1.本发明属于人工智能与知识工程技术领域,具体涉及基于知识提示的概念抽取模型。简称kpce。
背景技术:
2.认知智能指的是让计算机具备类似人类认知世界的能力。而人类认知世界最主要的方式之一便是语言,因此自然语言处理是认知智能的重要组成部分。反思人类理解自然语言的过程不难发现,理解自然语言可以视作建立从文本到知识的映射过程。借助已有背景知识,人类可以较为轻松的理解语言。由于自然语言句式语义的多样性和复杂性,计算机也需要背景知识才可以理解自然语言。然而,对于计算机而言,理解不同的实体与概念需要规模足够大的数据集,理解实体和概念之间的相互关系需要丰富的语义关系,因此高质量结构化的知识是帮助计算机理解自然语言的关键。近年来,知识图谱(kg)作为知识的一种结构化形式,引起了人们的广泛关注。知识图谱由实体、概念和关系构成。实体为真实世界中的事物,也被称作为对象或者实例。概念是实体的上位词,可以理解为实体的类别。例如提及“科学家”一般指的是一类从事科学研究的人,而非某个特定科学家。将某个实体归属于某个或某几个特定的概念可以视为概念化的过程。
3.知识图谱中的概念使机器能够更好地理解自然语言,从而在许多知识密集型领域发挥重要作用,例如个性化推荐、问答系统和常识推理等。尽管近年来许多工作在构建知识图谱方面进行了大量的努力,但现有知识图谱中的概念仍远远不够完善。例如,在广泛使用的中文知识图谱cn-dbpedia中,有近1700万个实体,但总共只有27万个概念,超过20%的实体甚至没有概念(上位词)。probase虽然是一个大型的英文知识图谱,但其中有两个或多个修饰语的细粒度概念只占30%。本发明专注于从实体的描述性文本中抽取多粒度概念以补全现有的知识图谱。
4.现有的基于文本的概念获取方法大多采用从文本中直接抽取概念的方案,可分为模式匹配方法和基于学习的方法。模式匹配方法可以获得高质量的概念,但由于该类方法严重依靠模板,因此泛化能力差,召回率较低。基于学习的方法采用经过标记数据微调的大规模预训练语言模型来抽取概念。然而,这些基于大规模预训练语言模型的方法一个不可忽视的缺点是存在“抽取偏差”问题。
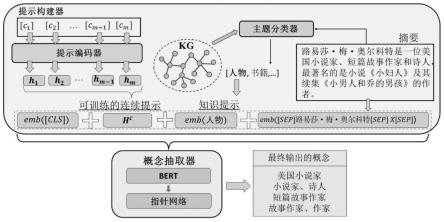
5.抽取偏差指抽取的文本片段(候选概念)是基于它们的上下文(共现)关联而不是它们真正的语义相关性来预测的,因此导致抽取精度低。导致抽取偏差的根本原因在于大规模预训练语言模型的预训练过程。在预训练期间,大规模预训练语言模型从大量语料库中挖掘统计关联,并倾向于基于共现相关性而不是文本字符串之间的真实语义关系进行预测。例如,对于图1中的实体路易莎
·
梅
·
奥尔科特,这些基于大规模预训练语言模型的概念抽取模型倾向于将“小说”和“作家”作为其概念一起抽取,因为这两个概念经常同时出现在许多文本。显然,“小说”是一个有偏差且错误的概念。
6.抽取偏差的挑战促使本发明采用语言提示的想法。通过适当的设计,语言提示可
以引导大规模预训练语言模型更好地利用从预训练中获得的知识,从而大大提高下游任务的性能。因此,本发明通过获取知识图谱中的主题知识来构造语言提示。该主题提示有助于发现目标实体与候选抽取片段(候选概念)之间基于知识的关联,因此可以指导大规模预训练语言模型区分有偏差的概念,有效地减少抽取偏差。
技术实现要素:
7.本发明的目的在于提供一种基于知识提示的概念抽取模型,以实现高质量多粒度的概念抽取。
8.本发明提出的概念抽取任务可以表述如下:给定实体e及其相关的描述性文本x,要从中抽取e的一组概念。基于这个模式,本发明提出的结合知识提示的概念抽取模型,可以抽取海量概念来提高下游任务的性能,例如知识图谱补全、本体扩展等。请注意,实现概念抽取的一个必要条件是必须保证给定的文本包含丰富的概念。本发明将从在线百科全书或知识库中获得的实体摘要文本作为输入,因为摘要总体上明确地给出了实体的概念。为了构建中文训练集,本发明从cn-dbpedia中抽取了实体及其概念和摘要文本。为了构建英语训练集,本发明从probase中获取了实体及其概念,并从wikipedia中获取了实体的摘要文本。
9.本发明提供的结合知识提示的概念抽取模型,简称kpce,其架构图如图1所示。大规模预训练语言模型的抽取偏差在基于主题知识的语言提示指导下得到了显着缓解。具体来说,目标实体的主题被用作显式离散的语言提示,因而无需复杂的模板设计。主题是从现有知识图谱的知识(包括isa关系和实体抽象文本)中获得的,有助于模型发现目标实体与候选抽取片段(候选概念)之间基于知识的关联。因此,主题提示可以指导大规模预训练语言模型区分有偏差的概念,并更有效地消除抽取偏差。此外,因为神经网络本质上是连续的,离散的语言提示可能不是最优的。因此,本发明还在连续空间中自动搜索提示,以弥合大规模预训练语言模型预训练阶段和下游自然语言处理任务之间的差距。本发明使用双向编码表示的预训练语言模型,简称bert,随机标记作为可训练的连续提示,以使模型更快地收敛。虽然将这两种提示融合到大规模预训练语言模型中的方式很简单,但已被证明是有效的,并且避免了复杂的语言提示模板对下游任务性能的影响。此外,本发明在基于语言提示的bert上附加了一个指针网络,它可以在文本中以适当的选择阈值重复抽取一个同一个片段,故而可成功抽取多粒度的高质量概念。
