1.本技术涉及自然语言处理技术领域,尤其涉及一种自然语言处理模型的训练方法和装置。
背景技术:
2.在自然语言处理(natural language processing,nlp)领域,“提示”(prompt)是将人为的规则给到预训练语言模型,使模型可以更好地理解人的指令的一项技术,可以简单理解为给任务的输入加入补充文本,以便更好地利用预训练语言模型。
3.与一般的微调(fine-tuning)相比,提示调整(prompt tuning)将prompt加入到微调过程中,并且可以做到只对prompt部分的参数进行训练,同时保证整个预训练模型的参数固定不变,这种灵活性是一般的fine-tuning无法做到的。
4.因此,如何进一步提升使用提示调整方法训练预训练语言模型的效果值得研究。
技术实现要素:
5.本技术提供了一种自然语言处理模型的训练方法和装置,能够进一步提升使用提示调整方法训练预训练语言模型的效果。
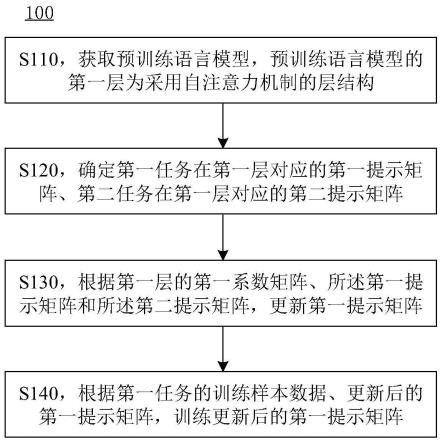
6.第一方面,提供了一种自然语言处理模型的训练方法,包括:
7.获取预训练语言模型,预训练语言模型的第一层为采用自注意力机制的层结构;
8.确定第一任务在第一层对应的第一提示矩阵、第二任务在第一层对应的第二提示矩阵,第一提示矩阵和第二提示矩阵为用作连续提示的可学习向量矩阵,第一任务和第二任务属于自然语言处理任务;
9.根据第二提示矩阵确定第一层的第一系数矩阵;
10.根据第一系数矩阵、第一提示矩阵和第二提示矩阵,更新第一提示矩阵;
11.根据第一任务的训练样本数据、更新后的第一提示矩阵,训练更新后的第一提示矩阵,其中,
12.第一任务在第一层对应的自注意力机制运算的输入包括第一拼接向量矩阵,第一拼接向量矩阵由第一层的第一向量矩阵和更新后的第一提示矩阵拼接得到,第一向量矩阵为与第一任务对应的键向量矩阵或值向量矩阵。
13.本技术实施例在训练模型前,将多个nlp任务对应的提示矩阵融合来更新单个任务的提示矩阵,将多个nlp任务联合学习,进行了隐式的数据增强,提升了模型的表示能力,由于nlp任务之间具有递进关系或者相似关系,能够通过多个任务的提示矩阵联合学习来提升提示调整方法的效果。进一步地,由于本技术实施例中的提示调整方法基于了transformers模型,transformers基础参数是共享的,不同任务间的提示矩阵相当于在同一个基础参数上进行对模型的扰动,因此这些扰动有一定共性,不同任务的提示矩阵之间可以进行显式的信息的相互传递,一个nlp任务可以参考其他nlp任务训练的提示矩阵对本身的值进行改动,这样加速了提示矩阵的收敛速度,从而加快了训练速度。
14.在一个示例中,该方法还包括:
15.根据第一提示矩阵确定第一层的第二系数矩阵;
16.根据第二系数矩阵、第一提示矩阵和第二提示矩阵,更新第二提示矩阵;
17.根据第二任务的训练样本数据、更新后的第二提示矩阵,训练更新后的第二提示矩阵,其中,
18.第二任务在第一层对应的自注意力机制运算的输入包括第二拼接向量矩阵,第二拼接向量矩阵由第一层的第二向量矩阵和更新后的第二提示矩阵拼接得到,第二向量矩阵为与第二任务对应的键向量矩阵或值向量矩阵。
19.在一个示例中,根据第二提示矩阵确定第一层的第一系数矩阵,包括:
20.初始化与第二提示矩阵对应的第一权重矩阵,第一权重矩阵是基于第一任务的训练样本数据和第二任务的训练样本数据的可学习的矩阵;
21.确定第一激活函数以及与第二提示矩阵对应的第一偏置矩阵;
22.将第一权重矩阵、第二提示矩阵、第一偏置矩阵作第一激活函数的输入,将第一激活函数的输出确定为第一层的第一系数矩阵。
23.在一个示例中,预训练语言模型的第二层为采用自注意力机制的层结构,方法还包括:
24.确定第二任务在第二层对应的第三提示矩阵,第三提示矩阵为用作连续提示的可学习向量矩阵。
25.在一个示例中,根据第一系数矩阵、第一提示矩阵和第二提示矩阵,更新第一提示矩阵,包括:
26.根据第一提示矩阵和第三提示矩阵确定第二层的第三系数矩阵;
27.根据第一系数矩阵、第三系数矩阵、第一提示矩阵、第二提示矩阵和第三提示矩阵,更新第一提示矩阵;
28.其中,根据第二提示矩阵确定第一层的第一系数矩阵,包括:
29.根据第一提示矩阵和第二提示矩阵确定第一系数矩阵。
30.在一个示例中,根据第一提示矩阵和第二提示矩阵确定第一系数矩阵,包括:
31.确定第二提示矩阵与第一提示矩阵之间的第一欧式距离;
32.基于陆地移动距离算法根据第一欧式距离确定第一转移量,第一转移量用于表征第二提示矩阵传递到第一提示矩阵的信息的占比;
33.根据第一转移量确定第一系数矩阵。
34.在一个示例中,根据第一提示矩阵和第三提示矩阵确定第二层的第三系数矩阵,包括:
35.确定第三提示矩阵与第一提示矩阵之间的第二欧式距离;
36.基于陆地移动距离算法根据第二欧式距离确定第二转移量,第二转移量用于表征第三提示矩阵传递到第一提示矩阵的信息的占比;
37.根据第二转移量确定第三系数矩阵。
38.在一个示例中,根据第一系数矩阵、第三系数矩阵、第一提示矩阵、第二提示矩阵和第三提示矩阵,更新第一提示矩阵,包括:
39.根据第一层的第一任务确定第一比重;
40.根据预训练语言模型的层数和除第一任务以外的剩余任务数量确定第二比重;
41.根据第一比重、第二比重、第一系数矩阵、第三系数矩阵、第一提示矩阵、第二提示矩阵和第三提示矩阵,更新第一提示矩阵。
42.第二方面,提供了一种自然语言处理模型的训练装置,包括:
43.模型获取模块,用于获取预训练语言模型,预训练语言模型的第一层为采用自注意力机制的层结构;
