1.本文发明涉及一种基于深度学习的汉字书法风格识别方法,属于人工智能技术领域。
背景技术:
2.书法是我国具有几千年历史的传统艺术,是我们中华民族的特色文化代表之一,它不仅记录着我国悠久的历史文化,还是传播信息的重要方式。书法的点画结构、用笔方法和特征展现出它优美的艺术美感。我国历史悠长,各类书法家的作品层出不穷,人们在学习、临摹之时或者随性挥毫泼墨之时,想要知道自己的书法与哪一位书法家风格近似,并且知道相似度的评价,以满足学习或者大众娱乐之需要。
3.当前所用的传统的基于特征相似度的识别方法,在汉字已知且所书写的汉字的中正程度较好的情况下有着不错的识别率。但是由于传统书法风格繁多,且部分汉字没有可以参考的标准,即便可以使用cyclegan等方式生成缺失的汉字但和原作者所书写的汉字还是有所差距,同时现有的部分专利基于深度学习的方法只是实现了楷书、隶书等基础风格的识别,而没有实现进一步的细化书法家风格识别。
4.深度学习技术可以通过对大量数据集进行自主学习,学习到图像的层级特征,提取到图像的高级特征。对比传统的特征需要人工决定提取,并且可能存在缺失的情况,深度学习具有无可比拟的优势。本发明为了将楷书与行书多种不同书法风格,欧阳询楷书、颜真卿楷书、柳公权楷书、宋徽宗楷书、王羲之行书、米芾行书等进行更高精度的识别任务,提出了一种基于深度学习的汉字书法风格识别方法。该模型不仅可以识别出12类不同书法家的书法风格,还可以通过简单的修改实现基础的楷书、行书、草书等分类,并为进一步的度量学习实现新书法风格的识别提供帮助。
技术实现要素:
5.本发明的目的是提出一种基于深度学习的汉字书法风格识别方法,其为了解决传统特征相似度存在的对比字缺失、特征提取繁琐、且各类限制较多的问题。
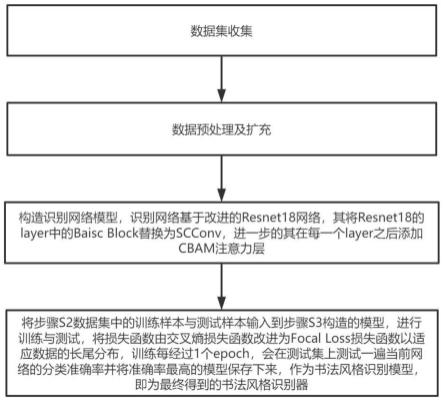
6.一种基于深度学习的汉字书法风格识别方法,包括如下步骤:
7.s1、数据集收集;
8.s2、数据集预处理及扩充;
9.s3、构造识别网络模型,识别网络基于改进的resnet18网络,其将resnet18的layer中的basic block替换为自校正卷积scconv,进一步的其在每一个layer之后添加cbam注意力层;
10.s4、将步骤s2数据集中的训练样本与测试样本输入到步骤s3构造的模型,进行训练与测试,将损失函数由交叉熵损失函数改进为focal loss损失函数以适应数据的长尾分布,训练每经过1个epoch,会在测试集上测试一遍当前网络的分类准确率并将准确率最高的模型保存下来,作为书法风格识别模型,即为最终得到的书法风格识别器。
11.作为本发明的进一步方案,所述步骤s1中:
12.通过爬虫及手动收集的方式,从互联网中收集王羲之、米芾、宋徽宗等书法名家作品,总计 12类不同风格的书法字体。
13.作为本发明的进一步方案,所述步骤s2中:
14.所述的图片预处理包括依次进行图片汉字分割裁剪、去噪、二值化、重置大小,并且利用人工标注的方式对其进行标注;此外为拓展数据将预处理后的单字图片进行左右旋转、平移操作扩充至原数量的5倍组成训练数据集。
15.作为本发明的进一步方案,所述步骤s3中:
16.自校正卷积scconv其首先将输入x沿着channel方向进行分割,形成x1和x2,x2即为 residual,之后x1分成三个通路进入到self-calibration module,self-calibration module是一个多尺度特征提取模块,其两个尺度空间中进行卷积操作通过下采样后的特征实现自校准,最后对两个尺度空间x1, x2输出特征y1,y2进行拼接操作,得到最终输出特征y;
17.cbam注意力层包括通道注意力模块和空间注意力模块:通道注意力模块首先是两个并行的最大池化层和平均池化层,之后经过共享的多层感知器将两个池化层的输出相加,并采用sigmoid激活函数得到通道注意力的输出;空间注意力模块首先将通道注意力的输出经过最大池化和平均池化得到两个特征图,然后通过拼接操作对两个特征图进行拼接,接着通过7
×
7的卷积变为1通道的特征图,最后使用 sigmoid激活函数得到空间注意力的输出并与原图相乘变回原图大小。
18.作为本发明的进一步方案,所述步骤s4中:
19.通过改进的resnet18网络对扩充后的数据集进行训练的具体步骤为:
20.(1)将扩充后的数据集按照8:2的比例划分为训练集和测试集;
21.(2)将数据集按照不同的风格进行分类,将同一风格的汉字放入同一文件夹中,并将文件夹命名为该书法风格的名称(以拼音首字母表示),例如:wxz_kai表示王羲之的楷体;
22.(3)损失函数由传统的交叉熵损失函数改进为focal loss损失函数以适应数据的长尾分布;
23.(4)对改进resnet18网络进行重复监督训练,并在学习的过程中根据学习误差不断调整网络各层之间的连接权重以及网络大小,并通过测试集进行网络测试,获取网络测试的准确率;
