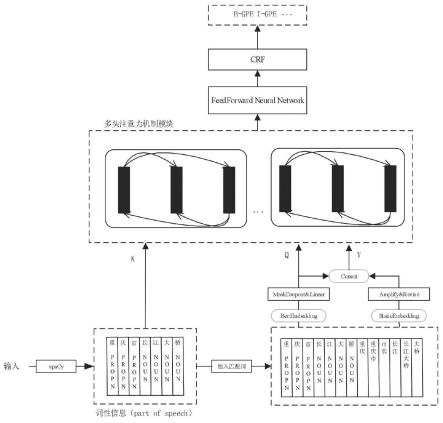
1.本发明涉及深度学习以及自然语言处理领域,具体涉及一种基于嵌入分布改进的中文命名实体识别方法。
背景技术:
2.随着机器翻译、信息提取、条件搜索等领域的飞速发展,自然语言处理在实际应用中越来越广泛,而命名实体识别(named entity recognition,ner)作为信息抽取、机器翻译等领域最重要的任务之一,其目的是自动检测给定文本中的命名实体并识别其类别。由于汉语中不存在英语文本中类似的空格分词符,因此汉语ner相较于英文ner来说更加困难。
3.在研究早期,汉语ner任务被分解为两个独立的串联式任务,即分词和词序标记,这种方法存在一个严重的缺陷:如果存在分词错误,那么会导致分词错误在后续网络中传播。在后续的研究中,研究者提出基于字符的模型来避免分词错误,但这样完全丢掉词信息放弃了词语深层的语义信息,也变相的降低了嵌入的语义表达能力。于是,研究者们提出将词信息整合到基于字符的ner模型中。在近些年,研究者们聚焦于建模词与字符间的关系,以此来让模型学习到某些潜在的语义信息,例如(xiaonan li,hangyan,xipeng qiu,andxuanjing huang.2020. flat:chinese ner using flat-lattice transformer.in proceedings ofthe 58th annualmeeting oftheassociation for computational lin-guistics,pages 6836
–
6842,online. association for computational linguistics.)模型提出基于跨度信息的位置编码来建模词元间的联系;但是,在中文ner任务中很少有人关注原始的词嵌入,如果原始词嵌入存在问题,那么它将产生和分词信息错误传播一样的错误。对于静态词嵌入,(gong c,he d,tan x,et al.frage:frequency-agnostic wordrepresentation[j].advances in neural informationprocessing systems,2018,31.)探讨了词频信息对于词嵌入信息的影响,提出将词频信息从嵌入信息中剔除,以此来解决低频词语义表达能力弱的问题;(mu j,bhat s,viswanath p.all-but-the-top: simple and effective postprocessing for word representations[j].arxiv preprintarxiv:1702.01417,2017.)提出一种词嵌入后处理技术,通过消除公共平均向量和几个顶部主导方向,使得现成的表示更加强大。词嵌入会分布于一个狭窄的锥形区域内,这样的分布会很大程度上限制词嵌入的表达能力,(gao j,he d,tan x,etal.representation degeneration problem in training natural language generationmodels[j].arxiv preprint arxiv:1907.12009,2019.)证明了这个现象并提出了一个新型的正则化方法来解决这个问题。另一方面,随着预训练模型的发展,语境化的词嵌入表示代替静态词嵌入成为了主流趋势,近些年研究者们常利用bert预训练模型得到词嵌入作为网络的输入。但命名实体识别的研究者们很少考虑到词嵌入的可靠性问题,(ethayarajh k.how contextual are contextualized wordrepresentations?comparing the geometry ofbert,elmo,and gpt-2embeddings[j]. arxiv preprint arxiv:1909.00512,2019.)研究了elmo、bert
