1.本发明涉及生物统计学技术领域,特别涉及父母子三元亲属结构的候选区域基因关联检测系统及方法。
背景技术:
2.基因是指携带有遗传信息的dna或rna序列,也称为遗传因子,是控制性状的基本遗传单位。基因通过指导蛋白质的合成来表达自己所携带的遗传信息,从而控制生物个体的性状表现。现代医学研究证明,除外伤外,几乎所有的疾病都和基因有关系。人体中正常基因也分为不同的基因型,不同的基因型对环境因素的敏感性不同,敏感基因型在环境因素的作用下可引起疾病,单独由异常基因直接引起疾病,被称为遗传病。因此基因与性状的关联检测问题成为本领域的研究重点。
3.目前基因关联检测方法主要是针对独立个体的基因关联检测,但是疾病的状态一般都不是独立的,而是受相似遗传因素和环境因素影响。由于家庭成员具有相似的遗传和环境因素,且家庭成员的疾病状态一般并不独立,所以目前针对独立个体的基因关联检测还存在难以克服群体分层的影响,从而无法精准实现基因与性状的关联检测问题。
技术实现要素:
4.本发明目的是为了解决现有基因关联检测方法还存在难以克服群体分层的影响,从而导致无法精准实现基因与性状的关联检测的问题,而提出了父母子三元亲属结构的候选区域基因关联检测系统及方法。
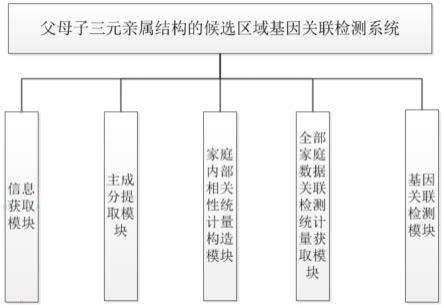
5.父母子三元亲属结构的候选区域基因关联检测系统具体过程为:
6.信息获取模块,主成分提取模块,家庭内部相关性统计量构造模块,全部家庭数据关联检测统计量获取模块,基因关联检测模块;
7.所述信息获取模块用于获取父母子三元亲属结构家庭成员基因组上的标记位点信息x
ijl
以及性状信息y
ijl
;
8.其中,x
ijl
和y
ijl
分别表示第i个子群体第j个家庭中第l个个体的基因型得分和数量性状值;
9.所述主成分提取模块用于提取信息获取模块获取的信息主成分t
ijl
=(t
ijl1
,
···
,t
ijlf
);
10.其中,f是主成分的总数量;
11.所述家庭内部相关性统计量构造模块用于根据x
ijl
和y
ijl
和t
ijl
构造家庭内部相关性统计量u
ij
;
12.所述全部家庭数据关联检测统计量获取模块用于根据u
ij
获取全部家庭数据关联检测统计量;
13.所述基因关联检测模块用于根据获取全部家庭数据关联检测统计量的统计p值,并根据统计p值确定基因与性状信息是否有关联。
14.父母子三元亲属结构的候选区域基因关联检测方法应用于父母子三元亲属结构的候选区域基因关联检测系统中。
15.本发明的有益效果为:
16.本发明从家庭型数据着眼,提出了一种新的基于广义估计方程的主成分法,对常见或罕见遗传变异的关联性进行检测,同时建立了关联检验统计量,对目标性状的潜在因果变异位点进行检测,克服了群体分层的影响,从而实现了在家庭型数据框架下基因与性状的精准关联检测。
附图说明
17.图1为本发明模块图。
具体实施方式
18.具体实施方式一:本实施方式父母子三元亲属结构的候选区域基因关联检测系统,包括:信息获取模块,主成分提取模块,家庭内部相关性统计量构造模块,全部家庭数据关联检测统计量获取模块,基因关联检测模块(如图1);
19.所述信息获取模块用于获取父母子三元亲属结构家庭成员基因组上的标记位点信息x
ijl
以及性状信息y
ijl
;
20.其中,x
ijl
和y
ijl
分别表示第i个子群体第j个家庭中第l个个体的基因型得分和数量性状值;
21.所述主成分提取模块用于提取信息获取模块获取的信息主成分t
ijl
=(t
ijl1
,
···
,t
ijlf
);
22.其中,f是主成分的总数量;
23.所述家庭内部相关性统计量构造模块用于根据x
ijl
和y
ijl
和t
ijl
构造家庭内部相关性统计量u
ij
;
24.所述全部家庭数据关联检测统计量获取模块用于根据u
ij
获取全部家庭数据关联检测统计量;
25.所述基因关联检测模块用于根据获取全部家庭数据关联检测统计量的统计p值,并根据统计p值确定基因与性状信息是否有关联。
26.具体实施方式二:所述家庭内部相关性统计量构造模块用于根据x
ijl
和y
ijl
和t
ijl
构造家庭内部相关性统计量,具体为:
27.步骤一、建立主成分t
ijl
=(t
ijl1
,
···
,t
ijlf
)与y
ijl
的广义线性函数和主成分t
ijl
=(t
ijl1
,
···
,t
ijlf
)与候选标记点位信息x
1ijl
的广义线性函数:
28.y
ijl
=g1(t
ijl
) ψ
ijl
,
29.x
1ijl
=g2(t
ijl
) ε
ijl
30.其中,ψ
ijl
是随机变量,ε
ijl
是随机变量,g1(t
ijl
)和g2(t
ijl
)是模型核心函数,候选标记点位信息x
1ijl
是标记点位信息x
ijl
中的一部分,e(ψ
ijl
)=e(ε
ijl
)=0,e(ψ
ijl
)和e(ε
ijl
)是随机变量ψ
ijl
和ε
ijl
的期望;
31.[0032][0033]
β1=(β
10
,β
11
...,β
1f
)是模型核心函数g1(t
ijl
)中主成分的系数;β2=(β
20
,β
21
...,β
2f
)是模型核心函数g2(t
ijl
)中主成分的系数;
[0034]
步骤二、利用步骤一获取的广义线性函数获取家庭内部的相关性统计量u
ij
:
[0035]
步骤二一、基于广义估计方程理论对g1(t
ijl
)和g2(t
ijl
)进行估计获得的
[0036]
步骤二二、将步骤二一获得的代入步骤一获得广义线性函数中获得和并利用和配置残差变量,如下:
[0037][0038][0039]
步骤二三、利用步骤二二获得的残差变量构造家庭内部的相关性统计量u
ij
:
[0040][0041]
其中,是第i个子群体的性状值平均值,是第i个子群体的基因型的平均值,c
ij
是第i个群体中第j个家庭中的个体总数。
[0042]
具体实施方式三:所述全部家庭数据关联检测统计量获取模块用于根据u
ij
获取全部家庭数据关联检测统计量,具体为:
[0043][0044]
其中,k是子群的总数,ni是i个子群中家庭的总数;
[0045]
具体实施方式四:所述基因关联检测模块用于根据获取全部家庭数据关联检测统计量的统计p值,并根据统计p值进行基因关联检测,具体为:
[0046]
s1、在零假设下计算全部家庭数据关联检测统计量的统计p值;
[0047]
s2、将获得的统计p值与预设的显著性水平进行比较,若p大于预设的显著性水平,则表示基因与性状产生关联,若p小于等于预设的显著性水平则表示基因与性状没有关联;
[0048]
其中,统计p值是显著性水平。
[0049]
具体实施方式五:父母子三元亲属结构的候选区域基因关联检测方法应用于父母子三元亲属结构的候选区域基因关联检测系统中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。