44.提示矩阵确定模块,用于确定第一任务在第一层对应的第一提示矩阵、第二任务在第一层对应的第二提示矩阵,第一提示矩阵和第二提示矩阵为用作连续提示的可学习向量矩阵,第一任务和第二任务属于自然语言处理任务;
45.系数矩阵确定模块,用于根据第二提示矩阵确定第一层的第一系数矩阵;
46.提示矩阵更新模块,用于根据第一系数矩阵、第一提示矩阵和第二提示矩阵,更新第一提示矩阵,第一系数矩阵与第二提示矩阵相关;
47.模型训练模块,用于根据第一任务的训练样本数据、更新后的第一提示矩阵,训练更新后的第一提示矩阵,其中,
48.第一任务在第一层对应的自注意力机制运算的输入包括第一拼接向量矩阵,第一拼接向量矩阵由第一层的第一向量矩阵和更新后的第一提示矩阵拼接得到,第一向量矩阵为与第一任务对应的键向量矩阵或值向量矩阵。
49.在一个示例中,装置还包括:
50.系数矩阵确定模块还用于根据第一提示矩阵确定第二系数矩阵;
51.提示矩阵模块还用于根据第二系数矩阵、第一提示矩阵和第二提示矩阵,更新第二提示矩阵;
52.模型训练模块还用于根据第二任务的训练样本数据、更新后的第二提示矩阵,训练更新后的第二提示矩阵,其中,
53.第二任务在第一层对应的自注意力机制运算的输入包括第二拼接向量矩阵,第二拼接向量矩阵由第一层的第二向量矩阵和更新后的第二提示矩阵拼接得到,第二向量矩阵为与第二任务对应的键向量矩阵或值向量矩阵。
54.本技术实施例的装置在训练模型前,将多个nlp任务对应的提示矩阵融合来更新单个任务的提示矩阵,将多个nlp任务联合学习,进行了隐式的数据增强,提升了模型的表示能力,由于nlp任务之间具有递进关系或者相似关系,能够通过多个任务的提示矩阵联合学习来提升提示调整方法的效果。进一步地,由于本技术实施例中的提示调整方法基于了transformers模型,transformers基础参数是共享的,不同任务间的提示矩阵相当于在同一个基础参数上进行对模型的扰动,因此这些扰动有一定共性,不同任务的提示矩阵之间可以进行显式的信息的相互传递,一个nlp任务可以参考其他nlp任务训练的提示矩阵对本身的值进行改动,这样加速了提示矩阵的收敛速度,从而加快了训练速度。
附图说明
55.为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
56.图1是本技术实施例提供的一例自然语言处理模型的训练方法的示意性流程图;
57.图2是本技术实施例提供的再一例自然语言处理模型的训练方法的示意性流程图;
58.图3是本技术实施例提供的一例预训练语言模型架构示意图;
59.图4是本技术实施例提供的一例提示矩阵组合示意图;
60.图5是本技术实施例提供的一例系数矩阵g的获取方法示意图;
61.图6是本技术实施例提供的一例自然语言处理模型的训练装置示意图。
具体实施方式
62.下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能解释为对本技术的限制。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
63.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本技术的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
64.为了便于理解本技术中的方案,以下对一些技术概念进行简单介绍:
65.提示(prompt)学习:将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,可以简单理解为给任务的输入加入补充文本,以便更好地利用预训练模型。在提示学习中,补充文本可以提示模板的形式来作为模型的输入,提示模板的制作分为手工创建模板和自动化生成模板,而自动化生成模板又分为离散提示(又叫做硬提示(hard prompt))和连续提示(又叫做软提示(soft prompt))。
66.硬提示(hard prompt):hard prompt中,prompt是一个实际的文本字符串。例如,输入的文本x=“i love this movie”。首先,设计一个prompt模板(prompt template):overall it was a[z]movie,在实际研究中,[z]是需要模型进行填充的空位,[z]的位置和数量决定了prompt的类型。例如,根据[z]位置的不同,可以将prompt分为cloze prompt([z]在句中)和prefix prompt([z]在句末)。具体选择哪一种则取决于任务形式和模型类别。
[0067]
软提示(soft prompt):在soft prompt中,prompt直接在底层语言模型的嵌入空间中进行描述。例如,在“提示调整”方法中,通过在嵌入式输入中插入可训练变量来学习连续的提示。
[0068]
提示调整(prompt tuning):将prompt加入到微调过程中,并且可以做到只对prompt部分的参数进行训练,同时保证整个预训练模型的参数固定不变。
[0069]
nlp任务:深度学习模型能够利用nlp任务来学习语言知识,nlp任务包括nlp基础任务和nlp上层任务(即nlp下游任务),其中,深度学习模型能够利用nlp基础任务来学习基
础语言知识,nlp基础任务例如有词性分析(pos)任务、语块分析(chunk)任务和依存句法分析(dep)任务等;nlp上层任务是深度学习模型在具体应用时学习的任务,例如有文本语义相关(relatedness)任务、文本蕴涵(entailment)任务和命名实体识别(ner)任务等。
