1.本发明涉及银行流计算数据处理领域,尤其是指一种基于多维中间态聚合的银行流计算业务实时指标系统。
背景技术:
2.随着大数据时代的到来,很多的金融场景中会出现多维数据,如银行流水数据,股票交易数据,信用卡账户数据等。这些数据通常包含多个特征,特征计算系统在处理这些不同的特征时往往会使用不同的计算方法,如求和、取平均、最大最小值等。然而随着业务复杂程度的提升,特征计算系统所需要处理的数据量急速增加,很多的金融场景需要对业务对象建立多维度的特征体系以及对不同的特征需要采用不同的处理方式,这些都对系统的性能提出了新的挑战。
3.银行流计算业务作为金融领域中重要的部分,其对系统的实时性有着较高的要求,目前大多数的实时指标系统都采用的是主流的经典流计算架构,在复杂的业务场景下,该架构暴露出两个问题:一是由于流式计算框架并不针对底层数据存储的管理和优化,每一次业务事件的处理都需要从底层数据库中取出相关数据并输入到计算框架中去,这便会造成系统io负载;二是由多维数据导致的不同的特征处理方式会造成额外的数据处理的开销以及计算资源的浪费,这也使得特征计算系统的运维成本大幅提高。以上两个问题使得经典流计算架构并不能满足银行流计算业务指标系统对于实时性的要求。
技术实现要素:
4.本发明的目的在于针对现有技术的不足,提出一种基于多维中间态聚合的银行流计算业务实时指标系统,通过对全量数据进行特征处理生成中间态记录并聚合,再与中间态数据库中的原始记录进行比对和更新的方式实现银行流计算指标业务。该系统可以提高多维数据的计算效率,节省计算资源,减少系统的io负载,以达到银行流计算业务在实时性方面的要求。
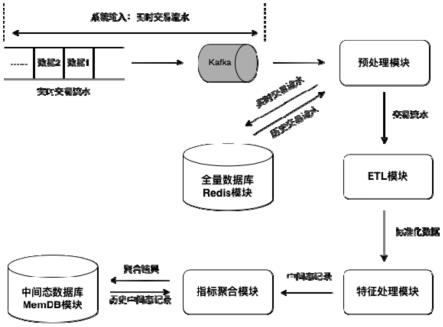
5.本发明的目的是通过以下技术方案来实现的:一种基于多维中间态聚合的银行流计算业务实时指标系统,该系统包括预处理模块、全量数据库redis模块、etl模块、特征处理模块、指标聚合模块和中间态数据库memdb模块;
6.所述预处理模块用于接收来自kafka消息队列的实时交易流水数据,根据业务需求从全量数据库redis模块中取出指定时间区间的全量历史数据以及将新的实时交易流水数据进行保存,并将由全量数据库redis模块中取出的历史数据以及kafka消息队列的实时交易流水数据一并发送至etl模块;
7.所述全量数据库redis模块用于银行流计算业务相关的完整的未经处理的多维数据;
8.所述etl模块用于对预处理模块发送的kafka消息队列的实时交易流水数据以及全量数据库redis模块的历史数据进行清洗和标准化,将数据按照维度对齐并统一格式,将
全量数据库redis模块中的历史数据以及来自kafka的实时交易流水数据转化为标准数据发送至特征处理模块;
9.所述特征处理模块对经过清洗和标准化的多维数据根据业务需求进行特征筛选,并根据指标聚合模块的聚合方式对筛选后的多维特征进行分组,形成指定格式的多维中间态记录;具体为:特征处理模块包含多种列表,每个列表对应一种指标聚合模块的聚合方式,每个列表中包含多维特征;每个列表根据业务需求决定特征数量以及特征组合格式;
10.所述指标聚合模块由多个聚合节点组成,每个聚合节点执行一种聚合方式,将特征处理模块得到的多维中间态记录按照对应的聚合方式分配到不同的聚合节点中进行聚合运算,将结果发送至中间态数据库memdb模块;
11.所述中间态数据库memdb模块用于存储聚合运算后的指标计算结果,为银行流计算业务提供指标判断依据。
12.进一步地,所述特征处理模块中的特征组合格式指的是对于每个特定业务场景下的某类特定数据,将其多个特征按照指定顺序进行排列,列表内直接存储每个特征的具体数值。
13.进一步地,所述指标聚合模块中每个聚合计算节点中的所需处理的多维中间态记录的聚合方式相同,采用先将可聚合数据组合再统一聚合的方式进行并行运算,避免单一中间态记录聚合时的串行运算,提升聚合效率。
14.进一步地,所述指标聚合模块的多维特征的聚合方法,包括取最大值、最小值、求和以及求平均值。
15.进一步地,所述特征处理模块获取用于数据聚合所需的额外辅助数据,包括待聚合时序数据的时间戳以及求取平均值时需要记录的数据总量。
16.本发明的优点及有益效果是:
17.(1)减少存储多维中间态记录所需空间:通过对业务需求进行分析,定义指定的特征组合格式,可以省去存储每个特征字段名的空间。
18.(2)减少系统io负载:系统会根据业务需求制定数据库读写方案,只需要从全量数据库中读取少量未经聚合处理过的数据,同时采用聚合中间态记录的方式,无需频繁的对全量数据库进行读写操作,从而减少了系统io负载。
19.(3)提升系统计算资源使用效率:通过采用按照聚合方式对特征进行分组的方法可将中间态记录分发到各个指定聚合方式的计算节点中去,分散了系统计算负载;多维中间态记录可以使系统同时对多个特征进行运算,另外采用先组合再统一聚合的计算方式将串行运算变为并行计算,可以使用如gpu等计算资源对计算过程进行加速,从而大大提升了计算资源的使用效率。
20.(4)通过减少系统io负载以及提升系统运算效率的方式,可以很好的满足银行流计算业务实时指标系统对于性能方面的要求。
附图说明
21.图1为本发明之较佳实施例的结构框图。
22.图2为多维中间态记录结构图。
具体实施方式
23.下面结合附图对本发明作进一步描述。
24.如图1所示,本发明提供了一种基于多维中间态聚合的银行流计算业务实时指标系统,包括预处理模块、全量数据库redis模块、etl(extract-transform-load)模块、特征处理模块、指标聚合模块、中间态数据库memdb模块。
25.本发明中以银行流计算业务中的信用卡相关业务进行说明,该业务场景通常为统计当月所有客户的单笔消费最大值、单笔还款最大值、累计消费总值和信用卡使用次数等,因此按照聚合方式可对业务需求作出以下分类:
26.1.求最大值:单笔消费金额,单次累积信用积分,单次还款金额等;
27.2.求和:消费总额,还款总额,消费频次,信用总积分等;
28.3.求平均:平均日支出,平均月支出,平均年支出等。
29.面对以上业务需求,可以为每种聚合方式定义指定的特征组合格式,如“最大值”业务的特征组合为(消费金额-还款金额-信用积分),因此在传递这一业务需求的中间态记录时不需要描述特征的字段,而是直接按照上述格式传递每一特征具体的值即可。
30.预处理模块会根据来自kafka消息队列的实时交易流水、全量数据库redis模块的历史交易数据以及中间态数据库memdb模块所存数据制定与全量数据库redis模块的交互方案,如已知中间态数据库memdb模块已存储某日之前的所有中间态数据,则只需要将该日之后的全量数据从全量数据库redis模块导出并参与聚合(该日之前的全量数据均已完成聚合并保存在中间态数据库memdb模块中因此不需要导出)。
31.所述全量数据库redis模块用于银行流计算业务相关的完整的未经处理的多维数据;,包括开户信息、交易记录、交易额度、还款记录、额度变更记录和信用卡有效期
32.etl模块会对实时交易流水以及历史交易数据进行清洗和标准化。将数据按照维度对齐并统一格式,将全量数据库redis模块中的历史数据以及来自kafka的实时交易流水数据转化为标准数据发送至特征处理模块;
33.特征处理模块在得到标准化后的全量数据后根据特征组合的格式定义生成中间态记录。多维中间态记录的具体结构如图2所示,包括主键p_key、聚合方式键w_key、特征组合键f_key和辅助数据键d_key,具体如下:
34.(1)主键p_key,关联特定的业务对象,如图2主键所示,可以是一信用卡账户id,该键值具有全局唯一性。主键与辅助数据一起用于决定多条中间态记录之间的可聚合性,当主键与辅助数据一致时表明两组数据可以进行聚合,因此可以通过对主键与辅助数据的哈希映射来加速可聚合数据间的组合过程。
35.(2)聚合方式键w_key,用于描述中间态记录所包含的特征的聚合方法,如取最大值,累加,求平均等。图2所示聚合方式为取最大值即用max表示。
36.(3)特征组合键f_key,由多个特征组成的列表构成,特征处理模块根据业务需求决定特征组合格式以省去字段名,同一中间态记录中的多个特征具有相同的聚合方式;对于根据业务需求所定义的特征组合格式是对于某个特定业务场景下的某类特定数据,将其多个特征按照指定顺序进行排列,这样做可以省去存储字段名所需空间,列表内直接存储每个特征的具体数值。图2根据取最大值的业务场景对信用卡数据进行特征组合的一种方式为:“消费金额-还款金额-信用积分”,则特征组合键的列表长度为3,每个值分别对应该
