1.本发明涉及电力负荷预测技术领域,尤其是涉及一种区域电力负荷的短期预测方法。
背景技术:
2.区域电力负荷具有不确定性强、时间相关性大的特点,其短期预测是配电网系统规划与调度的基础性工作,已成为能源研究的热点之一。目前常用的数据分析预测方法主要可以分为类推法、函数法、定性预测法、时间序列预测法、因果关系预测法等。
3.区域电力负荷适用于基于时间序列的数据分析预测方法,是一种回归预测方法,属于定量预测,承认事物发展的延续性,运用过去的时间序列数据进行统计分析,推测出事物的发展趋势;但其存在分析数据需要人为经验指定,预测精度低的问题,且负荷预测方法的选取对预测结果影响大,具有对异常值敏感的缺点,普适性较差,不适用于管理等工作。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种区域电力负荷的短期预测方法。
5.本发明的目的可以通过以下技术方案来实现:
6.一种区域电力负荷的短期预测方法,该方法包括如下步骤:
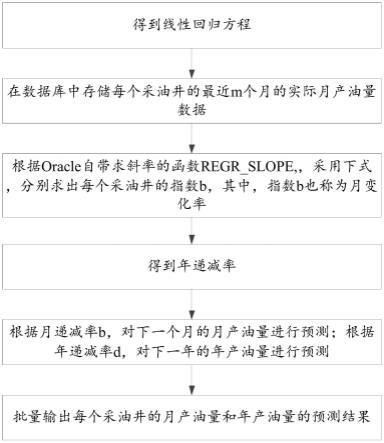
7.步骤1:采集区域电力负荷数据(训练数据与试验数据来源),采用统计函数模型对相关影响因素与负荷数据之间的相关性进行初步分析。具体步骤包括:
8.步骤1.1:选取某区域除节假日外的数据n天的逐小时负荷数据以及干球温度、露点温度、湿度等气象数据;
9.步骤1.2:采用correl统计函数模型分析相关影响因素与负荷数据之间的相关性;correl统计函数模型的表达式为:
[0010][0011]
式中:correl(x,y)为相关系数;x、y为各变量的数值;为变量平均值。相关系数correl(x,y)的不同值表示不同的特征标准,当相关系数correl(x,y)的值为0~0.3时,特征标准为微相关;当相关系数correl(x,y)的值为0.3~0.5时,特征标准为实相关;当相关系数correl(x,y)的值为0.5~0.8时,特征标准为显著相关;当相关系数correl(x,y)的值为0.8~1.0时,特征标准为高度相关。
[0012]
步骤1.3:根据步骤1.2中的分析结果分析各变量与实际负荷数据的相关性;
[0013]
步骤1.4:重复步骤1.2和1.3,直至所有相关影响因素完成相关性分析;
[0014]
相关影响因素包括干球温度,露点,相对湿度,风速等级,前24小时的平均负荷、前一天的同一时刻负荷,前一周的同一时刻负荷等。
[0015]
步骤1.5:从数据集(所有经过分析后的相关影响因素组成的数据集)中按相关性特性标准取出数据xi,对数据xi进行归一化处理,给予xi数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1;归一化处理采用如下公式进行:
[0016][0017]
式中:z为归一化之后的变量,μ和σ分别为变量xi的样本均值与样本标准差。
[0018]
步骤2:对步骤1得到的归一化后的数据集训练bp神经网络算法模型。具体地:
[0019]
步骤2.1:选定bp神经网络的隐含层神经元个数n,设置隐含层神经元以及输出层神经元的激励函数分别为tansig函数和purelin函数,随机初始化网络权值和阈值,取迭代次数为5000次。
[0020]
步骤2.2:采用trainglm学习函数,levenberg-marquardt算法在训练样本上重复训练10次,并计算10次训练结果的平均绝对误差百分比mape平均值;网络历元迭代次数为5000次,预期误差目标为0.00000001次。
[0021]
步骤2.3:若平均绝对误差百分比mape为最小值,则结束;否则跳到步骤2.1继续重新选择隐含层数n;
[0022]
步骤2.4:对隐含层神经元个数为n的神经网络,随机初始化网络权值和阈值,取迭代次数为30000次。采用trainglm学习函数,重复训练。
