1.本发明涉及一种脚本并发方法,更具体的说是涉及一种实现脚本单机高并发的方法。
背景技术:
2.脚本技术,是应对了部分逻辑需要动态加载代码,而并非将代码编译在程序内的技术。使用脚本技术将可以应对大部分业务逻辑不固定,需要频繁改动的场景,在实际应用中,只需要从服务端下发新的脚本,就可以完成对业务逻辑的变更。
3.而脚本技术由于其解释执行的特性,会比编译执行慢很多,并且会有物理环境的限制,如对内存的要求,会随着执行脚本的变多,而占用大量内存,从而直接降低脚本的并发量。同时,在一般情况下,都会将脚本设计为单线程运行,即多个脚本来运行时,会分个先来后到,无法做到在同时运行。
4.目前openresty内置的luajit,可以实现较高并发的lua脚本,但是lua脚本的学习成本较高,在常用的语言技术体系内,包含js,python,java等等,但是不包含lua,因此现有技术下,要实现脚本语言的高并发处理,只能采用上述lua相关的技术栈,基本不具备通用性,在常用技术栈,如js,python等条件下,很难有lua的一席之地,要求开发或实施人员额外学习的成本很高。并且在现有技术条件下,很难实现单台服务器扛住qps 5000以上的高强度并发压力。对于复杂的脚本,甚至是每个请求都带了不同的脚本代码时,其承压能力将进一步下降。对于服务器数量受限,服务器配置受限,并且脚本请求业务复杂的条件下,将无法承受较高的并发压力,出现脚本执行崩溃,执行结果异常,执行卡死无返回等等各种问题。
技术实现要素:
5.针对现有技术存在的不足,本发明的目的在于提供一种在需要动态执行脚本代码的场景下,使该脚本代码能支持高并发的能力,彻底解决了脚本语言执行能力低下,对并发不友好的弊端的方法。
6.为实现上述目的,本发明提供了如下技术方案:一种实现脚本单机高并发的方法,包括如下步骤:
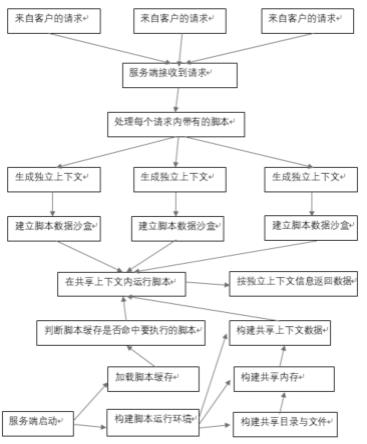
7.步骤一,启动服务端,构建脚本运行环境;
8.步骤二,客户端发送多个请求至服务端内,服务端接收到多个请求后处理每个请求内带有的脚本;
9.步骤三,服务端将多个请求内带有的脚本同步放入到脚本运行环境内,在共享上下文内同步运行多个脚本,同时按每个脚本对应的独立上下文信息返回数据至客户端。
10.作为本发明的进一步改进,所述步骤一种构建脚本运行环境的具体步骤如下:步骤一一,构建共享目录与文件;
11.步骤一二,构建共享内存;
12.步骤一三,构建共享上下文数据,完成脚本运行环境构建。
13.作为本发明的进一步改进,所述步骤一中服务端启动后还进行加载脚本缓存数据,判断脚本缓存中是否命中要执行的脚本,若命中则不做处理在共享上下文内运行脚本,若未命中则进行处理后在共享上下文内运行脚本。
14.作为本发明的进一步改进,所述步骤二中处理每个请求内带有的脚本的具体步骤如下:
15.步骤二一,分析每个请求内带有的脚本,根据每个脚本生成相互独立的独立上下文;
16.步骤二二,同时根据步骤二一生成的独立上下文建立脚本数据沙盒。
17.作为本发明的进一步改进,所述步骤一中判断脚本缓存中是否命中要执行的脚本的具体步骤为在服务端接受到一个脚本的请求时,会先对脚本代码进行哈希运算,并使用运算结果到缓存中进行匹配,若是命中缓存,则直接从缓存内读取编译后的脚本并执行,若是不命中缓存,则把脚本代码进行编译,将编译结果写入缓存,然后执行编译后的脚本。
