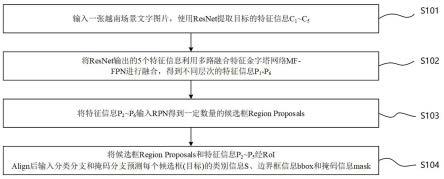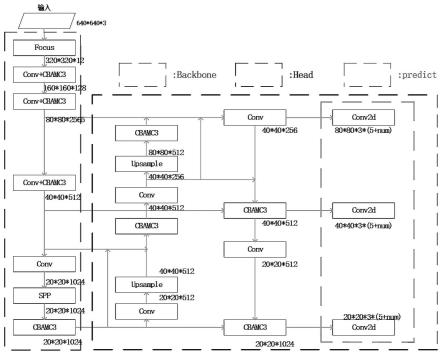
基于改进yolov5的跌倒行为检测方法及系统
技术领域
1.本发明涉及老年人监护监测技术,具体涉及基于改进yolov5的跌倒行为检测方法及系统。
背景技术:
2.世界老年人口正在迅速增长。在中国,65岁以上人口占总人口的10.1%,到2050 年将增加到35%左右[1]。在日本,内部事务和通信省统计局的数据显示,2019年,65 岁以上的人占总人口的28.4%[2]。随着年龄的增长,以及高血压、低血压、膝关节疼痛等身体疾病的存在,老年人逐渐不能稳定地控制自己的运动,导致跌倒次数增多。根据世界卫生组织的数据表明,跌倒是意外死亡的第二大原因[3]。老年人若因严重受伤或昏迷摔倒,无法及时寻求帮助,很可能导致死亡。因此,提出一种有效的跌倒检测方法是十分必要的。
[0003]
近年来,跌倒检测方法根据获取跌倒特征方式的不同主要分为三类:基于可穿戴传感器的方法、基于环境传感器的方法和基于计算机视觉的方法。
[0004]
基于可穿戴传感器的方法主要通过让老年人佩戴特定的传感器来确定他们的行为状态或位置信息。大部分的研究都是基于加速度计的研究,其方法是通过分析和采集多个轴的加速度来判断是否发生跌倒。例如,chaitep和chawachat提出了一种算法,该算法使用加速度计读数导出的重力值来检测下落。shahzad等人在2017年实现了一种基于加速度计的跌倒事件检测系统,随后他们进一步提出了一种仅使用加速度计的高精度跌倒检测方法。在文献,yacchirema等人,2018年的另一项研究中,作者将3d轴加速度计嵌入6lowpan可穿戴设备中,以收集运动信息,并应用决策树算法来识别跌倒。虽然相比较与环境传感器而言,采用穿戴传感器的方法检测跌倒要更加便宜、更容易操作。然而,它们的最大缺点是侵入性很强。
[0005]
基于环境传感器的方法,文献将传感器放置在室内,用于检测不同的信号。信号主要包括压力、振动、音频、红外阵列、wi-fi、雷达等。这种跌倒检测方法的主要原理是利用无线技术识别物体周围环境的变化,从而通过无线信号的变化判断人体行为状态。相比于可穿戴式设备,它的优点在于可以在老年人不戴任何设备的情况下判断是否发生跌倒,起到了很好的隐私保护作用。然而,这种方法成本较高,并且由于需要不断地接收信号,这对于传感器的位置有一定要求,从而导致检测距离有所限制。
[0006]
随着计算机视觉和目标检测的发展,基于计算机视觉的跌倒检测已成为一种重要的方法,该系统对老年人的入侵小,精度高,鲁棒性强。目前,根据是否需要形成候选框,目标检测算法可分为两类:一类是需要形成候选框的两阶段目标检测算法,另一类是不需要生成候选框的一阶段目标检测算法。基于两个阶段的检测方法主要包括:rcnn、 spp-net、fast-rcnn、faster-rcnn、mask-rcnn等。基于一阶段的检测算法主要有yolo 系列算法和ssd算法。公开号为cn112560723a的发明专利申请文献《一种基于形态识别与速度估计的跌倒检测方法及系统》包括构建形态识别模型和速度估计模型;获取待检测的视频流,待检测的视频流包括连续的若干帧图像;将待检测的视频流输入至速度估计模型中,得到待检测
的视频流所对应的人体形态变化速度;将待检测的视频流输入至形态识别模型,形态识别模型检测每一帧图像中的人体形态,并按照时间序列关联同一人物的人体形态,输出若干帧图像中每个人物的人体形态变化过程;根据人体形态变化速度以及人体形态变化过程,判断待检测的视频流中是否发生跌倒事件。该现有专利申请文献还披露了下述技术方案:关联人体形态,即将同一人物在不同帧中的人物候选框进行关联,从而得到每个人物的人体形态变化过程。多目标候选框前后帧关联有多种方式,下面举例说明:维护“正在追踪目标候选框”列表;获取最新图像帧中的人物候选框信息,记作“当前候选框信息”,计算“当前候选框信息”与“正在追踪目标候选框”的交并比,通过匈牙利算法实现候选框匹配;若当前候选框中存在无匹配样本,则添加到“正在追踪目标候选框”列表;若“正在追踪目标候选框”列表中存在无匹配样本,则在列表中删除该元素。构建的形态识别模型可以是包括目标检测网络(常用网络包括yolo/ssd/faster r-cnn)和候选框关联网络(常用网络包括deepsort)。或者,形态识别模型可以是包括多目标姿态估计网络(常用网络包括openpose/hrnet/rsn)、单人骨架分类网络(常用网络包括gcn)以及候选框关联网络(常用网络包括deepsort)。由于事先需要设好候选框,因此两阶段的目标检测算法的精度相比于一阶段的要高,但是检测速度会相对较慢。
