1.本发明涉及一种计算机信息系统的目标检测领域,具体涉及基于深度学习的视频识别炮弹爆炸火光烟雾方法及系统。
背景技术:
2.深度学习目标检测已经广泛应用于计算机视觉的研究,涵盖通用目标检测、特定领域目标检测,广泛应用于安全、医疗、交通等领域。目前随着网络带宽和gpu性能的提升,出现了越来越多的基于实时视频的目标检测。
3.现有目标检测技术多数是对不变形目标的检测,例如检测行人、车辆、故障件等,这些目标的形体变化不大,例如人体,只会存在姿态、大小、体型、肤色的不同,同样,多数目标与人体目标相同,变化的主要是姿态、颜色、尺寸,而火光和烟雾不仅存在以上变化,其还存在随着时间的变化,形状会变得异常夸张及不可预料。
4.公告号为cn109255375a的现有发明专利《基于深度学习的全景图像对象检测方法》法包括:s1输入测试图像;s2利用选择搜索算法在图像中提取2000个左右的候选区域;s3将每个候选区域缩放成固定的特征并传入cnn,经过运算输出cnn特征(warp)成227
×
227的大小并输入到cnn,将cnn的fc7层的输出作为特征;s4将每个候选区域提取到的cnn特征输入到svm分类器进行分类。该现有专利采用svm分类器对提取到的cnn特征进行分类,未公开本技术采用的具体图像识别及评估逻辑,同时采用的模型也不同于本技术使用的网络模型,该现有专利与本技术存在显著区别,同时该现有专利涉及的技术方案主要解决传统技术中空间信息丢失以及定位不准的技术问题,与本技术的应用场景及解决的技术问题不同。公告号为cn109272060a的现有发明专利《一种基于改进的darknet神经网络进行目标检测的方法和系统》采用固定相机连续获取训练样本图像,并对训练样本中的检测目标进行边框和类别的标注;通过旋转角度、调整饱和度、调整曝光量、调整色调来生成更多训练样本;基于改进的darknet神经网络构造图像检测模型;利用上述检测模型训练样本图像,并设置检测模型训练时的学习率及迭代次数,输出指定通道数的像素特征图片;每迭代一定次数保存相应的检测模型,直到指定迭代次数终止,并利用最终的检测模型进行相关图像目标检测。该现有专利主要应用场景及解决的问题为针对细微物体图像识别,解决传统识别技术中遮挡漏检的缺陷,可知,该现有专利的应用场景及解决的技术问题与本技术存在显著区别。公告号为cn112150512a的现有发明专利一种融合背景差分法和聚类法的弹着点定位方法,提取所有爆炸共有的特征,即炮弹着地后,爆炸范围会在短时间内逐渐扩大,使用背景差分法获得爆炸的区域大小信息,使用聚类算法提取并分析爆炸区域的信息,该现有专利融合了背景差分法和聚类算法的优点,对获取到的运行目标进行数据处理和分析。该现有专利未采用本技术的概率值判断、约定范围判断、连续帧判断、关键帧提取等的技术方案,该现有专利与本技术存在显著区别,同时,该现有专利解决问题偏重弹着点定位,而本技术主要解决对爆炸烟雾和火光的识别,该现有专利与本技术的解决的技术问题不同,应用场景也存在区别,无法产生本技术的技术效果。综上可知,现有技术中缺乏对炮弹爆炸
产生的火光及烟雾进行识别的目标检测技术。同时对目标的识别,尤其针对快速变化的目标的检测精度较低,识别率受有制约。
5.综上,现有技术存在难以针对炮弹爆炸火光烟雾进行高精度快速识别的技术问题。
技术实现要素:
6.本发明所要解决的技术问题在于如何解决现有技术存在的难以针对炮弹爆炸火光烟雾进行高精度快速识别的技术问题。
