基于智能优化算法的多小区大规模mimo系统实时功率分配方法
技术领域
1.本发明涉及mimo系统实时功率分配方法,属于移动通信与无线网络技术领域。
背景技术:
2.为了适应无线数据流量的快速增长,5g技术的一个关键目标是将区域吞吐量提高两到三个数量级,甚至更高。目前,提高频谱效率已经成为实现5g网络中高吞吐量的主要途径,一种通用的提高频谱效率的方法是在收发机中使用多天线技术,即大规模mimo技术。在大规模mimo技术中,成千数百根天线被部署在基站侧,这种大规模天线阵列利用复用增益和分集增益,将通信系统的能量效率和频谱效率提升到了新的高度,并给未来移动通信的发展指明了方向;但大量的天线增加了接收终端信号检测的复杂度,进而影响对发送信号准确的接收,而通过预编码技术在发送端对发射信号进行预处理,即可避免影响接收机对信号的正确检测。
3.功率分配问题伴随着通信系统的发展,在大规模mimo系统中功率分配一直是一个重要的问题。通常解决功率分配问题会构建特定的目标函数进行算法设计,常见的目标函数有最大化最小频谱效率或最大化总和频谱效率,但传统的解决方法高度依赖于迭代,其计算复杂度高、计算时间长,无法应用到实际。并且在实际的通信系统中,为了给所有用户提供相同质量的服务,通常选择最大化最小频谱效率为目标函数求解功率分配,虽然能够实现完全的公平,但会降低系统总频谱效率;最大化总和频谱效率能够获得很高的总和频谱效率,但却完全忽略了用户之间的公平性。
技术实现要素:
4.本发明是为了解决基于传统方法的大规模mimo功率分配算法计算复杂度高以及当前在多小区大规模mimo系统中直接采用线性预编码方案不能使系统获得很好性能的缺点,提出了一种基于智能优化算法的多小区大规模mimo系统实时功率分配方法。
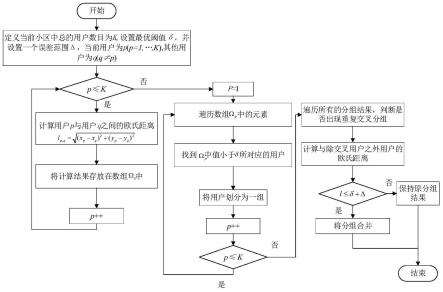
5.基于智能优化算法的多小区大规模mimo系统实时功率分配方法,首先获取用户位置信息,基于用户的位置信息,利用实时功率分配网络对用户进行实时功率分配;
6.所述的实时功率分配网络为神经网络,实时功率分配网络通过以下方式获得:
7.s1、建立多小区大规模mimo系统模型,系统工作在tdd模式下;tdd即时分双工模式;
8.s2、在上行链路阶段,基站利用接收到的导频信息进行信道状态信息csi估计,根据信道的互易性得到对下行链路的信道估计;
9.s3、首先对用户进行分组;根据小区内的分组结果,判断在小区内进行分组后是否存在未被分组的单独用户,如果存在单独用户,针对非单独用户的分组,在分组内采取rzf预编码;同时将分组后的每组等效为独立用户,将在等效的独立用户与未被分组的单独用户间采用bd预编码消除干扰;完成小区内干扰消除预编码;小区之间采用slnr进行预编码;
10.s4、基于免疫算法对多小区大规模mimo系统的功率进行分配,免疫算法产生初始抗体种群为nk种可能的解决方案,每个免疫个体代表对应分配的功率;构建免疫算法的亲和度函数如下:
11.max mean(se
cell1
)
×
...
×
mean(se
celll
)
×
min(se
cell1,k
)
×
...
