1.本发明属于计算机技术应用领域,涉及应用于游戏领域的人工智能技术,主要包括深度强化学习和深度学习,具体是涉及一种基于拆分动作空间的深度强化学习斗地主游戏方法。
背景技术:
2.近些年,人工智能技术被广泛运用于人们生活的各个领域之中。随着alphago在围棋领域带来的卓越成就,强化学习渐渐地在游戏领域崭露头角。其中,基于时序差分的强化学习方法是对状态或状态动作价值的估计进而指导智能体使其按照一定的策略选择动作,以达到较好的结果。然而,强化学习被运用到斗地主游戏中面临着动作空间巨大和奖励稀疏的问题。一方面,斗地主游戏的动作空间是根据游戏规则对牌进行组合进而构成的,动作空间总量高达两万多。由于动作都是牌的组合,所以拆分组合元素会大幅度降低动作空间。另一方面,斗地主游戏是典型的稀疏奖励环境,游戏期间,环境并不会返回有效的即时奖励信息,所以设计奖励机制能有效解决奖励稀疏的问题,促进网络训练。
技术实现要素:
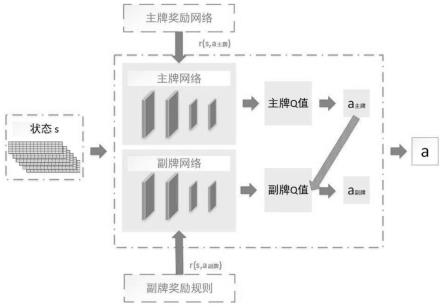
3.发明目的:本发明所要解决的技术问题是克服强化学习运用于斗地主游戏时动作空间巨大和奖励稀疏的问题,本发明根据斗地主游戏规则将动作空间分为主牌和副牌两个部分并为这两个部分构建奖励机制,形成主副牌dqn结构。本发明能够有效解决动作空间巨大和奖励稀疏的问题,进而提升斗地主游戏中智能体的智能性,提升游戏胜率。
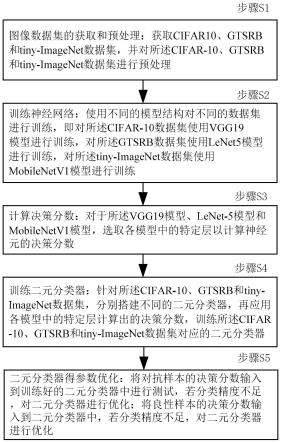
4.技术方案:本发明所述的一种基于拆分动作空间的深度强化学习斗地主游戏方法,具体操作步骤如下:
5.(1)、对斗地主游戏空间进行拆分;
6.(2)、对样本数据进行编码;
7.(3)、构建主牌dqn网络,定义主牌奖励函数;
8.(4)、构建副牌dqn网络,定义副牌奖励函数;
9.(5)、训练未进行动作空间拆分和奖励函数设计的dqn网络,确保该dqn网络的结构和设置于主牌dqn和副牌dqn一致;
10.(6)、将主副牌dqn智能体和单一dqn智能体置于地主、下家农民和上家农民的位置上与随机策略玩家进行模拟游戏,以胜率作为标准进行比较,将比较数据进行可视化展示。
11.进一步的,在所述步骤(1)中,对斗地主游戏空间进行拆分具体是:
12.(1.1)、根据斗地主游戏规则,区分一个出牌为主牌和副牌两部分;
13.(1.2)、遍历斗地主游戏所有的出牌可能性,拆分成主牌和副牌,进而构建主牌动作空间和副牌动作空间。
14.进一步的,在所述步骤(2)中,对样本数据进行编码具体是:
15.使用一个5*15的矩阵对牌信息进行编码表示,列表示牌的点数,从3到大王;行表
示数量,从0到4;
16.选择以当前手牌信息、最近三次出牌信息、已经出了的牌和还剩下的牌作为状态信息,拼接成一个6*5*15的矩阵;
17.将斗地主游戏数据处理为《s,a,r,s’》,构建《s,a,r,s’》样本集,
18.其中,a表示是一个集合,包括主牌动作和副牌动作;s表示一个6*5*15的one-hot矩阵;r表示一个集合,包括采取主牌动作后的即时奖励和采取副牌动作后的即时奖励;s’表示一个6*5*15的one-hot矩阵,表示转移到的下一个状态。
19.进一步的,在所述步骤(3)中,构建主牌dqn网络,定义主牌奖励函数的具体步骤如下:
20.(3.1)、收集并处理高水平人类玩家的游戏数据为特征数据和标签二元组:收集高水平人类玩家的斗地主游戏数据,并以当前手牌信息为特征数据,出牌动作处理为one-hot编码形式作为标签数据,形成以《特征数据,标签数据》二元组为元素的集合作为专家数据集合;