[0070]
陆地移动距离(earth mover's distance,emd),是由ijcv期刊文章《the earth mover'sdistance as a metric for image retrieval》提出的一种图像相似度度量方法,最初emd的概念是用于图像检索的,后来因为其各种优点,逐渐用到其他方面的相似度度量。
[0071]
transformer层:transformer是2017年的一篇论文《attention is all you need》提出的一种模型架构,提出了堆叠transformer-block的transformers网络。其中,每一个transformer-block的结构相同,均包含自注意力(attention)机制,这个attention操作的目的就是计算当前表达(token)与每个位置(position)之间的“相关度”,从而决定每个position的向量(vector)在最终该时间步(timestep)的上下文(context)中占的比重有多少。transformer层中所使用的attention公式为其中,q为查询(query)向量矩阵(后面简称为q向量矩阵),k为键(key)向量矩阵(后面简称为k向量矩阵),v为值(value)向量矩阵(后面简称为v向量矩阵)。
[0072]
transformers的双向编码表示(bidirectional encoder representation from transformers,bert)语言模型:bert利用掩码语言模型(masked language model,mlm)进行预训练并且采用深层的双向transformers组件来构建整个模型。近几年来,有关预训练语言模型(pre-train language model,plm)的研究比比皆是,自然语言处理也借着这股春风获得了长足发展。尤其是在2017-2019年间,研究者们的重心逐渐从传统任务特征(task-specific)的有监督模式转移到预训练上。基于预训练语言模型的研究思路通常是“预训练,微调”,即将plm应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对plm本体进行调整。
[0073]
随着plm体量的不断增大,对其进行微调的硬件要求、数据需求和实际代价也在不断上涨。除此之外,丰富多样的下游任务也使得预训练和微调阶段的设计变得繁琐复杂,因此研究者们希望探索出更小巧轻量、更普适高效的方法,prompt tuning就是一个沿着此方向的尝试。prompt tuning仅调整极少的参数即可让模型适配下游任务。
[0074]
目前,使用提示调整方法训练plm的效果有待进一步提升。
[0075]
需要说明的是,目前针对transformers层还没有本领域通用的中文解释,因此本技术采用transformers来指代这种层结构或者模型。
[0076]
为了进一步提升模型的效果和模型的小样本学习能力,本技术实施例提供了一种自然语言处理模型的训练方法,如图1中的方法100所示,其中,图1是本技术实施例提供的一例自然语言处理模型的训练方法的示意性流程图,方法100包括:
[0077]
s110,获取预训练语言模型。
[0078]
其中,预训练语言模型的第一层为采用自注意力机制的层结构。
[0079]
示例性地,该预训练语言模型包括transformers层,该预训练语言模型为t5,robertaa,deberta等。
[0080]
应理解,该预训练语言模型可以包括其他层,其他层可以是采用自注意力机制的
层结构,也可以是其他类型的层结构。
[0081]
s120,确定第一任务在第一层对应的第一提示矩阵和第二任务在第一层对应的第二提示矩阵。
[0082]
其中,第一提示矩阵和第二提示矩阵为用作连续提示的可学习向量矩阵,第一任务和第二任务属于自然语言处理任务。
[0083]
其中,第一任务在第一层对应的第一提示矩阵可以理解为,为每个任务在每一层设置一个提示矩阵,该提示矩阵由其对应的任务的样本数据来训练和更新,以具备该任务的特征。
[0084]
示例性地,自然语言处理任务包括词性标注(part-of-speech tagging)任务、语块分析(chunking)任务、依存分析(dependency parsing)任务、命名实体识别(ner)任务、关系抽取任务等。
[0085]
示例性地,初始的第一提示矩阵和第二提示矩阵是随机初始化后的矩阵。
[0086]
s130,根据第一层的第一系数矩阵、所述第一提示矩阵和所述第二提示矩阵,更新第一提示矩阵。
[0087]
其中,第一系数矩阵是根据第二提示矩阵确定的。
[0088]
示例性地,将第一系数矩阵与第二提示矩阵的乘积与第一提示矩阵相加,得到更新后的第一提示矩阵。
[0089]
更新第一提示矩阵的方式包括,首先随机初始化第一权重矩阵和第一偏置矩阵,其中,第一权重矩阵和第一偏置矩阵是基于第一任务的训练样本数据和第二任务的训练样本数据的可学习的矩阵,第一权重矩阵和第一偏置矩阵用于将第二提示矩阵作线性映射。接着向预训练语言模型输入第一任务的训练样本数据和第二任务的训练样本数据,经模型训练后更新第一层的第一权重矩阵。然后确定第一激活函数,可选地,该第一激活函数为sigmoid函数。最后将第一权重矩阵与第二提示矩阵的乘积再加上第一偏置矩阵,作为第一激活函数的输入,第一激活函数的输出为该第一系数矩阵。
[0090]
