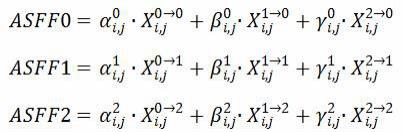
1.本发明涉及图像处理技术,具体来讲,涉及一种双支路混合残差连接的表情识别方法,该方法结合自适应特征融合,构建鲁棒的特征提取网络,以获得更优的人脸表情识别。
背景技术:
2.人脸表情在人与人之间的沟通中占据很大的比重。面部表情识别是计算机通过分析人脸信息尝试理解人类情感的一种技术,目前已成为计算机视觉领域的热点话题。随着面部表情研究的发展与深入,表情识别的方法也越来越多样化。要提高表情识别精度、速度以及处理识别中伴有的多种影响因素等问题在一定程度上受到计算机技术发展影响,而随着芯片处理能力的迅猛增长和网络体系结构的精心设计,各个领域的研究开始转向利用深度学习解决各种问题并且也取得了远超先前方法的识别结果 ,因此人脸表情识别技术在各个方面的发展空间也得以有了进一步发展。人脸表情识别任务也逐渐从实验室受控环境转移至具有挑战性的真实世界环境,在深度学习的带动下,神经网络能够自动学习特征信息,逐渐应用于自动人脸表情识别任务。
3.作为人脸识别的一个分支,表情识别的研究在心理学以及行为学等方面都有极大的研究价值。而面部表情分析中最关键的技术就是面部特征提取算法。由于表情特征信息存在类间相似性以及类内差异性特点,需要提取到足够完善细微的特征信息。但如果直接使用深度神经网络进行特征提取,容易出现过拟合现象,达不到我们需要的识别精度。因此,本设计提出一种混合残差连接方法,在此基础上设计双支路的特征提取网络,完善特征提取;其次,综合分析网络深度以及宽度两方面问题,融合深度可分离卷积,构建轻量级的表情识别网络;最后,根据人脸表情信息特点,为了获取更加精准、完善的特征信息,添加自适应特征融合模块,并对融合后的信息进行分析验证,选取表现最为优越的层级输出,进行最终的表情分类预测。将深度学习应用于表情识别,在保证识别精度的同时为提高应用性,轻量化的模型便于向其他嵌入式设备部署,也是目前的研究重点。
技术实现要素:
4.本发明的目的在于解决目前表情识别任务中存在的可靠表情识别数据库较少、非受控条件下识别不够鲁棒以及深度学习构建表情识别模型训练时间长,模型较大等问题,通过对非受控表情识别数据集fer2013进行训练以及测试,经所述方法,在使用单一网络训练,以及不采取额外训练数据情况下,获得较现有算法更好的识别率。
5.为了实现上述目的,本发明提供一种双支路混合残差连接的表情识别方法,以解决表情识别在非受控条件下的识别精度、以及模型的轻量化等问题,其中主要包括五个部分,第一部分是基础图像数据增强;第二部分是构建双支路混合残差网络进行特征提取;第三部分是添加自适应特征融合模块;第四部分是融合深度可分离卷积减少模型参数量;第五部分是网络训练与测试,输出最终的表情分类预测。
6.第一部分包括两个步骤:步骤1,对图片进行随机缩放裁剪,其次对图片数据进行水平翻转,以增加图片数据库;步骤2,使用mixup图片融合以及label_smoothing标签平滑方式对图片数据进一步增强,使得训练所得模型可以有更好的泛化能力;第二部分包括两个步骤:步骤3,主支路是对resnet18结构进行了修改:首先输入图片数据对应为通道数
×
图片高度
×
图片宽度,对应大小为1
×
40
×
40,由于图片尺寸较小,输入数据首先进行基础3
×
3卷积然后输入各layer层进行特征提取,之后再经过全局平均池化后传入全连接层进行表情的7分类预测;步骤4,次支路首先对原始resnet18网络的连接方式进行了简单修改:主支路残差连接块不变;从多尺度方面出发,选择使用1
×
1卷积核进行次支路部分的特征提取,能够最大限度保留来自原始输入图片的信息,并对最后的分类结果产生积极影响;第三部分包括两个步骤:步骤5,添加自适应特征融合模块asff将特征提取部分获取的大量多尺度表情信息,通过学习权重参数的方式将不同层的特征融合到一起,保证特征信息完善,并在一定程度去除产生的特征冗余;步骤6,对asff各层级结果分别输出,并进行最终的表情分类预测;第四部分包括一个步骤:步骤7,将普通卷积替换为深度可分离卷积,减少由于网络加深带来的巨大参数量;第五部分包括两个步骤:步骤8,调试从步骤2到步骤7的网络结构超参数,设置网络模型参数,其中,主要超参数学习率设定为0. 1,epochs设置为300,bach size设置为64,采用sgd优化器,并得到最终的训练模型;步骤9,下载非受控表情识别数据集fer2013,按照步骤8所设定训练好的模型进行训练以及测试。
