技术特征:
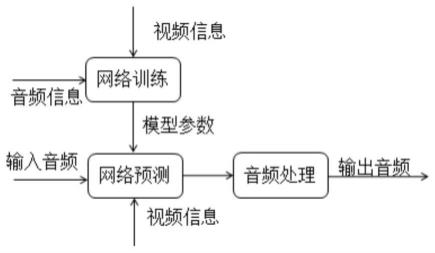
1.一种基于多模态的沉浸声生成方法,其特征在于,所述方法包括:获取样本视频的视频信息和音频信息;其中,所述音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;将所述样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到所述上混处理模型的模型参数,并基于所述模型参数对上混处理模型进行更新;将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声,其中所述视频信息中至少包括运动信息和位置信息。2.根据权利要求1所述的方法,其特征在于,所述方法还包括:将直接声源作为中置声道进行声像平移处理,得到左声道信号和右声道信号;根据背景声进行去相关处理,获得后置左环绕声道信号和后置右环绕声道信号;并将直接声源进行低通处理得到重低音声道信号;将左声道信号、右声道信号、后置左环绕声道信号、后置右环绕声道信号、重低音声道信号合并得到5.1声道音频信号。3.根据权利要求1所述的方法,其特征在于,将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,包括:结合左右声道音频信号进行立体声参数提取,得到立体声参数;其中,所述立体声参数信息包括声道间时间差和声道间能量差;根据左右声道频域信号、立体声参数信息及视频信息进行声源分离,得到直接声源和背景声;其中,所述视频信息包括运动信息和位置信息;基于直接声源和背景声,经过音频处理,得到5.1声道音频信号。4.根据权利要求3所述的方法,其特征在于,所述声道间时间差通过第一公式进行确定,所述第一公式具体包括:itd=argmax{φ
lr
(m)}其中,φ
lr
为归一化互相关函数。5.根据权利要求3所述的方法,其特征在于,所述声道间能量差通过第二公式进行确定,所述第二公式具体包括:其中,x
l
为左声道音频信号,x
r
为右声道音频信号。6.根据权利要求1所述的方法,其特征在于,所述方法还包括:针对左声道音频信号和右声道音频信号基于快速傅立叶变换进行处理,得到左右声道音频频域信号;基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;
针对所述左右声道频域信号输入至unet网络,并将包含运动信息的特征图添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z信号;基于左右声道音频信号进行下混处理,得到mono信号;将mono信号作为w信号,结合得到的x、y、z信号得到foa音频信号。7.根据权利要求1所述的方法,其特征在于,所述方法还包括:基于左右声道音频信号进行下混处理,得到单声道音频和立体声参数;其中,所述立体声参数信息包括声道间时间差和声道间能量差;针对左声道音频信号和右声道音频信号基于快速傅立叶变换进行处理,得到左右声道音频频域信号;基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;针对所述左右声道频域信号输入至unet网络,并将基于视频提取的包含运动信息的特征图与所述立体声参数添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z信号;进行音频处理,将下混处理的单声道音频作为w信号,结合得到的x、y、z信号得到foa音频信号。8.根据权利要求2所述的方法,其特征在于,所述方法还包括:将5.1声道音频信号中的左声道信号、右声道信号、后置左环绕声道信号、后置右环绕声道信号、重低音声道信号进行快速傅立叶变换得到音频频域信号;基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;针对所述音频频域信号输入至unet网络,并将包含运动信息的特征图添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonic信号中x、y和z信号;基于输入5.1声道音频和一阶ambisonic信号中x、y和z信号,得到包含高度信息的沉浸声音频信号。9.根据权利要求1所述的方法,其特征在于,所述声源分离包括基于音频时域信号进行处理和/或基于音频频域信号进行处理。10.一种基于多模态的沉浸声生成装置,其特征在于,所述装置包括:获取模块,用于获取样本视频的视频信息和音频信息;其中,所述音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;训练模块,用于将所述样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到所述上混处理模型的模型参数,并基于所述模型参数对上混处理模型进行更新;计算模块,用于将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声,其中所述视频信息中至少包括运动信息和位置信息。
技术总结
本申请公开了一种基于多模态的沉浸声生成方法及装置。本方法首先获取样本视频的视频信息和音频信息;其中,音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;然后将样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到上混处理模型的模型参数,并基于模型参数对上混处理模型进行更新;最后将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声。本发明结合视频信息,针对多声道音频进行上混处理,可以有效提升沉浸声音效,保证视音视频播放内容的一致性,进而有效提升沉浸声播放效果。放效果。放效果。
技术研发人员:徐涛 董强国 孙学京 周令非 张辉
受保护的技术使用者:中国电影科学技术研究所
技术研发日:2022.05.19
技术公布日:2022/8/26
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。