×
min(se
celll,k
)
[0012][0013]
其中,ρ
jk
表示为小区j中用户k分配的功率,mean(se
celll
)表示小区l中所有用户的平均频谱效率,min(se
celll,k
)表示小区l中用户最小的频谱效率;se
celll
为小区l中用户的下行频谱效率;
[0014]
s5、如此通过免疫算法求得功率分配的解,并将用户位置信息和信道状态信息以及对应免疫算法得到的功率分配的结果保存起来作为数据集;其中用户位置信息和信道状态信息作为输入标签,功率分配的结果作为输出标签;
[0015]
在所搭建的大规模mimo系统中,设置随机生成所有小区中所有用户的位置x={x
jk
;j=1,...l;k=1,...k},进而产生信道,接着计算预编码矩阵、用户的信号和干扰,最后利用免疫算法迭代计算得到最优的功率分配结果;通过免疫算法寻优形成一个样本数据,经过多次循环迭代形成训练集;
[0016]
s6、搭建用于预测功率分配的神经网络模型;
[0017]
s7、将训练集中的用户位置信息和信道状态信息作为神经网络的输入,对应的功率分配作为神经网络的输出,利用训练集对神经网络进行训练,进而得到实时功率分配网络。
[0018]
进一步地,s2的具体过程包括以下步骤:
[0019]
在tdd模式下,下行链路信道是上行链路信道的转置,上行链路信道矩阵g由小尺度衰落矩阵h和大尺度衰落系数矢量β的对角阵组成,且大尺度衰落系数包含路径损耗和阴影衰落,小区j的所有k个用户到小区l基站的上行链路信道矩阵:
[0020][0021]
下行链路信道矩阵即可表示为其中t代表转置。
[0022]
进一步地,s3中对用户进行分组的过程包括以下步骤:
[0023]
(1)假设当前小区为j,在小区j内产生随机分布的k个用户,计算小区j内当前用户p的位置坐标(x
p
,y
p
)与其他所有剩余用户q的位置坐标(xq,yq)之间的欧氏距离,将其表示为:将计算的结果保存在数组ω
p
中;
[0024]
(2)基于最优距离阈值δ,设置误差范围δ;
[0025]
(3)遍历集合内的所有值,将距离小于δ所对应的用户划分为一组;
[0026]
(4)接着计算下一个用户(p 1)与其他所有剩余用户之间的欧氏距离,重复步骤(1)、步骤(3)进行分组;
[0027]
(5)遍历小区的内所有k个用户,完成当前小区内的用户分组;
[0028]
(6)遍历(5)所得到的小区内k个用户分组结果,判断是否存在重复交叉分组的情
况;对于两个交叉分组,针对二者的并集减去交集的元素,计算每两个元素的之间的欧氏距离,如果所有的欧式距离均小于δ δ,则将两个分组划为一组;否则保持原分组结果不变;以此情况类推,完成最终的分组情况。
[0029]
进一步地,s3中采用bd预编码算法在第j个小区中对于第k个用户,其预编码矩阵w
jk
需满足与本小区内的其它所有用户的信道矩阵正交。
[0030]
进一步地,小区之间采用slnr进行预编码的过程包括以下步骤:
[0031]
根据小区j的用户k接收到的信号可表示为:
[0032][0033]
其中,ρ
jk
表示发送端分配给用户k的功率,β
jlk
表示小区j的用户k与小区l的基站之间的大尺度衰落系数,[h
jlk1
,....,h
jlkm
]表示的第k行;
[0034]
基于slnr的预编码抑制ici,slnr的表达式为:
[0035][0036]
其中,ρ
jk
表示发送端分配给用户k的功率,σ2表示噪声功率。
[0037]
进一步地,在大规模mimo系统中,小区j中用户k的下行频谱效率为:
[0038][0039]
其中,代表在每个相干块中进行下行数据传输占整个相干时间的比值;sinr
jk
代表小区j中用户k对应的信干噪比。
[0040]
进一步地,信干噪比如下