10.具体来说,本发明提供的基于知识提示的概念抽取模型,包括两个模块:提示构建器和概念抽取器;其中:
11.(1)提示构建器:在kpce的这个关键组件中,给定实体的主题被用作大规模预训练语言模型bert的知识引导提示。此外,还添加一个可训练的连续提示,以增强概念抽取性能;
12.(2)概念抽取器:基于构造的提示,概念抽取器利用提示引导bert以及一指针网络从输入文本中抽取多粒度、高质量的概念。
13.下面分别详细阐述模型各部分的具体细节,其中,粗体小写字母表示向量,粗体大写字母表示矩阵。
14.(1)提示构建器
15.在本发明的框架中,kpce模型将bert作为大规模预训练语言模型,并通过基于语言提示的范式整合外部知识,以增强bert的概念抽取的效果。具体来说,kpce使用给定实体的主题作为知识引导提示,它是基于来自现有知识图谱的外部知识来识别的。在预训练过程中,大规模预训练语言模型从大量语料库中挖掘统计关联,并倾向于基于共现相关性而不是文本字符串之间的真实语义关系进行预测,因此基于大规模预训练语言模型的概念抽取模型倾向于将与实体相关的所有概念都同时抽取。然而相关的概念并不一定属于实体的上位概念,从而导致抽取偏差和低质量的抽取结果。但是,如果可以提示模型输入实体的主题。在这种情况下,基于大规模预训练语言模型的概念抽取模型会降低抽取偏差概念的可能性,从而有效缓解抽取偏差的问题。例如,以图1中的实体路易莎
·
梅
·
奥尔科特,基于大规模预训练语言模型的概念抽取模型倾向于将“小说”和“作家”作为路易莎
·
梅
·
奥尔科特的概念同时抽取,但是,如果可以提示模型路易莎
·
梅
·
奥尔科特的主题是人物而不是书籍。在这种情况下,基于大规模预训练语言模型的概念抽取模型会降低抽取“小说”的可能性或增加抽取“作家”的可能性。
16.(1.1)知识引导的语言提示构建。以cn-dbpedia为例。本发明首先从知识图谱中随机抽取了100万个实体,并得到它们现有的概念(上位词)。然后,kpce选择实体(实例)最多的前100个概念构成“典型概念”集合,该集合可以覆盖知识图谱中超过99.8%的实体。接下来,kpce使用谱聚类和自适应k-means算法将这些典型概念聚类成几组,每组对应一个主题。为了实现谱聚类,kpce首先使用重叠系数来衡量两个概念之间的相似度:
[0017][0018]
其中,ent(c1)和ent(c2)分别是概念c1和概念c2的实体集。δ是一个参数,用于避免某些概念在知识图谱中没有实体时分母为零的情况。依据上述相似度,可以构建典型概念的相似度矩阵。为了确定概念集群的最佳数量,本发明计算了2到30个集群的轮廓系数(sc)和calinskiharabaz指数(chi),从中发现最好的聚类数是17。因此,将典型概念聚类为17个组,并为每个组定义一个主题名称。为了识别给定实体的主题,本发明通过基于bert的分类器将实体摘要的主题预测为上述17个典型主题之一。为了训练基于bert的主题分类器,本发明随机抽取40,000个实体及其在知识图谱中的现有概念。根据概念聚类结果,可以确定每个实体的主题。具体来说,将以下标记作为分类器的输入:
[0019]
{[cls]e[sep]x[sep]}
ꢀꢀ
(1)
[0020]
其中,[cls]和[sep]是特殊标记(令牌)。e={e1,e2,...,eq}是给定实体e的标记序列,x={x1,x2,...,xn}是输入文本x的标记序列。通过对输入标记序列的多头自注意操作,分类器获取标记[cls]的最终隐藏状态(向量),即计算主题概率分布:
[0021]
p(topic)∈r
17
,
[0022]
其中,n1是总层数,d1是向量维度。然后,将topic
text
概率最高的主题识别为x的主题,计算如下:
[0023]
h0=ew1 b1,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0024]hl
=transformor_encoder(h
l-1
),1≤l≤n1,
ꢀꢀꢀꢀꢀꢀꢀ
(3)
[0025]
[0026]
topic
text
=argmax(p(topici)),1≤i≤17.
