1.本发明涉及一种使用处理器系统的硬件加速指令实现计算的计算机实现的方法和对应的系统。本发明进一步涉及一种计算机可读介质,该计算机可读介质包括执行以上方法的指令和/或使用硬件加速指令实现所述计算的指令。
背景技术:
2.随着收集和处理的数据量不断增加,高效地实现大的计算变得越来越重要。需要处理大量数据的一个领域尤其普遍的是机器学习。例如,诸如深度神经网络(dnn)的神经网络的评估但尤其还有训练涉及大量矩阵乘法、卷积、点积和类似运算的评估。针对特定应用定制了大量且不断发展的多种dnn架构。
3.为了加速此类计算,越来越多的专用硬件变得可用。这样的硬件涉及硬件加速器,其被优化以高效地执行特定指令,诸如矩阵乘法或卷积。因此,使用此类硬件加速指令允许特别是在资源受限的环境中更高效地实现计算。
4.为了利用硬件加速指令,重要的是提供编译器技术,用于将高级编程语言中的代码翻译成调用硬件加速指令的机器可执行指令。这是特别重要的,因为要执行的计算和执行计算的硬件架构二者都在不断发展。然而,自动确定如何实现诸如与神经网络层评估相关的计算之类的计算是复杂的任务,使得它们进行对硬件加速指令的最有效利用。该任务如此复杂的原因之一是,硬件加速指令可能具有复杂的数据流,所述复杂的数据流可能涉及在多维输入和输出阵列上的数百或数千个并行和顺序运算。
5.在m. sotoudeh等人的论文“isa mapper: a compute and hardware agnostic deep learning compiler”(在https://arxiv.org/abs/1810.09958可获得并且通过引用并入本文)中,提出了对包括矩阵乘法指令的指令集执行代码生成的技术。深度学习计算内核和硬件能力由中间表示来描述,该中间表示对运算符的循环级表示起作用。应用指令映射来确定可以在硬件系统上执行计算的可能方式。在该指令映射中,多个“ir变换”被应用于计算,之后“确定性映射器”试图在循环级将变换的计算映射到硬件指令。调度程序选择特定的映射。为了管理映射和调度的大搜索空间,使用了启发法、成本模型和潜在的机器学习。
技术实现要素:
6.使用硬件加速指令实现计算的现有技术的一个缺点是,使用运算符的循环级表示引入了隐式实现决策,如循环和张量排序或访问函数表示法(notation)。例如,运算符中模板的张量访问函数可以是板的张量访问函数可以是,而加速器可以提供具有访问函数的指令。对于,匹配是可能的,但是通常难以例如通过模式匹配来自动建立这样的匹配。因此,可能错过可能的实现。
7.现有技术对明确指定的ir变换集的依赖也是不利的。难以直接检测到导致嵌入的
特定变换序列。最终,这可能导致非确定性的搜索过程,其中需要生成许多不同的实现候选。此外,添加的变换越多,搜索空间增大得就越多,其中数字解的递减回报。因此,在寻找最佳实现所需的探索和在合理量的时间内找到解所需的搜索空间限制之间存在紧张关系。此外,即使使用了大的变换集,实现的子类仍然有可能隐藏在不可用的变换后面。
8.由于这些缺点,现有技术可能无法找到进行对硬件加速指令的最有效利用的计算实现。在一些情况下,现有技术甚至可能根本无法找出硬件加速指令可以如何用于计算中。因此,合期望的是具有能够使用硬件加速指令找到更多可能的计算实现的技术。还合期望的是具有能够更高效地找到此类实现的技术。
9.根据本发明的第一方面,分别如权利要求1和14限定的,提供了一种使用处理器系统的硬件加速指令实现计算的计算机实现的方法和对应的系统。根据本发明的另一方面,如权利要求15限定的,提供了一种计算机可读介质。
10.各种措施针对使用处理器系统的硬件加速指令来实现计算。通过使用硬件加速指令实现计算,这意味着找到了计算中指令的可能调用,换句话说,找到了可以通过调用指令来执行的计算的一部分。确定的调用可以用于自动生成机器可执行指令,所述机器可执行指令实现计算并且根据确定的可能调用来调用硬件加速指令,例如,将计算编译成可执行代码,但是这不是必需的。找到可能调用本身已经是有用的,例如:供在手动实现计算中使用;用于确定这样的实现究竟是否可能;或者供执行实际编译的另一个系统使用。
11.计算和硬件加速指令可以由相应的数据流图来表示。数据流图的节点可以表示计算或指令的输入和运算,其中边表示节点之间的数据流关系,例如,运算的传入边可以用来表示运算作用的值。硬件加速指令通常用固定的数据流执行预定义的运算,例如,指令数据流图可以是固定的。运算通常是标量运算,例如,应用于个体数值或非数值元素的运算。
12.有趣的是,发明人意识到,确定计算中硬件加速指令的可能调用的问题可以被表述为将计算数据流图的节点赋值给指令数据流图的节点的约束满足问题。因此,约束满足问题的解可以将计算数据流图的节点(例如,计算的运算或输入)赋值给指令数据流图的节点(例如,硬件加速指令的运算或输入)。这样的赋值在本文中也被称为指令数据流图到计算数据流图的“映射”。实际上,提出了一种自下而上的方法,其中通过找到约束满足问题的解,可以逐步地构造从指令到计算的映射,而不是通过变换计算并且然后将计算映射到硬件指令以自上而下的方法找到可能调用。
13.约束满足问题可以被定义为使得约束满足问题的解表示在计算中硬件加速指令的可能调用。为此,约束满足问题可以包括称为数据流约束和输入约束的至少两种类型的约束。
14.数据流约束可以实施赋值给指令数据流图的节点的计算数据流图的节点具有与指令数据流图等效的数据流。例如,硬件加速指令被映射到对应于硬件加速指令的功能的计算部分。特别地,根据指令数据流图所指示的数据流关系,对指令数据流图的输入所映射到的计算值执行指令数据流图的运算可以导致与执行这些运算所映射到的计算数据流的运算相同的计算结果。实施此的一种方式是通过实施指令数据流图所映射到的计算数据流图的子图同构于指令数据流图本身,尽管该要求的放松是可能的。
15.然而,如发明人意识到的,为了从指令数据流图到计算数据流图的映射表示硬件加速指令的可能调用,在许多情况下,仅仅使用数据流约束是不够的。这是因为硬件加速指
令和/或其编程接口通常对该指令可以应用的计算值施加附加的限制。例如,硬件加速指令可能要求其输入根据特定的内存布局来组织,和/或根据特定的访问模式来访问。为了表示这样的要求,约束满足问题还可以包括一个或多个输入约束,所述一个或多个输入约束限制计算数据流图的哪些节点可以被赋值给硬件加速指令的输入。因此,可能调用可以是与硬件加速指令和/或其编程接口所施加的限制相兼容的调用。
16.有趣的是,通过依据约束满足问题定义可能调用,使能通过求解约束满足问题来确定可能调用。该技术本身是已知的。数据流和输入约束可以保证调用是可能的。不需要首先对完全计算应用变换并且然后尝试是否可以使用硬件加速指令来实现变换的计算,这可能是低效的。取而代之,表示硬件加速指令调用的映射可以由约束求解器逐渐地构造,其中约束保证解是可能调用。也不需要定义显式的代码变换集,这可能非常困难或者不可能完成。
17.因为映射是在运算级上执行的,而不是例如在循环级上执行的,并且因为约束求解器可以找到满足约束的任何映射,所以可以避免诸如循环排序、内存布局和内存访问功能之类的隐式的实现决策。特别地,可以用比基于预定义的变换集的已知方法提供的更灵活的内存布局来确定调用。在基准上的实验示出,实践中该增加的灵活性允许找到比已知技术性能更好的调用。因此,可以找到硬件加速指令的宽范围的可能调用,并且这可以以更高效的方式(例如计算更低成本的方式)来完成。可以找到硬件加速指令的那些更有效的调用,或者甚至可以找到这在先前不可行的计算的调用。
18.使用约束求解器查找可能调用的另外优点是,可能的是将可能调用需要满足的需求与被认为是有益的偏好分离。特别地,通过调整约束求解器应用的变量选择策略和/或值选择策略,可能的是在约束求解期间控制解空间,但是不影响解有效意味着什么。通过控制约束求解器,可能的是引导约束求解器首先找到特定的解。因此,可以改进所确定的可能调用的质量,并且可能的是通过然而在不丢弃部分解空间的情况下有效地建议部分潜在解来尝试,来进一步改进约束求解器的效率:如果建议没有导致解,则约束求解器可以继续考虑其他可能的解。
19.可选地,可以生成机器可执行指令来实现计算。这些指令可以根据所确定的可能调用来调用硬件加速指令。这样,可以获得利用硬件加速指令的计算的高效实现。因此,可以提供一种将计算编译成机器可执行指令的方法。
20.可选地,计算和指令数据流图可以包括表示标量运算的节点。例如,标量运算可以作用于固定数量的一个或多个单独的值(通常是一个或两个),并输出固定数量的一个或多个单独的值(通常是一个)。因此,约束满足问题可以将标量运算映射到标量运算,而不是在循环级别上作用。在一些实施例中,图的每个节点可以表示标量运算,其中可能的例外是如其他地方所述的交换约简运算。如其他地方所解释的,通过在标量级执行映射,可以以其他方式限制可以找到哪些调用的隐式建模假设被最小化,从而允许标识性能更好的调用。
21.可选地,硬件加速指令可以实现矩阵乘法、卷积、点积、矩阵向量积、累积和、池化和哈达玛积中的一个或多个。这些是在大的计算中重复执行的常见运算,并且对于其硬件加速是可用的,因此优化它们特别相关。
22.通常,计算是包括预期由硬件加速指令可实现的运算的计算。例如,该计算可以是诸如在神经网络评估中卷积运算符的应用之类的更大计算的子计算,其被手动选择为潜在