[0007]
综上,现有技术存在平均精度低、侵入性强、适用场景受有限制以及检测速度慢的技术问题。
技术实现要素:
[0008]
本发明所要解决的技术问题在于如何解决现有技术存在的平均精度低、侵入性强、适用场景受有限制以及检测速度慢的技术问题。
[0009]
本发明是采用以下技术方案解决上述技术问题的:基于改进yolov5的跌倒行为检测方法包括:
[0010]
s1、加载预置yolov5模型,初始化所述预置yolov5模型的参数;
[0011]
s2、采集并预处理图像数据,据以得到训练数据集验证数据,根据所述训练数据提取图像特征并进行物体定位分类,计算损失函数,利用sgd优化所述预置yolov5模型的网络参数,根据所述验证数据计算map,据以迭代获取适用模型,其中,所述步骤s2 中采用预置ciou损失函数作为预测框偏差的指标;
[0012]
s3、采集并输入测试图片至所述适用模型,据以进行位置及分类预测,计算向前推导及nms所用时间,据以在所述测试图片上画出最终跌倒行为识别结果,其中,所述步骤s3还包括:
[0013]
s31、在所述预置yolov5模型中的残差组件后加入cbam注意力机制,以卷积块注意力模型对所述测试图片的特征图进行最大池化、平均池化、拼接操作以及卷积操作,据以生成单通道矩阵,据以得到卷积块注意力处理结果;
[0014]
s32、将所述卷积块注意力处理结果输入到sigmoid激活函数,以得到主干网络特征;
[0015]
s33、在所述预置yolov5模型中的特征金字塔中采用bifpn结构,据以对不少于2 种尺度的所述主干网络特征进行双向跨尺度连接以及加权特征融合,以得到跨尺度特征融合识别数据,据以获取所述最终跌倒行为识别结果。
[0016]
本发明将yolov5的边界框损失函数giou更换为ciou,然后在yolov5的主干网络中的残差组件后加入卷积块注意力机制(convolutional block attention module, cbam)模块,该机制将位置信息嵌入到通道注意力当中,使网络可以更专注地学习跌倒这一特征;最后将特征融合层的特征金字塔网络结构替换成加权双向特征金字塔(bifpn) 网络结构,充分利用不同尺度的特征,从而提高检测精度。
[0017]
在更具体的技术方案中,所述步骤s2中,以下述逻辑计算所述预置ciou损失函数:
[0018][0019]
loss
ciou
=1-ciou
[0020][0021]
其中,b代表预测框的中心点,b
gt
代表真实框的中心点,ρ表示计算b和b
gt
之间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离、α是权重参数、v则是度量长宽比一致性的参数。
[0022]
本发明通过以上操作,ciou在设计预测边界框时把重叠面积、中心点的间距,以及长宽比都纳入考虑。本发明以ciou损失函数代替原yolov5模型中的giou,作为yolov5 新的边界框损失函数,实现更加准确地检测跌倒行为。
[0023]
在更具体的技术方案中,所述步骤s31包括:
[0024]
s311、在所述预置yolov5模型中的残差组件后加入cbam注意力机制,以形成 cbamc3模块;
[0025]
s312、以所述cbamc3模块中的通道注意力模块对所述测试图片的特征图进行最大池化及平均池化操作,以得到池化一维向量;
[0026]
s313、将所述池化一维向量传递到预置的多层感知机mlp;
[0027]
s314、通过预置乘逻辑处理获得所述调整通道注意力特征图;
[0028]
s315、以所述cbamc3模块中的空间注意模块对所述调整注意力特征图进行最大池化和平均池化操作,将两层进行拼接操作,并用7
×
7的卷积核进行卷积操作以生成所述单通道矩阵,据以获取所述卷积块注意力处理结果。
[0029]
本发明中的cbamc3模块在进行特征提取时会增加一项注意力机制的计算,其作用是对特征图中的不同目标进行不同维度上的注意力加权计算,提高算法对特征图中主要特征的提取,以此来提高目标检测算法的准确性。本发明通过添加注意力机制,即使是跌倒后有部分遮挡且周围有其他物体干扰的情况下也有很好的检测效果,解决了室内环境较为复杂的情况下出现漏检、误检的问题。