[0041][0042]
其中,g
jjk
代表小区j中用户k与小区j基站间的信道,e{
·
}表示求期望。
[0043]
进一步地,基于免疫算法对多小区大规模mimo系统的功率进行分配的过程包括以下步骤:
[0044]
s401、产生初始抗体种群,初始抗体种群中每个免疫个体均是维数为(k
×
l)的矩阵,相应的值即代表对应分配的功率,第一代抗体随机产生后,其后的抗体在前一代抗体的基础上通过选择与更新得到,每个抗体对应的功率取值上限n
max
=p
max
,p
max
为每小区的基站在下行链路发射的总功率,取值下限n
min
=0;
[0045]
s402、计算初始种群内每个抗体的亲和度函数值;
[0046]
计算抗体相似度、抗体浓度和激励度;
[0047]
s403、选取激励度前nk/2个抗体进行免疫操作;先进行复制抗体,然后对复制得到的抗体进行变异操作,并需要对变异后的抗体进行边界条件的判定,再进行克隆抑制仅保
留亲和度高的复制抗体,最后进行种群刷新即再随机生成nk/2个抗体,种群合并形成新一代的抗体z
(1)
;
[0048]
s404、判断是否满足算法终止条件即设置的迭代次数,若满足,则终止寻优过程并输出结果;否则,继续寻优,直到算法满足终止,得到最优解z
(gen)
。
[0049]
进一步地,s6中的神经网络模型为具有全连接层的前馈神经网络,其具有2kl维的输入层,n个隐层和k 1维的输出层。
[0050]
进一步地,s7中在利用训练集对神经网络进行训练之前,需要对训练集中的数据进行标准化处理。
[0051]
有益效果:
[0052]
智能优化算法在解决全局寻优、非线性等复杂问题方面具有独特的优势。所以本发明将其运用到大规模mimo的功率分配问题中,可以在实现功率分配目标的同时使得系统整体和用户个体的频谱效率均得到提高。现阶段,伴随着机器学习的飞速发展,在通信领域,许多研究成功的将其与通信相结合,使其在通信领域也能发挥很好的作用。因此本发明基于神经网络在大规模mimo中进行功率分配,利用全连接的神经网络去拟合基于智能优化算法的功率分配方案,其性能在逼近优化算法的同时,还能降低计算的复杂度和时间。
附图说明
[0053]
图1为小区内用户分组流程示意图;
[0054]
图2为本发明的流程示意图;
[0055]
图3为多小区大规模mimo的系统模型示意图;
[0056]
图4为采用不同预编码方案求得用户频谱效率的累积概率分布函数(cdf)曲线;
[0057]
图5为免疫算法流程示意图;
[0058]
图6为分别使用免疫算法和传统二分算法求解得到的用户平均频谱效率的累积概率分布函数(cdf)曲线;
[0059]
图7为神经网络模型;
具体实施方式
[0060]
本发明首先设计基于分组消除干扰的预编码方案,然后利用人工免疫算法去替代传统的方法求解功率分配,最后利用神经网络去拟合用户信息和功率分配之间的关系,使其性能能够与传统的计算方法近似又能够降低计算复杂度和时间,通过降低计算复杂度和时间使得系统可以适应用户的位置移动,从而为用户执行实时的功率分配。
[0061]
具体实施方式一:结合图2说明本实施方式。
[0062]
本实施方式所述的基于智能优化算法的多小区大规模mimo系统实时功率分配方法,包括以下步骤:
[0063]
s1、建立多小区大规模mimo的系统模型:
[0064]
如图3所示,假设多小区大规模mimo系统中具有l=4个正六边形小区,每小区中心的基站端配置m=128根天线,每个小区内随机分布着k=20个用户终端,他们距离基站的最近距离为rc=100m,最远距离为小区的半径rh=1000m,相干时间长度t=200,大尺度衰落系数建模为β
jlk
=z
jlk
/(r
jlk
/rh)v,其中,路径损耗系数v=3.8,r
jlk
代表j小区用户k到小区l内