服从硬件加速指令的应用。就数据流而言,可能存在许多不同的方式,可以以所述许多不同的方式在计算中调用指令,但是这些方式中仅有一些可以遵守硬件加速指令和/或其编程接口所施加的限制,并且那些可能调用在性能方面可能有很大不同。因此,能够自动找到和/或枚举可能调用是很重要的。
23.可选地,指令数据流图可以包括仅硬件加速指令的输出子集的节点。硬件加速指令的其他输出以及用于计算这些其他输出的运算可能被忽略,从而使约束满足问题更高效地求解。然后,基于所确定的可能调用,可以将所确定的可能调用推广到由指令执行的完全计算。例如,对于矩阵乘法指令,单个输出元素的计算的数据流图可能足以外推至完全矩阵乘法的输入和输出。可以选择的输出子集,其使用硬件加速指令的所有输入,使得可能调用映射所有输入,使得外推更容易;或者也可以外推指令输入到计算的映射。
24.可选地,该计算可以是应用于神经网络评估中的计算。例如,计算可以包括卷积、矩阵乘法和/或应用于例如神经网络层输入的池化运算。计算可以触及神经网络层输入的每个节点。神经网络评估是在神经网络的训练期间和使用期间二者都发生的运算,并且涉及重复应用服从诸如矩阵乘法的硬件加速的运算,并且因此是特别相关的优化目标。此外,就数据流而言,存在许多不同的方式,可以以所述许多不同的方式应用这些运算。特别地,为了使神经网络训练有效,通常需要在大数据集上训练神经网络;而神经网络的评估通常发生在资源受约束的环境中。在这两种情况下,优化具有特别的重要性。此外,考虑到神经网络层和加速硬件很大的多样性和不断发展,能够获得新类型的神经网络层和/或新硬件目标的实现是特别重要的。
25.可选地,计算的至少一部分可以由多面体表示来指定。多面体表示可以象征性地定义计算数据流图的节点集。当求解约束满足问题时,多面体表示可以被实例化以获得该节点集的具体注释,并且然后指令数据流图的节点可以被映射到该获得的节点。
26.多面体表示本身是一种紧凑地表示基于循环的程序的方式。有趣的是,发明人意识到,除了对基于循环的程序的建模循环之外,多面体表示也可以用于对数据流建模。通过直接将多面体表示彼此转化来确定调用是不合期望的,例如,因为该表示表示了像循环或张量维数排序的建模假设,并且因为这样做可能需要定义表示的显式变换,以及在其他地方描述的相关联的缺点。有趣的是,通过使用指令数据流图要映射到的计算数据流图的多面体表示,避免了这些缺点。
27.结合本技术,多面体表示可以用于象征性地定义计算数据流图的多面体集合。然而,有趣的是,指令数据流图和计算数据流图之间的映射仍然可以不依据节点集(例如运算集)来执行,而是依据个体节点(例如个体运算)来执行。多面体表示法可以避免需要存储完全计算数据流图;仅映射以形成指令数据流图的那些个体元素需要被实例化。在许多情况下,这大大降低了计算和内存复杂性。
28.多面体表示通常不用于表示计算数据流图,或者至少在约束求解期间不使用它的多面体表示。计算数据流图的多面体节点通常作为约束满足问题的变量单独存储。
29.可选地,可以定义一个或多个输入约束,以实施硬件加速指令的输入具有允许的内存布局和/或内存访问模式。通常,硬件加速指令和/或其编程接口可以实施将指令所应用到的输入根据某种布置存储在内存中,例如,输入形成连续的内存块,内存地址以某种方式对齐,等等。这些是内存布局要求的示例,这些内存布局要求限制了硬件加速指令可以应
用于哪些输入。这些要求可以表示为输入约束,以确保它们得到遵守。类似地,硬件加速指令可以支持给定的访问模式集,根据给定的访问模式集,可以应用指令,例如,是否根据给定的步幅(stride)、给定的模板模式等来访问输入。这样,可以进一步限制硬件加速指令可以应用于哪些输入。
30.还可能的是将与硬件加速指令的中间结果和输出相关的内存布局和/或内存访问模式限制包括在约束集合中,例如表示由指令和/或其编程接口施加的指令。
31.可选地,可以定义一个或多个约束,实施将硬件加速指令的成对可相互并行化的运算映射到计算的成对可相互并行化的运算。例如,通过包括指示数据流图的可并行性的特殊类型的边,可以将对标记为可相互并行化。尽管没有必要显式地将运算对标记为可相互并行化,并在映射中实施此,但是这样做对于约束求解的性能是有益的,因为它允许求解过程直接消除其中可相互并行化的运算没有映射到可相互并行化的运算的潜在赋值。
32.有趣的是,发明人意识到,对于指令数据流图的全部都是可相互并行化的运算集,不需要为每个单独的对包括可并行性约束。由于求解器的效率通常与约束数量成比例,因此仅对于对的子集包括约束改进了求解器的性能;并且子集还帮助求解器消除赋值。此外,通过传递性,对于指令数据流图的对集合实施可并行性约束可能意味着也满足传递闭包中每个对的可并行性约束。在计算数据流图中,可以对于可相互并行化的运算集合中的每对运算指示可并行性,以免不必要地限制可以进行哪些赋值。对于计算数据流图来说,这可以施加较小的性能惩罚,尤其是如果该图例如由于多面体表示的使用而在求解期间没有被完全实例化。
33.可选地,指令数据流图的节点可以表示交换约简运算。例如,用于交换约简运算(例如和或积)的节点可以表示该运算被应用于该节点的所有传入边。使用此类节点可以大大减少指定常见硬件加速运算(诸如矩阵乘法或卷积)所需的节点和边的数量,而不影响数据流图作为计算或指令表示的正确性。它还允许更灵活的映射,因为该图没有指定元素需要减少的特定次序。尽管交换约简运算可以被隐式地定义,例如,由具有多于两个传入边的节点来定义,但是优选的是显式地将节点标记为表示交换约简运算。例如,这可以通过在图中包括自边来完成。这样的显式标记可以使约束求解器更高效地确定用于交换约简运算的映射。
34.数据流约束可以实施表示指令数据流图的交换约简运算的节点被映射到计算数据流图的对应节点。对应的节点可以是表示计算的交换约简运算的节点,例如,对于交换约简运算所作用的每个元素具有传入边的节点。然而,这不是必需的。也可能的是在指令数据流图中单独表示总体约简运算的个体约简。在此类情况下,指令数据流图的节点可以被映射到表示个体约简的节点。这可以使建模计算更容易,因为不需要对于交换约简运算的单独建模工作。
35.可选地,在求解约束满足问题时,可以使用通过指令数据流图向后传播的变量选择策略。在实践中观察到,对于由数据流和输入约束定义的约束满足问题的类型,使用该变量选择策略具有最大的传播潜力,并且因此通常在寻找解方面是最高效的。这被发现是特别地用于神经网络层评估的计算的情况。
36.可选地,约束满足问题可以被定义为允许硬件加速指令的运算映射到不影响计算(例如导致相同计算结果)的虚拟运算(dummy operation)。求解约束满足问题可以包括将
节点映射到虚拟运算,例如,可以将节点映射到不包括在计算数据流图中的运算,或者可以将多个节点映射到计算数据流图的相同节点。通过允许虚拟运算,增加了查找可能调用的灵活性。特别地,它可以允许将硬件加速指令应用于否则不可由指令执行的工作负载。例如,计算的相关部分可以小于硬件加速指令,例如,仅指令数据流图的节点子集可以被映射到计算数据流图的节点。例如,指令可以计算四个元素的总和,而计算需要仅三个元素的总和。通过包括不影响计算的虚拟运算,例如,为指令执行的运算添加中性元素,诸如零用于加法或一用于乘法,计算的相关部分仍然可以由硬件加速指令执行。
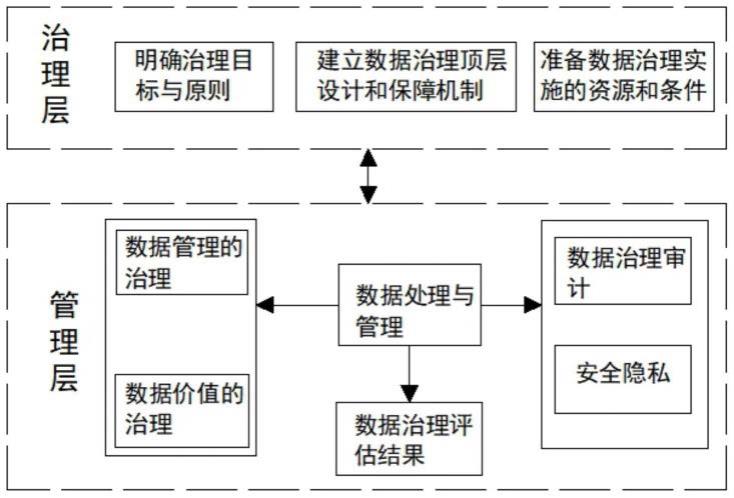
37.可选地,一个或多个约束可以被包括在约束满足问题中,实施硬件加速指令的输入以形成超矩形。该约束允许约束求解器快速排除大部分搜索空间,例如,仅在对指令数据流节点进行了几次赋值之后。这极大地改进了搜索的效率,并且此外保证了提供的正则解可以更容易地被推广以获得计算的剩余部分的调用。因为在许多实际应用中,硬件加速指令的典型调用具有超矩形输入,所以在此类情况下,这些限制不导致错过性能良好的可能调用。
38.可选地,可以确定约束满足问题的多个解。然后可以评估它们的性能,并且基于该性能评估,可以从多个解中选择一个解。约束求解器可以找到满足约束的可能调用,但是通常不在性能方面优化找到的解(尽管约束求解器可以被配置为对某些解进行优先级排序,也如本文所述)。然而,约束求解器可以被配置为输出对约束满足问题的多个解,或者甚至枚举所有可能的解。通过评估这些多个解的性能,可能的是选择具有所期望性能的解。可以采用各种策略,例如,可以确定固定数量的解或者可以使用固定量的时间来寻找解,并且然后可以评估找到的解;或者可以迭代地确定和评估解,直到找到具有合期望性能的解,或者直到在某个时段内没有找到进一步的改进;等等。
39.本领域技术人员将领会,可以用被认为有用的任何方式来组合本发明的以上提及的实施例、实现和/或可选方面中的两个或更多。
40.基于本说明书,本领域技术人员可以对任何系统和/或任何计算机可读介质实行修改和变型,所述修改和变型对应于所描述的对应计算机实现方法的修改和变型。
附图说明
41.本发明的这些和其它方面将从实施例和附图中清楚,并且进一步参考实施例并且参考附图来被阐明,所述实施例在以下描述中作为示例被描述,在所述附图中图1示出了用于实现计算的系统;图2示出了使用硬件加速指令执行计算的系统;图3示出了如何实现计算的详细示例;图4a示出了数据流图的详细示例;图4b示出了定义数据流图的多面体表示的详细示例;图5a-5d示出了应用超矩形约束的详细示例;图6示出了实现计算的计算机实现的方法;图7示出了包括数据的计算机可读介质。
