1.本发明涉及一种基于亮度补偿残差网络的水下图像增强方法,属于水下图像增强技术领域。
背景技术:
2.近年来高质量的水下图像对于勘测海洋资源、保护海洋生物、防卫海洋安全等方面有着重要的意义。但是由于水下成像的复杂性,导致拍摄所得的图像存在严重的质量问题,不利于信息的获取与深入研究。因此,需要对水下图像进行增强与修复,以进一步提取更多有用信息。
3.水下图像呈现模糊、低对比度、颜色失真等问题是由于光在水下传播的特殊性。由于不同波长的光在水下传播时的衰减不同,导致水下图像出现颜色失真的问题。其次,水中悬浮粒子对光的散射作用,导致水下图像出现模糊、对比度低的问题。
4.水下图像处理技术,主要分为基于非物理模型的图像增强方法,基于物理模型的图像恢复方法和基于深度学习的图像增强方法。非物理模型方法主要是直接通过调整图像的像素值来改善效果,但是由于不考虑水下成像的光学特性,容易产生色差和伪影。基于物理模型的图像恢复方法是建立水下图像退化的数学模型,根据模型估计参数,然后反推得到清晰的水下图像,但是模型通常是基于一种先验性假设,具有一定的局限性。基于深度学习的水下图像增强方法分为卷积神经网络和对抗生成网络,通过构建相应的网络模型,通过大量成对数据的训练,可将低质量的水下图像转换为高质量的图像,但是仍存在部分细节丢失、过饱和等问题。
技术实现要素:
5.本发明所要解决的技术问题是针对现有技术的现状,提供一种基于亮度补偿残差网络的水下图像增强方法,能够解决水下图像颜色失真、模糊、低对比度等问题,同时通过亮度补偿进一步提高图像的细节信息。
6.为解决上述技术问题,本发明所采用的技术方案是:
7.包括如下步骤:
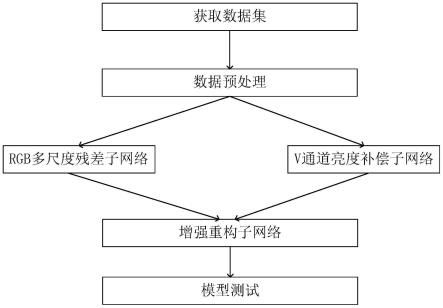
8.s1、获取网络训练所需数据集:通过选取水下图片和相应的增强图片作为训练集和测试集;
9.s2、数据预处理:对图片的尺寸和类型进行相应处理;
10.s3、rgb多尺度残差子网络训练:将rgb类型的训练集放入rgb多尺度残差子网络进行训练,得到增强网络模型1和输出结果y1;
11.s4、v通道亮度补偿子网络训练:将v通道的训练集放入v通道亮度补偿子网络进行训练,得到增强网络模型2和输出结果y2;
12.s5、增强重构环节:将输出结果y1和y2放入增强重构子网络进行计算,得到最终的增强结果y;
13.s6、模型测试:将待测的数据集放入训练好的增强网络1、增强网络2,通过增强重构子网络计算后即可得到增强后的图片。
14.本发明技术方案的进一步改进在于:所述s1中从公开数据集uiebd、euvp、ufo-120中随机选取6400张水下图片和相应的增强图片作为训练集;随机选取1600张水下图片包含或不包含相应的增强图片作为测试集。
15.本发明技术方案的进一步改进在于:所述s2的具体步骤包括:
16.将训练集和测试集裁剪为256
×
256的大小;原有的训练集和测试集是rgb类型的,将rgb类型转为hsv类型,提取亮度通道v并单独保存。
17.本发明技术方案的进一步改进在于:所述s3的具体步骤包括:
18.rgb多尺度残差子网络包括2个卷积层、3个多尺度残差块和1个激活函数,输入为rgb类型的水下图片x1,标签为相应的rgb类型的增强图片b1,输出为rgb类型的增强图片y1;损失采用的是感知损失l
con
和内容损失l2的线性组合;
19.第一个卷积层将输入图片x1的3通道转成64通道,经过relu激活函数送入连续的3个多尺度残差块进行特征提取,最后经过第二个卷积层将通道数转为3,得到生成的增强图片y1;
20.多尺度残差块包含4个通道:第一个通道不做处理,第二个通道采用两个3
×
3的卷积,第三个通道采用2个3
×
3的空洞卷积,在增大感受野的同时,不引入额外的计算量,第四个通道采用res2net模块,将原先的3
×
3卷积替换成3个3
×
3卷积,增大了感受野;第二个通道的第一个卷积层的输出和第三个通道的第一个卷积层的输出通过拼接作为第二个通道的第二个卷积层的输入和第三通道的第二个卷积层的输入,第二个通道的输出和第三个通道的输出通过拼接的方式,再经过1
×
1卷积与第一通道和第四通道的输出相加作为整个多尺度残差块的输出;
21.内容损失l
21
是计算增强图片y1与标签b1的像素间损失;
[0022][0023]
其中yi是rgb多尺度残差子网络训练的增强结果,bi是输入图片对应的增强图片,n是训练的图片数量;
[0024]
感知损失l
con1
计算增强图片y1与标签b1的高级感知特征之间的损失,采用的imagenet上预训练的vgg19模型;
[0025][0026]