基站的距离,z
jlk
代表阴影衰落因子,10log10(z
jlk
)服从标准差为8db的高斯分布,导频复用因子为1,传输带宽20mhz,每个用户的上行发射功率均为100mw,p
max
=2000mw,总接收机噪声功率σ2设为-94dbm,蒙特卡洛仿真设置200次。
[0065]
s2、在多小区大规模mimo系统中,首先使用mmse信道估计方法对上行链路信道进行估计,通过对上行链路信道估计取转置即可得到下行链路信道的估计;
[0066]
小区j中所有用户k到小区l内基站的上行链路信道
[0067]
其中,h
jl
代表小尺度衰落矩阵,代表大尺度衰落系数矢量β组成的对角阵。
[0068]
上行信道估计时,小区中用户向基站发送导频序列,小区l基站接收到的导频信号为:
[0069][0070]
其中,ρ
p
表示用户发射导频功率,τ为用户发射导频序列长度,dj=[d
j1
,d
j2
,....,d
jk
]
t
为小区j的k个用户的导频向量,n
l
为加性高斯白噪声。
[0071]
经过mmse得到对h
jl
的估计为:
[0072][0073]
其中,i表示单位矩阵;ri为基站i接收到的导频信号,u
il
为小区i中所有用户到小区l基站的大尺度衰落矢量β组成的对角阵取平方。
[0074]
由此得到对下行链路的信道估计为:
[0075]
s3、将小区内用户进行分组,基于预编码矩阵消除小区内干扰、小区间干扰;
[0076]
在大规模mimo系统中,通常在下行链路中采用预编码算法对待发送信号进行预处理,基站利用信道矩阵,通过预编码算法抑制用户间的干扰,从而提高无线通信系统的传输质量。针对存在mui(多用户间干扰)和ici(小区间干扰)的多小区大规模mimo系统,大多数大规模mimo下行链路预编码都没有考虑消除小区间干扰,然而小区间干扰会在很大程度上降低mimo系统性能,特别是小区边界用户的性能。因此本发明提出的算法分为三步,首先将小区内用户进行分组,接着分别设计预编码矩阵消除小区内干扰、小区间干扰;
[0077]
s301、为了能够很好的消除用户之间的干扰,希望对每个用户设计的预编码矩阵与其他所有用户的信道矩阵相互正交,虽然这样能够消除干扰却没能够考虑噪声的问题,尤其是当用户位置距离近且低信噪比的情况下性能较差;因此设置合理的用户分组,减轻噪声干扰非常必要。以第j个小区为例,根据用户的位置坐标计算彼此之间的欧氏距离进行分组,小区内用户分组流程图如图1所示,这样考虑设计更贴近实际的通信场景,受到热点区域的影响,使得用户的分布在某一区域会呈现密集的特性,由于用户间的距离过近,会导致信道的矩阵因为高度相关而产生较大的奇异值,因而产生噪声放大的问题,所以有必要将用户进行分组。
[0078]
对用户进行分组的过程包括以下步骤:
[0079]
(1)假设当前小区为j,在小区j内产生随机分布的k个用户,计算小区j内当前用户
p的位置坐标(x
p
,y
p
)与其他所有剩余用户q的位置坐标(xq,yq)之间的欧氏距离,将其表示为:将计算的结果保存在数组ω
p
中;
[0080]
(2)基于最优距离阈值δ,设置误差范围
[0081]
(3)遍历集合内的所有值,将距离小于δ所对应的用户划分为一组;
[0082]
(4)接着计算下一个用户(p 1)与其他所有剩余用户之间的欧氏距离,重复步骤(1)、步骤(3)进行分组;(5)遍历小区的内所有k个用户,完成当前小区内的用户分组;
[0083]
(6)遍历(5)所得到的小区内k个用户分组结果,判断是否存在重复交叉分组的情况;对于两个交叉分组,针对二者的并集减去交集的元素,计算每两个元素的之间的欧氏距离,如果所有的欧式距离均小于δ δ,则将两个分组划为一组;否则保持原分组结果不变;以此情况类推,完成最终的分组情况;
[0084]