7.本发明是采用以下技术方案解决上述技术问题的:基于深度学习的视频识别炮弹爆炸火光烟雾方法包括:
8.s1、通过预置网络上搜索获取炮弹打击视频图像数据,以提取得到样本数据,利用所述样本数据及预置阈值识别所述视频图像数据中的时间段数据及图像帧;
9.s2、分类标注所述样本数据,以得到火光样本数据及烟雾样本数据,据以生成分类样本集,以处理得到训练文件,获取并利用预训练模型及所述训练文件训练爆炸识别模型;
10.s3、利用darknet深度学习框架及yolov4算法,根据所述爆炸识别模型,取火光位置下方中心点坐标及其前后图像帧内中心点坐标的相互距离,据以判断每帧图像中的火光是否同一,以得到火光识别结果,以预置概率阈值、约定范围、烟雾消散时间及帧连续参数识别所述每帧图像中的烟雾,以得到烟雾识别结果,所述步骤s3还包括:
11.s31、获取所述每帧图像的像素区域数据,据以处理得到概率值,以所述预置概率阈值判断所述每帧图像中的烟雾;
12.s32、判断邻接的两帧中,前帧落点是否在后帧落点的所述约定范围内,据以判定获取同一炸点,以将后帧的所述约定范围作为新约定范围;
13.s33、以前述s31及s32处理所有帧数据,以识别图像中的连续烟雾;
14.s34、采集气候条件数据,据以处理得到所述烟雾消散时间,以清除已有烟雾数据并识别新烟雾;
15.s35、采集天气数据,据以设定所述帧连续参数,用以判定所述烟雾的真假;
16.s4、调整所述火光识别结果和所述烟雾识别结果的fps、分辨率并推送至客户端。
17.本发明通过便捷样本数据采集、样本训练、火光及烟雾识别及结果视频推送等步骤快速识别炮弹爆炸的火光及烟雾。本发明能够接收实时视频流和离线视频文件,通过深度学习算法yolov4检测火光和烟雾,并只输出一次结果,将检测完成的视频重新作为视频流进行推送。利用本发明,能够检测火光和烟雾,并得到同一个火光或者烟雾的唯一结果,而不会重复识别。本发明提供快速辨别同一个持续的火光或烟雾的能力,避免同一个火光或烟雾被识别多次,影响识别率,并通过调整输出视频的fps、分辨率,解决稳定、低带宽的结果视频输出,保证了可调整带宽的视频结果输出方法的稳定性,也能够对其他特定领域目标检测提供思路。
18.在更具体的技术方案中,所述步骤s1包括:
19.s11、触发帧截取操作,通过所述预置网络上搜索获取炮弹打击视频图像数据;
20.s12、利用ffmpeg视频处理工具从所述炮弹打击视频图像数据中提取得到所述样本数据。
21.在更具体的技术方案中,所述步骤s1的帧截取方式还包括:
22.s101、利用所述样本数据识别所述炮弹打击视频图像数据中的火光及烟雾;
23.s102、根据具体识别范围调节所述预置阈值,据以挑选得有用图像帧,以获取所述样本数据。
24.本发明采取了两种方法,第一种方法适用于零数据情况,另一种方法适用于已有样本数据情况,能够逐帧截取炮弹爆炸后产生的火光和烟雾,为了扩大识别范围,可将识别阈值调低,避免丢失火光和烟雾,挑选有用的图像帧,提供了一种快速获取样本数据的方法并验证了其可行性。
25.在更具体的技术方案中,所述步骤s2包括:
26.s21、分类标注所述样本数据,以得到火光样本数据及烟雾样本数据,据以生成测试集、训练集及评估集;
27.s22、根据生成测试集、训练集及评估集处理得到目标类别文件、类别数、测试训练集图像路径及权重信息;
28.s23、通过预训练获取所述预训练模型,据以根据所述目标类别文件、所述类别数、所述测试训练集图像路径及所述权重信息训练爆炸识别模型。
