融合gbdt和xgboost的路面iri预测方法
技术领域
1.本发明属于路面监测技术领域,涉及一种融合gbdt和xgboost的路面iri预测方法。
背景技术:
2.现有路面平整度评价指标(iri)预测方法主要包括两大类,一类是基于时间序列的预测方法,另一类是基于特征参数的学习型预测方法。
3.基于时间序列的预测方法主要预测路面全寿命周期内的性能指标衰变,用于养护规划和资金分配,利用的数据主要包括结构特征数据、交通环境数据和历史检测数据,往往需要足够多的历史检测数据建模。该方法未充分利用包括病害信息在内的底层检测数据、特征参数等。其主要问题是预测模型精度差,只能应用于网级道路管理决策。
4.基于特征参数的学习型预测方法主要分为两类,一类是辅助时间序列模型的建模,另一类是基于某一类检测数据预估其他性能指标。其精度相对较高,但是需要大量数据作为支撑,不同项目管理模式的移植性较差。
5.因此,亟需一种新的路面iri预测方法来提高预测精度。
技术实现要素:
6.有鉴于此,本发明的目的在于提供一种融合gbdt和xgboost的路面iri预测方法,解决现有学习型预测模型的特征选择问题;并采用融合模型,提高路面iri预测精度,可以大大提高养护资金规划效益,实现成本效益最优得目标。
7.为达到上述目的,本发明提供如下技术方案:
8.一种融合gbdt和xgboost的路面iri预测方法,具体包括以下步骤:
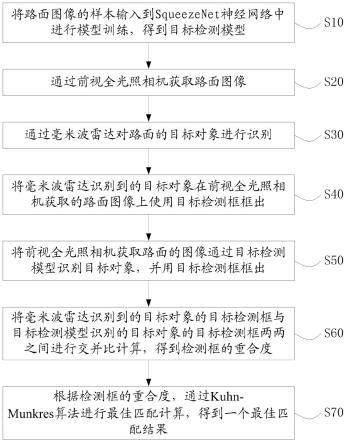
9.s1:获取路面特征数据,并采用随机森林算法选择特征数据集;
10.s2:构建stacking融合模型:将步骤s1的特征数据集划分成若干子数据集,输入第一层预测模型的各个基学习器中,每个基学习器输出各自的预测结果;然后,将第一层的模型输出与步骤s1的特征数据集作为第二层的输入,对第二层预测模型的元学习器进行训练,再对位于第二层的模型输出求平均值,得到最终预测结果。其中,第一层预测模型包括gbdt模型和xgboost模型;第二层预测模型的元学习器采用bagging模型。
11.进一步,步骤s1中,所述随机森林算法具体包括:采用平均不纯度下降指数,以分类或回归精度作为准则函数,采用序列后向选择和广义序列后向选择方法进行特征选择。
12.进一步,步骤s1中,所述平均不纯度下降指数mdi的计算公式为:
[0013][0014]
其中,imp、impr、imp
l
分别表示总体纯度及分叉左侧、右侧的纯度,n
t
、分别表示总体、左侧、右侧节点的样本数量,n是样本大小。
[0015]
进一步,步骤s2中,构建gbdt模型,具体包括:输入训练样本集t={(x1,y1),
…
,
(xi,yi),
…
,(xn,yn)},其中x是输入样本空间,xi是评估指标,y为履约情况,损失函数是l(yi,f(xi)),输出是回归树gbdt模型的具体训练过程为:
[0016]
1)初始化估计函数,使损失函数极小化;
[0017][0018]
其中,f0(x)是只有一个根节点的树,l(yi,c)是损失函数,c是使损失函数最小化的常数;
[0019]
2)令迭代次数为m=1,2,
…
,m,m表示最大迭代次数;
[0020]
①
对第i个样本,i=1,2,
…
,n,计算损失函数的负梯度,把它作为残差估计;
[0021][0022]
其中,r
mi
表示第i个样本的残差估计;
[0023]
②
拟合残差对rmj生成一棵回归树,以估计回归树叶节点区域,得到第m棵树节点区域r
mj
,其中,j=1,2,
…
,j,j表示叶子节点个数;
[0024]
③
对j=1,2,
…
,j,利用线性搜索估计叶节点区域的值,令损失函数最小化:
[0025][0026]
④
更新学习器fm(xi):
[0027][0028]
3)在相同的叶节点区域将所有c
mj
值累加,得到最终回归树:
[0029][0030]
进一步,步骤s2中,构建xgboost模型,具体包括:输入训练样本集t={(x1,y1),
…
,(xi,yi),
…
,(xn,yn)},其中x是输入样本空间,xi是评估指标,y为履约情况;
[0031]
目标函数为:
[0032][0033]
其中,表示预测值;
[0034]
在xgboost中,每棵树需逐个加入,以期效果能够得到提升;
[0035][0036][0037]
其中,t为树的数量;
[0038]
如果叶子的节点太多,模型的过拟合风险就会增大。所以在目标函数中加入惩罚
项ω(f
t
)来限制叶子节点个数;
[0039][0040]
