大的学习能力学习源域和目标域的特征表示,进一步的,dmstfa的多分类器方法从多个角度衡量源域和目标域的可转移特征分布偏差,并组合多分类器的结果,增强了模型在具有较大分布差异的目标域上的泛化能力,显著提高了设备故障诊断模型诊断准确率,解决了单一空间上域适应算法对具有较大差异的目标域泛化能力不强的问题,从而实现对设备故障的智能诊断。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。