技术特征:
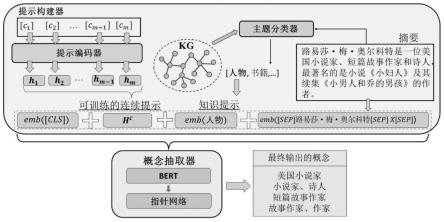
1.一种基于知识提示的概念抽取模型,其中,概念抽取任务表述如下:给定实体e及其相关的描述性文本x,要从x中抽取e的一组概念;根据此模式,提出基于知识提示的概念抽取模型,用于抽取海量概念来提高下游任务的性能,其特征在于,通过设计语言提示引导大规模预训练语言模型更好地利用预训练中获得的知识,从而提升概念抽取的性能;该模型包括两个模块:提示构建器和概念抽取器;其中:(1)提示构建器:其中,给定实体的主题被用作双向编码表示的预训练语言模型,简称bert,的知识引导提示;此外,还添加一个可训练的连续提示,以增强概念抽取性能;(2)概念抽取器:基于构建器的提示,概念抽取器利用提示引导bert以及一指针网络从输入文本中抽取多粒度、高质量的概念。2.根据权利要求1所述的基于知识提示的概念抽取模型,其特征在于,所述的提示构建器,是将bert作为大规模预训练语言模型,并通过基于语言提示的范式整合外部知识,以增强bert的概念抽取的效果;下文中,粗体小写字母表示向量,粗体大写字母表示矩阵;具体来说,使用给定实体的主题作为知识引导提示,它是基于来自现有知识图谱的外部知识来识别的;在预训练过程中,大规模预训练语言模型从大量语料库中挖掘统计关联性,并基于共现相关性而不是文本字符串之间的真实语义关系进行预测,因此,基于大规模预训练语言模型的概念抽取模型将与实体相关的所有概念都同时抽取;(1.1)知识引导的语言提示构建;首先从知识图谱中随机抽取100万个实体,并得到它们现有的概念,即上位词;然后,选择实体最多的前100个概念构成典型概念集合,该集合覆盖知识图谱中超过99.8%的实体;接下来,使用谱聚类和自适应k-means算法将这些典型概念聚类成几组,每组对应一个主题;为了实现谱聚类,首先使用重叠系数来衡量两个概念之间的相似度:其中,ent(c1)和ent(c2)分别是概念c1和概念c2的实体集,δ是一个参数,用于避免某些概念在知识图谱中没有实体时分母为零的情况;依据上述相似度,构建典型概念的相似度矩阵;为了确定概念集群的最佳数量,计算2到30个集群的轮廓系数(sc)和calinskiharabaz指数(chi),从中得到最好的聚类数是17;因此,将典型概念聚类为17个组,并为每个组定义一个主题名称;为了识别给定实体的主题,通过基于bert的分类器将实体摘要的主题预测为上述17个典型主题之一;为了训练基于bert的主题分类器,随机抽取40,000个实体及其在知识图谱中的现有概念,根据概念聚类结果,确定每个实体的主题;具体来说,将以下标记作为分类器的输入:{[cls]e[sep]x[sep]}
ꢀꢀꢀꢀ
(1)其中,[cls]和[sep]是特殊标记;e={e1,e2,...,e
q
}是给定实体e的标记序列,x={x1,x2,...,x
n
}是输入文本x的标记序列;通过对输入标记序列的多头自注意操作,分类器获取标记[cls]的最终隐藏状态,即计算主题概率分布:p(topic)∈r
17
,其中,n1是总层数,d1是向量维度;然后,将topic
text
概率最高的主题识别为x的主题,计算如下:
h0=ew1 b1,
ꢀꢀꢀꢀ
(2)h
l
=transformor-encoder(h
l-1
),1≤l≤n1,
ꢀꢀꢀꢀ
(3)topic
text
=argmax(p(topic
i
)),1≤i≤17;
ꢀꢀꢀꢀ
(5)其中,e∈r
(q n 3)
×
d
,是所有输入标记的初始嵌入词向量矩阵,d是嵌入大小;是第l层的隐藏矩阵,是第n1层的隐藏矩阵;是从获得的;此外,都是可训练的参数;q是向量e的维度,n是向量x的维度;(1.2)可训练的连续提示构建;为了构建连续提示,使用来自bert的随机标记;具体地,对于给定实体e,首先从bert的词汇表中随机选择m个标记,构成一个随机标记集,表示为c={c1,c2,...,c
m
};假设e的主题标记序列记为t={t1,t2,...,t
k
},则c和t的连接作为e的综合提示;接下来,将语言提示的标记序列与e和x连接起来,构成抽取模型的完整输入标记序列:{[cls]ct[sep]e[sep]x[sep]};
ꢀꢀꢀꢀ
(6)为了对t、e和x中的字符进行编码,采用bert的词嵌入;具体使用一个双向长短期记忆网络(lstm)和由relu激活的两层感知器(mlp)对连续提示进行编码:o
c
=bilstm(e
c
),
ꢀꢀꢀꢀ
(7)h
c
=mlp(o
c
).