29.在更具体的技术方案中,所述步骤s23还包括:以训练输出的map和fps判断当前的所述权重信息训练爆炸识别模型是否适用。
30.在更具体的技术方案中,所述步骤s3还包括:将离线视频文件模拟为rtsp协议视频流,并利用预置视频流稳定性检测工具文采视频流检测的稳定性。
31.在更具体的技术方案中,所述步骤s31包括:
32.s311、利用所述darknet深度学习框架及所述yolov4算法处理所述每帧图像,以得到不同的像素区域是否为烟雾的所述概率值;
33.s312、判断所述概率值是否大于所述预置概率阈值;
34.s313、若是,则判定该所述像素区域存在所述烟雾;
35.s314、若否,则排除该所述像素区域。
36.在更具体的技术方案中,所述步骤s31中的所述约定范围为所述烟雾的出现位置的下方中心点坐标为原点,以预置范围尺寸为半径的像素区域范围。
37.本发明以视频检测程序使用darknet深度学习框架、yolov4算法以及模型文件识别火光和烟雾,通过对约定范围的使用能够判断连续烟雾,避免同一个烟雾出现多次,提高了炮弹爆炸烟雾识别的精度。
38.在更具体的技术方案中,所述步骤s35包括:
39.s351、根据所述天气数据设定所述帧连续参数,其中,所述帧连续参数包括:连续20帧;
40.s352、如所述烟雾出现次数大于或等于所述帧连续参数,则判定所述烟雾为真。
41.本发明利用烟雾消散时间以清除已有烟雾,保证下一个烟雾如果落在了约定范围内则认为是新烟雾,防止重复对炮弹爆炸烟雾的重复识别。
42.本发明针对传统技术中在识别过程中可能出现错误,例如把不是烟雾的物体识别为烟雾的缺陷,设置连续帧录入20帧出现次数参数指标,以判断是否为真烟雾,提高了烟雾识别的准确性。本发明使用传统方式的多条件参数组合方式解决了同一个烟雾仅被当作识
别结果输出一次的问题。
43.在更具体的技术方案中,基于深度学习的视频识别炮弹爆炸火光烟雾系统,其特征在于,所述系统包括:
44.样本采集模块,用以通过预置网络上搜索获取炮弹打击视频图像数据,以提取得到样本数据,利用所述样本数据及预置阈值识别所述视频图像数据中的时间段数据及图像帧;
45.模型训练模块,用以分类标注所述样本数据,以得到火光样本数据及烟雾样本数据,据以生成分类样本集,以处理得到训练文件,获取并利用预训练模型及所述训练文件训练爆炸识别模型,所述模型训练模块与所述样本采集模块连接;
46.火光及烟雾识别模块,用以利用darknet深度学习框架及yolov4算法,根据所述爆炸识别模型,取火光位置下方中心点坐标及其前后图像帧内中心点坐标的相互距离,据以判断每帧图像中的火光是否同一,以得到火光识别结果,以预置概率阈值、约定范围、烟雾消散时间及帧连续参数识别所述每帧图像中的烟雾,以得到烟雾识别结果,所述火光及烟雾识别模块与所述模型训练模块及所述样本采集模块连接,所述火光及烟雾识别模块还包括:
47.烟雾概率判定模块,用以获取所述每帧图像的像素区域数据,据以处理得到概率值,以所述预置概率阈值判断所述每帧图像中的烟雾;
48.约定范围判定模块,用以判断邻接的两帧中,前帧落点是否在后帧落点的所述约定范围内,据以判定获取同一炸点,以将后帧的所述约定范围作为新约定范围,所述约定范围判定模块与所述烟雾概率判定模块连接;
49.连续烟雾识别模块,用于以前述s31及s32处理所有帧数据,以识别图像中的连续烟雾,所述连续烟雾识别模块与所述约定范围判定模块及所述烟雾概率判定模块连接;