例如,假定某个用户a与用户b、c、d一组,但是用户b又与a、c、d、e、f一组的情况,将计算a与e、f之间的欧氏距离,如果a与e、f的距离均小于δ δ,则将a、b、c、d、e、f划为一组;否则保持原分组结果不变;以此情况类推,完成最终的分组情况;
[0085]
以上是一个小区内的用户分组,当给多个小区内用户分组时,重复以上过程即可,具体流程参考图1。
[0086]
s302、第j个小区的基站发送给用户的信号为:
[0087][0088]
其中,s
ji
表示在第j个小区中对用户i发送的信号,w
ji
表示在第j个小区中对用户i的预编码矩阵;
[0089]
针对上述小区的分组情况,在分组内采用rzf预编码,这里选取最优阈值δ为10,假设分组内共有n个用户,这n个用户与本小区基站之间的信道矩阵分别定义为g
j,1
,g
j,2
...g
j,n
;则其中任一用户n的rzf预编码矩阵为:其中,α表示正则化参数,i为单位矩阵,h表示取共轭转置。
[0090]
如果在第j个小区中不存在未被分组的单独用户,则已完成本小区内干扰消除预编码设计;反之,计算每个分组内所有用户的平均信道矩阵,将每组内所有用户视为一个等效独立用户,将其信道矩阵等效为计算得到的平均信道矩阵,没有被分组的用户仍视为单独用户,利用bd预编码算法消除等效独立用户和单独用户之间的干扰,求解未被分组单独用户的预编码矩阵。
[0091]
bd预编码算法能够完全抵消多用户间的同信道干扰,使得多用户mimo信道变成单用户的mimo信道,其核心思想是通过svd分解获得各用户相对其他用户无干扰的正交基,使得每个用户的预编码矩阵与其他所有用户的信道矩阵相互正交。
[0092]
为了消除等效独立用户和单独用户之间的干扰,使用bd预编码,对于某一单独用户ks,定义当前小区的其他用户信道矩阵为:为了求出的零空间,对矩阵进行svd分解:
[0093]
其中,为左奇异矩阵;是前个右奇异向量,rank()表示矩阵求秩,是后个右奇异向量;因此,构成了零空间的一个正交基;
[0094]
接着对单独用户ks的等效信道进行svd分解可得:
[0095][0096]
其中,uk为左奇异矩阵,为svd分解后的右奇异矩阵中的前lk列向量,
[0097]
所以第j个小区中单独用户ks的预编码矩阵可以设计为:
[0098][0099]
通过上述步骤,完成用户分组及小区内干扰消除。
[0100]
s303、为了降低用户接收到的干扰,通常会采用最大化sinr(信干噪比)来设计预编码矩阵,根据小区j中用户k接收到的信号可表示为:
[0101][0102]
其中,ρ
jk
表示发送端分配给等效用户k的功率,β
jlk
表示小区j的等效用户k与小区l的基站之间的大尺度衰落系数,[h
jlk1
,....,h
jlkm
]表示的第k行,w
li
表示小区l中用户i的预编码矩阵,s
li
表示给小区l中用户i的发送信号,n
jk
表示小区j中用户k接收到的噪声。
[0103]
可以得到用户的sinr表达式,然而利用sinr求解等效用户k的预编码矩阵wk需要涉及到其他用户的预编码矩阵,导致各个用户的优化相互耦合,无法得到准确的预编码向量准确的解,鉴于此,本发明采用基于slnr(信号泄露噪声比)的预编码抑制ici,slnr预编码虽然不能够消除用户自身的干扰,但却能消除用户间的干扰,最大化slnr表明泄露给其他用户的干扰最小同时意味着其他用户给自身带来的干扰更小,能够获得更好的系统和容量;
[0104]
经过消除小区内干扰预编码之后小区j内所有用户的下行链路等效矩阵为其中,是小区j内所有用户k到小区j基站的下行链路信道矩阵,w是小区j内所有用户消除用户间干扰的预编码向量组成的矩阵。
[0105]
接着考虑小区间干扰的问题,根据第j个小区中第k个用户的信漏噪比slnr
jk