其中yi是rgb多尺度残差子网络训练的增强结果,bi是输入图片对应的增强图片,φ是预训练的vgg19网络,j表示该网络的第j层,c
jhj
wj是第j层特征图的形状,n是训练的图片数量;
[0027]
总损失l
t1
是内容损失l
21
和感知损失l
con1
的线性组合;
[0028]
l
t1
=l2 l
con1
。
[0029]
本发明技术方案的进一步改进在于:所述s4的具体步骤包括:
[0030]
v通道亮度补偿网络包括卷积层、池化层、多尺度残差块、上采样和激活函数,输入为v通道水下图片x2,标签为相应的v通道增强图片b2,输出为v通道增强图片y2;损失采用的是感知损失l
con
、内容损失l2以及多尺度结构相似损失l
ms_ssim
的线性组合;
[0031]
第一个卷积层将输入图片x2的单通道转成64通道,经过relu激活函数得到特征f1,f1经过自适应池化将图片的尺寸从256
×
256变成128
×
128,然后通过1
×
1卷积,通道数由64变为128,送入第一个多尺度残差块得到特征f2,f2经过自适应池化将图片的尺寸从128
×
128变成64
×
64,然后通过1
×
1卷积,通道数由128变为256,送入第二个多尺度残差块得到特征f3,f3经过自适应池化将图片的尺寸从64
×
64变成32
×
32,然后通过1
×
1卷积,通道数由256变为512,送入第三个多尺度残差块得到特征f4,f2、f3、f4经过1
×
1卷积,通道数变为64,f4经过上采样后与f3进行残差连接,得到后的特征再经过上采样后与f2进行残差连接,得到后的特征再经过上采样与f1进行残差连接,最终通过3
×
3的卷积得到增强的v通道图片y2;
[0032]
内容损失l
22
是计算增强图片y2与标签b2的像素间损失;
[0033][0034]
其中yi是v通道亮度补偿子网络训练的增强结果,bi是输入图片对应的增强图片,n是训练的图片数量;
[0035]
感知损失l
con2
计算的是增强图片y2与标签b2的高级感知特征之间的损失,采用的imagenet上预训练的vgg19模型;由于增强图片y2与标签b2都是单通道的,vgg19模型的输入是3通道的,计算损失时需要将其扩展为3通道;
[0036][0037]
其中yi是v通道亮度补偿子网络训练的增强结果,bi是输入图片对应的增强图片,φ是预训练的vgg19网络,j表示该网络的第j层,c
jhj
wj是第j层特征图的形状,n是训练的图片数量;
[0038]
多尺度结构相似损失lms_ssim基于多层的ssim损失,考虑了分辨率、亮度、对比度、结构指标;
[0039][0040]
其中m表示不同的尺度,μ
p
,μg分别表示y2和b2的均值,σ
p
,σg表示y2和b2的之间的标准差,σ
pg
表示y2和b2之间的协方差,βm,γm表示两项之间的相对重要性,c1,c2是常数项防止除数为0;
[0041]
总损失l
t2
是内容损失l
21
、感知损失l
con1
和多尺度结构相似损失l
ms_ssim
的线性组合:
[0042]
l
t2
=l2 l
con1
l
ms_ssim
。
[0043]
本发明技术方案的进一步改进在于:所述s5具体包括:
[0044]
增强重构子网络是将rgb多尺度残差子网络的输出y1转为hsv类型,将其中的v通道值与v通道亮度补偿子网络的输出y2进行线组合,得到最终增强图片的v通道值,与y1的hs通道融合成新的hsv类型,再转为rgb类型,结合两个网络的优势,得到最终增强图片y。
[0045]
由于采用了上述技术方案,本发明取得的技术进步是:
[0046]
本发明提出了一种基于亮度补偿残差网络的水下图像增强方法,在基于多尺度残差块的rgb增强子网络中提出了一种新型的多尺度残差块,第三通道采用空洞卷积的好处是在减少计算量的同时扩大了感受野,第四通道将普通的3*3卷积替换成了res2net模块,在减少计算量的同时扩大了感受野;通过残差连接,使得浅层的细节信息与高层的语义信息相融,使得生成的图片颜色得到了修正,细节得到了增强;基于亮度补偿的v通道增强子网络,采用capafe上采样的方式,基于输入特征进行特征重组,在特征重组时具有更大的感受野,计算量小;多尺度特征融合,将浅层的细节信息与高层的语义信息相互融合,细节得到进一步补充;增强重构子网络将两者的优势相结合,使得最终生成的图片效果更好。
附图说明
[0047]
图1是本发明实施例的流程图;
[0048]
图2是本发明实施例的网络结构示意图;
[0049]
图3是本发明实施例多尺度残差块的结构示意图;
[0050]
图4是本发明实施例res2net模块的结构示意图。
具体实施方式