42.应当注意到,各图纯粹是图解性的并且不按比例绘制。在各图中,与已经描述的元素相对应的元素可以具有相同的参考标号。
具体实施方式
43.图1示出了使用处理器系统的硬件加速指令来实现计算的系统100。例如,可以使用图2的系统200的处理器系统240来实现计算,例如,系统100可以产生可由处理器系统240执行的指令,或者至少确定对处理器系统240支持的硬件加速指令的调用,该硬件加速指令可以用于在处理器系统240上执行计算。系统100和200可以组合,例如,系统100的处理器系统140(下面进一步讨论)可以支持硬件加速指令。
44.系统100可以包括用于访问计算数据030和指令数据040的数据接口。计算数据030可以定义表示计算的计算数据流图。计算数据流图的节点可以表示计算的输入或运算。指令数据040可以定义表示硬件加速指令的指令数据流图。指令数据流图的节点可以表示硬件加速指令的输入或运算。
45.指令数据流图可以具有至少16个、至少32个或至少128个节点。节点的数量可以是最多2048个或最多4096个。计算数据流图通常具有比指令数据流图更大数量的节点,例如是指令数据流图的、或倍。例如,指令数据流图的节点数量可以是至少、或。
46.例如,也如图1中图示的,数据接口可以由数据存储接口120构成,数据存储接口120可以从数据存储装置021访问数据030、040。例如,数据存储接口120可以是存储器接口或永久存储接口——例如硬盘或ssd接口,但也可以是个域网、局域网或广域网接口——诸如蓝牙、紫蜂或wi-fi接口或以太网或光纤接口。数据存储装置021可以是系统100的内部数据存储装置——诸如硬盘驱动器或ssd,但是也可以是外部数据存储装置——例如网络可访问的数据存储装置。在一些实施例中,数据030、040可以各自例如经由数据存储接口120的不同子系统从不同的数据存储装置被访问。每个子系统可以具有如上针对数据存储接口120所述的类型。
47.例如数据存储接口120的数据接口也可以用于访问硬件加速指令的所确定的可能调用,或者如图中所示,通过根据所确定的可能调用调用硬件加速指令来实现计算的机器可执行指令050。这些指令050可以供执行计算的处理器系统(例如图2的处理器系统240)使用。
48.系统100可以进一步包括处理器子系统140,处理器子系统140可以被配置为在系统100的操作期间获得计算数据030和指令数据040。
49.处理器子系统140可以进一步被配置为基于计算数据和指令数据来定义约束满足问题。约束满足问题可以由变量集、域集和约束集来定义。通过“定义”约束满足问题,这意味着以允许约束满足问题由约束求解器求解的形式使得关于约束满足问题的信息可用。例如,不需要显式地和单独地存储变量、域和/或约束的集合,例如,如本身已知的,它们可以被隐式地定义和/或延迟地评估。此外,可以以计算数据030和/或指令数据040的形式使得部分或全部约束满足问题可用,例如,指令数据040可以包括或以其他方式定义指令数据流图的节点的节点集,并且从而定义约束满足问题的变量集。
50.对约束满足问题的解可以表示在计算中硬件加速指令的可能调用。约束满足问题可以将计算数据流图的节点赋值给指令数据流图的节点。约束满足问题可以包括一个或多个数据流约束,所述一个或多个数据流约束实施计算数据流图的赋值节点具有与指令数据
流图等效的数据流。约束满足问题可以进一步包括一个或多个输入约束,所述一个或多个输入约束限制计算数据流图的哪些节点可以被赋值给硬件加速指令的输入。后一种限制可以由硬件加速指令和/或其编程接口施加。可以例如通过基于计算数据030和/或指令数据040自动定义约束、通过接收约束的手动定义或两者的组合来定义约束。
51.处理器子系统140可以进一步被配置为求解约束满足问题,以确定在计算中硬件加速指令的可能调用。处理器子系统可以进一步被配置为输出定义可能调用的数据。
52.系统100可以进一步包括输出接口,用于输出定义可能调用的数据,所述数据例如是对约束满足问题的解或从解导出的机器可执行指令050。例如,也如图1中图示的,输出接口可以由数据接口120构成,其中所述接口在这些实施例中是输入/输出(“io”)接口,数据可以经由所述输入/输出(“io”)接口存储在数据存储装置021中。在一些实施例中,输出接口可以与数据存储接口120分离,但是通常可以具有如上针对数据存储接口120所述的类型。输出接口也可以是任何其他类型的输出接口,例如网络接口。
53.图2示出了使用硬件加速指令执行计算的系统200。
54.系统200可以包括用于访问指令050以执行计算的数据接口220。例如,指令050可以由图1的系统100生成,或者基于由系统100确定的可能调用。例如,也如图2中图示的,数据接口可以由数据存储接口220构成,该数据存储接口220可以从数据存储装置022访问指令050。通常,数据接口220和数据存储装置022可以具有与关于图1描述的数据接口120和数据存储装置021相同的类型。
55.系统200可以进一步包括处理器子系统240。处理器子系统240可以支持硬件加速指令。通常,硬件加速指令是由执行专用任务的处理器子系统240支持的指令。专用任务不是基本的cpu指令,诸如标量加法、标量乘法、按位“与”等。取而代之,对硬件加速指令的单次调用可以对应于执行这些基本指令中的几个;但是执行硬件加速指令通常更快。执行硬件加速指令可以改进计算性能,例如,导致减少的时延和/或增加的吞吐量。
56.硬件加速指令通常具有多个标量输入(例如,诸如整数或浮点的数值),例如至少4个、至少16个或至少64个。硬件加速指令可以具有单个输出(例如,诸如整数或浮点的数值),但是也可以具有多个这样的输出,例如至少4个、至少16个或至少64个。硬件加速指令可以对应于一定数量的n个基本cpu指令。例如,基本cpu指令可以对应于指令数据流图的节点。因此,n可以等于指令数据流图的节点数,或者,如果指令数据流图仅对部分指令建模,则n可以更大。例如,n可以是至少、至少或者至少。
57.通常,处理器子系统240可以由单个中央处理单元(cpu)来体现,但是也可以由这样的cpu和/或其他类型的处理单元的组合或系统来实现。处理器系统240可以以各种方式支持硬件加速指令。在一些实施例中,硬件加速指令是处理器子系统240的cpu的指令,例如,硬件加速指令可以在芯片上实现。在一些实施例中,如图中图示的,硬件加速指令可以由与cpu分离的硬件加速器241执行,该硬件加速器241例如是专用处理单元。硬件加速器241例如可以是协处理器;专用指令集处理器(asip);现场可编程门阵列(fpga);专用集成电路(asic);复杂可编程逻辑器件(cpld);或者任何其他类型的可编程逻辑。例如,硬件加速器241可以是vta加速器,如在t. moreau等人的“a hardware-software blueprint for flexible deep learning specialization”(在https://arxiv.org/abs/1807.04188可获得并且通过引用并入本文)中讨论的。
58.指令050可以调用硬件加速指令。处理器子系统240可以被配置为执行计算,所述计算包括例如通过调用硬件加速器241根据指令050调用硬件加速指令。因为使用了所确定的可能调用,所以可以改进计算效率。
59.可选地,计算可以是训练的机器学习模型(例如深度神经网络)的应用的部分。处理器子系统240可以被配置为经由传感器接口从传感器获得至机器学习模型的输入,传感器接口例如是图像传感器、激光雷达传感器、雷达传感器、压力传感器、容器温度传感器等。处理器子系统240可以被配置为将机器学习模型应用于输入以获得输出。基于该输出,控制数据可以被导出并经由致动器接口提供给致动器,该致动器例如是电动、液压、气动、热、磁和/或机械致动器。例如,系统200可以用于控制机器人、自主车辆等。
60.通常,本说明书中描述的每个系统——包括但不限于图1的系统100和图2的系统200——可以被体现为单个设备或装置或者被体现在单个设备或装置中,所述单个设备或装置诸如是工作站或服务器。该设备可以是嵌入式设备。该设备或装置可以包括执行适当软件的一个或多个微处理器。在这方面针对图2的处理器系统240给出的示例也适用于图1的处理器系统140。由处理器系统运行的软件可能已经被下载和/或存储在对应的存储器中,所述对应的存储器例如是诸如ram的易失性存储器或诸如闪存的非易失性存储器。通常,相应系统100、200的每个功能单元可以以电路的形式实现。将领会,除非另有说明,否则与图1的系统100相同的考虑和实现选项通常可以应用于系统200。
61.图4a示出了数据流图的详细但非限制性的示例。数据流是依据运算(计算可以被细分成所述运算)以及在这些运算之间的数据流关系的计算的表示。具体而言,该图可以包括节点和边。节点可以表示计算的输入和运算。边可以表示节点之间的数据流关系。这包括输入/输出关系(本文中称为顺序型边),但是也可以可选地包括其他类型的关系。除了这些节点和边,该图中还可能存在其他节点和边。数据流图通常是有向的,例如,包含至少一个有向边。数据流图可以是连通图,但这不是严格需要的。