ꢀꢀꢀꢀ
(5)
[0027]
其中,e∈r
(q n 3)
×d,是所有输入标记的初始嵌入词向量矩阵,d是嵌入大小。是第l层的隐藏矩阵,是第n1层的隐藏矩阵;是从获得的;此外,都是可训练的参数;q是向量e的维度,n是向量x的维度。
[0028]
(1.2)可训练的连续提示构建。神经网络本质上是连续的,因此上述基于知识图谱的主题可能不是最优的。因此,本发明进一步结合可训练的连续提示来增强对大规模预训练语言模型的提示效果。为了构建连续提示,kpce使用来自bert的随机标记。具体来说,对于给定的实体e,首先从bert的词汇表中随机选择m个标记,它们构成一个随机标记集,表示为c={c1,c2,...,cm}。假设e的主题标记序列记为t={t1,t2,...,tk},则c和t的连接作为e的综合提示。接下来,kpce将语言提示的标记序列与e和x连接起来,构成抽取模型的完整输入标记序列:
[0029]
([cls]ct[sep]e[sep]x[sep]}。
ꢀꢀ
(6)
[0030]
为了对t、e和x中的字符进行编码,kpce采用bert的词嵌入。kpce使用一个双向长短期记忆网络(lstm)和由relu激活的两层感知器(mlp)对连续提示进行编码,
[0031]
oc=bilstm(ec),
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0032]
hc=mlp(oc).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0033]
其中,ec∈rm×d是c的随机初始化嵌入矩阵,oc和hc是m
×
d的矩阵。然后,将结果输入到公式(6)中,可得:
[0034]
{emb([cls])hcemb(t[sep]e[sep]x[sep])},
ꢀꢀꢀꢀ
(9)
[0035]
其中,hc={h1,h2,...,hm}是可训练的嵌入组,emb(
·
)表示获取bert词嵌入的操作。经过训练,可以找到超出bert词汇表的最优连续提示。
[0036]
(2)概念抽取器
[0037]
将公式9输入到基于提示的bert与指针网络,得到候选片段(候选概念)及其相应的概念置信度分数。指针网络专门用于抽取多粒度概念。通过对输入嵌入的多头自注意力操作,bert输出最终的隐藏状态(矩阵),即其中d2是向量维度,n2是总层数。使用构建指针网络来预测每个字符作为抽取概念的开始位置和结束位置的概率。使用p
start
,p
end
∈r
(k m q n 4)
来表示所有字符分别是开始位置和结束位置的概率。它们被计算为:
[0038][0039]
其中,b∈r
(k m q n 4)
×2都是可训练的参数。为了生成抽取结果,只考虑实体摘要文本中每个字符的概率。给定一个抽取片段,以xi和xj分别作为其开始位置和结束位置的字符,则该抽取片段的置信度分数cs
ij
∈r,可以计算为:
[0040][0041]
相应地,该指针网络模型生成候选概念的排序列表及其置信度分数,并输出置信
度分数大于选择阈值的概念。请注意,一个片段可以通过适当的选择阈值作为多个抽取概念的相同子序列重复输出。例如,如图2所示,当置信度分数阈值设置为0.30时,“作家”作为三个不同粒度概念的子序列被多次抽取。因此,该策略使kpce能够抽取多粒度概念。
[0042]
在训练过程,kpce采用交叉熵函数crossentropy(
·
)作为kpce模型的损失函数。具体来说,假设集合y
start
∈n
k m q n 4
(y
end
∈n
k m q n 4
)包含作为概念开始(或结束)位置的每个输入字符的真实标签(0或1)。那么,对于这两种情况的预测,有以下两种训练损失:
[0043]
l
start
=crossentropy(p
start
,y
start
),
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0044]
l
end
=crossentropy(p
end
,y
end
),
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0045]
然后,整体训练损失为
[0046]
l=αl
start
(1-α)l
end
ꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0047]
其中,α∈(0,1)是控制参数。本发明使用adam来优化损失函数。假设θc是可训练的连续提示的参数集,θb是模型的其余参数集。kpce通过以下目标优化θc(或θb),
