基于路网索引的top-k空间关键字查询方法
技术领域
1.本发明涉及路网索引和top-k查询的技术领域,尤其是指一种基于路网索引的top-k空间关键字查询方法。
背景技术:
2.top-k空间关键字查询问题作为空间数据库的一大研究热点,其目的是查询出离用户位置距离较近并且满足用户查询偏好的若干个对象,而其查询意图则是由关键词作为表达。top-k空间关键字查询问题不仅考虑了对象与关键字的匹配程度,还考虑了用户与查询对象之间的空间距离,根据空间距离的衡量方式上的区别,可以分为欧式空间和路网空间两种不同的距离。欧式空间表示的是两点距离用直线距离来度量,而路网空间两点距离是用道路网上的最短路程来度量。
3.不过,支持路网上高效的top-k查询是非常困难的。其主要的瓶颈在于,计算点到点最短路的代价特别高,不像计算两点欧式直线距离那么简单。此外,即使能很快得到道路最短道路距离,如果没有高效的剪枝算法和策略,要计算出top-k结果也是非常消耗时间的。虽然现在有大量的工作研究路网上的top-k查询处理问题。然而,现有的方法都没办法支持大规模的道路网络。这些方法的主要问题大多是索引会导致过高的存储代价,或着太高的预处理时间代价。
技术实现要素:
4.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于路网索引的top-k空间关键字查询方法,以划分子图的方式构建路网索引,缓解了索引存储代价太高的问题,将节点的空间文本得分为上界剪枝对象,能够提高查找top-k空间关键字对象的速度。
5.为实现上述目的,本发明所提供的技术方案为:基于路网索引的top-k空间关键字查询方法,包括以下步骤:
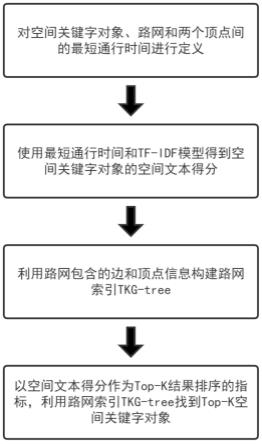
6.1)对路网的相关概念进行定义,其中包括空间关键字对象o、路网图g和两个顶点间的最短通行时间函数τ
*
(t);
7.2)使用步骤1)得到的最短通行时间函数τ
*
(t)衡量空间关键字对象o的空间邻近性,得到空间得分函数,记为fs(o);使用tf-idf模型衡量空间关键字对象o的文本相似性,得到文本得分函数,记为fd(o);使用文本得分函数fd(o)和空间得分函数fs(o)加权计算得到空间文本得分函数,记为
8.3)根据步骤1)定义的路网,使用其包含的边和顶点信息对路网索引tkg-tree进行构造;tkg-tree是一颗由图切割而来的平衡树结构,其根节点对应整个路网图g,并有着以下性质:根节点的每个后代节点ni都对应一个子图gi,把最下面一层节点称为叶子节点;tkg-tree有两个超参数f和μ,分别代表非叶子节点的分支数和叶子节点的顶点数量上限;每个节点ni均包含了一个通行时间矩阵mi和一个记录了对象关键字信息o.key的倒排文档di;
9.4)以步骤2)得到的空间文本得分函数作为top-k结果排序的指标,从查询点vq出发,利用步骤3)构建的路网索引tkg-tree找到排名top-k的空间关键字对象o。
10.进一步,在步骤1)中,对以下概念进行了定义:
11.a、在路网的边中,用通行时间来表示边的长度,而边的通行时间会随着时刻t的不同而改变,因此记边的通行时间函数为ω(t);在路网顶点中,其中的部分顶点携带了以关键字形式存在的文本信息,将拥有空间位置信息和文本关键字信息的顶点称为空间关键字对象o,表示为:
12.o=(vo,o.key)
13.式中,vo表示对象所在的顶点位置,o.key表示对象关键字信息;
14.b、将路网建模为一个无向图,表示为:
[0015][0016]
式中,g为路网图,代表一个由若干条边交叉组成的无向图路网结构;v1表示第1个顶点,vn表示第n个顶点,v={v1,v2,...vn}代表路网中的所有顶点的集合;e1表示第1条边,en表示第n条边,e={e1,e2,...en}表示路网中边的集合;而ω1(t)表示第1条边的通行时间函数,ωn(t)表示第n条边的通行时间函数,w={ω1(t),ω2(t),...ωn(t)}则表示与对应边相关联的通行时间函数集合;
[0017]
c、在路网中,起点到终点的一条路径ρ由一系列相邻的连通顶点序列表示《vi,...vj》,其中vi表示第i个顶点,vj表示第j个顶点,而p则用来表示从起点到终点的所有路径集合;记路径ρ的通行时间函数为τ(t),那么将从起点到终点的最短通行时间函数τ
*
(t)定义如下:
[0018]
τ
*
(t)=min{τ(t)|ρ∈p}
[0019]
式中,τ(t)表示在时刻t出发,路径ρ的通行时间函数;τ
*
(t)则表示在时刻t出发,从起点到终点的所有路径中最短的通行时间函数。
[0020]
进一步,所述步骤2)包括以下步骤:
[0021]
2.1)定义了基于路网空间的top-k空间关键字的查询参数query:
[0022]
query=《vq,q.key,t,k》
[0023]
式中,vq表示查询点,q.key表示查询的关键字词组,t代表查找的时刻,k表示返回的空间关键字对象o的数量;
[0024]
2.2)使用最短通行时间函数τ
*
(t)来衡量空间关键字对象o与查询点vq的空间邻近性,定义空间得分函数fs(o)如下:
[0025][0026]
式中,表示空间关键字对象o所在顶点vo到查询点vq之间的最短通行时间;
[0027]
2.3)使用tf-idf模型来衡量空间关键字对象o与查询的关键字词组q.key的文本相似性,定义文本得分函数fd(o)如下:
[0028][0029]
式中,key和q.key分别表示关键字和查询的关键字词组,tf(key)表示关键字key在空间关键字对象o中出现的次数,idf(key)表示关键字key在所有空间关键字对象o中出现的频率倒数;关键字key的重要性随着它在空间关键字对象o中出现的次数成正比增加,但同时会随着它在所有空间关键字对象o中出现的频率成反比下降;
[0030]
2.4)使用文本得分函数fd(o)和空间得分函数fs(o)得到空间文本得分函数其计算公式如下:
[0031][0032]
式中,α表示权重因子,表示空间文本得分函数,它由空间得分函数fs(o)和文本得分函数fd(o)加权计算得到。
[0033]
进一步,在步骤3)中,路网索引tkg-tree是通过图切割的方法来构造的,首先将整个路网图g当做根节点,然后把g切割成f个大小相同的子图,并把它们作为根节点的孩子节点,接着继续递归地切割这些子图,直到最后子图包含的顶点数量不超过μ个;根据路网的拓扑关系,运行floyd算法得到节点ni的通行时间矩阵mi,矩阵mi记录了该节点ni对应子图gi内各个顶点之间的最短通行时间函数τ
*
(t);对该节点ni对应子图gi内所有空间关键字对象o的关键字信息o.key取并集,得到节点ni的倒排文档di。
[0034]
进一步,在步骤4)中,输入查询参数后,以空间文本得分函数作为top-k结果排序的指标进行查找;先定义一个最大优先队列q和结果集r,从查询点vq所在子图开始搜索,将子图内所有的空间关键字对象o加入优先队列q并按照空间文本得分函数排序;使用n
x
记录tkg-tree上当前访问到的最高层节点,标记当前的搜索范围为该节点对应的子图g
x
,同时,定义节点的空间文本得分作为上界进行剪枝:
[0035][0036]
式中,fs(node)表示查询点vq到当前子图g
x
的最短通行时间,使用路网索引tkg-tree的通行时间矩阵mi计算得到;表示空间关键字对象o能达到的最大文本得分,使用路网索引tkg-tree的倒排文档di计算得到;将队列q中的空间关键字对象o依次出队,筛选出空间文本得分比上界高的空间关键字对象o,加入结果集r;若队列q为空且结果集r未满k个,则将n
x
更新为原来节点的父节点,并扩大当前的搜索范围为n
x
节点更新后对应的子图,同时将改为n
x
节点更新后的空间文本得分,重复上述操作,直到结果集r有k个结果,算法自动结束;最大优先队列q和上界保证了从查询点vq到第k个结果是全局最优的,因此,能正确的找到top-k空间关键字对象o。
[0037]
本发明与现有技术相比,具有如下优点与有益效果:
[0038]
1、本发明考虑了时间因素对top-k路网距离的影响,更加具有实际应用价值。
[0039]
2、本发明与其它路网空间的top-k查询方法相比,预处理时间更短,存储代价更小。
[0040]
3、本发明在不同规模的数据集上均有着毫秒级的查询响应时间,具有良好的通用性和可拓展性。
附图说明
[0041]
图1为本发明方法的逻辑流程示意图。
[0042]
图2为本发明所使用的路网索引tkg-tree示意图。
具体实施方式
[0043]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0044]
参见图1所示,本实施例提供了一种基于路网索引的top-k空间关键字查询方法,其具体情况如下:
[0045]
1)对空间关键字对象、路网图和最短通行时间进行了定义:
[0046]
a、在路网的边中,用通行时间来表示边的长度,而边的通行时间会随着时刻t的不同而改变,因此记边的通行时间函数为ω(t);在路网顶点中,其中的部分顶点携带了以关键字形式存在的文本信息,将拥有空间位置信息和文本关键字信息的顶点称为空间关键字对象o,表示为:
[0047]
o=(vo,o.key)
[0048]
式中,vo表示对象所在的顶点位置,o.key表示对象的关键字信息;
[0049]
b、将路网建模为一个无向图,表示为:
[0050][0051]