的计算公式:
[0106][0107]
其中,β
jlk
表示小区j的用户k与小区l的基站之间的大尺度衰落系数,[h
jlk1
,....,h
jlkm
]表示的第k行,且h
jjkm
表示小区j用户k与小区j基站的第m根天线之间的小尺度衰落
因子,σ2为噪声功率;ρ
jk
表示为小区j中用户k分配的功率。
[0108]
定义:
[0109][0110][0111]
通过计算a
jk
和b
jk
最大广义特征值对应的广义特征向量,得到小区j用户k的预编码矩阵。
[0112]
图4所示为采用不同预编码方案求得用户频谱效率的累积概率分布函数(cdf)曲线对比,可以发现所提出的预编码方案相较于其他预编码方案可以取得较好的性能。
[0113]
s4、基于免疫算法对多小区大规模mimo系统的功率进行分配,免疫算法是受生物免疫系统的启发而推出的一种新型的智能搜索算法。免疫算法将优化问题中待优化的问题对应免疫应答中的抗原,可行解对应抗体,可行解质量对应免疫细胞与抗原的亲和度;如此将生物免疫应答中的进化抽象为进化寻优。如图5所示,具体包括如下步骤:
[0114]
s401、产生初始抗体种群,设定数目nk为20个免疫个体,初始抗体种群表示形式为即对应nk种可能的解决方案,每个免疫个体均是维数为(k
×
l)的矩阵,相应的值即代表对应分配的功率,第一代抗体随机产生后,其后的抗体在前一代抗体的基础上通过选择与更新得到,每个抗体对应的功率取值上限n
max
=p
max
,p
max
为每小区的基站在下行链路发射的总功率,取值下限n
min
=0;最大的免疫代数gen=300,变异概率pro=0.7,激励度系数分别为alfa=2和belta=1,邻域范围初值为ne=0.05*n
max
,相似度阈值delta=0.2,克隆个数co=10;
[0115]
s402、计算初始种群内每个抗体的亲和度函数值aff,其对应于优化目标:
[0116]
max mean(se
cell1
)
×
...
×
mean(se
celll
)
×
min(se
cell1,k
)
×
...
×
min(se
celll,k
)
[0117][0118]
其中,ρ
jk
表示为小区j中用户k分配的功率,mean(se
celll
)表示小区l中所有用户的平均频谱效率,min(se
celll,k
)表示小区l中用户最小的频谱效率。
[0119]
这样在兼顾最小频谱效率用户的同时也将整个系统的平均频谱效率考虑进来,使得用户个体和系统整体的性能同时都能得到提升。
[0120]
在大规模mimo系统中,求解小区j中用户k的下行频谱效率定义为:
[0121][0122][0123]
其中,代表在每个相干块中进行下行数据传输占整个相干时间的比值;g
jjk
代表小区j中用户k与小区j中基站间的信道;e{
·
}表示求期望。
[0124]
接着计算抗体相似度、抗体浓度和激励度;抗体间相似度确定的方法如下:若抗体m和抗体n中对应分配的功率差值小于相似度阈值θ时,就认为其是相似的,这里θ取值为5,抗体m与其他所有抗体n之间的相似度计算为:其中,abm、abn分别表示抗体m和抗体n,接着计算抗体m的浓度,抗体浓度表示抗体种群的多样性,其计算公式为:激励度是对抗体质量的最终评价结果,一般亲和度大、浓度低的抗体会获得更大的激励,其计算公式为:reward(abm)=alfa*aff(abm)-belta*den(abm)。
[0125]
s403、选取激励度前nk/2个抗体进行免疫操作;先进行复制抗体,然后对复制得到的抗体进行变异操作,并需要对变异后的抗体进行边界条件的判定,再进行克隆抑制仅保留亲和度高的复制抗体,最后进行种群刷新即再随机生成nk/2个抗体,种群合并形成新一代的抗体
[0126]