[0030]
在更具体的技术方案中,所述步骤s314中,通过下述逻辑处理获得所述调整通道注意力特征图:
[0031][0032]
其中,w1和w2表示权重,和表示平均池化和最大池化后的feature map,σ为sigmoid激活函数。
[0033]
在更具体的技术方案中,所述步骤s32中,通过下述逻辑,利用所述sigmoid激活函数处理所述卷积块注意力处理结果:
[0034][0035]ms
=σ(f
7*7
(fs))
[0036]
在更具体的技术方案中,所述步骤s33包括:
[0037]
s331、取消pan中仅有一个输入边的节点;
[0038]
s332、在所述pan中的同级别的输入节点和输出节点之间增加一条额外的边;
[0039]
s333、将每个双向路径作为一个特征网络层,以进行高层次特征融合。
[0040]
在更具体的技术方案中,所述步骤s333中,以下述逻辑进行加权特征融合:
[0041][0042]
其中,以激活函数relu保证权重wi≥0,该权值的获取方式包括:网络训练,ii表示输入的特征。
[0043]
本发明采用的特征融合可以将图像中提取的特征进行融合,使其具有更强的分辨力。因此,将高、低特征进行适当地融合对提高目标检测模型准确度有很大作用。本发明将yolov5结构中的pan模块替换成bifpn,来加强特征融合,提高检测准确度。
[0044]
在更具体的技术方案中,所述步骤s33中,以bifpn对主干网络提取出的三种不同尺度的特征,利用下述逻辑进行跨尺度连接和加权特征融合,以得到所述跨尺度特征融合识别数据:
[0045][0046][0047]
其中,为自上而下的中间特征,为自下而上的输出特征,resize为上采样或下采样操作,conv为卷积操作。
[0048]
在更具体的技术方案中,所述步骤s2还包括:
[0049]
s21、采用召回率、精准率、平均精度均值map作为实验评价指标;
[0050]
s22、以下述逻辑处理得到精确度:
[0051][0052]
s23、以下述逻辑处理得到所述召回率:
[0053][0054]
s24、以所述召回率recall为横轴,以所述精确度precision为纵轴组成的曲线,以下述逻辑处理得到所述曲线围成的面积,以作为所述平均精度ap:
[0055][0056]
s25、利用下述逻辑处理所述平均精度ap,以得到所述平均精度均值map:
[0057][0058]
其中m表示测试集中的样本个数。
[0059]
在更具体的技术方案中,基于改进yolov5的跌倒行为检测系统包括:
[0060]
模型加载初始化模块,用以加载预置yolov5模型,初始化所述预置yolov5模型的参数;
[0061]
模型训练模块,用以采集并预处理图像数据,据以得到训练数据集验证数据,根据所述训练数据提取图像特征并进行物体定位分类,计算损失函数,利用sgd优化所述预置yolov5模型的网络参数,根据所述验证数据计算map,据以迭代获取适用模型,所述模型训练模块与所述模型加载初始化模块连接,其中,所述步骤s2中采用预置ciou损失函数作为预测框偏差的指标;
[0062]
跌倒识别模块,用以采集并输入测试图片至所述适用模型,据以进行位置及分类预测,计算向前推导及nms所用时间,据以在所述测试图片上画出最终跌倒行为识别结果,所述跌倒识别模块与所述模型训练模块连接,其中,所述步骤s3还包括:
[0063]
卷积块注意力模块,用以在所述预置yolov5模型中的残差组件后加入cbam注意力机制,以卷积块注意力模型对所述测试图片的特征图进行最大池化、平均池化、拼接操作以及卷积操作,据以生成单通道矩阵,据以得到卷积块注意力处理结果;
[0064]
主干网络特征模块,用以将所述卷积块注意力处理结果输入到sigmoid激活函数,以得到主干网络特征,所述主干网络特征模块与所述卷积块注意力模块连接;
[0065]
跨尺度融合识别模块,用以在所述预置yolov5模型中的特征金字塔中采用bifpn 结构,据以对不少于2种尺度的所述主干网络特征进行双向跨尺度连接以及加权特征融合,以得到跨尺度特征融合识别数据,据以获取所述最终跌倒行为识别结果,所述跨尺度融合识别模块与所述主干网络特征模块连接。
[0066]