50.烟雾消散模块,用以采集气候条件数据,据以处理得到所述烟雾消散时间,以清除已有烟雾数据并识别新烟雾;
51.帧连续判定模块,用以采集天气数据,据以设定所述帧连续参数,用以判断所述烟雾的真假;
52.结果推送模块,用以将所述火光识别结果和所述烟雾识别结果推送至客户端。
53.本发明相比现有技术具有以下优点:本发明通过便捷样本数据采集、样本训练、火光及烟雾识别、结果视频推送等步骤快速识别炮弹爆炸的火光及烟雾。本发明能够接收实时视频流和离线视频文件,通过深度学习算法yolov4检测火光和烟雾,并只输出一次结果,将检测完成的视频重新作为视频流进行推送。利用本发明,能够检测火光和烟雾,并得到同一个火光或者烟雾的唯一结果,而不会重复识别。本发明提供快速辨别同一个持续的火光或烟雾的能力,避免同一个火光或烟雾被识别多次,影响识别率,并通过调整输出视频的fps、分辨率,解决稳定、低带宽的结果视频输出,保证了可调整带宽的视频结果输出方法的稳定性,也能够对其他特定领域目标检测提供思路。
54.本发明采取了两种方法,第一种方法适用于零数据情况,另一种方法适用于已有样本数据情况,能够逐帧截取炮弹爆炸后产生的火光和烟雾,为了扩大识别范围,可将识别阈值调低,避免丢失火光和烟雾,挑选有用的图像帧,提供了一种快速获取样本数据的方法并验证了其可行性。
55.本发明以视频检测程序使用darknet深度学习框架、yolov4算法以及模型文件识别火光和烟雾,通过对约定范围的使用能够判断连续烟雾,避免同一个烟雾出现多次,提高了炮弹爆炸烟雾识别的精度。
56.本发明针对传统技术中在识别过程中可能出现错误,例如把不是烟雾的物体识别为烟雾的缺陷,设置连续帧录入20帧出现次数参数指标,以判断是否为真烟雾,提高了烟雾识别的准确性。本发明使用传统方式的多条件参数组合方式解决了同一个烟雾仅被当作识别结果输出一次的问题。本发明解决了现有技术中存在的难以针对炮弹爆炸火光烟雾进行高精度快速识别的技术问题。
附图说明
57.图1为本发明实施例1的基于深度学习的视频识别炮弹爆炸火光烟雾方法基本流程示意图;
58.图2为本发明实施例1的火光及烟雾识别具体步骤流程示意图;
59.图3为本发明实施例1的现场实验第一识别效果图;
60.图4为本发明实施例1的现场实验第二识别效果图。
具体实施方式
61.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
62.实施例1
63.如图1所示,本发明的基于深度学习的视频识别炮弹爆炸火光烟雾方法包括以下步骤:
64.s1、采集样本;
65.在本实施例中,本发明涉及的样本数据颇为稀缺,多数来自网络或电视节目报道、相关网络视频文件等,所以如何快速的提取视频文件中适用的图像帧变得很关键,本发明采取了两种方法,第一种方法适用于零数据情况,另一种方法适用于已有样本数据情况。
66.方法一是手动截取视频关键帧,使用此方法能够逐帧截取炮弹爆炸后产生的火光和烟雾。在网络上搜索相关炮弹打击视频、图片,加载视频文件,在产生火光和烟雾前,触发截取操作,开始逐帧或者跳帧截取图像帧,挑选有用的图像帧,以此获取样本数据。手动截取视频关键帧主要采用ffmpeg视频处理工具,此工具为开源软件,具备丰富的视频处理功能,可轻松逐帧获取图像数据。
67.方法二是自动截取视频关键帧,使用已有的样本数据对视频文件进行火光和烟雾识别,将识别结果时间段内及前后时间段内容图像帧均作为结果输出,为了扩大识别范围,可将识别阈值调低,避免丢失火光和烟雾,挑选有用的图像帧,以此获取样本数据。