ꢀꢀꢀꢀ
(8)其中,e
c
∈r
m
×
d
是c的随机初始化嵌入矩阵,o
c
和h
c
是m
×
d的矩阵;然后,将结果输入到公式(6)中,得:{emb([cls])h
c
emb(t[sep]e[sep]x[sep])},
ꢀꢀꢀꢀ
(9)其中,h
c
={h1,h2,...,h
m
}是可训练的嵌入组,emb(
·
)表示获取bert词嵌入的操作;经过训练,可以找到超出bert词汇表的最优连续提示。3.根据权利要求2所述的基于知识提示的概念抽取模型,其特征在于,所述的概念抽取器中,将公式9输入到基于提示的bert与指针网络,得到候选片段即候选概念,及其相应的概念置信度分数;其中,指针网络用于抽取多粒度概念;通过对输入嵌入的多头自注意力操作,bert输出最终的隐藏状态,即其中d2是向量维度,n2是总层数;使用构建指针网络来预测每个字符作为抽取概念的开始位置和结束位置的概率;使用p
start
,p
end
∈r(
k m q n 4
)来表示所有字符分别是开始位置和结束位置的概率,它们被计算为:其中,b∈r
(k m q n 4)
×2,都是可训练的参数;为了生成抽取结果,只考虑实体摘要文本中每个字符的概率,给定一个抽取片段,以x
i
和x
j
分别作为其开始位置和结束位置的字符,则该抽取片段的置信度分数cs
ij
∈r,计算式为:相应地,指针网络模型生成候选概念的排序列表及其置信度分数,并输出置信度分数大于选择阈值的概念;
在训练过程,采用交叉熵函数crossentropy(
·
)作为kpce模型的损失函数;具体地,假设集合y
start
∈n
k m q n 4
或y
end
∈n
k m q n 4
包含作为概念开始或结束位置的每个输入字符的真实标签,则对于这两种情况的预测,有以下两种训练损失:l
start
=crossentropy(p
start
,y
start
),
ꢀꢀꢀꢀ
(12)l
end
=crossentropy(p
end
,y
end
),
ꢀꢀꢀꢀ
(13)然后,整体训练损失为l=αl
start
(1-α)l
end
ꢀꢀꢀꢀ
(14)其中,α∈(0,1)是控制参数;使用adam来优化损失函数;假设θ
c
是可训练的连续提示的参数集,θ
b
是模型的其余参数集;通过以下目标优化θ
c
或θ
b
,,通过训练,获得最优的连续提示,以此引导bert实现高质量多粒度的概念抽取。4.根据权利要求3所述的基于知识提示的概念抽取模型,其特征在于,从cn-dbpedia中抽取实体及其概念和摘要文本,构建中文训练集;从probase中获取实体及其概念,并从wikipedia中获取实体的摘要文本,构建英语训练集。
技术总结
本发明属于人工智能与知识工程技术领域,具体为一种基于知识提示的概念抽取模型,简称KPCE。本发明模型包括提示构建器和概念抽取器;提示构建器,给定实体的主题用作双向编码表示的预训练语言模型,简称BERT,的知识引导提示;并添加可训练的连续提示,以增强概念抽取性能;概念抽取器利用提示引导BERT以及指针网络从输入文本中抽取多粒度、高质量的概念。本发明使用从现有知识图谱中获取的主题知识构建语言提示,同时考虑神经网络连续性特征,将可训练的连续提示与上述主题构建的知识提示结合,以此提升大规模预训练语言模型BERT在概念抽取任务上的性能;还借助指针网络,设置适当的阈值重复抽取文本中同一片段,实现多粒度概念的获取。度概念的获取。度概念的获取。
技术研发人员:员司雨 阳德青 肖仰华
受保护的技术使用者:复旦大学
技术研发日:2022.04.20
技术公布日:2022/8/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。