62.出于说明的目的,该图示出了计算的数据流图。例如,该计算作为4
×
4矩阵乘法的一个输出元素的计算而发生。例如,该示例可以用作计算数据流图或指令数据流图,或者作为计算数据流图或指令数据流图的部分。圆圈表示图的节点。箭头标示图的边。
63.数据流图的一个或多个节点可以表示计算的输入。这些节点在本文中也被称为数据节点。通常,数据节点仅具有外向的顺序型边,例如,没有任何类型的传入边或其他类型的外向边。该图示出了与由该图表示的计算的相应输入x1、x2、x3和x4相对应的数据节点411、412、413和414;以及与相应输入y1、y2、y3、y4相对应的数据节点421、422、423和424。该图示出了对应于常数值0的另一个输入节点461。
64.数据流图的一个或多个节点可以表示计算的运算。这些节点在本文中也被称为运算节点。运算节点可以根据其执行的运算来标记。尽管数据流图本身可以用于表示任何类型的运算,但是通常,本文的运算通常是标量运算,例如,对固定数量的数值(例如,标量加法、标量乘法、标量除法、求反)或非数值(例如,按位“与”、按位“异或”、按位“非”等)执行的运算。例如,标量值可以是在内存中具有例如至多256、至多128、至多64或至多32位的固定大小表示的值。
65.通常,运算节点具有与该运算所消耗的数据相对应的一个或多个传入顺序边。例如,该图示出了运算节点431,表示输入x1 411和y1 421的标量乘法;运算节点432,表示输入x2 412和y2 422的标量乘法;运算节点433,表示输入x3 413和y3 423的标量乘法;和运算节点434,表示输入x4 414和y4 424的标量乘法。如在该示例中,运算可以是交换运算,在这种情况下,运算的输入的次序通常不明确表示;但是也可能的是例如通过标记传入的顺序边例如对于非交换运算表示输入的次序。
66.有趣的是,运算节点可以用来表示交换约简运算,诸如加法或乘法。例如,节点441表示其传入节点的加法,运算节点431-434和节点461表示运算的初始值。为初始值添加节点是可选的,例如,可以假设初始值,除非明确给出等于例如为零或一的运算的中性元素。运算的初始值可以被映射到计算的相等的初始值。使用单个节点441来表示该运算具有几个优点。它减轻了包括用于运算的单独成对应用的单独节点的需要,例如,将值431、432相加;将值433加到结果并将值434加到该结果。这增加了效率,并且还防止数据流图实施以特定次序执行的相加,例如,通过不准许通过首先将值433和434相加;然后加值432;并且然后加值431来确定总和。表示交换约简运算的节点可以用在指令数据流图、计算数据流图或两者中。
67.如该示例中所示,节点可以在图中被明确标记为表示交换约简运算。在该示例中,这是通过将自边451加到节点441来完成的。标记的其他方式也是可能的,例如,通过将节点标记为表示交换约简运算。该标记具有如下优点:它使得约束求解器更高效地确定用于交换约简运算的映射,例如,当选择将交换约简运算映射到哪个节点时,约束求解器可以能够比通过例如试图映射运算的输入更容易地丢弃不具有自边的节点。
68.在指令数据流图中而不是在计算数据流图中使用交换约简节点的情况下,使用自边来标记交换约简运算特别方便。例如,当将指令数据流图的交换约简节点a映射到计算数据流图的对应节点b时,自边可以在约简运算的后续应用之间映射到计算数据流图的对应边。实施存在这样的对应边可以使得其更容易地检测两个图之间的映射。
69.运算节点可以为使用该运算结果的其他运算产生一个或多个外向的顺序边。对于其他运算不具有外向的的顺序边(但是对于其自身可能有外向的自边)的节点可以表示由图表示的计算的输出。例如,节点441可以表示输出。因此,在数据流图中,输出可以等同于产生输出的运算。也可能的是例如通过标记来明确标记输出。输出节点可以用例如表示输出的形状和/或数据类型的附加信息来标记,该附加信息可以用于在计算和指令之间匹配。
70.可选地,数据流图的成对运算可以被标记为是可相互并行化的。这可以通过例如在节点对之间加边来完成(在该图中未示出)。这样的边在本文中被称为空间边。特别地,例如对于不同的输出元素,可以在执行相同运算但在计算的不同部分中的节点之间加空间边。如本文所述,空间边可以再次用于帮助约束求解器将可相互并行化的运算映射到可相互并行化的运算。
71.对于可相互并行化的运算集,通过仅包括边集的子集,可以实现空间边数量的减少以及因此效率的改进。例如,不是让k个节点的集合通过空间边完全连接,而是可以通过修剪连接同时维持相同的连接分量来减少边的数量。例如,可以选择星形配置,其中一个内部节点通过空间边连接到k-1个叶子。通过传递性,可以维护可并行性信息。
72.数学上,如本文使用的数据流图可以例如被形式化为标记的有向图,定义为
,其中n是节点集合,有向边集合是,并且是从集合中赋值标签的函数。是节点标签类集合,其例如保持张量形状、数据类型和/或算术运算。是边标签集合。
73.在各个方面中,被称为计算数据流图的数据流图可以用于表示计算。被称为指令数据流图的数据流图可以用来表示指令。这些数据流图可以表示计算或指令的完全输入/输出行为,其例如包括计算或指令的所有输入和输出以及对输出如何跟随输入进行建模的节点。在一些情况下,也可能的是仅对计算和/或指令的子集建模。例如,指令数据流图可以仅表示用于计算其输出子集的运算和/或输入,其中输入、运算和/或输出的剩余部分如其他地方所述通过外推法来确定。
74.也不需要由计算或硬件加速指令明确地执行图的运算,例如,加法和乘法可以在指令数据流图中单独建模,而它们由硬件通过组合的乘法和加法来执行。因此,表示指令或计算的中间结果的节点不一定对应于在指令或计算期间的某个点显式计算或存储的值。然而,在实现中,输入和输出通常被显式地计算。
75.在各个方面中,使用定义数据流图的数据,该数据流图例如是计算数据流图或指令数据流图。通过“定义”数据流图,意味着节点和边的集合从数据可导出,或者至少给定一个节点或边,可以确定该节点或边是否属于该图。特别地,数据本身不一定包含与个体节点和边相对应的显式数据项。例如,也可能的是象征性地定义节点和边的集合,如也关于图4b所讨论的,或者可以隐式地定义边,例如,通过给出不具有边的节点对,某一类型的边的存在可以由数据定义,等等。各种替代方案是可能的。
76.图3示出了如何使用硬件加速指令实现计算的详细但非限制性的示例。
77.图中示出的是指令数据流图(dfg)idg 330,其表示硬件加速指令,换句话说,硬件加速指令执行的功能或计算。例如,指令dfg idg可以如关于图4a所述。特别地,图idg的节点可以表示硬件加速指令的输入和运算。
78.图中还示出的是计算dfg cdg 340,其表示例如如在图4a中使用硬件加速指令实现的计算。图cdg的节点可以表示计算的输入和运算。指令数据流图idg和计算数据流cdg图是不同的,例如,没有共同的节点或边。
79.指令和计算dfg是两个不同的图,每个图可以由相应的计算和指令数据(未示出)来表示。如所讨论的,该数据可以隐式或显式地定义图的节点和边,例如,允许枚举节点和边或者至少测试节点和边集合的成员资格。图idg、cdg通常在相同的运算集合上定义,例如,具有相同的粒度。这使得将两个图的运算彼此映射变得更容易并且因此更高效。
80.在定义运算def 355中,指令和计算dfg(idg、cdg)可以用于定义约束满足问题csp 360。对该问题csp的解可以表示在计算中硬件加速指令的可能调用。
81.如本身已知的,约束满足问题csp通常由变量集var 361;用于相应变量的相应域集doms 362;和集约束cons 363定义。在数学上,约束满足问题csp可以用三元组(x,d,c)来表示,其中:是变量集,针对其问题是找到一个值。是值域集,值可以从所述值域集赋值给相应的变量。赋值
可以为选择取得一个值。因此,变量可能被限制为仅从域取值。是约束集。约束可以在变量的子集上形成,并且评估是否用的所有赋值都有效。
82.对约束满足问题csp的解可以是赋值给所有变量的赋值,并且其中没有赋值违反约束c的合取。
83.约束满足问题csp可以表示通过将计算数据流图cdg的节点映射到指令数据流图idg的节点,在计算中找到硬件加速指令的可能调用的问题。变量集合var可以包括用于指令数据流图的每个节点的变量。计算数据流图的每个节点可以被包括在至少一个变量的域dom中。约束集cons可以包括数据流和输入约束。例如,约束的数量可以是指令数据流图的节点数量的至少10倍、至少100倍或至少一倍、两倍或五倍。
84.因此,将指令嵌入到计算中可以有效地在标量级描述。有趣的是,指令中的节点和计算中的节点之间的每个潜在赋值都可以表示为图的节点之间的映射,因此该公式可以用于捕获对嵌入问题的每个可能的解。匹配问题本身不束缚于隐式实现决策,像张量或访问函数的内存布局或者循环排序。这移除了对于在搜索中计及这些决策的变换的需要。取而代之,此类变换可以从嵌入的结果中导出这些。
85.特别地,对于指令dfg idg的每个节点,例如,变量可以包括在变量集vars中。因此,硬件加速指令中的每个标量运算和数据元素可以由变量表示。域集doms可以被定义为。这里,可以包括计算dfg cdg的所有节点,或者包括所有节点集合的子集,例如,具有与节点d相同运算的所有节点的子集,等等。然而,也可能的是通过约束来施加后一种限制。域可以包括例如与虚拟运算或输入相对应的附加值。