本发明相比现有技术具有以下优点:本发明将yolov5的边界框损失函数giou更换为ciou,然后在yolov5的主干网络中的残差组件后加入卷积块注意力机制(convolutional block attention module,cbam)模块,该机制将位置信息嵌入到通道注意力当中,使网络可以更专注地学习跌倒这一特征;最后将特征融合层的特征金字塔网络结构替换成加权双向特征金字塔(bifpn)网络结构,充分利用不同尺度的特征,从而提高检测精度。
[0067]
本发明通过以上操作,ciou在设计预测边界框时把重叠面积、中心点的间距,以及长宽比都纳入考虑。本发明以ciou损失函数代替原yolov5模型中的giou,作为yolov5 新的边界框损失函数,实现更加准确地检测跌倒行为。
[0068]
本发明中的cbamc3模块在进行特征提取时会增加一项注意力机制的计算,其作用是对特征图中的不同目标进行不同维度上的注意力加权计算,提高算法对特征图中主要特征的提取,以此来提高目标检测算法的准确性。本发明通过添加注意力机制,即使是跌倒后有部分遮挡且周围有其他物体干扰的情况下也有很好的检测效果,解决了室内环境较为复
杂的情况下出现漏检、误检的问题。本发明解决了现有技术中存在的平均精度低、侵入性强、适用场景受有限制以及检测速度慢的技术问题。
附图说明
[0069]
图1为本发明实施例1的yolov5轻量级监测模型示意图;
[0070]
图2为本发明实施例1的mosaic数据增强效果图;
[0071]
图3为本发明实施例1的focus结构图;
[0072]
图4为本发明实施例1的切片操作示意图;
[0073]
图5a为本发明实施例1的c3结构示意图;
[0074]
图5b为本发明实施例1的c3残差结构示意图;
[0075]
图6为本发明实施例1的spp结构示意图;
[0076]
图7为本发明实施例1的cbam注意力模块示意图;
[0077]
图8为本发明实施例1的加入cbam注意力机制前的bottleneck模块结构图;
[0078]
图9为本发明实施例1的加入cbam注意力机制后的bottleneck模块结构图;
[0079]
图10a为本发明实施例1的yolov5检测效果图;
[0080]
图10b为本发明实施例1的添加注意力机制yolov5_ccb检测效果图;
[0081]
图11a为本发明实施例1的特征融合结构pan示意图;
[0082]
图11b为本发明实施例1的特征融合结构bifpn示意图;
[0083]
图12为本发明实施例1的yolov5_ccb网络结构示意图;
[0084]
图13为本发明实施例2的模型训练及图片识别整体流程示意图;
[0085]
图14为本发明实施例3的yolov5_ccb与yolov5边界框loss对比图;
[0086]
图15为本发明实施例3的yolov5_ccb检测跌倒效果图。
具体实施方式
[0087]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0088]
实施例1
[0089]
如图1所示,yolov5目标检测算法是基于pytorch框架的一个轻量级检测模型,根据模型的大小分4个版本,分别为yolov5s、yolov5m、yolov5l、yolov5x,这4个模型的宽度和深度依次增加。本文将使用yolov5x模型进行检测及改进。
[0090]
yolov5网络模型分为输入(input)、主干(backbone)、头部(head)和预测 (prediction)四部分。
[0091]
1.1输入端
[0092]
如图2所示,yolov5的输入端主要包括马赛克(mosaic)数据增强、自适应计算锚框和自适应缩放图像三个部分。马赛克(mosaic)数据增强在yolov4已经得到使用,并且效果很好。mosaic数据增强原理跟cutmix数据增强类似,不同之处在于,cutmix数据增强仅随机拼接两张图片,而mosaic数据增强通过随机缩放、剪裁和排列来拼接四张图片。这样做的好
处是有助于小目标的检测效果,其结果如图2所示。自适应锚框计算,可以根据不同类别训练出最佳锚框。自适应缩放图片是指采用缩减黑边的方式将原图片缩放到统一尺寸,通过对不同尺寸的图片自适应添加不同大小的黑边,从而尽可能减少图像高度上两端的黑边,使得在推理阶段减少计算,提高目标检测速度。
[0093]
1.2主干网络
[0094]
如图3至图6所示,主干网络主要包含focus、c3和spp三个模块。其中focus模块通过对输入图片进行类似于邻近下采样的切片操作,可得到2倍信息的下采样特征图,其结构图及切片操作如图3、图4所示。c3模块主要是为了从网络结构设计的角度解决推理中计算量过大的问题,其具体结构如图5a及图5b所示。spp模块通过对特征层卷积后得到的特征图进行不同尺度上的最大池化,从而增大感受野,增强网络的非线性表达能力。