[0051]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0052]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0053]
图1为本发明实施例一种基于亮度补偿残差网络的水下图像增强方法的流程图。
[0054]
参见图1,实施例的水下图像增强方法,具体步骤如下:
[0055]
步骤s1:获取网络训练所需数据集,通过选取水下图片和相应的增强图片作为训练集和测试集;
[0056]
从公开数据集uiebd、euvp、ufo-120随机选取6400张水下图片和相应的增强图片作为训练集,训练集用以训练网络模型;随机选取1600张水下图片和相应的增强图片作为测试集,测试集也可以不包括相应的增强的图片,测试集用于评估模型的性能和泛化能力;
[0057]
步骤s2:数据预处理,对图片的尺寸和类型进行相应处理;
[0058]
将训练集和测试集裁剪为256
×
256的大小,便于计算,同时减少了内存的占用;
[0059]
原有的训练集和测试集是rgb类型的,需要将rgb类型转为hsv类型,提取亮度通道v并单独保存;
[0060]
步骤s3:rgb多尺度残差子网络训练;将rgb类型的训练集放入rgb多尺度残差子网络进行训练,得到增强网络模型1和输出结果y1;
[0061]
所述多尺度残差子网络如图2所示:
[0062]
rgb多尺度残差子网络是由2个卷积层、3个多尺度残差块、1个激活函数组成的,输入为rgb类型的水下图片x1,标签为相应的rgb类型的增强图片b1,输出为rgb类型的增强图片y1;损失采用的是感知损失l
con1
和内容损失l
21
的线性组合;
[0063]
第一个卷积层卷积核大小是3
×
3,步长为1,padding为1,作用是将输入图片x1的3通道转成64通道,经过relu激活函数送入连续的3个多尺度残差块进行特征提取,最后经过第二个卷积层,卷积核大小是3
×
3,步长是1,padding为1,作用是将多尺度残差块的输出通道数由64转为3,得到生成的增强图片y1;
[0064]
所述多尺度残差块如图3所示:
[0065]
多尺度残块的输入参数为feat,feat用于设定多尺度残差块内部输入输出通道数,多尺度残差块包含4个通道:第一个通道不做处理,第二个通道采用两个3
×
3的卷积,步长都为1,padding为1,但是两个卷积层的输入输出通道数不同,第一个卷积层的输入输出通道数是feat,第二个卷积层的输入输出通道数是feat
×
2;第三个通道采用2个3
×
3的空洞卷积,空洞率为2,步长都为1,padding为1,但是两个卷积层的输入输出通道数不同,第一个卷积层的输入输出通道数是feat,第二个卷积层的输入输出通道数是feat
×
2,在增大感受野的同时,不引入额外的参数;第四个通道采用res2net模块,将原先的3
×
3卷积替换成3个3
×
3卷积,增大了感受野;第二个通道的第一个卷积层的输出和第三个通道的第一个卷积层的输出通过拼接作为第二个通道的第二个卷积层的输入和第三通道的第二个卷积层的输入,第二个通道的输出和第三个通道的输出通过拼接的方式,再经过1
×
1卷积与第一通道和第四通道的输出相加作为整个多尺度残差块的输出,1
×
1卷积层的作用是将拼接后的特征的通道数由feat
×
4变成feat。在rgb多尺度残差子网络中所用的多尺度残差块的feat设为64;
[0066]
所述res2net模块如图4所示:
[0067]
res2net模块结构:输入特征经过1
×
1卷积后,将特征分为4部分。第一部分不经过处理;第二部分经过3
×
3卷积输出;第三部分与第二部分的输出相加后经过3
×
3卷积输出;第四部分与第三部分的输出相加后经过3
×
3卷积后输出;四部分的输出拼接后经过1
×
1输出;
[0068]
内容损失l
21
是计算增强图片y1与标签b1的像素间损失;
[0069][0070]
其中yi是rgb多尺度残差子网络训练的增强结果,bi是输入图片对应的增强图片,n是训练的图片数量;
[0071]
感知损失l
con1
计算增强图片y1与标签b1的高级感知特征之间的损失,采用的imagenet上预训练的vgg19模型;
[0072][0073]
其中yi是rgb多尺度残差子网络训练的增强结果,bi是输入图片对应的增强图片,
φ是预训练的vgg19网络,j表示该网络的第j层,c
jhj
wj是第j层特征图的形状,n是训练的图片数量;
[0074]
总损失l
t1
是内容损失l
21
和感知损失l
con1
的线性组合:
[0075]
l
t1
=l2 l
con1
。
[0076]