在一个示例中,该模型还用于训练第三任务,该方法包括,确定第三任务在第一层对应的第四提示矩阵,第四提示矩阵为用作连续提示的可学习向量矩阵,第三任务属于自然语言处理任务。其中,更新第一提示矩阵的方式还包括:
[0091]
根据该层的第一系数矩阵、第二提示矩阵、第四系数矩阵、第四提示矩阵和第一提示矩阵,更新第一提示矩阵,其中,第四系数矩阵是根据第四提示矩阵确定的。第四系数矩阵的确认方式参见第一系数矩阵的确认方式,在此不再赘述。
[0092]
进一步可选地,将第一系数矩阵与第二提示矩阵的乘积加到第一提示矩阵上,并且,继续将第四系数矩阵与第四提示矩阵的乘积加到第一提示矩阵上,得到更新后第一提示矩阵。
[0093]
进一步地,该模型用于训练多个任务,该多个任务至少包括上述的第一任务和第二任务,还可以包括第三任务,当然还可以包括其他任务,下面以包括第一任务、第二任务和第三任务为例结合上述实施例进行效果说明:
[0094]
第一任务为基础语言任务例如词性分析任务,第二任务为基础语言任务例如语块分析任务,第三任务为下游任务例如命名实体识别任务。根据上述实施例可以总结出,首先确定第一任务对应的初始的第一提示矩阵、第二任务对应的初始的第二提示矩阵和第三任
务对应的初始的第四提示矩阵,该初始的第一提示矩阵、第二提示矩阵和第四提示矩阵可以是随机初始化得到的。然后根据上述实施例的提示矩阵更新方式,将初始的第一提示矩阵根据第二提示矩阵和第四提示矩阵更新,以此类推,初始的第一提示矩阵可根据当前层的其他所有任务对应的提示矩阵进行更新,然后再根据训练样本数据训练更新后的第一提示矩阵;将初始的第二提示矩阵根据第一提示矩阵和第四提示矩阵更新,以此类推,初始的第二提示矩阵可根据当前层其他所有任务对应的提示矩阵进行更新,然后再根据训练样本数据训练更新后的第二提示矩阵;将初始的第四提示矩阵根据第一提示矩阵和第二提示矩阵更新,以此类推,初始的第四提示矩阵可根据当前层其他所有任务对应的提示矩阵进行更新,然后再根据训练样本数据训练更新后的第四提示矩阵。可以看出,预训练语言模型训练多个任务时,在确定每个任务的初始的提示矩阵后,根据同一层的其他所有任务经过处理后的提示矩阵参照上述方式更新(由于每个任务各自对应的提示矩阵的比重为1来参与到自身的更新中,因此也可以说,每个任务的初始的提示矩阵是根据同一层的所有任务经过处理后的提示矩阵来更新的)。该多个任务包括nlp基础任务和下游任务,根据上述更新各个任务初始的提示矩阵的方式能够融合多个任务的信息,在学习训练样本数据的特征时能够提升单个任务的学习效果,有利于提升提示调整方法的效果。
[0095]
进一步地,第二提示矩阵的更新方式与第一提示矩阵类似,具体如下,根据第一层的第二系数矩阵、第一提示矩阵和第二提示矩阵,更新第二提示矩阵,第二系数矩阵是根据第一提示矩阵确定的。在一个示例中,首先随机初始化第二权重矩阵和第二偏置矩阵,其中,第二权重矩阵和第二偏置矩阵为可学习的矩阵。接着向预训练语言模型输入第一任务的训练样本数据和第二任务的训练样本数据,经模型训练后更新第一层的第二权重矩阵。然后确定第一激活函数,可选地,该第一激活函数为sigmoid函数。最后将第二权重矩阵与第一提示矩阵的乘积再加上第二偏置矩阵,作为第一激活函数的输入,第一激活函数的输出为该第二系数矩阵。
[0096]
在一个示例中,预训练语言模型的第二层为采用自注意力机制的层结构,方法还包括:
[0097]
确定第二任务在第二层对应的第三提示矩阵,第三提示矩阵为用作连续提示的可学习向量矩阵。
[0098]
需要注意的是,本技术示例中的第一层中的“第一”,或第二层中的“第二”,仅用于区分两个不同的层结构,可理解为某一层,不用于特指该模型中的第几层。
[0099]
更新第一提示矩阵的方式还包括:
[0100]
根据第一层的第一系数矩阵、第二层的第三系数矩阵、第一提示矩阵、所述第二提示矩阵和第三提示矩阵,更新第一提示矩阵,其中,第三系数矩阵是根据第一提示矩阵和第三提示矩阵确定的,第一系数矩阵是根据第一提示矩阵和第二提示矩阵确定的。
[0101]
其中,确定第一系数矩阵和第三系数矩阵的方式包括:
[0102]
确定第二提示矩阵与第一提示矩阵之间的第一欧式距离,以及第三提示矩阵与第一提示矩阵之间的第二欧式距离;
[0103]
基于陆地移动距离算法根据第一欧式距离得到第一转移量,第一转移量用于表征第二提示矩阵传递到第一提示矩阵的信息的占比,根据第一转移量确定第一系数矩阵;
[0104]
基于陆地移动距离算法根据第二欧式距离得到第二转移量,第二转移量用于表征
第三提示矩阵传递到第一提示矩阵的信息的占比,根据第二转移量确定第三系数矩阵。
[0105]
应理解,在第一转移量和第二转移量各自是一个数值的情况下,第一系数矩阵和第三系数矩阵各自可以是一个数值。
[0106]
示例性地,更新第一提示矩阵的方式还包括:
[0107]
根据第一层的第一任务确定第一比重;
[0108]
根据预训练语言模型的层数和除第一任务以外的剩余任务数量确定第二比重;
[0109]
根据第一比重、第二比重、第一系数矩阵、第三系数矩阵、第一提示矩阵、第二提示矩阵和第三提示矩阵,更新第一提示矩阵。
[0110]
例如,更新后的第一提示矩阵=初始的第一提示矩阵
×
第一比重 第二比重
×
第二提示矩阵
×
第一系数矩阵 第二比重
×
第三提示矩阵
×
第三系数矩阵。
[0111]
可选地,第一比重的值为1。
[0112]
由上述实施例可以看出,该多个任务至少包括上述的第一任务和第二任务,当然还可以包括其他任务,下面以包括第一任务和第二任务为例结合上述实施例进行效果说明:
[0113]