特征组合顺序的每个字段。
37.(4)辅助数据键d_key,由两个字段组成,分别是应对时序数据的时间戳,以及用于数据聚合所需的额外辅助数据,如求取平均值时需要记录数据总量。若不需辅助数据则用null进行填充,如图2所示的取最大值计算过程不需要用到辅助数据则该字段的值为null。
38.指标聚合模块中每个聚合计算节点所需处理的多维中间态记录聚合方式均相同,并且采用了先将可聚合数据组合再统一聚合的方式,可以避免单一中间态记录聚合时的串行运算,而是采用使用底层计算资源如gpu等对海量数据进行并行运算,统一聚合,从而提升聚合效率。指标聚合模块在得到多维中间态记录后会先按照聚合方式进行分组,将具有相同聚合方式的中间态记录分配至同一计算节点,聚合计算节点的运算过程如下:聚合计算节点每次取出n条多维中间态记录,先遍历n条记录,根据多维中间态记录的主键以及辅助数据键先将系统数据哈希映射到指定队列,映射的过程并不进行聚合计算而是直接合并多维中间态记录,在遍历完n条数据之后再对已经合并好的每个队列进行统一的聚合运算,具体算法如下所示(以python语法表示):
[0039][0040][0041]
第01行的参数data是包含所有中间态记录的列表。第02行定义的是保存最终聚合结果的字典型变量。第03行为遍历n条多维中间态记录。第04行是先将每条记录的主键和辅助数据键进行组合,并使用该组合键进行哈希映射。第05行是判断字典中是否有上述组合键,如果没有则在第06行为该组合键新建一个列表,如果字典中有该组合键或者为组合键新建完列表之后,在第07行将中间态记录的特征组合键直接添加到对应的列表中,这一过程只涉及可以聚合的数据的组合并不涉及聚合运算。第08行遍历字典,第09行将每个组合键下的列表进行统一的聚合计算。第10行返回最终的聚合结果。
[0042]
指标聚合模块完成聚合运算后得到最终的聚合结果,并将计算结果与中间态数据库memdb模块中的对应中间态记录进行两两聚合并更新数据库。这一过程只需要进行1次中间态数据库memdb模块的读取和写入操作,很大程度地减少了系统的io负载。同时由于指标聚合模块采用了先合并所有可聚合记录再统一进行聚合计算的方法,而每个合并好的队列中的所有数据都是采用相同的聚合方式,因此可以使用gpu等底层计算资源进行并行计算,对计算过程进行加速,很大程度的提升了计算资源的使用效率和减少了计算所需时间。
[0043]
本发明系统的工作流程如下:
[0044]
(1)预处理模块接收来自kafka消息队列的实时交易流水并与全量数据库redis模
块进行交互。交互完成后将实时交易流水以及历史交易数据一并发送至etl模块。
[0045]
(2)etl模块对数据进行清洗和标准化并发送至特征处理模块。
[0046]
(3)特征处理模块根据业务需求筛选特征并按照指定格式组合,每种组合格式对应一种聚合方式,之后生成多维中间态记录并发送至指标聚合模块。
[0047]
(4)指标聚合模块根据聚合方式将中间态记录分配到不同的聚合节点中,聚合计算节点每次取出n条多维中间态记录,先遍历n条记录,根据多维中间态记录的主键以及辅助数据键先将中间态记录哈希映射到指定队列,映射到同一队列的数据即为可聚合数据,映射的过程并不进行聚合计算而是直接合并多维中间态记录,在遍历完n条数据之后再对已经合并好的每个队列进行聚合运算。
[0048]
(5)将指标聚合模块计算得到的最终中间态记录与中间态数据库memdb中的对应中间态记录进行两两聚合并保存。
[0049]
本发明的重点在于:通过使用多维中间态记录,系统无需从全量数据库redis模块中读取所有数据,也无需对中间态数据库进行频繁的读写操作,更无需对每一特征进行单独运算,减少系统io负载效果显著。特征格式的定义减少了保存中间态记录所需空间,另外聚合计算的过程中按照聚合方式分配计算节点以及使用gpu并行计算的方法既分散了系统的计算负载,又很大程度的提升了计算资源的使用效率,从而更好的满足银行流计算业务实时指标系统对于实时性的要求。
[0050]
上述实施案例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
