1.本发明涉及机器翻译技术领域,更具体的是涉及基于中间语义表示的文档级别机器翻译方法技术领域。
背景技术:
2.文档级别的机器翻译受到了研究领域持续增长的关注。相比较句子级别的机器翻译系统,文档级别的机器翻译系统更加实用,因为实际翻译任务基本上都是整篇文档。文档级别机器翻译和句子级别机器翻译的显著区别在于文档级别机器翻译在翻译每句话时都要考虑其在文档中的前后上下文,涉及到一些篇章结构信息包括指代、省略、一致性、连贯性等。研究表明,人类翻译员在翻译文档时也需要考虑整篇文档的上下文。虽然句子级别的机器翻译结果分开看已经很有竞争力,但从连在一起的整篇文档看还远远达不到让人满意的程度。
3.现有的文档级别机器翻译方法基本采用序列到序列的深度神经网络,例如最近的g-transformer模型,将文档上下文和翻译语句作为一个词或子词序列,映射生成目标语言的词或子词序列。这些方法依赖深度学习模型中的自注意编码器形成每个词或子词以及上下文关系的分布式表征。这种上下文关系是基于统计的隐式的关系,没有明确的关系表征和语义表征。以指代关系为例,分布式表征中不会明确表明某个代词指向前文中的哪个对象,可能会导致翻译结果虽然阅读起来流畅但语义和原文不一致。
技术实现要素:
4.本发明的目的在于:提升机器翻译表达的准确性。为了解决上述技术问题,本发明提供一种基于中间语义表示的文档级别机器翻译方法。
5.本发明为了实现上述目的具体采用以下技术方案:
6.一种基于中间语义表示的文档级别机器翻译方法,包括以下步骤:
7.步骤s1:通过amr parser将原始语言的文档中的语句进行解析,每个语句对应一个amr语义图,所述amr语义图包括多个概念节点;
8.步骤s2:通过amr coreference resolver将amr语义图进行补全;
9.步骤s3:将补全后的amr语义图进行组合,形成完整的doc-amr语义图;
10.步骤s4:通过图神经网络生成所述doc-amr语义图中各个概念节点的amr向量表征,所述amr向量表征包括上下文信息和节点关系信息,根据amr向量表征输出目标语言的翻译子词序列。
11.优选地,所述步骤s3中,所述形成完整的doc-amr语义图的方法包括:
12.进行分布式编码,获取每个单词的分布式上下文向量表征;
13.基于每个单词的分布式上下文向量表征获取每个概念节点的分布式上下文向量表征;
14.以每个概念节点的分布式上下文向量表征为基础,采用amrcoref-bert模型判别
需要跨句链接的所述概念节点;所述amrcoref-bert模型由标注好的训练数据进行训练;
15.采用共指消解神经网络对所述概念节点之间的共指链接关系进行预测,获得跨句共指链接;
16.根据跨句共指链接,将每个语句的arm语义图进行连接,形成所述doc-arm语义图。
17.优选地,所述步骤s4中的所述图形神经网络包括:
18.编码器端:用于生成所述amr向量表征;
19.解码器端:用于根据所述amr向量表征生成目标语言的翻译子词序列。
20.优选地,所述生成所述amr向量表征的方法包括:
21.输入原始语言文档的子词序列,原始语言文档的子词序列在所述编码器端的输入端被转换成对应的嵌入表示;
22.通过所述编码器端生成上下文嵌入表示;
23.将所述上下文嵌入表示对应到所述doc-arm语义图中的各个所述概念节点;
24.以所述上下文嵌入表示作为各个所述概念节点的初始化向量表征,经过多层图神经网络,将所述概念节点之间的关系表达进去,形成所述doc-amr语义图中各个所述概念节点的amr向量表征。
25.优选地,所述嵌入式表示采用embedding向量。
26.优选地,所述生成生成目标语言的翻译子词序列的方法为:
27.所述解码器端根据所述amr向量表征以序列方式逐词生成目标语言文档内容,组合成为所述翻译子词序列。
28.本发明的有益效果如下:
29.本方法使用了doc-amr语义图,通过显式的语义表征,能够防止上下文噪声带来的干扰,使得机器翻译的结构更稳定;基于本方法的方案能将意思相同但表达不同的句子归为一种amr语义图,所以对于源语言的不同表达有更好的鲁棒性,翻译结果也更一致;本方法方法对语料的规模需求更小,可以运用到低资源的语言上;本方法采用的doc-amr语义图完整表达了上下文中共指的对象,这种共指关系在翻译过程中得到保持,使得翻译后的文档前后有较高的一致性、连贯性和逻辑性。
附图说明
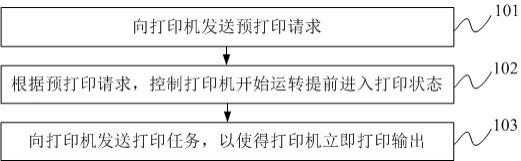
30.图1是本发明的流程示意图;
31.图2是实施例1的arm语义图;
32.图3是实施例1的amr coreference resolver解析后的arm语义图;
33.图4是实施例1的doc-arm语义图;
34.图5是实施例1的图神经网络示意图。
具体实施方式
35.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
36.因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
37.实施例1
38.如图1所示,本实施例提供一种基于中间语义表示的文档级别机器翻译方法,包括以下步骤:
39.步骤s1:通过amr parser将原始语言的文档中的语句进行解析,每个语句对应一个amr语义图,所述amr语义图包括多个概念节点;
40.以“the boys must not go”为例,其解析后的图结构如图2所示;
41.其中每一个节点表达一个在句子中出现的概念即concept,节点间的有向箭头表达句子中概念间的关系即relation。例如,arg#表示谓词的第几个论元。本例子中的arg0表达“boy”是行为“go”的主体。
42.步骤s2:通过amr coreference resolver将amr语义图进行补全;
43.由于文档上下文中的指代关系、内容省略等现象,使得要对篇章语义准确理解后才能做出准确的翻译。amr语义图作为句子语义的一种表示,没有反映出篇章级别的跨句关系,于是amr coreference resolver用来解决这个问题,amr coreference resolver可以将语句间的指代关系和省略内容补全。如图3所示,amr coreference resolver解析出sentence2中的“he”指向sentence1中的“bill”,sentence2中谓词“arrive-01”有一个缺失的论元arg3,内容是sentence1中的“paris”。
44.步骤s3:将补全后的amr语义图进行组合,形成完整的doc-amr语义图;
45.这一步扩展了句子级别amr的表达,例如图3中的句子进行组合后doc-amr语义图如图4所示。通过识别共指表达“bill”和“he”所对应的共指概念“p0:person”,我们定位到相应的概念节点,并建立谓词“arrive-01”和此概念节点的连接,然后将原概念节点“he”删除。
46.步骤s4:通过图神经网络生成所述doc-amr语义图中各个概念节点的amr向量表征,所述amr向量表征包括上下文信息和节点关系信息,根据amr向量表征输出目标语言的翻译子词序列。
47.作为优选方案,所述步骤s3中,所述形成完整的doc-amr语义图的方法包括:
48.进行分布式编码,获取每个单词的分布式上下文向量表征;
49.基于每个单词的分布式上下文向量表征获取每个概念节点的分布式上下文向量表征;
50.以每个概念节点的分布式上下文向量表征为基础,采用amrcoref-bert模型判别需要跨句链接的所述概念节点;所述amrcoref-bert模型由标注好的训练数据进行训练;
51.采用共指消解神经网络对所述概念节点之间的共指链接关系进行预测,获得跨句共指链接;
52.根据跨句共指链接,将每个语句的arm语义图进行连接,形成所述doc-arm语义图。
53.此外,本方法不同于传统序列到序列(seq2seq)模型,本方法以源语言的子词序列作为输入,先使用列到序列模型生成子词序列的上下文表征,然后在此上下文表征的基础
上叠加图神经网络,将doc-amr语义图的概念节点和关系表达为图神经网络中的节点和关系。经过多层的gnn模型后,可以生成各个概念节点的amr向量表征,这种amr向量表征既包含上下文信息,也包含节点关系信息,能实现较远上下文的语义关联。
54.在翻译的时候,以上面获取的amr表征向量为输入,nmt模型的解码器以传统的序列方式将逐个子词生成并合并为目标语言文档内容。
55.所以所述步骤s4中的所述图形神经网络参阅图5,可以包括:
56.编码器端:用于生成所述amr向量表征;
57.解码器端:用于根据所述amr向量表征生成目标语言的翻译子词序列。
58.进一步地,所述生成所述amr向量表征的方法包括:
59.输入原始语言文档的子词序列,原始语言文档的子词序列在所述编码器端的输入端被转换成对应的嵌入表示;
60.通过所述编码器端生成上下文嵌入表示,也就是图5中圆圈的部分;
61.将所述上下文嵌入表示对应到所述doc-arm语义图中的各个所述概念节点;
62.以所述上下文嵌入表示作为各个所述概念节点的初始化向量表征,经过多层图神经网络,将所述概念节点之间的关系表达进去,形成所述doc-amr语义图中各个所述概念节点的amr向量表征。
63.优选地,所述嵌入式表示采用embedding向量。
64.特别说明的是,翻译的焦点由解码器端中的cross-attention决定,通过学习获得焦点的转移策略,焦点可以简单理解为在翻译时注意力主要集中咋哪个语言上。
65.综合来说,首先,传统的序列到序列机器翻译模型,在无关的上下文发生改变时会产生不一样的翻译结果。比如说在要翻译的语句前后随意加上一段话,当前语句的翻译结果就经常不一样,有时本来正确的翻译会变错误,而首先本实施例的方案能够防止上下文噪声带来的干扰,使得机器翻译的结构更稳定。
66.其次,本实施例的方案可以将意思相同但表达不同的句子归为一种amr语义图,所以对于源语言的不同表达有更好的鲁棒性,翻译结果也更一致。同时,这种方法对语料的规模需求更小,可以运用到低资源的语言上。
67.最后,由于doc-amr语义图中完整表达了上下文中共指的对象,这种共指关系在翻译过程中得到保持,使得翻译后的文档前后有较高的一致性、连贯性和逻辑性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。