24.(5)在准确率最高的时候,记录迭代次数,选择网络迭代次数为记录的次数时的模型作为书法风格识别的模型。
25.与现有的基于相似度和基于特征的技术相比,本发明不依赖于手工特征提取,有着良好的泛化能力;与现有基于深度学习的方法相比,本发明通过引入自校正卷积scconv与cbam注意力机制,为了解决数据的长尾分布问题将损失函数改进为focal loss,从而使本发明具有较高的识别准确率。同时本发明书法风格识别不局限于楷书四大家更加全面,并在进一步的实验中发现楷书的细化风格识别的准确率比行书的细化风格的准确率更高。
附图说明
26.图1为本发明算法流程示意图
27.图2为预处理后的单字示意图
28.图3为自校正卷积scconv示意图
29.图4为cbam注意力机制示意图
具体实施方式
30.下面结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述。
31.如图1-图4所示,本实施方式所描述的一种基于深度学习的汉字书法风格识别方法,主要利用深度学习的方法解决了传统特征及相似度方法存在的对比字缺失、特征提取繁琐、且各类限制较多的问题,进一步的通过改进resnet18网络,在basic block中引入自校正卷积scconv,并在每一层的layer 之间引入了cbam注意力机制,最后将损失函数改进为focal loss损失函数适应数据的长尾分布使得本发明具有较高的识别准确率。具体步骤如下:
32.步骤s1:数据集收集
33.通过爬虫及手动收集的方式,从互联网中收集王羲之、米芾、宋徽宗等书法名家作品,总计 12类不同风格的书法字体。
34.步骤s2:数据集预处理及扩充
35.所述的图片预处理包括依次进行图片汉字分割裁剪、去噪、二值化、重置大小,并且利用人工标注的方式对其进行标注;此外为拓展数据将预处理后的单字图片进行左右旋转、平移操作扩充至原数量的5倍组成训练数据集
36.步骤s3:构造识别网络模型,识别网络基于改进的resnet18网络,其将resnet18的layer中的basic block替换为自校正卷积scconv,进一步的其在每一个layer之后添加cbam注意力层;其中自校正卷积scconv如图3所示,cbam注意力如图4所示。
37.步骤s3中,自校正卷积scconv首先将输入x沿着channel方向进行分割,形成x1和x2, x2即为residual,之后x1分成三个通路进入到self-calibration module,self-calibration module是一个多尺度特征提取模块,其两个尺度空间中进行卷积操作通过下采样后的特征实现自校准,最后对两个尺度空间x1,x2输出特征y1,y2进行拼接操作,得到最终输出特征y;
38.步骤s3中,cbam注意力层包括通道注意力模块和空间注意力模块:通道注意力模块首先是两个并行的最大池化层和平均池化层,之后经过共享的多层感知器将两个池化层的输出相加,并采用 sigmoid激活函数得到通道注意力的输出;空间注意力模块首先将通道注意力的输出经过最大池化和平均池化得到两个特征图,然后通过拼接操作对两个特征图进行拼接,接着通过7
×
7的卷积变为1通道的特征图,最后使用sigmoid激活函数得到空间注意力的输出并与原图相乘变回原图大小。
39.步骤s4:通过改进的resnet18网络对扩充后的数据集进行训练
40.具体流程如下:
41.(1)将扩充后的数据集按照8:2的比例划分为训练集和测试集;
42.(2)将数据集按照不同的风格进行分类,将同一风格的汉字放入同一文件夹中,并将文件夹命名为该书法风格的名称(以拼音首字母表示),例如:wxz_kai表示王羲之的楷体;
43.(3)损失函数由传统的交叉熵损失函数改进为focal loss损失函数以适应数据的长尾分布;
44.(4)对改进resnet18网络进行重复监督训练,并在学习的过程中根据学习误差不断调整网络各层之间的连接权重以及网络大小,并通过测试集进行网络测试,获取网络测试的准确率;
45.(5)在准确率最高的时候,记录迭代次数,选择网络迭代次数为记录的次数时的模型作为书法风格识别的模型。
46.实施例
47.将训练集总计8856张书法单字图像和测试集2158张书法单字图像,大小为224
×
224。输入到本方法所提出的步骤s3中的改进模型中,根据步骤s4的方法进行训练,在训练集上训练改进模型210 个epoch,每经过一个epoch,将该模型在测试集上进行验证,得到测试集的准确率。在具体的实验中,12 类书法风格的识别准确率最高为78.64%,未改进的resnet18其准确率为74.02%,resnet50、densent121等网络其准确率均在75%左右。进一步的分别对楷书和行书中不同的书法风格进行识别,其中楷书下6类不同书法风格的准确率为90.28%,行书下6类不同书法风格的识别率为68.25%。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。