[0095]
1.3neck模块
[0096]
neck模块主要用于融合不同尺度的特征,增强模型对于不同缩放尺度对象的检测,从而识别不同大小的特征图。yolov5颈部采用fpn pan结构。fpn是一种自上而下的特征金字塔结构,通过上采样传输高层特征信息并进行融合,得到预测特征图。虽然 fpn能够传递很强的语义信息,但是对于特征图的空间信息有很大的缺失。而pan是一种自下而上的金字塔结构,通过自下向上传达强定位特征,从不同的主干层对不同的检测层进行特征融合。
[0097]
1.4输出端
[0098]
yolov5输出端的激活函数使用sigmoid,边界框损失函数使用giou,并使用nms (非极大值抑制)对满足iou阈值的多目标框再次进行筛选,提高多目标检测能力。
[0099]
2模型的改进及优化
[0100]
2.1主干网络的改进
[0101]
近年来,注意机制已成为神经网络的重要组成部分,并应用于计算机视觉的各种任务。注意力机制的加入可以增强复杂背景中跌倒目标的特征表达能力,增强特征图中的重要通道和空间特征,从而有效提高目标定位精度。
[0102]
如图7所示,卷积块注意力模型(convolutional block attention module,cbam) 是一种轻量级的注意机制,它将空间注意和通道注意以顺序模式结合起来。请参阅图7,它由channel attention module(cam)和spatial attention module sam(sam)两个子模块构成,分别负责channel attention和spatial attention。
[0103]
通道注意力模块将输入特征图经过最大池化和平均池化操作,然后将池化后的两个一维向量传递到一个多层感知机(multilayer perception,简称mlp),再将通道注意力与输入元素相乘,获得通道注意力调整后的特征图。对应公式如 (1)所示。
[0104][0105]
其中,w1和w2表示权重,和表示平均池化和最大池化后的feature map,σ为sigmoid激活函数。
[0106]
空间注意模块的输入来自于通道注意力模块的输出,将输入的特征图分别进行最大池化和平均池化操作,然后将两层进行拼接操作,并用7
×
7的卷积核进行卷积操作生成单通道矩阵。最后,同样地将结果输入到sigmoid激活函数。对应公式如(2)(3)所示。
[0107][0108]ms
=σ(f
7*7
(fs))
ꢀꢀꢀ
(3)
[0109]
如图8至图10b所示,因此,本文在yolov5模型的c3模块中的残差组件后加入cbam 注意力机制,形成新的c3模块——cbamc3,这表示c3模块在进行特征提取时会增加一项注意力机制的计算,其作用是对特征图中的不同目标进行不同维度上的注意力加权计算,提高算法对特征图中主要特征的提取,以此来提高目标检测算法的准确性。加入 cbam注意力机制前后的bottleneck模块结构图如图8、图9所示,加入前后检测效果对比如图10a及图10b所示。从对比图中可以看出,添加注意力机制之后,即使是跌倒后有部分遮挡且周围有其他物体干扰的情况下也有很好的检测效果,解决了室内环境较为复杂的情况下出现漏检、误检的问题。
[0110]
2.2特征金字塔结构的改进
[0111]
如何有效地表示和处理多尺度特征一直是目标检测模型研究的重点。特征融合可以将图像中提取的特征进行融合,使其具有更强的分辨力。因此,将高、低特征进行适当地融合对提高目标检测模型准确度有很大作用。
[0112]
yolov5模型采用fpn pan结构进行多尺度特征融合。fpn采用自顶向下的方法组合多尺度特征,从而增强了特征图的语义信息,但由于高层特征图的分辨率较低,导致空间信息缺失。为了解决这一问题,在原先的基础上增加了一个自底向上的路径聚合网络 pan,以增强特征图的空间信息。虽然pan比fpn的精度更高,但它的代价是计算量大并且参数更多。bifpn结构在pan结构的基础上做了一些改变。如图11a及图11b所示, bifpn对pan有以下三个主要变化:
[0113]
(1)直接取消只有一个输入边的节点,该节点不再进行特征融合,以此达到简化特征网络的目的。
[0114]