s404、判断是否满足算法终止条件即设置的迭代次数,若满足,则终止寻优过程并输出结果;否则,继续寻优,直到算法满足终止,得到最优解z
(gen)
;图6为分别使用免疫算法和传统二分算法求解得到的用户平均频谱效率的累积概率分布函数(cdf)曲线,可以发现采用免疫算法可以比传统的基于二分算法的求解使得系统性能得到提升。
[0127]
s5、通过免疫算法求得最优的功率分配策略,并将用户位置信息和信道状态信息以及对应免疫算法得到的功率分配结果保存起来作为数据集;其中用户位置信息和信道状态信息作为输入标签,功率分配的结果作为输出的标签。训练用于用户功率分配预测的神经网络,神经网络有助于减少系统确定用户位置信息与最优功率分配的处理时间,可以利用训练好的神经网络模型做到随用户位置变化进行实时的功率分配。
[0128]
在所搭建的大规模mimo系统中,设置随机生成用户的位置x={x
jk
;j=1,...l;k=1,...k},进而产生信道,接着计算预编码矩阵、用户的信号和干扰,最后利用免疫算法迭代计算得到功率分配的结果。
[0129]
通过免疫算法寻优形成一个样本数据,经过多次循环迭代形成一个大量的训练集;这里用户的位置信息因具有传播信道和系统干扰的本质特征被作为神经网络的输入。
[0130]
搭建用于预测功率分配的全连接的神经网络模型;
[0131]
为了使得搭建的神经网络模型对未知位置信息的用户预测结果更加精确,即神经网络模型具有更高的准确性和鲁棒性,设计具有全连接层的前馈神经网络,如图7所示,其具有2kl维的输入层,n个隐层和k 1维的输出层,用于预测产生近似最优的功率分配的结果;
[0132]
将数据集的数据进行标准化处理,并将得到的数据集在搭建的神经网络上进行训练;
[0133]
在进行训练之前,首先对模型进行初始化,设置最大迭代次数,设置批次大小;在进行训练时神经网络进行前馈后,我们会得到输出值和目标值之间的误差,然后使用反向传播更新权重和偏置,dnn模型将不断地学习,直到错误最小。训练完成后,保存模型。
[0134]
同样利用免疫算法产生测试数据集,送入已经训练好的神经网络模型当中,得到当前功率分配的预测,并将结果进行标准化的还原处理,即求得到功率分配的结果。
[0135]
本实施方式中,免疫算法进行多次迭代产生具有n=10000个样本的训练集,并将用户的位置信息、信道状态信息和功率分配的结果保存,将保存的结果进行标准化处理后送入神经网络进行模型训练,为了防止出现过拟合的现象,添加drop_out,drop_out函数的作用是将某些神经元的输出设置为0,使得该神经元失活,避免神经网络过分依赖这些神经元,且drop_out能够有效缓解过拟合,降低网络训练耗时。训练步骤如下:
[0136]
首先初始化模型,设置批次大小为n_batch_size=512,训练迭代次数epoch=500,并设置早停机制,随机抽取训练样本的10%作为验证集;神经网络训练经过前馈后,得到预测值与真实值之间的误差,定义为:
[0137][0138]
其中分别为预测结果和真实标签值;
[0139]
使用反向传播更新权重,持续进行,直至完成迭代;得到神经网络模型并保存。
[0140]
同样地,运用免疫算法随机生成n_test=1000的测试集,标准化处理后用所生成的模型进行测试,将得到的预测值进行标准化的还原即得到最优的功率分配结果。利用神经网络因为采用了简单的矩阵向量运算,可以降低功率分配的复杂性,与标准方法相比有利于在短时间内获得功率分配的最优解,因而可以跟随用户位置变化执行实时的功率分配。
[0141]
得到训练好的神经网络模型作为实时功率分配网络,利用实时功率分配网络对用户进行实时功率分配。
[0142]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