第一任务为基础语言任务例如语块分析任务,第二任务为下游任务例如命名实体识别任务。根据上述实施例可以总结出,首先确定第一任务对应的初始的第一提示矩阵和第二任务对应的初始的第二提示矩阵,该初始的第一提示矩阵和第二提示矩阵可以是随机初始化得到的。然后根据上述实施例的提示矩阵更新方式,将初始的第一层的第一提示矩阵根据第二任务在第一层对应的第二提示矩阵和第二任务在第二层对应的第三提示矩阵更新,以此类推,初始的第一提示矩阵可根据其他所有任务在所有层对应的提示矩阵参照上述方式进行更新,然后再根据训练样本数据训练更新后的第一提示矩阵。因此,每个任务在每一层对应的初始的提示矩阵可根据其他所有任务在所有层对应的提示矩阵更新,每个任务在每一层对应的提示矩阵能够融合多个任务的信息,在学习训练样本数据的特征时能够提升单个任务的学习效果,有利于提升提示调整方法的效果。
[0114]
s140,根据第一任务的训练样本数据、更新后的第一提示矩阵,训练更新后的第一提示矩阵。
[0115]
其中,第一任务在第一层对应的自注意力机制运算的输入包括第一拼接向量矩阵,第一拼接向量矩阵由第一层的第一向量矩阵和更新后的第一提示矩阵拼接得到,第一向量矩阵为与第一任务对应的键向量矩阵或值向量矩阵。
[0116]
具体地,向预训练语言模型输入第一任务的训练样本数据和更新后的第一提示矩阵,训练更新后的第一提示矩阵,将最后输出层的输出输入损失函数中,计算损失,然后利用上述方式更新训练好的第一提示矩阵后,再和第一任务的训练样本数据作为预训练语言模型的输入,不断迭代一定次数后,直至损失函数的导数为0,从而确定最终的第一提示矩阵。
[0117]
在一个示例中,根据第二任务的训练样本数据、更新后的第二提示矩阵,训练更新后的第二提示矩阵,其中,
[0118]
第二任务在第一层对应的自注意力机制运算的输入包括第二拼接向量矩阵,第二拼接向量矩阵由第一层的第二向量矩阵和更新后的第二提示矩阵拼接得到,第二向量矩阵为与第二任务对应的键向量矩阵或值向量矩阵。
[0119]
本技术实施例在训练模型前,将多个nlp任务对应的提示矩阵融合来更新单个任务的提示矩阵,将多个nlp任务联合学习,进行了隐式的数据增强,提升了模型的表示能力,由于nlp任务之间具有递进关系或者相似关系,能够通过多个任务的提示矩阵联合学习来提升提示调整方法的效果。进一步地,由于本技术实施例中的提示调整方法基于了transformers模型,transformers基础参数是共享的,不同任务间的提示矩阵相当于在同一个基础参数上进行对模型的扰动,因此这些扰动有一定共性,不同任务的提示矩阵之间可以进行显式的信息的相互传递,一个nlp任务可以参考其他nlp任务训练的提示矩阵对本身的值进行改动,这样加速了提示矩阵的收敛速度,从而加快了训练速度。
[0120]
在方法100的基础上,本技术结合具体预训练模型和训练步骤,通过以下实施例对方法100进行详细举例说明。图2是本技术实施例提供的再一例自然语言处理模型的训练方法的示意性流程图。如图2中的方法200所示,以基于transformers架构的bert模型为例,该方法200可以包括:
[0121]
s210,确定多个任务分别对应的训练样本数据。
[0122]
例如,文本分类任务的训练样本数据为:“今天天气真不错”。在使用bert模型中,上述文本会变成["[cls]","今","天","天","气","真","不","错","[sep]"]。其中,[cls]和[sep]是bert中表示文本开始和结束的符号。
[0123]
s220,确定多个任务对应的提示矩阵。
[0124]
具体地,对应原有模型计算自注意力时的k向量矩阵的提示矩阵为pk,pk用于与k向量矩阵拼接,得到新的k向量矩阵,对应原有模型计算自注意力时的v向量矩阵的提示矩阵为pv,pv用于与v向量矩阵拼接,得到新的v向量矩阵。新的k向量矩阵和新的v向量矩阵参与到自注意力机制的运算中,从而使得pk和pv得到了训练。
[0125]
图3是本技术实施例提供的一例预训练语言模型架构示意图,下面结合图3对pk和pv进行介绍。如图3所示,以一个任务为例,在bert模型中的每一层设置pk和pv,pk可看做由h0,h1,
…
,hi组成的向量矩阵,i可根据任务调节,其中,h0到hi是与训练任务相关的参数向量矩阵,在训练时只更新这部分参数,每个向量矩阵的形状为1*768;pv可看做由h0’
,h1’
,
…
,h
i’组成的向量矩阵,h0’
到h
i’参见h0到hi的说明,在此不再赘述。假设输入x=“amazing!”,经过嵌入层处理后用向量表示输入x,向量为e([cls])、e(amazing)和e(!)(e为模型的嵌入函数),将该词向量输入到bert模型中,通过标注数据对pk和pv进行训练,由于bert模型的参数被冻结,即不参与训练,所以只对pk和pv进行训练。
[0126]
结合图3,下面举例说明“拼接”的含义:
[0127]
假设输入到bert模型中的文本为“你是一个好学生”,一个transformers层的k向量矩阵对应[cls]你是一个好学生[sep],k向量和pk拼接后的形式如h0,h1,
…
,hi[cls]你是一个好学生[sep]。
[0128]
pk与k向量矩阵的拼接可以表示为:
[0129]
k’=contact(pk,k)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(1)
[0130]
其中,k’表示拼接后的k向量矩阵。
[0131]
在图3的基础上,以训练一个任务为例,介绍本技术中的transformers模型,包括(1)embedding层(嵌入层);(2)transformers-block(transformers-块结构),一般为多个;(3)输出层。