86.给定变量vars和域doms,约束集cons可以用来表示赋值可以满足的条件,以便表示硬件加速指令的可能调用。
87.可以由约束cons实施的重要方面是指令数据流图idg的节点的数据流等效于它们被赋值到的计算数据流图cdg的节点的数据流。例如,取由赋值的节点给出的计算流图的部分,并用指令数据流图的节点替换它,可以产生具有相同输出的计算的数据流图。实施该等效的约束可以称为数据流约束。
88.特别地,数据流约束可以实施指令数据流图idg同构于由约束满足问题csp的解所诱导的计算数据流图cdg的子图。在这种情况下,用指令数据流图替换计算数据流图的映射子图可以产生在节点之间的连接和节点标记方面相同的图。然而,严格同构可以用本文描述的几种方式来放松。
89.为了实施等效,对于指令数据流图的边,表示其数据流的一个或多个约束可以被包括在数据流约束中。在数学符号中,给定指令dfg 和计算dfg
ꢀꢀ
,数据流约束可以要求对约束满足问题csp的解表示单射函数,该单射函数描述中与匹配(例如:)并且维持标记(例如)的节点和边的不同子集。单射性可以通过要求计算
数据流图的每个节点在解中仅存在一次来实施。实施此的全局
“”
约束可以包括在数据流约束中。
90.例如,以下伪代码可以用于对数据流建模:
91.数据流约束可以实施将硬件加速指令的可相互并行化的运算对映射到计算的可相互并行化的运算对。在该示例中,这是通过在相应的数据流图idg、cdg中包括空间类型边,并实施指令数据流的空间边映射到计算数据流图的空间边来完成的。如所讨论的,包括针对在可相互并行化的运算集合中的每一对的约束可能导致大量的约束。可以利用成对约束的传递特性来避免此。不是针对集合中的每个对实施可相互并行性,而是可以仅针对对的子集实施可相互并行性。特别地,如果子集具有作为传递闭包的全集,则对于该全集来说,可并行性仍然可以是隐式的。例如,可以选择指令dfg中的任意第一个节点,并且可以向它所具有的每个并行节点添加约束。如果平行于第一节点的任何节点被赋值了值,则第一节点的域可以被修剪以仅包含平行于被赋值的节点。这可以传播到与第一节点平行所有其他节点。因此,可以高效地修剪相同数量的值。
92.在求解约束满足问题csp时,可以用来自变量vars的相应域doms的值给变量vars赋值。在求解期间,计算数据流图cdg的节点可以被选择作为指令数据流图idg的节点的可能值。约束求解器可以应用所谓的传播算法,该传播算法试图给变量赋值,并检查约束cons是否允许该赋值和/或该赋值是否根据约束而实施给其他变量vars赋值。下面是用于实施数据流约束的示例传播算法。给定节点s,值被赋值给该节点s,并且该节点s具有到另一个节点t的边,该示例算法检查对s的赋值是否正确,以及什么正确的值可以被赋值给另一个节点t:
93.在该示例中,传播器直接基于t中节点之间的关系过滤值。它评估关系(“evaluate_relation(评估_关系)”),并从实施不存在连接的伙伴节点域(“t.intersect”)移除值。如果该对之间的关系是函数关系,则它可以直接指定一个解(
“”
)。即使不是这种情况,所示的传播也足够强大以归入域,这意味着域中仅保留该约束的有效解,并且不需要进一步传播。剩余的域值相对于其变量上的其他约束进行评估。如果传播导致空域,则赋值失败。
94.当值被赋值给指令数据流图idg的节点s和t二者时,约束可以通过验证在计算数据流图cdg中存在连接该对的边来检查正确性,例如。特别地,这可以涉及实施将表示交换约简运算的指令数据流图idg的自边映射到计算数据流图cdg的自边。
95.不需要的是数据流约束实施严格的同构。可以采用各种放松。例如,不是要求将指令数据流图idg的源运算映射到计算数据流图cdg的相同目标运算,而是要求源运算是目标运算的推广就可以是足够的,例如,至少具有目标运算所需准确度的运算,或者可以由源运算实例化的运算。同样如在其他地方所讨论的,可以采用放松来使得能够将指令数据流图的交换约简运算映射到表示交换约简运算的单个约简的计算数据流图的节点。不实施严格同构的另一个示例是使用虚拟运算,这同样如在其他地方所讨论。
96.如发明人所意识到的,为了定义什么构成了计算中硬件加速指令的可能调用,在许多情况下,借助于数据流约束来定义数据流的等效是不够的。也就是说,如图中所示,硬件加速指令和/或其编程接口可以对可能调用施加硬件限制集hwr 320。定义def约束满足问题csp可以包括定义表示这些硬件限制的一个或多个约束cons。硬件限制hwr可以以各种方式表示,例如表示为约束,表示为当定义约束满足问题时从其实例化约束的模板,表示为基于指令和/或计算数据流图隐式地定义约束的代码等。
97.特别地,硬件限制可以施加一个或多个输入约束,所述一个或多个输入约束限制了计算数据流图cdg的哪些节点可以被赋值给硬件加速指令的输入,例如,可以被赋值给指令数据流图idg的输入节点。例如,这样的约束可以实施输入具有允许的内存布局和/或允许的访问模式。也可以对硬件加速指令的输出设置类似的约束,例如,如果输出将用于另一个计算中或当前计算的需要特定内存布局的其他部分中的话。除了指令施加的限制之外,还可能的是包括用于获得具有其他期望特性的调用的限制,例如,使用输入数组的第一个元素的调用等。这可以更容易地推广找到的调用,以生成用于完全计算的代码。通常,合适的约束集cons可以至少取决于硬件目标和可用的代码生成方法。
98.例如,约束cons可以包括以下各项中的一个或多个:-将输入限制在允许的内存访问模式;例如,输入访问模式可以限于模板计算,或者具有规则步幅和/或偏移的访问模式;传播可以将这样的维度中的值束缚到零,这可以在存在这些访问模式的计算中移除大部分搜索空间;-在计算中将映射指令输入限制到特定轴;-限制指令应用于计算中的某些值;例如,通过将指令中的第一输出限制为计算中的第一输出元素,搜索可以将搜索固定为在这些点周围的值。
99.有趣的是,包括附加的更多约束可能使解空间更具体,而放送约束可以作为实现策略探索的工具。约束求解是有益的,因为它在程序表达式中提供了表述性,并且具有可定制的传播和搜索算法。
100.约束满足问题csp可以用这样的方式定义:硬件加速指令的运算可以被映射到不影响计算的虚拟运算。实际上,可以获得指令在计算中的“不完美”(例如,非同构)嵌入。这可以允许找到调用,否则这是不可能的。例如,可能不可能的是将计算均匀划分成由指令计算的更小的子问题。允许虚拟运算使能在这样的情形下还使用硬件加速指令。例如,对于16
×
16矩阵乘法,可以用硬件加速指令来执行8
×
8矩阵乘法。该指令可以通过填充输入和输出张量来使用:然后形状可以匹配指令,并且可以使用指令。通过以下各项的任何组合,可以在约束满足问题中允许虚拟运算:允许或约束重叠/重复计算;允许或约束重叠/重复的内存访问;以及允许或约束将虚拟值插入到计算中。通常,作为虚拟值,包括运算的神经元素,使得计算的结果不受影响,例如,零(例如,用于加法)或一(例如,用于乘法)。这些值可以被加到相应变量的域dom中。
101.还可能的是将约束包括到约束集cons中,以使约束满足问题csp更容易,并且从而更高效地求解。例如,可以通过对指令数据流图idg的具有相同域的变量组——例如描述指令输出运算的所有变量——应用修剪约束来减小变量组的域大小。例如,域的范围可以用向量来描述,例如,来描述,例如,可以标示边长为4的立方体。因此,立方体中的坐标可以描述为,其中。因此,通过设置上限,例如设置,可以控制域的范围。例如,以下一元修剪约束可以用于通过以下方式为g中的所有变量设定m维域中所有维的大小的阈值:其中是赋值给该组的变量数,并且是一维的大小。还可能的是将变量组的域坐标限制到任何其他阈值,例如限制到指令维度的长度,等等。修剪约束是降低搜索空间的低开销约束。
102.因此,约束满足问题csp可以将计算数据流图的节点赋值给指令数据流图的节点。在一些实施例中,计算dfg的一个节点被赋值给指令dfg的每个节点。在一些实施例中,向指令数据流图的每个节点赋值计算数据流图的节点或表示虚拟输入或运算的节点。在一些实施例中,给指令dfg的每个节点赋值不同的值,例如,最多可以给计算dfg的每个节点赋值一次。
103.图中还示出了运算solve 365,该运算solve 365接受约束满足问题csp并求解它以确定计算中硬件加速指令的可能调用inv 370(如果它存在的话)。调用inv可以将指令数据流图idg的节点映射到计算数据流图cdg的节点,如图中从指令数据流图idg的节点b、c、d去往计算数据流图cdg的节点b、c、d的虚线箭头所图示。在该示例中,调用inv的几个合期望
的特性被说明。如所图示的,指令数据流图idg的每个节点可以被映射到计算数据流图cdg的节点;然而,计算数据流图通常具有附加的节点:该示例中的节点a和e。指令数据流图idg的相应节点之间的边的存在可能意味着它们被映射到的计算数据流图cdg的相应节点之间的边的存在;但是可以存在附加的边,其在该示例中例如是节点a和c之间的边以及节点d和节点e之间的边。然而,指令数据流图的非输入节点(例如节点d)通常被映射到计算数据流图的节点(例如节点d),其具有相同数量和/或类型的传入边。