[0023]
步骤3:对步骤2得到的bp神经网络模型进行精度检验、选取与训练,利用预测模型预测区域电力负荷。具体步骤包括:
[0024]
步骤3.1:设置迭代次数为100000次,对选定隐含层层数为n,隐含层神经元个数为k,隐含层神经元以及输出层神经元的激励函数分别为tansig函数和purelin函数的神经网络进行深度训练。
[0025]
步骤3.2:对mape值进行比较,选取激励函数模型,迭代训练。
[0026]
步骤3.3:达到目标误差,则迭代训练结束。
[0027]
步骤3.4:为了检验模型的泛化能力,运用已建立的预测模型对区域电力负荷检验样本进行预测。
[0028]
本发明提供的区域电力负荷的短期预测方法,相较于现有技术至少包括如下有益效果:
[0029]
1)本发明通过已建立的预测模型对检验样本进行预测,该方法在实验数据中表现出强大的非线性拟合能力,预测精度更高,平均绝对误差百分比(mape)较低,适合工程实用;
[0030]
2)本发明算法通过对比了不同隐含层层数、神经元个数、激励函数条件下的预测结果,摆脱了单一隐含层函数对预测数据的局限性,并对拟合后的预测数据进行检验,预测精度更高,数据更直观,普适性更高,适用于管理工作;
[0031]
3)本发明可以作为电厂电力负荷预测数据的基础技术,可辅助用于电厂现货市场交易、燃料调度、出力分析、数据挖掘等领域工作。
附图说明
[0032]
图1为实施例中本发明区域电力负荷的短期预测方法的流程示意图;
[0033]
图2为实施例中本发明区域电力负荷的短期预测方法的原理示意图;
[0034]
图3为实施例中bp神经网络算法的流程图;
[0035]
图4为实施例中purelin-purelin激励函数模型mape曲线;
[0036]
图5为实施例中purelin-tansig激励函数模型mape曲线;
[0037]
图6为实施例中tansig-tansig激励函数模型mape曲线;
[0038]
图7为实施例中tansig-purelin激励函数模型mape曲线;
[0039]
图8为实施例中单隐含层误差与平均绝对误差分布图;
[0040]
图9为实施例中按小时划分的预测错误统计信息曲线;
[0041]
图10为实施例中按星期的划分预测错误统计信息曲线;
[0042]
图11为实施例中单隐含层检验预测负荷与实际负荷;
[0043]
图12为实施例中单隐含层平均绝对误差百分比mape。
具体实施方式
[0044]
下面结合附图和具体实施例对本发明进行详细说明。显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0045]
实施例
[0046]
目前对负荷的季节性趋势与区域的温度、湿度和风速等外生变量数据进行统计分析,证明它们之间具有良好的相关性;考虑温度相似度和日期接近度,依托某区域电力负荷数据的数据将其划分为各个较小的区域;多用曲线法、指标法和对比法,分析年、月、周、日和各行业的负荷特性,用来研究特殊负荷与日负荷特性的相关性分析方法。
[0047]
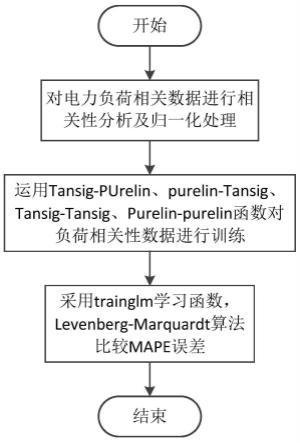
本发明涉及一种区域电力负荷的短期预测方法,该方法为基于tansig-purelin、purelin-tansig、tansig-tansig、purelin-purelin激励函数bp神经网络的区域电力负荷预测方法,输出负荷由mape值的精度确定。具体地,如图1、2所示,方法包括如下步骤:
[0048]
步骤一、采集区域电力负荷数据,采用统计函数模型对相关影响因素与负荷数据之间的相关性进行初步分析;具体地:
[0049]
1.1、本实施例选取某区域三年除节假日54天外的数据1771天的逐小时负荷数据以及干球温度、露点温度、湿度等气象数据。
[0050]
1.2、用correl统计函数模型分析相关影响因素与负荷数据之间的相关性;