[0132]
其中,embedding层用于将文本映射为矩阵。将输入文本定义为x,x有z个词,那么embedding层的输入为长度z的文本对应的索引(该索引是每个词在模型词表中的索引,该模型词表是根据谷歌开源的bert模型训练得到的词表,该模型词表用于将文本进行编码从而得到索引),输出e为[z,d]大小的矩阵,其中d为embedding层将每个词对应的索引转换成的矩阵的长度。其中,z=512,d=768。
[0133]
多个transformers-block堆叠构成transformers层,transformers block会对词向量进行切分,切分数被称为“头”(head),比如原有的每个词向量300维,共有5个head,那么每一个head就按顺序取300维中被切分成5份的第h个份(每一份都有60维),并将切分后的h份分别放入不同的transformers block中。本技术后续实施例以head数目为1进行说明,模型中的层数为l,例如,l=6。每一层的向量矩阵q、k、v通过自注意力机制的运算影响每一层的输出。
[0134]
输出层则根据不同的任务输出相应任务对应的内容,例如,文本分类输出为文本的类别概率,命名实体识别任务输出每一个词分类的概率,关系抽取任务需要抽取文本的主体、客体、事件的概率等。
[0135]
需要说明的是,本技术对预训练语言模型不作限定,只要是以transformer层为基础的模型就可以,例如还可以是t5,robertaa,deberta等。
[0136]
在上述transformers模型的基础上,假设第m层的任务1的提示矩阵分别为p
1,m,k
(用于与k向量矩阵拼接)和p
1,m,v
(用于与v向量矩阵拼接),首先随机初始化各个任务的提示矩阵,然后,在此轮的训练过程中,根据这一层其他任务的提示矩阵确定新的当前层任务1的提示矩阵,假设有t个任务,重新确定的p
1,m,k
如以下公式所示:
[0137][0138]
其中,
[0139][0140]
图4是本技术实施例提供的一例提示矩阵组合示意图,图4中的一个圆圈表示一个hi,下面结合图4来介绍公式(2),其中,p
′
1,m,k
是基于其他任务的提示矩阵更新后的任务1在第m层的提示矩阵,p
1,m,k
到p
t,m,k
是任务1到任务t在第m层的提示矩阵,为用于加权求和的权重(是一个系数矩阵),其下标(1,2)表示该权重的编号,该编号是有方向的(即任务2将一定比重的信息传递到任务1),以此类推到可以看出p
′
1,m,k
由包括自身在内的多个任务的提示矩阵之间交互而成,即不同任务的提示矩阵按照一定权重加到原来的p
1,m,k
上,从而更新了第m层的任务1的提示矩阵。
[0141]
图5是本技术实施例提供的一例系数矩阵g的获取方法示意图,下面结合图5介绍公式(3),其中,i和j表示不同的任务,和分别为第m层的线性映射对应的权重矩阵和偏置矩阵,σ为sigmoid激活函数。以为例,经转置后和p
2,m,k
作矩阵乘法,然后加上参数最后经过sigmoid函数激活。应理解,激活函数还可以是其他类型的函数,本技术对此不作限定。
[0142]
参数矩阵w
ij
和经过随机初始化后,后续的矩阵中的值利用任务i和任务j的训练样本数据来训练,直至更新后的p
′
1,m,k
符合预设条件,例如该预设条件为该任务所对应的
损失函数的倒数为0。
[0143]
可选地,我们在多层中共享线性映射的参数矩阵w
ij
和b
ij
,即,即向量矩阵的长度和p
1,m,k
的长度相同,矩阵中的每一个值在0~1之间(图5中的的一个圆圈表示一个0~1之间的值),表示该提示矩阵中每个hi(hi表示起到提示作用的字(token))被使用的比例。
[0144]
重新确定的p
1,m,v
如以下公式所示:
[0145][0146]
其中,
[0147][0148]
可以看出,p
1,m,k
和p
1,m,v
共享由于多个任务之间的联系不会因为是k向量矩阵对应的提示矩阵还是v向量矩阵对应的提示矩阵而改变,故可以共享这样也可以减少模型训练的参数。
[0149]
以此类推,第m层的多个任务的提示矩阵的更新如以下公式所示:
[0150][0151][0152]
最后按照上述方式确定其他层的提示矩阵。
[0153]
s230,将提示矩阵输入模型中并对该模型进行训练。
[0154]
具体地,将多任务的文本输入模型后,每一层的输出都有k向量矩阵和v向量矩阵,将原始k向量矩阵和原始v向量矩阵分别与对应的更新后的提示矩阵拼接后,得到新的k向量矩阵和v向量矩阵。然后将新的k向量矩阵和v向量矩阵作为该层的自注意力机制运算的输入,经过自注意力机制运算后得到该层的输出,并将该层的输出作为下一层的输入,直至该模型最后的输出层输出各个任务对应的内容。最后计算损失,根据损失更新所有的提示矩阵。
[0155]
其中,第m层多个任务对应的拼接后的k向量矩阵如以下公式所示:
[0156][0157]
其中,k
t,m
表示第m层任务t对应的原始的k向量矩阵,k
′
t,m
表示第m层任务t对应的拼接后的新的k向量矩阵。
[0158]
其中,第m层多个任务对应的拼接后的v向量矩阵如以下公式所示:
[0159][0160]
其中,v
t,m
表示当前层任务t对应的原始的v向量矩阵,v
′
t,m
表示当前层任务t对应的拼接后的新的v向量矩阵。
[0161]
应理解,可以重复s220和s230,不断更新提示矩阵,以得到较优的提示矩阵。
[0162]