(2)对于同级别的输入节点和输出节点,在它们之间增加一条额外的边,这样可以融合更多的特性。
[0115]
(3)不同于pan只有一条自底向上的路径和一条自底向下的路径,bifpn将每个双向路径作为一个特征网络层来实现更高层次的特征融合。
[0116]
其主要特点是双向跨尺度连接及加权特征融合。双向跨尺度连接:首先是删除了只有一个输入的节点,该节点无特征融合且贡献度很小,将该节点删除之后没有很大影响而且会简化网络;然后是在原始输入节点和输出节点之间增加了一条边,在不消耗更多成本的情况下让其可以融合更多的特征。加权特征融合:bifpn使用的是快速归一化融合,直接用权值除以所有权值加和来进行归一化,同时将权值归一化到[0,1]之间,提高了计算速度,其计算公式如(4)所示。
[0117][0118]
其中用激活函数relu来确保权重wi≥0,该权值由网络训练得到,ii表示输入的特征,并使用softmax来进行归一化。改进后,bifpn的输入来自主干网络提取出的三种不同尺度的特征p3、p5、p7,将三种不同尺度特征进行跨尺度连接和加权特征融合,最后在输出端设置三种不同尺度的特征分辨率的预测分支。以节点p6为例,其形成的两个融合特征过程
公式如(5)(6)所示
[0119][0120][0121]
如图11a及图11b所示,其中为自上而下的中间特征(请参阅图11b),为自下而上的输出特征(请参阅图11b),resize为上采样或下采样操作,conv为卷积操作。
[0122]
基于以上优点,本文将yolov5结构中的pan模块替换成bifpn,来加强特征融合,提高检测准确度。
[0123]
2.3损失函数
[0124]
损失函数可以很好的反应模型和实际数据间的差异,yolov5原网络使用giou函数作为输出端的边界框损失函数,其计算公式如(7)(8)(9)所示。
[0125][0126][0127]
loss
giou
=1-giou
ꢀꢀꢀ
(9)
[0128]
然而,giou也有一些问题,即当实际框和预测框处于包含关系,或者两者的宽度和高度对齐时,根据上述的公式可知giou会退化为iou。此时,将无法判断真实框与预测框的相对位置,使得目标定位不准确,影响最终检测精度。
[0129]
因此本文使用ciou损失函数作为预测框偏差的指标,ciou损失函数的计算公式如 (10)(11)(12)所示。
[0130][0131]
loss
ciou
=1-ciou
ꢀꢀꢀ
(11)
[0132][0133]
其中,b代表预测框的中心点,b
gt
代表真实框的中心点,ρ表示计算b和b
gt
之间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离、α是权重参数、v则是度量长宽比一致性的参数。通过以上操作,ciou在设计预测边界框时把重叠面积、中心点的间距,以及长宽比都考虑进去了。
[0134]
综上,在本文研究的跌倒行为检测中将使用ciou损失函数代替原yolov5模型中的 giou,作为yolov5新的边界框损失函数,实现更加准确地检测跌倒行为。
[0135]
2.4改进后的yolov5网络结构及参数列表
[0136]
如图12所示yolov5本身已经是一个效果不错的目标检测算法,但模型依然存在一定的问题并且为了结合跌倒行为检测这一实际应用,需要对其进行模块或结构上的改进。根据前面章节的理论分析与研究,可以得到将边界框损失函数更换为ciou、引入 cbam注意力机制以及更改特征融合层为bifpn结构后的yolov5算法—— yolov5-ccb(yolov5-ciou
cbam bifpn),其模型结构、模型参数列表如下表2-1所示:
[0137]
表2-1 yolov5_ccb模型参数列表
[0138]
[0139][0140]
表中自左向右的列分别表示:序号、输入数据来自哪一层(-1表示来自上一层的输出)、模块参数的计算量、子模块名、模块具体的参数信息(包括输入/输出通道数、卷积核大小、步长信息等)。
[0141]
实施例2
[0142]
本实验整体实现
[0143]
模型训练算法
[0144][0145]
整体流程
[0146]
本实验的整体流程图如图13所示,模型训练及图片识别整体流程包括以下具体步骤:
[0147]
s1、加载模型及初始化参数;
[0148]
s2、数据预处理;
[0149]
s3、特征提取及物体定位分类;
[0150]
s4、计算损失函数;
[0151]