[0051]
correl统计函数模型的表达式为:
[0052][0053]
式中:correl(x,y)为相关系数;x、y为各变量的数值;为变量平均值。相关系数correl(x,y)的不同值表示不同的特征标准,如表1所示。
[0054]
表1相关系数标准及特性标准
[0055][0056]
1.3、根据步骤1.2中的分析程序分析各变量与实际负荷数据的相关性。
[0057]
1.4、重复步骤1.2和1.3直至所有相关影响因素完成相关性分析;所有相关影响因素包括干球温度,露点,相对湿度,风速等级,前24小时的平均负荷、前一天的同一时刻负荷,前一周的同一时刻负荷等。
[0058]
本实施例分析得到的负荷数据与各变量之间的相关关系如表2所示:
[0059]
表2负荷数据与各变量的相关关系
[0060][0061]
其中,v,c,dry,dew,r,ws,al,hl,wl分别代表变量,相关系数,干球温度,露点,相对湿度,风速等级,前24小时的平均负荷、前一天的同一时刻负荷,前一周的同一时刻负荷。
[0062]
1.5、将所有经过分析后的相关影响因素组成数据集,从数据集中按相关性特性标准取出数据xi,对数据xi进行归一化处理,给予xi数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1;归一化处理采用如下公式进行:
[0063][0064]
式中:z为归一化之后的变量,μ和σ分别为变量v的样本均值与样本标准差。
[0065]
步骤二、对步骤一得到的归一化后的数据集训练bp神经网络算法模型;bp神经网络算法模型如图3所示。本步骤具体包括:
[0066]
2.1、选定bp神经网络的隐含层神经元个数n,设置隐含层神经元以及输出层神经元的激励函数分别为tansig函数和purelin函数,如表3所示。随机初始化网络权值和阈值,取迭代次数为5000次。
[0067]
表3不同激励函数
[0068][0069]
2.2、采用trainglm学习函数,levenberg-marquardt算法在训练样本上重复训练10次,并计算10次训练结果的平均绝对误差百分比mape平均值;网络历元迭代次数为5000次,预期误差目标为0.00000001次。
[0070]
2.3、若平均绝对误差百分比mape为最小值,则结束;否则跳到2.1继续重新选择隐含层数n;
[0071]
2.4、对隐含层神经元个数为19的神经网络,随机初始化网络权值和阈值,取迭代次数为30000次。采用trainglm学习函数,重复训练。不同激励函数得到的mape曲线如图4~图7所示,各激励函数得到的具体mape数值如表4所示。
[0072]
表4不同激励函数
[0073][0074]
步骤三、对步骤二得到的bp神经网络模型进行训练与精度检验;具体地:
[0075]
3.1、设置迭代次数为100000次,选择隐含层个数为1,隐含层神经元个数n=19,隐含层神经元和输出层神经元的激活函数分别为tansig函数和purelin函数。神经网络进行深度训练以达到目标误差,迭代训练结束。得到的单隐含层误差与平均绝对误差如图8所示。
[0076]
3.2、按小时划分预测错误统计信息曲线如图9所示,按星期划分预测错误统计信息曲线如图10所示。训练样本仿真曲线如图11所示,其中深黑色曲线为实际负荷预测,浅灰色曲线为预测负荷,可知预测负荷的拟合趋势和实际样本趋势一致,进一步地,预测负荷与实际负荷平均绝对误差百分比mape如图12所示,进一步说明bp神经网络模型在训练样本上对a区短期电力负荷数据具有较好的拟合能力。
[0077]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的工作人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。