其中,γ为惩罚力度,t为叶子的个数,ω为叶子节点的权重,λ为可调参数,ωj为每棵树叶子节点分数集合;
[0041]
完整的目标函数obj
(t)
为:
[0042][0043]
记得到
[0044][0045]
求出目标函数最优解:
[0046][0047]
上式可作为树的子叶分数,树的结构随着分数的增加而优异;且一旦分裂后的结果小于给定参数的最大所得值,算法将停止增长子叶深度。
[0048]
本发明的有益效果在于:
[0049]
(1)本发明解决了现有学习型预测的特征选择问题,不再采用单纯的相关性分析技术(例如:皮尔逊相关系数),而是采用基于特征学习的支撑度来考察其特征指标的选择。可以大大提升精度且模型具备较强的应用场景移植能力。
[0050]
(2)本发明采用融合模型,相对于单一模型而言,提高了路面iri预测精度,克服了传统预测模型仅解决平均拟合精度的问题。
[0051]
(3)本发明通过精度及移植性能的提高,本发明可以广泛应用于不同地区。本发明通过提高预测精度,可以大大提高养护资金规划效益,实现成本效益最优得目标。
[0052]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0053]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0054]
图1为本发明融合gbdt和xgboost的路面iri预测方法流程示意图;
[0055]
图2为基于随机森林算法的特征重要性评分示意图;
[0056]
图3为本发明stacking融合模型与现有多元线性回归、svm、gbdt、xgboost模型的
预测效果对比图。
具体实施方式
[0057]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0058]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0059]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0060]
请参阅图1~图3,为一种融合gbdt和xgboost的路面iri预测方法,主要包括以下几部分:
[0061]
1)获取所有特征数据(根据实际情况),具体特征变量见表1。
[0062]
表1特征变量相关描述
[0063]
[0064][0065]
2)特征选择
[0066]
拟采用机器学习的方式进行特征选择,使用的模型是随机森林。随机森林特征选择,就是使用随机森林算法,来自动选择相关性高的特征。它是一种基于随机森林的封装式特征选择算法,以随机森林算法为基本工具,以分类或回归精度作为准则函数,采用序列后向选择和广义序列后向选择方法进行特征选择。
[0067]
采用平均不纯度下降指数用于特征选择,
[0068][0069]
其中,imp、impr、imp
l
分别纯度,n
t
、分别表示节点的样本数量,n是样本大小。
[0070]
输入端口用于接收前置节点传下来的数据集,输出端口用于输出增加了离散后的字段的数据集,选择特征数量不超过20个,纯度下降梯度结果大于0.02的特征指标结果如图2所示。
[0071]
3)gbdt模型
[0072]
gbdt算法本质上是大量简单模型的联合,其核心在于,从第二棵决策树开始,每棵决策树的输入为其之前所有决策树的输出总和,基于这种提升思想,多个决策树的结论累加获得最终的输出。
[0073]
gbdt是一种基于gradient boosting策略训练出来的决策树类算法,主要由梯度提升、决策树算法和缩减三部分构成。gbdt的核心思想是减少残差,其每一次迭代是为了减少上一次迭代所产生的残差。当模型预测结果与实际观测值不一致时,在残差减少的梯度方向生成一棵新的决策树,以减少上一次的残差,连续反复迭代直至输出结果与实际观测值基本趋近一致。模型不断优化改进的一个标志是模型的损失函数迭代下降,gbdt算法就
是在损失函数梯度下降方向构建新的模型。
[0074]
输入训练样本集t={(x1,y1),
…
,(xi,yi),
…
,(xn,yn)},其中x是输入样本空间,xi是评估指标,y为履约情况,损失函数是l(yi,f(xi)),输出是回归树gbdt模型的具体训练过程为:
[0075]
1)初始化估计函数,使损失函数极小化;
[0076][0077]
其中,f0(x)是只有一个根节点的树,l(yi,c)是损失函数,c是使损失函数最小化的常数;
[0078]
2)令迭代次数为m=1,2,
…