68.炮弹爆炸后产生的火光,存在的时间很短,形变不大。炮弹爆炸后产生的烟雾,存在的时间较长,形变很大,由前期的小型烟雾迅速放大,之后慢慢扩散、消散,本发明着重选择小型烟雾。
69.s2、标注样本;
70.在本实施例中,首先通过标注工具对样本数据进行标注,分为火光和烟雾两种类型分别进行标注。根据标注信息生成测试集图像路径、训练集图像路径、评估集图像路径。
71.之后准备训练文件,主要有三个:yolo.names、yolo.data、yolov4.cfg。其中yolo.names文件存储了所有样本的目标类别,本发明中是火光flare和烟雾fog;yolo.data文件存储了类别数、测试集图像路径、训练集图像路径、权重等信息;yolov4.cfg文件存储了yolov4的网络结构。
72.s3、模型训练;
73.在本实施例中,接下来进行模型训练,模型训练时需要用到预训练模型。对于卷积神经网络cnn结构来说,不同层学到的图像特征不一样,越浅层学到的特征越通用,越深层学到的特征和具体任务关联性就越强。预训练模型就是已经用数据集训练好了的模型。模型训练以及接下来的识别选用开源深度学习框架darknet。
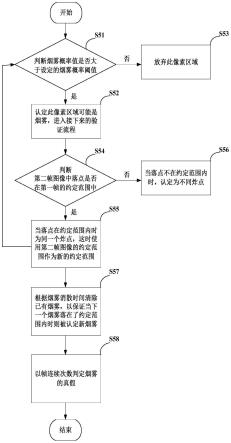
74.s4、模型评估;
75.在本实施例中,训练输出中的map和fps作为判断模型好坏条件之一,另需要拿出部分测试数据验证模型好坏。
76.s5、火光及烟雾识别;
77.在本实施例中,根据业务需要,将离线视频文件模拟为rtsp协议视频流。
78.视频检测程序使用darknet深度学习框架、yolov4算法以及模型文件识别火光和烟雾。为了不受rtsp协议视频流稳定性的影响,添加了视频流稳定性检测模块,保证视频检测程序持续运行。
79.在本实施例中,对于火光,平均出现5~8帧图像,对其识别率很高,取其出现位置的下方中心点坐标,判断每帧图像出现位置是否相近即可判断是否为同一个火光。
80.对于烟雾,出现时长与当天天气情况有关,是否有雾、风力大小等都会影响烟雾的识别,其中雾气对烟雾的识别率有影响。为了解决同一个烟雾被识别多次后输出多次的问题,设置了概率阈值、约定范围、烟雾消散时间、连续20帧出现次数等参数。
81.如图2所示,步骤s5中条件判断的步骤还包括:
82.s51、判断烟雾概率值是否大于设定的烟雾概率阈值;在本实施例中,当程序处理一帧图像时,会得到不同像素区域是否为烟雾的概率值;
83.s52、当大于设定的概率阈值时,程序认定此像素区域可能是烟雾,进入接下来的验证流程;
84.s53、否则放弃此像素区域;
85.s54、判断第二帧图像中落点是否在第一帧的约定范围中;
86.自然界中烟雾的规律,由小到大,从无到有再到消散,是一个连续的过程,而炮弹爆炸后的烟雾形态,下小上大,烟雾出现初期,烟雾与地面接触点基本不会发生变化。基于烟雾的连续、与地面接触点不变这两个特点,程序设置了约定范围指标参数。约定范围是指以烟雾出现位置的下方中心点坐标为圆点,以约定范围为半径的像素区域范围。假如前后两帧图像中都有某些像素区域经过了第一步概率阈值的判断,设定第一帧中的约定范围,查看第二帧图像中落点是否在第一帧的约定范围中。
87.s55、当落点在约定范围内时为同一个炸点,这时使用第二帧图像的约定范围作为
新的约定范围,之后图像帧都进行如此判断和处理;
88.s56、当落点不在约定范围内时,认定为不同炸点。在本实施例中,通过对约定范围的使用能够判断连续烟雾,避免同一个烟雾出现多次。