式中,g为路网图,代表一个由若干条边交叉组成的无向图路网结构;v1表示第1个顶点,vn表示第n个顶点,v={v1,v2,...vn}代表路网中的所有顶点的集合;e1表示第1条边,en表示第n条边,e={e1,e2,...en}表示路网中边的集合;而ω1(t)表示第1条边的通行时间函数,ωn(t)表示第n条边的通行时间函数,w={ω1(t),ω2(t),...ωn(t)}则表示与对应边相关联的通行时间函数集合;
[0052]
c、在路网中,起点到终点的一条路径ρ可由一系列相邻的连通顶点序列表示《vi,...vj》,其中vi表示第i个顶点,vj表示第j个顶点,而p则可用来表示从起点到终点的所有路径集合。记路径ρ的通行时间函数为τ(t),那么将从起点到终点的最短通行时间函数τ
*
(t)定义如下:
[0053]
τ
*
(t)=min{τ(t)|ρ∈p}
[0054]
式中,τ(t)表示在时刻t出发,路径ρ的通行时间函数;τ
*
(t)则表示在时刻t出发,从起点到终点的所有路径中最短的通行时间函数。
[0055]
2)使用步骤1)得到的最短通行时间函数τ
*
(t)衡量空间关键字对象o的空间邻近性;使用tf-idf模型衡量空间关键字对象o的文本相似性;使用文本得分函数和空间得分函数加权计算得到空间文本得分函数,其中包括以下步骤:
[0056]
2.1)定义了基于路网空间的top-k空间关键字的查询参数query:
[0057]
query=《vq,q.key,t,k》
[0058]
式中,vq表示查询点,q.key表示查询的关键字词组,t代表查找的时刻,k表示返回的空间关键字对象o的数量;
[0059]
2.2)使用最短通行时间函数τ
*
(t)来衡量空间关键字对象o与查询点vq的空间邻近性,定义空间得分函数fs(o)如下:
[0060][0061]
式中,表示空间关键字对象o所在顶点vo到查询点vq之间的最短通行时间。
[0062]
2.3)使用tf-idf模型来衡量空间关键字对象o与查询的关键字词组q.key的文本相似性,定义文本得分函数fd(o)如下:
[0063][0064]
式中,key和q.key分别表示关键字和查询的关键字词组,tf(key)表示关键字key在空间关键字对象o中出现的次数,idf(key)表示关键字key在所有空间关键字对象o中出现的频率倒数;关键字key的重要性随着它在空间关键字对象o中出现的次数成正比增加,但同时会随着它在所有空间关键字对象o中出现的频率成反比下降。
[0065]
2.4)使用文本得分函数fd(o)和空间得分函数fs(o)得到空间文本得分函数其计算公式如下:
[0066][0067]
式中,α表示权重因子,表示空间文本得分函数,它由空间得分函数fs(o)和文本得分函数fd(o)加权计算得到。
[0068]
3)使用步骤1)定义路网所包含的边和顶点信息对路网索引tkg-tree进行构造;路网索引tkg-tree是通过图切割的方法来构造的,如图2所示,我们把非叶子节点的分支数f设置为2,把叶子节点的最大顶点数量μ设为4;首先将整个路网图g当做根节点,然后把g切割成f个大小相同的子图,并把它们作为根节点的孩子节点,接着继续递归地切割这些子图,直到最后子图包含的顶点数量不超过μ个;根据路网的拓扑关系,运行floyd算法得到节点ni的通行时间矩阵mi,矩阵mi记录了该节点ni对应子图gi内各个顶点之间的最短通行时间函数τ
*
(t);对该节点ni对应子图gi内所有空间关键字对象o的关键字信息o.key取并集,得到节点ni的倒排文档di。
[0069]
4)以步骤2)得到的空间文本得分函数作为top-k结果排序的指标,从查询点vq出发,利用步骤3)构建的路网索引tkg-tree找到排名top-k的空间关键字对象;先定义一个最大优先队列q和结果集r,从查询点vq所在子图开始搜索,将子图内所有的空间关键字对象o加入优先队列q并按照空间文本得分函数排序;使用n
x
记录tkg-tree上当前访问到的最高层节点,标记当前的搜索范围为该节点对应的子图g
x
,同时,定义节点的空间文本得分作为上界进行剪枝:
[0070]
[0071]
式中,fs(node)表示查询点vq到当前子图g
x
的最短通行时间,使用路网索引tkg-tree的通行时间矩阵mi计算得到;表示空间关键字对象o能达到的最大文本得分,使用路网索引tkg-tree的倒排文档di计算得到;将队列q中的空间关键字对象o依次出队,筛选出空间文本得分比上界高的空间关键字对象o,加入结果集r;若队列q为空且结果集r未满k个,则将n
x
更新为原来节点的父节点,并扩大当前的搜索范围为n
x
节点更新后对应的子图,同时将改为n
x
节点更新后的空间文本得分,重复上述操作,直到正确地找到top-k空间关键字对象o。
[0072]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。