,m,m表示最大迭代次数;
[0079]
①
对第i个样本,i=1,2,
…
,n,计算损失函数的负梯度,把它作为残差估计;
[0080][0081]
其中,r
mi
表示第i个样本的残差估计;
[0082]
②
拟合残差对rmj生成一棵回归树,以估计回归树叶节点区域,得到第m棵树节点区域r
mj
,其中,j=1,2,
…
,j,j表示叶子节点个数;
[0083]
③
对j=1,2,
…
,j,利用线性搜索估计叶节点区域的值,令损失函数最小化:
[0084][0085]
④
更新学习器fm(xi):
[0086][0087]
3)在相同的叶节点区域将所有c
mj
值累加,得到最终回归树:
[0088][0089]
4)xgboost模型
[0090]
xgboost是一种迭代型树类算法,将多个弱分类器一起组合成一个强的分类器,是梯度提升决策树(gbdt)的一种实现。xgboost是一种强大的顺序集成技术,具有并行学习的模块结构来实现快速计算,其通过正则化来防止过度拟合,可以生成处理加权数据的加权分位数草图。
[0091]
具体算法步骤如下:
[0092]
目标函数为:
[0093][0094]
其中,表示预测值;
[0095]
在xgboost中,每棵树需逐个加入,以期效果能够得到提升;
[0096]
[0097][0098]
其中,t为树的数量;
[0099]
如果叶子的节点太多,模型的过拟合风险就会增大。所以在目标函数中加入惩罚项ω(f
t
)来限制叶子节点个数;
[0100][0101]
其中,γ为惩罚力度,t为叶子的个数,ω为叶子节点的权重,λ为可调参数,ωj为每棵树叶子节点分数集合;
[0102]
完整的目标函数obj
(t)
为:
[0103][0104]
记得到
[0105][0106]
求出目标函数最优解:
[0107][0108]
上式可作为树的子叶分数,树的结构随着分数的增加而优异;且一旦分裂后的结果小于给定参数的最大所得值,算法将停止增长子叶深度。
[0109]
5)stacking融合模型
[0110]
stacking模型融合方法首先将原始特征数据集划分成若干子数据集,输入第一层预测模型的各个基学习器中,每个基学习器输出各自的预测结果。然后,第一层的输出再作为第二层的输入,对第二层预测模型的元学习器进行训练,再由位于第二层的模型输出最终预测结果。stacking模型融合方法可以通过对多个模型的输出结果进行泛化,提升整体预测精度。
[0111]
在第一阶段,首先将原始数据集进行切分,按照一定比例划分为训练集和测试集,然后选取合适的基学习器以交叉验证的方式对训练集进行训练,将训练完成后的各个基学习器对验证集和测试集进行预测,第一阶段应该选取预测性能优秀的机器学习模型,同时保证模型间的多元化;在第二阶段,将基学习器的预测结果分别作为元学习器训练和预测的特征数据,元学习器结合上个阶段得到的特征和原始训练集的标签为样本数据进行模型构建,并输出最终的stacking模型预测结果,该阶段的元学习器一般选取稳定性较好的简单模型,起到整体提升模型性能的作用。
[0112]
如图1所示,stacking融合模型:使用gbdt、xgboost两种不同的集成模型算法作为基学习器得到两组预测结果,然后将三组预测结果应用在第二层使用元学习器,选用的是
bagging模型进行训练,从而得到最终的预测结果。
[0113]
6)stacking融合模型预测结果及评价
[0114]
为了验证stacking融合模型在路面iri预测中的优越性,选择相同的训练集和测试集,将本发明stacking融合模型与现有4种预测模型(多元线性回归、svm、gbdt、xgboost)对比分析,如图3所示。
[0115]
以美国ltpp数据为例,横跨62个州、市,包括:交通量大小(76989条数据)、裂缝长度(12964条数据)、交通开放日期(1817条数据)、车辙深度(18128条数据)、iri大小(97535条数据)、纹理信息(18735条数据),共6张表,共计226128条数据。
[0116]
根据表1和图3所示,在路面iri预测结果上,本发明的stacking融合模型的精度在本身表现不错的gbdt和xgboost模型上得到了更进一步的提升,最终rmse为0.040、mae为0.013,r2为0.996,达到了路面预测中高精度的要求。
[0117]
表1各预测模型的评价指标
[0118][0119]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。