s5、适用sgd进行网络参数更新优化;
[0152]
s6、根据验证数据在验证集上计算map;
[0153]
s7、判断最好性能衡量值是否更新;
[0154]
s8若是,则覆盖保存为最佳模型;
[0155]
s9、若否,则怕安段跌倒次数是否到达最终步;
[0156]
s10、若是,则得到最佳模型,完成模型训练,若否,则持续进行特征提取及物体定位分类;
[0157]
s11、选择最佳模型,输入测试数据至最佳模型;
[0158]
s12、进行位置和分类预测;
[0159]
s13、计算向前推导及nms所用时间;
[0160]
s14、在输入图片上画出最终识别结果。
[0161]
在本实施例中,首先是准备数据集,该数据集包含网上公开的跌倒数据集和网络中爬取的图片进行标注后得到的自制跌倒数据集,然后将数据集划分为训练集、测试集和
验证集。之后按照图13中描述的流程进行训练,得到最优的跌倒检测模型,最后对测试集数据进行测试得到训练结果。
[0162]
实施例3
[0163]
数据集介绍
[0164]
本文使用的数据集包括公开数据集和自制数据集,公开数据集采用le2i falldetection dataset;自制数据集是由网络上爬取出的人体跌倒图片经过标注所得。公开数据集含有5436张图片,自制数据含有2500张图片,按照8:2的比例将分别将两个数据集划分为训练集和验证集。数据集中一共包含两个类别,分别是没有发生跌倒行为的 (nofall)和发生了跌倒行为的(fall)。
[0165]
评价指标
[0166]
本文采用召回率(recall)、精准率(precision、平均精度均值map(meanaverage precision)作为实验评价指标。有关概念如下:tp(true posi-tives)是指被预测正确的正样本,即检测为跌倒实际也是跌倒;tn(true negatives)为正确预测的负样本,即检测为非跌倒实际也是非跌倒;fp(false positives)指的是被错误预测的正样本,即检测为非跌倒实际却是跌倒;fn(false negatives)指的是被错误预测的负样本,即检测为跌倒实际却是非跌倒。
[0167]
精确度(precision):表示分类器预测是跌倒并且确实是跌倒的部分占分类器预测是跌倒的比例。其公式如(13)所示。
[0168][0169]
召回率(recall):表示分类器预测为跌倒并且确实是跌倒的部分占所有确实是跌倒的比例,其公式如(14)所示。
[0170][0171]
平均精度ap(average precision):指的是以召回率recall为横轴,以精确度 precision为纵轴组成的曲线,曲线围成的面积就是ap。公式如(15)所示。
[0172][0173]
平均精度均值map(mean average precision):数据集中所有类别的平均精度的均值。其公式如(16)所示。
[0174][0175]
其中m表示测试集中的样本个数。
[0176]
实验结果与分析
[0177]
yolov5_ccb与yolov5实验对比
[0178]
如图14及图15所示,将yolov5模型和改进yolov5模型(yolov5_ccb)分别在公开数据集(le2i fall detection dataset)和自制数据集下进行训练,实验结果如表4-1所示。
在公开数据集下两个模型训练过程中边界框loss对比图、yolov5_ccb检测效果图如图14、图15所示。由表可知,无论是在公开数据集下训练还是在自制数据集下训练,yolov5改进后得到的yolov5_ccb模型虽然在推理时间上慢了3ms,但是在 precision及map上都高于原yolov5模型。图14中,处于高位的图线对应yolov5的边界框loss,处于低位的图线对应yolov5_ccb的边界框loss。由图14可以看出 yolov5-ccb模型相比于原yolov5模型来说收敛较快、损失值更小,说明将原损失函数修改之后提高了网络的收敛能力。由图15可以看出,当室内环境较为复杂或者跌倒后的人体出现部分被其他物体遮挡时准确率也能达到90%。
[0179]
表4-1 yolov5x模型与yolov5_ccb模型实验对比
[0180][0181]
yolov5_ccb与其他模型实验对比
[0182]