7.本发明给出了一种双支路混合残差连接的表情识别方法。该方法针对表情特征信息存在类间相似性以及类内差异性特点,设计了双支路混合残差连接方式以确保提取特征的完整确切;其次,综合分析网络深度以及宽度两方面问题,融合深度可分离卷积,构建轻量级的表情识别网络;最后,根据人脸表情信息特点,为了获取更加精准、完善的特征信息,添加自适应特征融合模块,并对融合后的信息进行分析验证,选取表现最为优越的层级输出,进行最终的表情分类预测。本发明可以解决表情识别在非受控条件下的识别精度、以及模型的轻量化等问题。
附图说明
8.图1为本发明的网络整体框架图;图2为本发明的融合深度可分离卷积的双支路混合残差特征提取网络结构图;图3为本发明的自适应特征融合模块asff结构图。
具体实施方式
9.为了更好的理解本发明,下面结合具体实施方式对本发明的结合自适应特征融合和双支路混合残差连接特征提取网络进行更为详细的描述。在以下的描述中,当前已有技术的详细描述也许会淡化本发明的主题内容,这些描述在这里将被忽略。
10.图1是本发明结合自适应特征融合和双支路混合残差连接特征提取网络的具体网络模型图,mrs模块为设计的融合深度可分离卷积的双支路混合残差模块。在本实施方案中,按照以下步骤进行:步骤1,对图片进行随机缩放裁剪,其次对图片数据进行水平翻转,以增加图片数据库;步骤2,使用mixup图片融合以及label_smoothing标签平滑方式对图片数据进一步增强,使得训练所得模型可以有更好的泛化能力。具体实施如下:(1)训练数据输入尺寸为48
×
48,因此设置40
×
40的尺寸进行随机裁剪,随后对图片进行水平翻转以增加训练数据;(2)mixup操作主要是对输入两张图片进行融合,通过设置α的数值,控制两张图片的融合比例,融合因子数值设定为1.0。
11.步骤3,构建如图2所示的融合深度可分离卷积的双支路混合残差特征提取网络,主支路是对resnet18结构进行了修改:首先输入图片数据对应为通道数
×
图片高度
×
图片宽度,对应大小为1
×
40
×
40,由于图片尺寸较小,输入数据首先进行基础3
×
3卷积然后输入各layer层进行特征提取,每层卷积层的卷积核维度大小均为3
×
3维,其中每层卷积层经relu激活函数进行非线性化,最后再经过全局平均池化后传入全连接层进行表情的7分类预测;步骤4,次支路首先对原始resnet18网络的连接方式进行了简单修改:主支路残差连接块不变;从多尺度方面出发,选择使用1
×
1卷积核进行次支路部分的特征提取,能够最大限度保留来自原始输入图片的信息,并对最后的分类结果产生积极影响。具体实施如下:(1)将输入图片数据使用1
×
1卷积核大小从另一支路依次进行下采样,在融合对应残差连接块的特征信息后,作为下一次1
×
1卷积的输入,直至与最后一层残差连接块进行融合;(2)进行混合残差操作后的特征信息不送入主支路网络进行特征提取,而是单独作为尺度1特征输出,在最后联结主干残差块的残差信息。最后将主支路网络以及尺度1支路所得各尺度信息进行特征融合,经由全连接层融合全局特征用于表情分类;步骤5,构建如图3所示的自适应特征融合模块asff,添加自适应特征融合模块asff将特征提取部分获取的大量多尺度表情信息,通过学习权重参数的方式将不同层的特征融合到一起,保证特征信息完善,并在一定程度去除产生的特征冗余;步骤6,将步骤5中的自适应特征融合模块与步骤4中的不同尺度层级输出相结合,对asff各层级结果分别输出,并进行最终的表情分类预测。具体实施如下:(1)首先从特征提取主干网络中提取出三个不同尺寸的层级,选定其中一个层级levell (l∈[0,2])后,对其他两个层级leveln(n∈[0,2],n≠l)进行上采样或下采样,将尺寸调整到与levell相同,然后进行融合,融合后得到结果asffl,选择第一层级结果作为输出,也就是对应的asff0输出,选择融合的三个层级分别为level0对应尺寸为512
