技术特征:
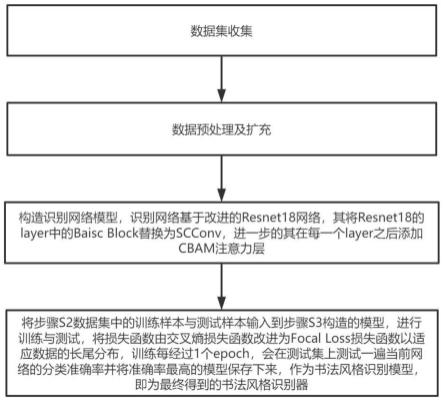
1.一种基于深度学习的汉字书法风格识别方法,其特征在于,所述方法包括以下步骤:s1、数据集收集;s2、数据集预处理及扩充;s3、构造识别网络模型,识别网络基于改进的resnet18网络,其将resnet18的layer中的basic block替换为自校正卷积scconv,进一步的其在每一个layer之后添加cbam注意力层;s4、将步骤s2数据集中的训练样本与测试样本输入到步骤s3构造的模型,进行训练与测试,将损失函数由交叉熵损失函数改进为focal loss损失函数以适应数据的长尾分布,训练每经过1个epoch,会在测试集上测试一遍当前网络的分类准确率并将准确率最高的模型保存下来,作为书法风格识别模型,即为最终得到的书法风格识别器。2.根据权利要求1所述的一种基于深度学习的汉字书法风格识别方法,其特征在于,所述步骤s1中:通过爬虫及手动收集的方式,从互联网中收集王羲之、米芾、宋徽宗等书法名家作品,总计12类不同风格的书法字体。3.根据权利要求1所述的一种基于深度学习的汉字书法风格识别方法,其特征在于,所述步骤s2中:所述的图片预处理包括依次进行图片汉字分割裁剪、去噪、二值化、重置大小,并且利用人工标注的方式对其进行标注;此外为拓展数据将预处理后的单字图片进行左右旋转、平移操作扩充至原数量的5倍组成训练数据集。4.根据权利要求1所述的一种基于深度学习的汉字书法风格识别方法,其特征在于,所述步骤s3中:自校正卷积scconv其原理是:首先将输入x沿着channel方向进行分割,形成x1和x2,x2即为residual,之后x1分成三个通路进入到self-calibration module,self-calibration module是一个多尺度特征提取模块,其两个尺度空间中进行卷积操作通过下采样后的特征实现自校准,最后对两个尺度空间x1,x2输出特征y1,y2进行拼接操作,得到最终输出特征y;cbam注意力层包括通道注意力模块和空间注意力模块:通道注意力模块首先是两个并行的最大池化层和平均池化层,之后经过共享的多层感知器将两个池化层的输出相加,并采用sigmoid激活函数得到通道注意力的输出;空间注意力模块首先将通道注意力的输出经过最大池化和平均池化得到两个特征图,然后通过拼接操作对两个特征图进行拼接,接着通过7
×
7的卷积变为1通道的特征图,最后使用sigmoid激活函数得到空间注意力的输出并与原图相乘变回原图大小。5.根据权利要求1所述的一种基于深度学习的汉字书法风格识别方法,其特征在于,所述步骤s4中:通过改进的resnet18网络对扩充后的数据集进行训练的具体步骤为:(1)将扩充后的数据集按照8:2的比例划分为训练集和测试集;(2)将数据集按照不同的风格进行分类,将同一风格的汉字放入同一文件夹中,并将文件夹命名为该书法风格的名称(以拼音首字母表示),例如:wxz_kai表示王羲之的楷体;(3)损失函数由传统的交叉熵损失函数改进为focal loss损失函数以适应数据的长尾
分布;(4)对改进resnet18网络进行重复监督训练,并在学习的过程中根据学习误差不断调整网络各层之间的连接权重以及网络大小,并通过测试集进行网络测试,获取网络测试的准确率;(5)在准确率最高的时候,记录迭代次数,选择网络迭代次数为记录的次数时的模型作为书法风格识别的模型。
技术总结
本发明涉及一种基于深度学习的汉字书法风格识别方法。本发明所述的一种基于深度学习的汉字书法风格识别方法包括:数据集收集;对数据集进行预处理将书法作品处理为单字并进行扩充;将所述的单字图像送入识别模型进行训练;保存准确率最高的模型作为识别模型;其中所述的识别模型为改进Resnet18神经网络,其在Basic Block中引入自校正卷积SCConv,并在每一层的Layer之间引入了CBAM注意力机制,最后将损失函数改进为Focal Loss损失函数适应数据的长尾分布。实验证明该方法解决了基于特征的书法风格识别困难的问题,并提高了识别的精准度。准度。准度。
技术研发人员:尹莉莉 陈国栋
受保护的技术使用者:哈尔滨理工大学
技术研发日:2022.06.07
技术公布日:2022/8/19
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。