104.为了执行求解运算solve,各种约束编程技术本身在文献中是已知的,并且可以在本文中应用。有趣的是,约束求解器用来寻找对问题的解的算法在许多情况下可以定制。这允许在解空间之上进行控制,例如,对某些解进行优先级排序,而不改变解有效与否意味着什么。特别地,许多现有的约束求解器solve允许传播算法、变量选择策略和/或值选择策略的定制。
105.传播器可以用于从域doms移除不能成为有效解的部分的值。传播器在它从域中移除但不添加值的意义上可以是单调过滤算法。传播器通常特定于每个约束cons。传播器可以基于相同约束下的域doms和其他变量赋值来推理从域移除哪些值。为了找到解,求解器solve可以使用搜索算法来系统地执行赋值,并通过域doms传播赋值。在本说明书中的其他地方给出了用于实施数据流约束的示例传播算法。
106.求解器solve在许多情况下使用基于回溯的搜索算法来寻找给定问题中的所有可能的解。这可能涉及变量选择策略,该变量选择策略确定变量集vars中的哪个变量接下来被赋予值。值选择策略可以确定以何种次序搜索变量的域,例如,它可以被视为的特定实现。变量和值的选择影响求解时间,并且还影响解输出所用的次序。因此,通过优化值和变量选择策略,可以影响求解的效率和确定的解的质量二者。
107.对于变量选择策略,最好使用通过指令数据流图向后传播的策略。可以首先选择输出,并且然后求解可以沿着图向后行进。已经发现,该策略对于例如神经网络层评估的相关计算具有最大的传播潜力。
108.对于值策略,一个示例是使用字典式(lexicographic)搜索。在许多情况下,可以基于关于硬件加速指令的输入数据的结构的附加信息来优化值选择策略。例如,在许多情况下,硬件加速指令可以具有多维输入,并且指令可以应用的值也可以具有多维。在这样的情况下,作为值选择策略,可以使用投资组合(portfolio)搜索策略。在这样的搜索中,并行搜索多个所谓的资产,每个资产提供把值赋值给变量所用的次序。不同的资产可以对应于硬件加速指令的维度和可能的输入值的维度之间的不同映射。资产可以根据其相应的维度映射对赋值进行优先级排序。可以并行搜索这些不同的资产,导致在宽范围的计算之上搜索持续时间的稳定。
109.有趣的是,当使用投资组合搜索策略时,通过限制指令的哪些维度可以映射到计算的哪些维度,可以限制可能资产的数量。这取决于手头的指令和计算,并且可以通过例如手动注释来执行。例如,指令和运算的维度可以被分区为例如用于矩阵乘法的约简维度和非约简维度。在投资组合搜索策略中,运算的约简维度然后可以仅映射到计算的约简维度,并且对于非约简维度类似。这样,资产的数量可以得到显著限制,从而改进性能。例如,在之上的矩阵乘法具有两个空间维度和一个约简维度。值选择策略可以尝试在计算中的维度和矩阵乘法的维度之间直接嵌入。在资产中,搜索可以对三个所选维度
进行优先级排序。如果是空间维度数并且是计算中的约简数,则资产数可以是。与个域的可能排列相比,这是显著的约简,否则所述排列可以是可能的。例如,在资产内,字典式搜索可以用作值选择策略。
110.如果求解器solve未能在这些初始投资组合中找到解,则搜索空间上的约束可以被放松,并且搜索可以用更宽的解空间重复进行。
111.通常(并且代替或附加于当使用如上面讨论的投资组合搜索时进行重复搜索),如果求解器solve未能找到对约束满足问题csp的解,则约束满足问题csp可以被放松,并且求解solve可以被重复,例如,直到已经找到解或者没有更合适的放松可用。例如,可以放送约束满足问题以允许虚拟运算,可以放送实施使用特定输入的约束;等等。这样的放松可能导致不太理想的解,例如,运算中的较少运算被优化,或者需要更多的预处理来取得由硬件加速指令可处理的正确形状的数据,但是通过执行这些放松,可以使得硬件加速指令也可以应用于这样不太理想的情形中。
112.图中还示出的是可选的编译运算comp 345,其可以使用所确定的调用inv来生成实现计算的机器可执行指令instr 350。指令instr可以根据确定的可能调用inv调用硬件加速指令。例如,调用inv可以用于生成可编译的代码,然后编译该可编译的代码以获得指令instr。用于从特定硬件加速指令的调用编译inv生成代码的规则通常取决于所提供的代码生成接口。通常,根据编程接口如何允许调用硬件加速指令,通过在约束满足问题csp中包括足够的输入约束,可以相对直接地完成将调用inv转化为指令instr。
113.在一些实施例中,指令数据流图可以包括仅硬件加速指令的输出子集的节点。为了生成机器可执行指令instr,调用inv可以用于推理硬件加速指令的一些或所有剩余输出到计算运算的映射。因此,硬件加速指令可以应用于比可能调用inv的映射所指示的更大部分的计算。例如,在矩阵乘法中,输出元素的计算与其邻居共享输入节点集,但没有中间结果。因此,调用inv可以仅为一个输出元素提供映射,然后可以通过使用该映射来实现计算的完全矩阵乘法来推广该映射。
114.有趣的是,生成指令instr还可能涉及将所确定的调用inv推广,以获得硬件加速指令的进一步调用。对于包括诸如卷积之类的神经网络工作负载的许多实际计算,可能的是从单个确定的调用inv外推出具有多个调用的计算实现。为此,可以从所确定的可能调用inv提取一个或多个特征,基于所述一个或多个特征特征,可以推广所确定的调用inv。例如,计算comp可以完全通过这样调用硬件加速指令来实现。
115.例如,对于卷积,可以评估与指令数据流图idg的输入和输出值相关联的计算数据流图cdg的变量,以计算指令的哪个维度与工作负载中的哪个维度相匹配,以及平铺因子是什么。由此,可以实现实现完全卷积的指令instr。例如,匹配的维度可以由找到的因子平铺,并移动到最里面的维度。这些平铺和重新排列对于嵌入可能是固定的。对于进一步的性能优化,其他循环和张量维度仍然可以是可变换的,可以应用例如循环平铺、重新排序、融合等。这样进一步的性能优化可以使用autotvm或类似工具自动确定。例如,具有硬件加速指令的嵌入式调用的指令instr可以由tvm的vta编程工具流生成。
116.还示出了可选的评估运算eval 355。在许多情况下,约束求解器solve能够确定求解约束满足问题csp的多个调用inv,例如,枚举对约束满足问题csp的所有可能的解。在评
估运算eval中,可以评估多个这样的调用的性能,并且可以基于该性能评估从多个解选择解。可以基于所确定的机器可执行指令instr来执行评估,例如,通过执行或模拟指令并测量性能;或者通过在没有首先确定指令instr的情况下直接在调用inv上计算(通常是硬件特定的)成本函数。
117.通常,本文描述的技术可以应用于各种类型的计算和硬件加速指令。硬件加速指令可以实现矩阵乘法、卷积、点积、矩阵向量积、累积和、池化和哈达玛积中的一个或多个。该计算可以包括例如卷积运算符、乘法或神经网络层的池化运算的评估。
118.通常,至少硬件限制hwr取决于目标硬件,而计算数据流图cdg取决于将被执行的计算。因此,例如,可能的是通过使用相同的指令数据流图idg和硬件限制hwr将所提出的方法应用于多个不同的计算数据流图cdg来确定多个计算的实现;并且通过使用相同的计算数据流图cdg和多个不同的硬件限制hwr和/或指令数据流图idg应用所提出的方法来确定相同计算的多个实现。
119.图4b示出了定义数据流图的多面体表示的详细但非限制性的示例。在各种实施例中,计算数据流图或其的部分可以由多面体表示来表示。
120.如例如关于图3所讨论的,可以通过求解约束满足问题来确定计算中硬件加速指令的可能调用,其中计算数据流图的节点被赋值给指令数据流图的节点。在许多实际情况下,计算数据流图的节点数量可以相当大,例如,至少1024个、至少4096个或至少104876个节点。然而,有趣的是,发明人意识到,通过使用多面体表示来存储计算数据流图或其至少一部分,可以避免显式地确定和存储计算数据流图的所有节点和/或边的列表。这改进了约束求解器的性能。
121.通常,在多面体表示中,数据流图的集节点被象征性地表示,例如,使用描述了哪些节点在该集中而不显式地枚举它们的表示。也可以象征性地表示边集,例如节点集的传入和/或外向边。当求解约束满足问题时,可以通过实例化多面体表示、例如通过根据如本文描述的值选择策略来选择节点,从而获得来自节点集的特定节点。指令数据流图的节点然后可以被映射到该实例化的节点。
122.作为示例,该图使用多面体表示以图形方式表示数据流图。如在图4a中,表示了4
×
4矩阵乘法,例如张量表达式
。该计算可以表示为循环嵌套:。
123.输入张量可以用它们的形状集来描述。例如,图中所示的是数据流图的输入节点集的多面体表示x,410。该集对应于例如包括图4a的节点411-414的集合,并且可以由如下集合来描述。
124.还示出了数据流图的另一输入节点集的多面体表示y,420,其包括图4a的节点421-424。该集合可以描述为:。
125.矩阵乘法计算的标量乘法运算可以由多面体表示* 430表示,多面体表示* 430例如包括图4a的乘法431-434。矩阵乘法计算的标量加法运算可以用多面体表示 440来表