×5×
5,
level1对应尺寸为256
×
10
×
10,level2对应尺寸为128
×
20
×
20;(2)三个层级经由asff模块进行自适应特征融合,对三个层级特征图生成自适应特征权重,并通过softmax将数值范围控制在[0,1],最后的结果经由全局平局池化后进行最后的表情预测:对三个层级特征图分别与自适应权重相乘再相加即构成asff0、asff1、asff2。公式如下:其中代表从leveln层的特征resize到levell层后(i, j)处的特征向量,是指网络自适应学习的三个不同level到levell的特征映射的空间重要性权重,asff0、asff1、asff2是在空间尺度融合后输出的特征图。本发明最后的层级输出选择设定为asff2。因此选择asff2做具体说明:asff2是选择将来自level0、level1特征图resize为跟level2同尺寸,其中代表 level0重置后的特征图, 代表level1重置后的特征图,代表来自level2的特征图。
[0012]
其中为对应在asff2中的各特征图权重参数,权重参数的生成则是先将resize后的level0_resized、level1_resized,以及level2,分别进行1
×
1卷积对通道进行128到16的降维,然后将三张特征图拼接成48
×h×
w的通道数(h代表特征图的高,w代表特征图的宽),再进行1
×
1卷积降维到3
×h×
w,使用1
×
1卷积分别计算来自level0_resized、level1_resized、level2的,最后在通道维进行softmax分别与level0_resized、level1_resized、level2对应相乘即可得到:步骤7,将普通卷积替换为深度可分离卷积,减少由于网络加深带来的巨大参数量,具体实施如下:由于整体在经过多次下采样后,通道数已经达到了512,考虑到由于过深的网络会使表情识别过拟合,而深度可分离卷积分为通道卷积以及点卷积,在一定程度上加深了网络层数,过度使用有损网络精度,因此本发明只将resnet18的layer4层中的最后一层卷积替换为深度可分离卷积以减少参数;步骤8,调试从步骤2到步骤7的网络结构超参数,设置网络模型参数,其中,主要超参数学习率设定为0. 1,epochs设置为300,bach size设置为64,采用sgd优化器,并得到最终的训练模型;步骤9,下载非受控表情识别数据集fer2013,按照步骤8所设定训练好的模型进行训练以及测试。在未替换深度可分离卷积识别精度达到73.36%,替换深度可分离卷积后识
别精度仅降低了0.02%,但模型参数量将少了接近5m。
[0013]
本发明基于深度神经网络,给出了一种自适应混合残差连接的表情识别轻量化网络,该方法为了完善表情特征信息提取机制,设计双支路的多残差连接方式:主分支根据resnet18架构搭建,并学习xception架构中的深度可分离思想,针对本发明训练任务特点,融合深度可分离卷积,作为特征提取主干网络;次分支从不同尺度方面出发,对输入部分进行多残差连接,确保提取到的特征信息完整准确,选用1
×
1的卷积核,使特征信息能够最大限度保留来自原始输入图片的信息,辅助之后的类别预测保证特征信息完整。其次,综合分析网络深度以及宽度两方面问题,融合深度可分离卷积,构建轻量级的表情识别网络。最后,衔接自适应特征融合模块asff,融合不同层级特征信息,搭建完整表情识别网络,在对三个层级输出进行验证分析后,选取对类别特征反响更好的层级输出来进行最终的表情分类。本发明实现了基于深度学习的自适应混合残差连接表情识别轻量化网络,具有较强的应用价值。
[0014]
尽管上面对本发明说明性的具体实施方式进行了描述,但应当清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。