为了更好的体现yolov5_ccb模型的优势,本文将yolov5_ccb与其他优秀的目标检测模型进行对比实验。具体的,yolov5-ccb与两阶段的mask_rcnn和一阶段的ssd、原 yolov5、yolov4进行对比,使用公开数据集进行训练、验证。如表4-2所示为各个模型在map、recall、precision和推理时间方面的对比结果。由表可知,yolov5_ccb模型大小比原yolov5x仅仅多了7m,虽然在推理时间上慢了3ms,但在精准度上提高了11.7%,在map上提高了4%;相比于二阶段的mask_rcnn在精准度上提高了6.7%,在map上提高了25.5%,在推理时间上快了150ms;与yolov4和sdd相比,yolov5_ccb在推理时间上要更快,在召回率、平均精度以及map上也都要更高。
[0183]
表4-2yolov5_ccb与其他模型实验对比结果
[0184][0185]
消融实验
[0186]
消融对比实验旨在验证不同改进模块对原yolov5的改进效果。使用公开数据集进行训练,实验结果如表4-3所示。其中优化模型1表示损失函数的修改,优化模型2表示修改原网络的特征金字塔结构,优化模型3表示在主干网络加入注意力机制,优化模型4表示即修改了损失函数同时也修改了特征金字塔结构,优化模型5标志修改了损失函数和加入了注意力机制,优化模型6标志加入了注意力机制和修改了特征金字塔结构。由表可知,与改进前的yolov5相比,注意力机制的加入使平均精度提高了0.3%,但是推理时间慢了1ms;修改金字塔结构后平均精度提高了1.8%,推理时间同样也慢了1ms;损失函数修改后,平均精度提高了0.9%,推理时间快了3ms;同时修改损失函数和特征金字塔结构后平均精度提高了1.8%,推理时间快了1ms;同时修改损失函数和加入注意力机制后平均精度提高了1.2%,推理时间慢了1ms;同时修改特征金字塔和加入注意力机制后平均精度提高了1.6%,推理时间没有变化;同时改进以上三处,平均精度提高了 4.0%,这相比于其他现有的跌倒行为检测方法有较大的提升。
[0187]
表4-3消融实验对比结果
[0188]
[0189][0190]
针对现有的yolov5模型存在的问题,以及复杂背景下检测跌倒时会出现漏检、误检及检测精度低的问题,提出了一种改进的yolov5模型来解决上述问题。该模型采用 ciou损失函数代替原有的giou,在主干网络c3模块中加入cbam注意机制,并修改特征金字塔结构为bifpn,得到yolov5_ccb改进算法,有效地解决了跌倒行为检测中遇到的问题。实验结果表明,改进后的跌倒检测模型能够从复杂环境的图像中准确提取跌倒特征并且也能达到很好的预测效果。改进后的模型在没有大幅增加模型尺寸的情况下,提高了检测精度和召回率。yolov5_ccb与原yolov5相比,改进后的网络在很多指标中都有所提升,与其他类型的目标检测算法相比也有很大的优势。改进后,yolov5_ccb 的检测准确率比原yolov5提高了约11.7%,map比原yolov5提高了约4%。总的来说,改进后的网络有效地提高了准确度,可以有效地解决当前跌倒行为检测中存在的许多问题。
[0191]
综上,本发明将yolov5的边界框损失函数giou更换为ciou,然后在yolov5的主干网络中的残差组件后加入卷积块注意力机制(convolutional block attention module,cbam)模块,该机制将位置信息嵌入到通道注意力当中,使网络可以更专注地学习跌倒这一特征;最后将特征融合层的特征金字塔网络结构替换成加权双向特征金字塔(bifpn)网络结构,充分利用不同尺度的特征,从而提高检测精度。
[0192]
本发明通过以上操作,ciou在设计预测边界框时把重叠面积、中心点的间距,以及长宽比都纳入考虑。本发明以ciou损失函数代替原yolov5模型中的giou,作为yolov5 新的边界框损失函数,实现更加准确地检测跌倒行为。
[0193]
本发明中的cbamc3模块在进行特征提取时会增加一项注意力机制的计算,其作用
是对特征图中的不同目标进行不同维度上的注意力加权计算,提高算法对特征图中主要特征的提取,以此来提高目标检测算法的准确性。本发明通过添加注意力机制,即使是跌倒后有部分遮挡且周围有其他物体干扰的情况下也有很好的检测效果,解决了室内环境较为复杂的情况下出现漏检、误检的问题。本发明解决了现有技术中存在的平均精度低、侵入性强、适用场景受有限制以及检测速度慢的技术问题。
[0194]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。