[0048][0049][0050]
通过此方法训练,kpce可以获得最优的连续提示,以此引导bert实现高质量多粒度的概念抽取。
附图说明
[0051]
图1为本发明的概念抽取模型kpce的框架图示。
[0052]
图2为本发明的指针网络图示。
具体实施方式
[0053]
下面通过具体实施的例子和对比实验进一步介绍本发明的优越性。
[0054]
1、评估设置。因为一些抽取的概念在知识图谱中不存在,因此无法自动评估。为了评估所有模型的抽取性能,实验邀请了一些志愿者来评估抽取概念是否正确。实验将已经作为给定实体的上位词且存在于知识图谱中的概念表示为ec(现有概念);将作为给定实体的上位词且不存在于知识图谱中的正确概念表示为nc(新概念)。由于给定实体的抽取概念可能已经作为其他实体的上位词存在于知识图谱中,因此评估统计中的nc对应于给定实体的新isa关系,而不是唯一的新概念。本发明总共雇用了四名注释者来确保评估的质量。每个概念由三个注释者标记为0、1或2,其中0表示给定实体的错误预测概念,而1和2分别代表ec和nc。如果三个注释者的结果不同,将聘请第四个注释者进行最终检查。
[0055]
2、超参数设置。实验是在配备32g内存的双geforce gtx 1080ti工作站和torch 1.7.1环境下进行的。采用具有12层和12个自注意力头的bert-base作为kpce中的主题分类器和概念抽取器。主题分类器的训练设置是:d=768,batch size=16,学习率=3e-5,dropout rate=0.1,训练epoch=2。概念抽取器的训练设置是:d=768,m=30,batch size=4,learning rate=3e-5,dropout rate=0.1,training epoch=2。此外,公式14中的α设置为0.3,概念抽取器中候选片段的选择阈值根据参数调整设置为0.12。
[0056]
3、对比实验结果及分析。将kpce与所有基线模型进行比较的评估结果列于表1中,
其中ec#和nc#分别是从500个测试实例中抽取的ec和nc的数量。从表中,可以发现kpce可以为给定的实体抽取更多的新概念,甚至可以获得知识图谱中没有的概念。因此,kpce可以抽取丰富的概念,其性能优于基线模型。进一步将kpce模型与以下消融变体进行了比较,以验证两种提示的有效性。kpce-t是没有知识引导提示(t)的概念抽取器的变体;kpce-c是没有连续提示(c)的概念抽取器的变体;kpce-t&c是没有两个提示的变体。本发明调查了它们在中文测试集和英文测试集上的表现,显示在表2中。根据结果,kpce-c和kpce-t优于kpce-t&c验证了添加知识引导提示和连续提示都表现出最大的性能提升。kpce-t优于kpce-c验证了主题提示在引导bert实现准确概念抽取方面,比连续提示更有效。
[0057]
表1
[0058][0059]
表2
[0060][0061]
此外,在表3中显示了一个实体korean alphabet,以及它抽取的前5个片段和片段对应的置信度分数,其主题在probase中被标识为科技。从这个案例的抽取结果中,可以发现两个提示(t&c)可以引导基于bert的抽取器降低错误抽取片段的置信分数(kpce-t&c中的第1和第5跨度)并增加提高抽取片段的置信分数(例如“系统”,“写作系统”),从而获得更准确的抽取结果。接着,实验将kpce与kpce
lda
进行了比较,其中主题是通过对所有实体的摘要使用lda算法获得的关键字。lda主题类的最佳数量也被确定为17。对于给定的实体,其主题被标识为其主题类别中概率最高的关键字。此外,实验还将kpce与可以隐式学习短语和实体先验知识的ernie进行了比较。比较结果列于表4中,这表明kpce设计的知识引导提示比其他两种方案更充分地利用了外部知识的价值。
neural information processing systems,2015,28.
[0074]
[5]devlin j,chang m w,lee k,et al.bert:pre-training of deep bidirectional transformers for language understanding[j].arxiv preprint arxiv:1810.04805,2018。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