步骤s4:v通道亮度补偿子网络训练;将v通道的训练集放入v通道亮度补偿子网络进行训练,得到增强网络模型2和输出结果y2;
[0077]
v通道亮度补偿网络由卷积层、池化层、多尺度残差块、上采样、激活函数组成的,输入为v通道水下图片x2,标签为相应的v通道增强图片b2,输出为v通道增强图片y2;损失采用的是感知损失l
con
、内容损失l2以及多尺度结构相似损失l
ms_ssim
的线性组合;
[0078]
第一个卷积层卷积核大小是3
×
3,步长为1,padding为1,作用是将输入图片x2的1通道转成64通道,经过relu激活函数得到特征f1,f1经过自适应池化将图片的尺寸从256
×
256变成128
×
128,然后通过1
×
1卷积,通道数由64变为128,送入第一个多尺度残差块得到特征f2,第一个多尺度残差块的feat设为128,f2经过自适应池化将图片的尺寸从128
×
128变成64
×
64,然后通过1
×
1卷积,通道数由128变为256,送入第二个多尺度残差块得到特征f3,第二个多尺度残差块的feat设为256,f3经过自适应池化将图片的尺寸从64
×
64变成32
×
32,然后通过1
×
1卷积,通道数由256变为512,送入第三个多尺度残差块得到特征f4,第三个多尺度残差块的feat设为512。f2、f3、f4经过1
×
1卷积,通道数变为64,f4经过上采样后与f3进行残差连接,得到后的特征再经过上采样后与f2进行残差连接,得到后的特征再经过上采样与f1进行残差连接,最终通过3
×
3的卷积得到增强的v通道图片y2;
[0079]
内容损失l
22
是计算增强图片y2与标签b2的像素间损失;
[0080][0081]
其中yi是v通道亮度补偿子网络训练的增强结果,bi是输入图片对应的增强图片,n是训练的图片数量;
[0082]
感知损失l
con2
计算的是增强图片y2与标签b2的高级感知特征之间的损失,采用的imagenet上预训练的vgg19模型。由于增强图片y2与标签b2都是单通道的,vgg19模型的输入是3通道的,计算损失时需要将其扩展为3通道;
[0083][0084]
其中yi是v通道亮度补偿子网络训练的增强结果,bi是输入图片对应的增强图片,φ是预训练的vgg19网络,j表示该网络的第j层,c
jhj
wj是第j层特征图的形状,n是训练的图片数量;
[0085]
多尺度结构相似损失lms_ssim基于多层的ssim损失,考虑了分辨率、亮度、对比度、结构指标。
[0086]
[0087]
其中m表示不同的尺度,μ
p
,μg分别表示y2和b2的均值,σ
p
,σg表示y2和b2的之间的标准差,σ
pg
表示y2和b2之间的协方差,βm,γm表示两项之间的相对重要性,c1,c2是常数项防止除数为0;
[0088]
总损失l
t2
是内容损失l
21
、感知损失l
con1
和多尺度结构相似损失l
ms_ssim
的线性组合:
[0089]
l
t2
=l2 l
con1
l
ms_ssim
[0090]
步骤s5:增强重构环节;将输出结果y1和y2放入增强重构子网络进行计算,得到最终的增强结果y;
[0091]
增强重构子网络是将rgb多尺度残差子网络的输出y1转为hsv类型,将其中的v通道值与v通道亮度补偿子网络的输出y2进行线组合,得到最终增强图片的v通道值,与y1的hs通道融合成新的hsv类型,再转为rgb类型,结合两个网络的优势,得到最终增强图片y;
[0092]
步骤s6:模型测试,将待测的数据集放入训练好的增强网络1、增强网络2,通过增强重构子网络计算后即可得到增强后的图片;
[0093]
本实施例的基于亮度补偿残差网络的水下图像增强方法在基于多尺度残差块的rgb增强子网络中提出了一种新型的多尺度残差块,第三通道采用空洞卷积的好处是在减少计算量的同时扩大了感受野,第四通道采用res2net模块,在减少计算量的同时扩大了感受野;通过残差连接,使得浅层的细节信息与高层的语义信息相融,使得生成的图片颜色得到了修正,细节得到了增强;基于亮度补偿的v通道增强子网络,采用capafe上采样的方式,基于输入特征进行特征重组,在特征重组时具有更大的感受野,计算量小;多尺度特征融合,将浅层的细节信息与高层的语义信息相互融合,细节得到进一步补充。增强重构子网络将两者的优势相结合,使得最终生成的图片效果更好。
[0094]
对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0095]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。