示,多面体表示 440例如包括图4a的加法441。标量乘法和加法一起可以用如下集合来表示:,i,j,k是域边界。s还包含描述选择了原始张量表达式t的哪个元素的附加维度,其例如在这种情况下为节点是表示加法还是乘法。
126.数据流图的节点集可以形成为由多面体表示定义的集合的并集,例如。
127.数据流图的节点之间的边集也可以由多面体表示来定义。多面体表示可以对应于两个域之间的二元关系。如果存在的关系,则在两个实例之间存在边,例如数据流。
128.例如,在图4b中,相应节点集410、420、430、440之间的边可以由以下关系定义:
129.在上面的示例中,关系r1指定乘法和加法发生在同一个循环迭代中,但是按照它们在张量表达式t中的位置来排序。r2可以被解释为在迭代维度k中顺序发生的两个加法运算。a
x
和ay对访问函数本身进行编码,并且由哪个节点执行访问,在这种情况下是t中的乘法。所有关系的并集可以描述数据流图的边,并且对于示例具体地是。
130.在该示例中,节点集440和对应关系r2用于表示交换约简运算,在该示例中是加法。如关于图4a所讨论的,在指令数据流图中,这样的交换约简运算可以由例如图4a的节点441的单个节点表示。在这样的情况下,指令数据流图的节点441可以有效地对应于计算数据流图的节点集440。实际上,关系r1可以对应于节点441的传入非自边,而关系r2可以对应于自边。在这种情况下,约束满足问题可以被配置为允许节点441被映射到节点集440中的任何节点。为了适应将交换约简运算映射到节点集440的节点,控制约简次序的项可以被放松,例如,在r1和r2中的的项可以被放松,使得它不确定约简的任何排序。通过该放松,集合440的每个节点可以有效地被视为交换约简节点。有趣的是,尽管该放松大大增加了图中的边数,但它可以使用多面体表示来高效地实现,因为它不需要完全实例化计算数据流图。替代地,当使用多面体表示时,交换约简运算也可以表示为单个节点。
131.数据流图的节点和/或边的标签可以被提供作为集合的公共标签,或者例如象征性地定义的单独标签。标签可以指示输入或输出的类型;运算类型等。例如,节点410可以被标记为
“”
;节点420标记为
“”
;节点430标记为
““”
;并且节点440标记为
“”
。
132.在多面体表示法中也可以指示可相互并行化的运算对。例如,也如关于图4a所讨论的,可以通过空间边来指示可相互并行化的运算对。这样的边集也可以用多面体表示来表示。
133.关于描述边集的关系,可能出现几种情况。所述关系中的一些或全部可能不对称。
诸如该示例中的关系的一个或多个关系可以是满射的和函数的,例如,乘法可以映射到它所消耗的x中恰好一个张量元素。诸如关系的一个或多个反向关系可以是非函数的,例如,x中的输入元素可以被多个乘法但不是他们的全部使用。这可以通过a
x
和ay的关系来观察,因为它们不包含分别具有或特性的项。对于x中的一个特定输入值,该关系可以描述使用该值的所有乘法的子集。
134.通常,由多面体表示定义的数据流图的运算集s可以被称为实例集,其中元素被称为动态执行实例。集合s可以由整数元组集来描述,其中整数元组描述动态执行实例,例如节点。例如,为了描述整数元组集,可以使用以下表示法:。
135.例如,相应的项可以提供相应元组成员的固定下限和/或上限。因此,所有项的合取可以定义全集。约束满足问题的域可以被定义为例如由节点类型定义的整数元组集的子集。对于输入节点,域可以由相应张量形状的元组集来描述。对于运算节点,域可以是表示运算的元组集,或者其子集。
136.实例对之间的二元关系的并集,例如图的顺序边,有时也称为数据依赖关系d。从源集到目标集的元素之间的关系可以标示为:其中项描述了关系中的条件。目标元组中的元素可以标示为。关系条件可以用于描述映射到目标集中元素的源元素e。所有项的合取可以描述整个关系域。
137.多面体表示的使用对于诸如卷积、矩阵乘法或池化运算之类的作为神经网络层评估的部分的计算特别有益。此类计算通常在例如n维数组的张量上运算,所述张量的边界在编译时是已知的。通常,不同的输出元素以相同的方式计算,但输入值具有不同的切片。计算通常还涉及没有条件语句的深度循环嵌套,并且是高度结构化的。这使得使用多面体表示来表示它们特别高效。
138.有趣的是,如本文所述,在约束满足问题中使用多面体表示不招致一般性的丧失。将指令映射到计算仍然在个体节点的级别、例如在标量级别完成。约束求解器可以将来自所描述的节点集的任何计算数据流图节点赋值给指令数据流图节点,而不管该集是如何描述的,例如,不管维度的次序如何。这与将显式变换应用于多面体表示的其他方法不同,在这种情况下,描述集的方式包含难以克服的建模假设。
139.图5a-5d示出了应用超矩形约束的详细但非限制性的示例。在各种环境中,限制硬件加速指令的输入以形成规则的形状是有益的。这可以导致具有更高效的内存访问的实现,和/或对于所述实现,高效的内存布局变换可用于允许硬件加速指令在输入上被调用。特别地,该示例示出了可以如何使用超矩形约束集来实施输入形成超矩形。
140.本文使用的术语超矩形通常指代具有任何维数的矩形,例如n=1、n=2、n=3或。点可以在超矩形上布置成正方形网格,例如对于形成点集形成点集,其中是步幅,每个步幅可以被单独固定,例如设置为一或者被动态确定。
141.例如,超矩形的使用适合于在神经网络评估中出现的计算,因为此类计算通常涉及(通常大的)张量,例如n维阵列。超矩形形状对于高效的内存访问特别有益,并且使能通过使用内存布局变换(例如,张量维度的转置或平铺)来高效地调用硬件加速指令。约束可以用于确保赋值给解的输入值的变量形成超矩形,例如,与张量空间的向量基对齐的超矩形。另一个优点是,约束输入以形成超矩形可以允许约束求解器相对容易地消除对指令数据流图的输入节点的潜在赋值,这可以大大改进约束求解的效率。
142.超矩形约束可以被配置为匹配和传播来自点的有序元组具有维数的超矩形形状,其例如对应于硬件加速指令的输入。该约束可以被配置为从迄今为止计算的值被赋值到的输入点集合以及从v中的点的总数来推理边界框。边界框之外的值可以被消除为硬件加速指令的剩余输入点的可能值。因此,在已经进行几个赋值之后,通常可能的是消除域的大部分。例如,在沿着张量的一个轴仅选择了两个点之后,该维度可以被限界在的大小。
143.可以通过执行点集v的线性迭代来计算矩形,包括迭代地尝试推理点是否创建了具有任何数量的任意维度的矩形。特别地,如果点按照字典式次序描述了网格,则迭代可能涉及执行以下步骤之一。基本步骤可以表示从最里面维度中的一个元素到下一个元素的移动。维度跳转可以表示移动到最里面维度的下一行,例如,对角地移动通过空间。为了实施网格结构,在维度跳转发生之前,基本步骤可能需要是相同的,并且重复固定次数。维度跳转可以给矩形添加新的维度。对于维度,可能要求发生次,其中。维度跳转可以具有由向量定义的形状,这可能需要与相同,其中是v中的第一个点,并且是按整数因子缩放的张量基向量之一。通过将限制为向量基的元素,可以确保角上存在直角并且矩形是轴对齐的。
144.图5a-5d示出了实施超矩形约束的示例,该超矩形约束在点集上实施网格结构。该图示出了可以如何实施和传播约束的示例。在图中,实心点512、522、532表示域值;交叉511、521、531、541表示对16个变量之一的选择;空点533、543表示通过传播移除的值。
145.在该示例中,在前4个步骤中,可能还没有可能传播(图5a-5b),因为沿着x轴的维度大小8小于变量总数16。然而,一旦选择了第五个值,就可以从域移除值。在该示例中,的值可以被移除,因为这是最里面维度的大小,并且对于每个外部维度都必须相同。从为第五个变量选择的值(1,0)中,传播器可以推理扩展到y维不能大于:。
146.在该示例中,这是。因此,可以消除点533(图5c)。剩余的点被映射,如图5d中所示。
147.有趣的是,通过在点集v之上迭代来实现超矩形约束,所获得的约束对于指令和工作负载之间的相对维度排序可能是透明的。结果,工作负载中的任何维度可以被映射到指令中的任何维度,而例如不必执行转置运算。有趣的是,该映射可以用于导出例如转置、平
铺、融合等之类的哪些内存变换在生成调用硬件加速指令的代码中使用。
148.接下来提供了超矩形约束实现的详细示例。该算法也适用于部分赋值的矩形。推理期间发现的信息可以通过计算边界框而直接用于传播剩余值的域,该边界框是可以由未完成的赋值形成的最大可能矩形。
149.该算法从查看第一步骤开始,并且如果它没有轴对齐,则它返回失败。然后,它从向量移除所执行的步骤,使得每个张量维度被使用一次。然后迭代剩余的点,并且每个步骤都制成表格。记录正在采取的步骤。一旦维度跳转到发生,为执行的步骤数就被记录在中。检查正在发生的每个步骤是否它已经被记录。如果它已经发生,则检查该步骤是否在正确的时间发生,并将所有计数器重置为内部维度。在图5的示例中,对于y维度中的每个步骤,在x维度中需要存在四个步骤。一旦y步骤发生,x的计数器就被重置。
150.。
151.现在提供实验的细节,其中所讨论的技术被应用于为vta硬件加速器生成代码,该vta硬件加速器提供硬件加速的矩阵乘法(gemm)指令。硬件在上实例化,具有256kb权重缓冲区、128kb数据缓冲区和消耗int8输入并产生float32结果的gemm内核。gemm单元用计算计算。其结果可以例如由矢量-标量单元处理,用于激活和量化运算。注意,矩阵操作数b是转置的。硬件具有用于矩阵操作数的独立内存访问的加载/存储单元。它可以加载和存储连续存储在内存中的全2d操作数矩阵。实验使用了来自百度deepbench推理基准的计算。