18.本发明的有益效果,采用了针对脚本构建共享内存,共享目录与文件,共享上下文等内容,确保脚本能够在共享的空间内,以独立的上下文运行,通过这种机制,可以实现,不论有多少个脚本要执行,它们都使用共同的一份运行环境,即运行环境本身,只占用一份内存,不会随着执行的脚本变多,而增加对内存的占用。同时,对于单独的脚本,包含了独立上下文的数据隔离,因此每个脚本都可以独立维护自己的数据。
附图说明
19.图1为本发明的实现脚本单机高并发的方法的流程图。
具体实施方式
20.下面将结合附图所给出的实施例对本发明做进一步的详述。
21.参照图1所示,本实施例的一种实现脚本单机高并发的方法,包括如下步骤:步骤一,启动服务端,构建脚本运行环境;
22.步骤二,客户端发送多个请求至服务端内,服务端接收到多个请求后处理每个请求内带有的脚本;
23.步骤三,服务端将多个请求内带有的脚本同步放入到脚本运行环境内,在共享上下文内同步运行多个脚本,同时按每个脚本对应的独立上下文信息返回数据至客户端,步骤一种构建脚本运行环境的具体步骤如下:
24.步骤一一,构建共享目录与文件;
25.步骤一二,构建共享内存;
26.步骤一三,构建共享上下文数据,完成脚本运行环境构建,步骤二中处理每个请求内带有的脚本的具体步骤如下:
27.步骤二一,分析每个请求内带有的脚本,根据每个脚本生成相互独立的独立上下文;
28.步骤二二,同时根据步骤二一生成的独立上下文建立脚本数据沙盒,在使用本实施例的方法的过程中,只需要依次执行上述步骤即可,因而本实施例由于采用了针对脚本
构建共享内存,共享目录与文件,共享上下文等内容,确保脚本能够在共享的空间内,以独立的上下文运行。举例来说,有脚本a和脚本b,它们均包含变量x,均调用系统函数func,则在脚本a内,x的值可以是1,而在脚本b内,x的值可以是2,彼此互不冲突,而调用函数func时,均是从共享内存里读取,即是说两个脚本调用的是同一个系统函数,过这种机制,可以实现,不论有多少个脚本要执行,它们都使用共同的一份运行环境,即运行环境本身,只占用一份内存,不会随着执行的脚本变多,而增加对内存的占用。同时,对于单独的脚本,包含了独立上下文的数据隔离,对于脚本a的操作,将不会影响脚本b,因此每个脚本都可以独立维护自己的数据。
29.作为改进的一种具体实施方式,所述步骤一中服务端启动后还进行加载脚本缓存数据,判断脚本缓存中是否命中要执行的脚本,若命中则不做处理在共享上下文内运行脚本,若未命中则进行处理后在共享上下文内运行脚本,所述步骤一中判断脚本缓存中是否命中要执行的脚本的具体步骤为在服务端接受到一个脚本的请求时,会先对脚本代码进行哈希运算,并使用运算结果到缓存中进行匹配,若是命中缓存,则直接从缓存内读取编译后的脚本并执行,若是不命中缓存,则把脚本代码进行编译,将编译结果写入缓存,然后执行编译后的脚本,如此便可通过保存编译后的脚本内容,以增加执行效率的做法。
30.综上所述,本实施例的方法不会对脚本语言的类型进行判断,对于任何脚本语言都一视同仁,在实际生产场景下,面对自定义语言的脚本也可以做到完好的支持。本发明可以提升脚本执行的承压能力至单台服务器一万qps以上。
31.以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。