应注意,该方法中的多个任务可以是学习目标相似的任务,例如多个情感分类任务,还可以是有递进关系的任务(如命名实体识别任务、依存句法分析任务、关系抽取任务等包括nlp基础任务和nlp下游任务的多个任务)。
[0163]
模型对多个nlp任务进行学习能够提升模型对单一任务的学习效果,在提示调整方法中,由于冻结了原模型的基础参数,只训练提示矩阵的参数,因此通过调整较少的参数就可以学习到任务相关的特异性参数。由此出发,在方法200中,同一层的每个任务的提示矩阵都由其他任务的提示矩阵的加权求和而成,进行了隐式的数据增强,提升了模型的表示能力,由于nlp任务之间具有递进关系或者相似关系,能够通过多个任务的提示矩阵联合学习来提升提示调整方法的效果。进一步地,由于本技术实施例的提示调整方法基于了transformers模型,transformers基础参数是共享的,不同任务间的提示矩阵相当于在同一个基础参数上进行对模型的扰动,因此这些扰动有一定共性,不同任务的提示矩阵之间可以进行显式的信息的相互传递,一个任务可以参考其他任务训练的提示矩阵对本身的值进行改动,这样加速了提示矩阵的收敛速度,从而加快了训练速度。
[0164]
需要说明的是,方法200中以同时训练多个任务为例进行了说明,每个提示矩阵都会和其对应的任务绑定,绑定的方法例如都会赋予同一个任务的标签等等,本技术对此不作限定。还可以每次只训练一个任务,当训练完多个任务后再更新该多个任务的提示矩阵。
[0165]
方法200中考虑了相同层的多个任务之间的信息传递,本技术还提供了一例不同层的多个任务之间信息传递的方式,下面参考方法200来介绍方法300。
[0166]
s310,确定多个任务的训练样本数据。
[0167]
具体内容参见s210,在此不再赘述。
[0168]
s320,确定多个任务的提示矩阵。
[0169]
以任务1在第1层的用于与k向量矩阵拼接的提示矩阵p
1,1,k
为例,通过以下步骤来更新提示矩阵:
[0170]
s321,计算第一层的任务1与多个层的其他任务的欧式距离。
[0171]d1,1,k
=‖p
1,1,k-[p
2,1,k
,
…
,p
2,l,k
,p
3,1,k
,
…
,p
3,l,k
,
…
,p
t,1,k
,
…
,p
t,l,k
]‖
ꢀꢀꢀꢀꢀꢀ
公式(10)
[0172]
其中‖x-y‖表示计算x与y之间的欧式距离,d
1,1,k
是一个(t-1)*l长度的数组,该数组也可以看做是长度为(t-1)*l的一维矩阵。
[0173]
s322,根据欧式距离计算多个层的其他任务到第一层的任务1的转移量集合。
[0174]
具体地,利用emd算法根据d
1,1,k
计算多个层(假设有l层)的其他任务到第一层的任务1的转移量集合f
1,1,k
(即系数矩阵),转移量集合f
1,1,k
的每一个元素为某一层的其他任务中的一个任务到任务1的转移量(每个转移量是一个数值,转移量也可以理解为某一层的其他任务中的一个任务能够传递到任务1的信息占多少比重),例如将第一层任务2转移到第
一层任务1的转移量记为那么f
1,1,k
如以下公式所示:
[0175][0176]
其中,f
1,1,k
中的所有元素的和为1,是长度为(t-1)*l的一维矩阵。
[0177]
s323,根据转移量集合更新第一层的任务1的提示矩阵。
[0178]
更新后的第一层的任务1的与k向量矩阵对应的提示矩阵记为p
′
1,1,k
,p
′
1,1,k
如以下公式所示:
[0179]
p
′
1,1,k
=p
1,1,k
f
1,1,k
*p
other,k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(12)
[0180]
p
other,k
=[p
2,1,k
,
…
,p
2,l,k
,p
3,1,k
,
…
,p
3,l,k
,
…
,p
t,1,k
,
…
,p
t,l,k
]
ꢀꢀꢀꢀꢀꢀ
公式(13)
[0181]
可选地,为了缩小其他提示矩阵对被更新的提示矩阵的影响,p
′
1,1,k
还可以如以下公式所示:
[0182]
p
′
1,1,k
=p
1,1,k
α
1,1,kf1,1,k
*p
other,k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(14)
[0183]
其中,权重α
1,1,k
为在0~1之间的值(包括0和1)。
[0184]
可选地,α
1,1,k
的值为
[0185]
应理解,公式(12)还可以变形为如以下公式所示:
[0186]
p
′
1,1,k
=α
1,1,k
*f
′
1,1,k
*p
all,k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(15)
[0187][0188]
p
all,k
=[p
1,1,k
,
…
,p
1,l,k
,p
2,1,k
,
…
,p
2,l,k
,p
3,1,k
,
…
,p
3,l,k
,
…
,p
t,1,k
,
…
,p
t,l,k
]公式(17)
[0189]
其中,f
′
1,1,k
中为0的部分表示其他层的任务1给第一层的任务1的转移量是0,1/α
1,1,k
的部分表示第一层的任务1给自己的转移量是1(即α
1,1,k
*1/α
1,1,k
=1),p
all,k
为所有的与k向量矩阵对应的是矩阵。
[0190]
根据上述内容,可类推到与v向量矩阵对应的提示矩阵的更新方式,更新后的第一层的任务1的与v向量矩阵对应的提示矩阵记为p
′
1,1,v
,p
′
1,1,v
如以下公式所示:
[0191]
p
′
1,1,v
=p
1,1,v
f