89.s57、根据烟雾消散时间清除已有烟雾,以保证当下一个烟雾落在了约定范围内时则被认定新烟雾;
90.在不同的气候条件下,烟雾持续时间不同,例如无风的晴朗天气下,炮弹爆炸后的烟雾能够持续几分钟不等,在如此上的时间内,极易发生炮弹在附近爆炸的情况发生,而被约定范围判断为同一炸点。烟雾消散时间用于清除烟雾,保证下一个烟雾如果落在了约定范围内则认为是新烟雾。烟雾消散时间值的设定与当前天气情况相关,可以在第一发炮弹爆炸时获取烟雾的消散时间。
91.s58、以帧连续次数判定烟雾的真假;
92.在本实施例中,自然界中各种物体形态、颜色都可能出现相似情况,程序在识别过程中可能出现错误,例如把不是烟雾的物体识别为烟雾,为解决这个问题设置连续20帧出现次数参数指标,连续20帧出现次数用于判断是否为真烟雾。不同的拍摄设备每秒图像帧数不同,20帧差不多为1秒视频的图像帧数。当设置此参数指标为10时,表示在连续出现的20帧图像中,有10次被识别为烟雾,则为真烟雾。此参数因天气有关,当大雾天气或者雨天时,需要降低此数值。
93.s6、输出结果并推送至客户端。
94.在本实施例中,结果推送包括两部分,其一是带有识别结果的图像和识别结果坐标,其二是带有识别结果的实时视频。对于第一部分结果无需赘述,直接保存到指定位置即可。对于第二部分结果则需要考虑多方面的问题,包括是否有接收端、发送时的fps、结果显示方式、像素等等。本发明通过解决以上问题,能够稳定持续输出、有效降低网络带宽、降低客户端处理压力等。
95.如图3及图4所示,以上是本发明的整个过程的叙述,本发明已经编码实现且完成现场试验,基于现场试验数据,自动炸点识别率高于98%。
96.综上,本发明通过便捷样本数据采集、样本训练、火光及烟雾识别、结果视频推送等步骤快速识别炮弹爆炸的火光及烟雾。本发明能够接收实时视频流和离线视频文件,通过深度学习算法yolov4检测火光和烟雾,并只输出一次结果,将检测完成的视频重新作为视频流进行推送。利用本发明,能够检测火光和烟雾,并得到同一个火光或者烟雾的唯一结果,而不会重复识别。本发明提供快速辨别同一个持续的火光或烟雾的能力,避免同一个火光或烟雾被识别多次,影响识别率,并通过调整输出视频的fps、分辨率,解决稳定、低带宽的结果视频输出,保证了可调整带宽的视频结果输出方法的稳定性,也能够对其他特定领域目标检测提供思路。
97.本发明采取了两种方法,第一种方法适用于零数据情况,另一种方法适用于已有样本数据情况,能够逐帧截取炮弹爆炸后产生的火光和烟雾,为了扩大识别范围,可将识别阈值调低,避免丢失火光和烟雾,挑选有用的图像帧,提供了一种快速获取样本数据的方法并验证了其可行性。
98.本发明以视频检测程序使用darknet深度学习框架、yolov4算法以及模型文件识别火光和烟雾,通过对约定范围的使用能够判断连续烟雾,避免同一个烟雾出现多次,提高
了炮弹爆炸烟雾识别的精度。
99.本发明针对传统技术中在识别过程中可能出现错误,例如把不是烟雾的物体识别为烟雾的缺陷,设置连续帧录入20帧出现次数参数指标,以判断是否为真烟雾,提高了烟雾识别的准确性。本发明使用传统方式的多条件参数组合方式解决了同一个烟雾仅被当作识别结果输出一次的问题。本发明解决了现有技术中存在的难以针对炮弹爆炸火光烟雾进行高精度快速识别的技术问题。
100.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