和gpt-2预训练模型每一层的单词化嵌入,证明了他们的分布不是各向同性的;(li b,zhou h,he j, et al.on the sentence embeddings from pre-trained language models[j].arxivpreprint arxiv:2011.05864,2020.)通过对嵌入的理论探讨,发现bert句向量空间在语义上是非平滑的。于是,本发明针对于词嵌入的各向异性分布情况进行改善,然后提出一种简单有效的方法来改变嵌入的分布特性,从而解决该问题。另一方面,基于嵌入信息的增强方法也是近些年的研究热点,(aiguo chen, chenglong yin.crw-ner:exploiting multiple embeddings for chinese namedentity recognition[c]//proceedings of 20214th international conference onartificial intelligence and big data(icaibd),2021:520-524.)以及(shuang wu, xiaoning song,zhenhua feng.mect:multi-metadata embedding basedcross-transformer for chinese named entity recognition[c]//proceedings of the 59th annual meeting of the association for computational linguistics,acl, 2021:1529-1539.)在输入层融入词根信息来提升语义信息,这也说明了辅助的输入信息能在一定程度上提升语义丰富度,因此,本发明在嵌入层为模型加入词性信息,以此来达到对语义的增强。
[0004]
综上所述,考虑到目前研究者普遍采用静态词嵌入以及基于语义信息的动态词嵌入,而静态词嵌入对于多义词表达存在天然的不足以及动态词嵌入分布存在的各向异性的分布而导致的表达退化的问题,本发明设计了一种基于嵌入分布改进的中文命名实体识别方法通过对静态词嵌入以及动态词嵌入分别做不同的变换处理,使模型的输入分布呈现各向同性的特性,让模型学习到更加丰富的语义信息,从而提升了中文命名实体识别的准确率。
技术实现要素:
[0005]
本发明的目的在于设计一种基于嵌入分布改进的中文命名实体识别方法准确的识别出文本中的实体,并在基于嵌入分布改进的中文命名实体识别方法的基础上针对具体实现命名实体识别的领域如医疗文本微调预训练模型,以达到最佳的实现效果。
[0006]
本发明提供了一种基于嵌入分布改进的中文命名实体识别方法,包括:输入信息预处理模块,用于将输入文本进行预处理,通过自然语言处理工具为输入文本增加词性信息,然后对静态词嵌入和基于bert的上下文语义词嵌入进行嵌入空间转换令其分布具备各向同性,最后将它们送入自注意力机制中进行建模,并通过条件随机场对标签约束进行学习,得到最后对实体以及实体类别预测。
[0007]
本发明内容主要分为三个部分:静态词嵌入处理方法、动态词嵌入处理方法以及注意力机制改进方法。
[0008]
基于嵌入分布改进的中文命名实体识别方法是本发明的主要内容,本发明提出的基于嵌入分布和注意力机制改进的中文命名实体识别方法,通过对输入文本预处理,得到网络模型的最终输入,然后经过注意力机制进行长距离依赖建模、前馈神经网络进行进一步的特征提取,最后将模型的输出送入条件随机场中进行标签信息的约束学习。具体包括以下步骤:
[0009]
1.对输入的文本进行预处理:在嵌入层,本发明将输入分为了三个部分,第一部分利用了开源的自然语言处理库对词性信息进行提取并将其转移到字符层面,然后通过预训