1,1,v
*p
other,v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(18)
[0192]
p
other,v
=[p
2,1,v
,
…
,p
2,l,v
,p
3,1,v
,
…
,p
3,l,v
,
…
,p
t,1,v
,
…
,p
t,l,v
]
ꢀꢀꢀꢀꢀꢀ
公式(19)
[0193]
可选地,为了缩小其他提示矩阵对被更新的提示矩阵的影响,p
′
1,1,v
还可以如以下公式所示:
[0194]
p
′
1,1,v
=p
1,1,v
α
1,1,vf1,1,v
*p
other,v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(20)
[0195]
其中,α
1,1,v
为在0~1之间的值(包括0和1)。
[0196]
应理解,公式(12)还可以变形为如以下公式所示:
[0197]
p
′
1,1,v
=α
1,1,v
*f
′
1,1,v
*p
all,v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(21)
[0198][0199]
p
all,v
=[p
1,1,v
,
…
,p
1,l,v
,p
2,1,v
,
…
,p
2,l,v
,p
3,1,v
,
…
,p
3,l,v
,
…
,p
t,1,v
,
…
,p
t,l,v
]
ꢀꢀꢀꢀꢀ
公式(23)
[0200]
其中,f
′
1,1,v
中为0的部分表示其他层的任务1给第一层的任务1的转移量是0,1/α
1,1,v
的部分表示第一层的任务1给自己的转移量是1(即α
1,1,v
*1/α
1,1,v
=1),p
all,v
为所有的与v向量矩阵对应的是矩阵。
[0201]
以此类推,第m层第t个任务的提示矩阵的更新如以下公式所示:
[0202]
p
′
t,m,k
=α
t,m,k
*f
′
t,m,k
*p
all,k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(24)
[0203][0204]
p
′
t,m,v
=α
t,m,v
*f
′
t,m,v
*p
all,v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(26)
[0205][0206]
s330,将提示矩阵输入模型中并对该模型进行训练。
[0207]
具体内容参见s230,在此不再赘述。
[0208]
需要说明的是,本技术对上述计算转移量的算法不作限定,能够获得各个层的其他任务到被更新任务的转移量即可。
[0209]
在方法300中,由于转移量可看作是权重,因此一个任务的提示矩阵由不同层的多个任务的提示矩阵的加权求和而成,进行了隐式的数据增强,提升了模型的表示能力,由于nlp任务之间具有递进关系或者相似关系,能够通过不同层之间的多个任务的提示矩阵联合学习来有效提升提示调整方法的效果。进一步地,由于本技术实施例的提示调整方法基于了transformers模型,transformers基础参数是共享的,不同任务间的提示矩阵相当于在同一个基础参数上进行对模型的扰动,因此这些扰动有一定共性,不同层的多个任务的提示矩阵之间可以进行显式的信息的相互传递,一个任务可以参考其他任务训练的提示矩阵对本身的值进行改动,这样加速了提示矩阵的收敛速度,从而加快了训练速度。
[0210]
图6是本技术实施例提供的一例自然语言处理模型的训练装置示意图,在上述自然语言处理模型的训练方法的基础上,本技术还提供了一种自然语言处理模型的训练装置,下面结合图6对该装置进行说明,如图6所示,该装置包括:
[0211]
模型获取模块410,用于获取预训练语言模型,预训练语言模型的第一层为采用自注意力机制的层结构;
[0212]
提示矩阵确定模块420,用于确定第一任务在第一层对应的第一提示矩阵、第二任务在第一层对应的第二提示矩阵,第一提示矩阵和第二提示矩阵为用作连续提示的可学习向量矩阵,第一任务和第二任务属于自然语言处理任务;
[0213]
系数矩阵确定模块430,用于根据第二提示矩阵确定第一层的第一系数矩阵;
[0214]
提示矩阵更新模块440,用于根据第一层的第一系数矩阵和第一提示矩阵,更新第一提示矩阵,第一系数矩阵与第二提示矩阵相关;
[0215]
模型训练模块450,用于根据第一任务的训练样本数据、更新后的第一提示矩阵,训练更新后的第一提示矩阵,其中,
[0216]
第一任务在第一层对应的自注意力机制运算的输入包括第一拼接向量矩阵,第一拼接向量矩阵由第一层的第一向量矩阵和更新后的第一提示矩阵拼接得到,第一向量矩阵为与第一任务对应的键向量矩阵或值向量矩阵。
[0217]
该装置的其他实现方式参见方法100至方法300中的说明,在此不再赘述。
[0218]
应该理解的是,虽然附图的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,附图的流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他
步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0219]
以上所述仅是本技术的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本技术的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