152.将根据本技术生成的代码与tvm的conv2d参考实现进行比较,后者将gemm单元的三个轴x、y、z静态映射到卷积中的批量、输出通道和输入通道维。tvm卷积实现期望nchw(n =批量大小,c =通道,h =高度,w =宽度)的内存布局。
153.在实验中,使用tvm机器学习编译器框架生成机器可执行的生成。当tmv遇到可以通过硬件加速的运算符时,实现由指定的部署策略处理。一种策略在针对硬件目标优化的tvm的ir中实现运算符。tvm针对vta的代码生成工具流程可以通过将我们的方法集成到vta的策略中来使用。指令dfg 是基于硬件配置生成的。基于此,约束满足问题如所述定义。的节点是变量,运算符的动态实例集形成了域。
154.在一个实验中,约束求解器用于确定类似于参考实现的可能调用。为此,使用了以下约束:-用于匹配gemm指令数据流的数据流约束;-超矩形约束,确保输入和输出元素映射到轴对齐的形状,从而允许基于转置和整形运算的更简单的内存变换;-约束,防止同一个动态执行实例在同一个指令调用中多次出现。-固定原点约束,实施所有输入和输出张量的第一匹配固定到相应域的原点;-稠密性约束,不允许输入和输出张量在任何维度上的步幅;-内存访问约束,仅允许工作负载维度与匹配指令的访问模式(例如没有步幅或模板模式)相匹配。
155.给定计算,约束求解器可以用于获得描述指令的每个运算和数据元素如何映射到计算的节点的可能调用。由于像卷积的dnn工作负载的规律性,因此将找到的调用外
推到重复调用硬件加速指令的实现是可行的。在该解中,评估与输入和输出值相关联的变量,以计算指令的哪个维度与工作负载中的哪个维度相匹配,以及切片因子是什么。该信息允许生成代码。匹配的维度用找到的因子平铺,并移动到最里面的维度。这些平铺和重新排序对于嵌入是固定的。其他循环和张量维度被自由变换,以进一步性能优化。这些优化包括循环平铺、重新排序或融合。autotvm用于自动确定每个conv2d层的最佳优化参数。具有嵌入式指令的代码是由tvm的vta编程工具流生成的。
156.实验表明,可能的是自动生成与专家做的参考实现具有相似结构和性能的实现。有趣的是,对于一些基准计算,基于确定的可能调用生成的代码与参考实现相比实现了显著的加速。也就是说,对于一些基准计算,参考实现由于其静态嵌入策略而实现了非常低的硬件利用率。对于这些计算,实现了高达
×
2.49倍的加速,并且对于个体运算符,观察到高达
×
238的改进。因此,在这些场景中,根据确定的调用自动生成的代码提供了显著的性能改进。
157.在另一个实验中,所提供的技术被用于动态改变dnn的计算张量布局。对约束满足问题的解指示哪些维度是必需的,并且因此哪些维度是空闲的,从而允许在代码生成期间改变空闲维度的内存布局。在本实验中,约束求解器用于根据nhwc(n =批量大小,h =高度,w =宽度,c =通道)布局生成可能调用。在许多情况下,与参考实现所使用的nchw布局相比,这被发现改进了性能。
158.在另外的实验中,与先前的实验相比,内存访问约束被放松了。这增加了对约束满足问题的解的数量。如所讨论的,在上面的实验中,约束被包括以获得类似于参考实现的解。对于所述基准计算中的一些,这些约束导致必须在ic维度上执行零填充,因为,导致较低的利用率和较大的张量。有趣的是,通过放松这些约束,发现了可能的是确定需要更少填充或不需要填充的可能调用,并且因此提供改进的性能。特别地,应用了放松,其允许包括在过滤器模板中的卷积的多个维度上的映射。放松约束意味着当生成代码实现计算时需要处理更多不同的情况,但这仍然是可行的。特别地,代码生成适于支持将多个张量维度融合成一个维度,以及模板计算的数据访问的线性化。后者涉及在内存中显式地复制由模板产生的访问模式,如。当展开维度的新占用为时,用于计算结果的运算总数保持不变。为了最小化创建开销,仅展开了嵌入所必需的模板维度。为了生成vta的代码,使用了张量分裂因子,所述分裂因子是原始维度的偶数除数。在没有任何填充的实现是不可能的情况下,如果必要,则缩减维度被自动添加到指令大小的下一个偶数除数。
159.特别地,利用中继功能实现了内存布局变换。展开模板的运算符使用“relay.take()”,这是取得索引列表的聚集函数,用于确定将复制的值,因为在relay中没有直接的运算符可用。
160.根据技术生成的实现的性能是依据推理和内存变换性能以及数据占用来评估的。与具有填充的tvm参考实现相比,在许多情况下,可能的是改进内存占用、运算符性能和/或总体性能。在一些情况下,这涉及到权衡,并且取决于针对其优化哪个性能参数,可以找到不同的最佳实现。特别地,在许多情况下,由填充控制的有效硬件利用率是改进性能的重要因素,尤其是在“仅”的层中,输入图像中的元素对结
果有意义地做贡献,从而降低了有效硬件利用率,并使所提出的技术特别有利。生成的调用执行得特别好的其他情形是填充创建了超过加速器权重缓冲区的容量的权重张量的情况。利用所提供的技术生成的实现可以避免此,这可以具有加速器可以在片上缓冲区中保存完全的权重张量的效果。在这样的情况下,发现了特别大的性能加速。
161.图6示出了使用处理器系统的硬件加速指令来实现计算的计算机实现的方法600的框图。方法600可以对应于图1的系统100的运算。然而,这不是限制,因为方法600也可以使用另一系统、装置或设备来执行。
162.方法600可以在题为“获得计算数据”的运算中包括获得610计算数据。计算数据可以定义表示计算的计算数据流图。计算数据流图的节点表示计算的输入或运算。
163.方法600可以在题为“获取指令数据”的运算中包括获取620指令数据。指令数据可以定义表示硬件加速指令的指令数据流图。指令数据流图的节点可以表示硬件加速指令的输入或运算。
164.方法600可以在题为“定义指令-》计算csp”的运算中包括基于计算数据和指令数据,定义630约束满足问题。对约束满足问题的解可以表示在计算中硬件加速指令的可能调用。约束满足问题可以将计算数据流图的节点赋值给指令数据流图的节点。约束满足问题可以包括一个或多个数据流约束,所述一个或多个数据流约束实施计算数据流图的赋值节点具有与指令数据流图等效的数据流。约束满足问题可以进一步包括一个或多个输入约束,所述一个或多个输入约束限制计算数据流图的哪些节点可以被赋值给硬件加速指令的输入。这些限制可能是由硬件加速指令和/或其编程接口施加的。约束满足问题可以包括附加的约束。
165.方法600可以在题为“求解csp以确定调用”的运算中包括求解640约束满足问题以确定计算中硬件加速指令的可能调用。方法600可以在题为“输出调用”的运算中包括输出650定义可能调用的数据。
166.将领会,通常,图6的方法600的运算可以以任何合适的次序来执行,例如,连续地、同时地或其组合,其在适用的情况下服从例如由输入/输出关系所必需的特定次序。
167.(一个或多个)方法可以在计算机上实现为计算机实现的方法、专用硬件或者二者的组合。如还在图7中图示的,例如可执行代码的用于计算机的指令可以例如以一系列710机器可读物理标记的形式和/或作为一系列具有不同的电(例如磁性)或光学属性或值的元件而存储在计算机可读介质700上。可执行代码可以以暂时性或非暂时性的方式存储。计算机可读介质的示例包括存储器设备、光存储设备、集成电路、服务器、在线软件等。图7示出了光盘700。
168.替代地,计算机可读介质700可以包括表示指令的暂时性或非暂时性数据710,所述指令当被支持硬件加速指令的处理器系统(例如,图2的系统200)执行时,使得处理器系统执行计算,其中所述指令根据如本文所述确定的可能调用来调用硬件加速指令。
169.此外,设想了一种计算机实现的方法,该方法包括由支持硬件加速指令的处理器系统根据确定的可能调用来执行调用硬件加速指令的指令。
170.示例、实施例或可选特征——无论是否被指示为非限制性的——都不要被理解为对如要求保护的本发明进行限制。
171.应当注意到,以上提及的实施例说明而不是限制本发明,并且本领域技术人员将
能够在不偏离所附权利要求书的范围的情况下设计许多替代的实施例。在权利要求书中,被置于括号之间的任何参考标记不应被解释为限制权利要求。使用动词“包括”及其变位不排除存在除了在权利要求中所陈述的那些元素或阶段之外的元素或阶段。在元素之前的冠词“一”或“一个”不排除存在多个这样的元素。诸如
“……
中的至少一个”之类的表述当在元素列表或组之前时表示从该列表或组中选择全部元素或元素的任何子集。例如,表述“a、b和c中的至少一个”应当被理解为包括仅a、仅b、仅c、a和b二者、a和c二者、b和c二者或者全部a、b和c。本发明可以借助于包括几个不同元件的硬件以及借助于合适编程的计算机来被实现。在枚举了几个构件的设备权利要求中,这些构件中的几个构件可以通过硬件的同一项来体现。仅有的事实即在相互不同的从属权利要求中记载了某些措施不指示这些措施的组合不能被有利地使用。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。