练好的词表进行向量映射作为输入;第二部分利用bert预训练模型来获取动态词嵌入作为输入;第三部分同时采用了静态词向量以及动态词向量作为输入。其中静态词向量的处理方法为:采用的词向量为50维,先对其中元素进行放大操作,首先计算相邻两个值a和b的平均值c,然后对a、b、 c进行排序,如果它们中最小的值都大于0,那么令a加上a与c的差的绝对值,令b加上b与c的差的绝对值,如果它们中最大的值都小于0,那么令a减去a 与c差的绝对值,令b减去b与c差的绝对值,之后在对所有词向量的元素进行放大后,其中过大的值进行尺度变换缩小,对过小的值进行尺度变化放大,计算50个值的平均值,将大于平均值和小于平均值的数目进行统计,然后对他们的差值的个数的值进行约束,使其在嵌入空间中所占空间更大。而动态词嵌入,由于采用了语境化能力强的bert模型,使得模型可以学习到同一个词在不同的句子中所具有的几个意思,因此表示向量只集中分布于向量空间中的某一簇,表示为各向异性,而这种情况会降低模型的泛化能力,也就是说在不同句子中,同一个词的分布应该是不同的,而不是在词嵌入空间中具有锥形分布,具有很高的余弦相似度,本发明首先对原始bert词嵌入进行随机mask操作,然后令其通过一个线性层使其具备各向同性的分布。
[0010]
2.构建一个基于嵌入分布改进的中文命名实体识别网络:在注意力机制的计算中,采用了transformerxl计算方法,对于位置编码部分采用了flat网络的编码方法,针对注意力机制的输入,本发明修改了原有的单输入为三输入,即本发明在嵌入层对输入做的三种处理。注意力模块计算方法如下:
[0011][0012]
att(a,v)=softmax(a)v
[0013]
其中,i表示第i个词元,ij表示第i个词元和第j个词元的关系。q为利用bert 预训练模型获取的动态词嵌入信息,k为利用自然语言处理工具获取的词性信息, v为同时采用的静态词向量以及动态词向量信息的表示。u、v为可学习的超参数,注意力机制中的位置信息编码模块是注意力机制中的位置信息编码,用于输入语句中词元之间的位置信息建模,归一化指数函数softmax将注意力值进行归一化处理。融合位置信息为:
[0014][0015]
上式中,中的h
i-hj代表同理,t
i-tj代表代表和计算过程如下式:
[0016][0017][0018]
上式中,d
model
是模型的维度,位置d通过下式计算方法得到:
[0019][0020]
式中hh表示head[i]到head[j]的距离,其中i表示第i个词元,j表示第j个词元,tt表示tail[i]到tail[j]到距离。
[0021]
3.利用开源数据集如weibo等对网络进行预训练,得到预训练模型;
[0022]
4.通过迁移学习的方式将预训练好的模型转移到目标域;
[0023]
5.通过微调的方式得到适用于目标域的预训练模型,使用此模型对该领域文本进行命名实体识别检测,得到目标实体和实体类型。
[0024]
由于采用以上技术方案,本发明具有以下优点:
[0025]
1、词嵌入技术为自然语言处理应用带来了巨大的改变,得益于几何学的表达,词向量能更好的捕捉语言规律,自word2vec被提出后,往往作为自然语言处理任务中的基础输入映射存在。例如,对于输入序列s={s1,s2,
…
sn},往往通过word2vec得到最终的输入s
′
=word2vec(s)。这种静态映射得到的词嵌入有一个很明显的不足,那就是缺少灵活的语境化表达,在以下两句话中可以明显的了解到“领导”的不同语义:“在
××
的领导下”和“真正的领导者”,那么对于这样多语义词的情况,静态词嵌入的表达就不能满足了。因此,随着bert预训练模型的提出,更多研究者更趋向于使用类似bert的预训练模型来得到语境化的词嵌入表达。但即使使用大规模语料库训练神经网络,大部分的词向量仍然会退化并分布在嵌入空间的一个狭小锥形区域内,这导致了一个非光滑的各向异性的语义空间,也就是说这样的分布损害了它的语义表达性能。在本发明中,首先对bert 词嵌入的分布做处理,使其分布由各向异性转为各向同性,然后再与静态词嵌入做一个融合,实现了两者优势的互补,从而能实现语义特征更好的表达。
[0026]
2、本发明提出针对自注意力机制的改进,不同于传统的transformerxl计算方法,传统的自注意力机制计算方法采用相同输入的不同线性变换来实现,这里为了这里采用了包含词信息的语义嵌入和基于bert预训练模型的上下文语义信息进行交互,最后再通过点乘结合了静态词嵌入与bert词嵌入的输入表征来进行信息恢复,使得模型能够关注到词元间的语义关系以及位置关系。
附图说明
[0027]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供下附图进行说明:
[0028]
图1是本发明的基于嵌入分布改进的中文命名实体识别方法流程示意图;
[0029]
图2是本发明的静态词嵌入和动态词嵌入分布图;
[0030]
图3是本发明对词嵌入特征处理后的分布图。
具体实施方案
[0031]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地、完整地描述。
[0032]
本发明提出了一种基于嵌入分布改进的中文命名实体识别方法,如图1,具体包括如下步骤:
[0033]
步骤1、对输入文本进行词匹配、词性匹配,以及词向量映射等预处理操作;
[0034]
步骤2、构建一个融合词性信息以及词信息的神经网络,将预处理得到的向量送入网络中学习。
[0035]
步骤3、利用改进的自注意力机制对经过预处理后得到的三部分输入进行注意力训练,在后续此类信息再次出现就可以自动关注到该区域;
[0036]
步骤4、将自注意力机制的输出送入到线性层中进行特征学习;
[0037]
步骤5、将编码器的输出送入到条件随机场中进行标签约束学习,得到最终的预测实体。
[0038]
具体实施方式
[0039]
步骤1:接收输入文本,利用输入预处理模块进行词匹配和词性匹配,然后将利用预训练好的向量表进行词向量映射,同时对静态词向量进行线性均匀扩增,首先对原始的静态词向量进行度量如图2(左图)所示,发现静态词嵌入的分布紧靠零域,这导致其分布不能很好的进行语义特征的表达,这里采用的词向量为 50维,先对其中元素进行放大操作,具体的实现方法是:计算相邻两个值a和b 的平均值c,然后对a、b、c进行排序,如果它们中最小的值都大于0,那么令a 加上a与c的差的绝对值,令b加上b与c的差的绝对值,如果它们中最大的值都小于0,那么令a减去a与c差的绝对值,令b减去b与c差的绝对值。在对所有词向量的元素进行放大后,其中过大的值进行尺度变换缩小,对过小的值进行尺度变化放大,计算50个值的平均值,将大于平均值和小于平均值的数目进行统计,然后对他们的差值的个数的值进行约束。对静态词向量处理后,需要对 bert词嵌入进行处理,这里对bert词向量进行度量如图2(右图)所示,发现其分布呈锥形,故将bert词向量与经过均匀放大操作后的静态词嵌入进行一个相加操作,然后经过dropout操作,得到图3(中)表示,然后通过一个线性层以进行各向同性的空间转换得到图3(右图)所示的向量表示。
[0040]
步骤2:将预处理后的文本送入自注意力机制模块进行建模,使用pytorch 框架构建此中文命名实体识别网络,多头注意力模块在整体框架中的位置如图1 所示,整体计算公式如下:
[0041][0042]
att(a,v)=softmax(a)v
[0043]
其中,i表示第i个词元,ij表示第i个词元和第j个词元的关系。q为利用bert 预训练模型获取的动态词嵌入信息,k为利用自然语言处理工具获取的词性信息, v为同时采用的静态词向量以及动态词向量信息的表示。u、v为可学习的超参数,注意力机制中的位置信息编码模块是注意力机制中的位置信息编码,用于输入语句中词元之间的位置信息建模,归一化指数函数softmax将注意力值进行归一化处理。融合位置信息为:
[0044][0045]
上式中,中的h
i-hj代表同理,t
i-tj代表代表和计算过程如下式:
[0046][0047][0048]
上式中,d
model
是模型的维度,位置d通过下式计算方法得到:
[0049][0050]
式中hh表示head[i]到head[j]的距离,其中i表示第i个词元,j表示第j个词元,tt表示tail[i]到tail[j]到距离。
[0051]
步骤3:将编码部分的输出送入到crf层进行计算,通过条件随机场对于标签信息
的约束学习,得到最后的预测实体。
[0052]
步骤4:训练所构建的中文命名实体识别网络。通过迁移学习的方式,先利用相关领域的开源数据对网络进行预训练,再使用自制已标注的中文实体识别数据集对于预训练的网络进行微调。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。