21.(3.2)、构建主牌奖励网络;将专家数据放入主牌奖励网络中训练,即使用高水平人类玩家游戏数据进行训练;网络的输入为玩家的手牌信息,输出为玩家在该手牌信息下,采用动作的可能性;
22.主牌奖励网络训练好后,以一个状态下采取该动作的softmax值作为该动作的即时奖励;
23.(3.3)、构建主牌dqn网络,使用主牌奖励网络得出样本中一个状态下采取一个动作对应的奖励值,将经过主牌奖励网络更新后的主牌样本数据输入到主牌经验池中,更新为新的样本数据,训练主牌dqn网络。
24.进一步的,在所述步骤(4)中,构建副牌dqn网络,定义副牌奖励函数是根据副牌本身的点数和副牌在其他可能性牌组出现的次数定义副牌奖励函数,其具体步骤如下:
25.(4.1)、定义副牌奖励规则,其具体公式为:
26.reward=k*e-(a b)
27.式中,a表示该副牌在其他可能动作中出现的次数,b表示该副牌组合牌面大小的总和,k表示常数超参数;
28.(4.2)、构建副牌dqn网络,将经过副牌奖励函数规则更新后斗地主游戏样本的副牌样本数据,并作为副牌dqn网络的输入,通过新的深度强化学习框架进行训练,训练副牌dqn网络。
29.进一步的,在所述步骤(5)中,确保该dqn网络的结构和设置于主牌dqn和副牌dqn一致具体是构建单一的dqn网络,不拆分动作空间,不构建奖励函数。
30.有益效果:本发明与现有技术相比,本发明的特点是:1、本发明将斗地主游戏的动作空间按照主牌和副牌的区别,拆分为主牌动作空间和副牌动作空间,有效降低了斗地主游戏的动作空间;2、本发明根据不同的动作空间,制定相对应的奖励规则。对于主牌,搭建并训练主牌奖励网络。对于副牌,使用人为定义奖励规则;本发明的最终结果是相比于单一的dqn网络,主副牌dqn网络能够有效提升斗地主游戏中智能体的表现,能够有效提升智能体游戏胜率。
附图说明
31.图1是本发明中斗地主游戏牌型图;
32.图2是本发明的整体流程示意图。
33.图3是本发明中dqn算法构建的深度强化学习框架示意图;
34.图4是本发明中信息编码的示意图;
35.图5是本发明中主牌奖励网络的结构图;
36.图6是本发明实施例中作为地主玩家与随机策略玩家对抗主副牌dqn和dqn的结果对比。
37.图7是本发明实施例中作为下家农民玩家与随机策略玩家对抗主副牌dqn和dqn的结果对比图
38.图8是本发明实施例中作为上家农民玩家与随机策略玩家对抗主副牌dqn和dqn的结果对比图。
具体实施方式
39.下面结合附图及实施例对本发明作进一步的说明。
40.如图所述,本发明所述的一种基于dqn深度强化学习算法的斗地主游戏方法,包括以下步骤:
41.步骤1、对斗地主游戏空间进行拆分,即斗地主游戏的出牌规则规定了具体的牌型,将每个牌型中满足牌组合大小要求的部分定义为主牌,满足牌型的部分定义为副牌,进而将斗地主游戏的动作空间拆分为主牌动作空间和副牌动作空间;
42.具体如下:
43.步骤1.1、根据斗地主游戏规则,区分一个出牌为主牌和副牌两部分,如牌组3334为例,333为主牌,4为副牌,则动作可拆分为333*和***4;
44.步骤1.2、遍历斗地主游戏所有的出牌可能性,拆分成主牌和副牌,进而构建主牌动作空间和副牌动作空间;
45.步骤2、对样本数据进行编码,本发明使用一个5*15的矩阵对牌信息进行编码表示,列表示牌的点数,从3到大王,行表示数量,从0到4;本发明选择以当前手牌信息、最近三次出牌信息、已经出了的牌和还剩下的牌作为状态信息,拼接成一个6*5*15的矩阵;构建《s,a,r,s’》样本集。其中a是一个集合,包括主牌动作和副牌动作;
46.步骤3、构建主牌dqn网络,定义主牌奖励函数,即:利用dqn算法构建深度强化学习框架,搭建主牌dqn网络,其具体如下:
47.步骤3.1、收集高水平人类玩家的斗地主游戏数据,并以当前手牌信息为特征数据,出牌动作处理为one-hot编码形式作为标签数据,形成以《特征数据,标签数据》二元组为元素的集合作为专家数据集合;即:收集并处理高水平人类玩家斗地主游戏数据,以监督学习的方式训练主牌奖励函数,主牌奖励网络的输入是玩家的手牌信息,输出是在当前输入状态下所有动作的概率;
48.步骤3.2、构建主牌奖励网络;将专家数据放入主牌奖励网络中训练;主牌奖励网络训练好后,以一个状态下采取该动作的softmax值(概率)作为该动作的即时奖励;即:以当前手牌信息作为主牌奖励网络的输入,以网络输入的该动作的概率值作为即时奖励,更
新主牌样本数据;
49.步骤3.3、构建主牌dqn网络,使用主牌奖励网络得出样本中对应的奖励值,将经过主牌奖励网络更新后的主牌样本数据输入到主牌经验池中,训练主牌dqn网络;即:搭建主牌dqn网络,将主牌样本数据放入经验池中进行训练;
50.步骤4、构建副牌dqn网络,定义副牌奖励函数,即:利用dqn算法构建深度强化学习框架,搭建副牌dqn网络;其具体如下;
51.步骤4.1、定义副牌奖励规则,公式为:
52.reward=k*e-(a b)
53.其中,a代表该副牌在其他可能动作中出现的次数,b表示该副牌组合牌面大小的总和,k为常数超参数;
54.步骤4.2、构建副牌dqn网络,将经过副牌奖励规则更新后的副牌样本数据输入到副牌经验池中,训练副牌dqn网络;
55.步骤5、训练没有进行动作空间拆分和奖励函数设计的dqn网络,并且确保该dqn网络的结构和设置于主牌dqn和副牌dqn完全一致;即:利用dqn算法构建深度强化学习框架,搭建完整动作空间的dqn网络;
56.步骤6、将主副牌dqn智能体和单一dqn智能体置于地主、下家农民和上家农民的位置上与随机策略玩家进行模拟游戏(以100轮游戏为准);比较主副牌dqn和单一dqn的胜率;
57.步骤7、参见附图6、附图7和附图8;附图6是作为地主,主副牌dqn和单一dqn的胜率比较;附图7是作为下家农民,主副牌dqn和单一dqn的胜率比较;附图8是作为上家农民,主副牌dqn和单一dqn的胜率比较将比较数据进行可视化展示;
58.作为本发明所述的针对斗地主游戏动作空间巨大问题的解决方法,步骤1.1根据斗地主游戏的出牌规则,将一次出牌中能够决定牌组大小的部分定义为主牌,剩余部分定义为副牌;步骤1.2将所有的斗地主游戏动作可能性拆分为主牌和副牌两个部分,形成主牌动作空间和副牌动作空间,以此替代巨大的完整动作空间。
59.作为本发明所述的针对斗地主游戏奖励稀疏的解决方法,步骤2首先对样本数据进行处理,对牌面信息进行编码,处理样本数据为《s,a,r,s’》。
60.作为本发明所述的针对斗地主游戏奖励稀疏的解决方法,步骤3针对主牌部分构建了主牌网络,搭建了主牌dqn网络结构;步骤3.1收集并处理高水平玩家游戏数据作为专家数据;步骤3.2构建了主牌奖励网络,采用监督学习的方法,将专家数据的手牌信息作为特征数据,将经过one-hot编码后的出牌动作作为标签;主牌奖励网络的输出是一个状态下所有动作的softmax值;步骤3.3使用主牌奖励网络确定某状态下采取某动作的奖励更新样本数据《s,a,r,s’》,并放入主牌dqn网络中训练。
61.作为本发明所述的针对斗地主游戏奖励稀疏的解决方法,步骤4针对副牌部分设计了奖励函数,搭建了副牌dqn网络结构;步骤4.1采用人为定义奖励函数的形式解决奖励稀疏的问题。步骤4.2采用步骤4.1的奖励规则,重新定义斗地主游戏中采取副牌动作的奖励值,作为样本数据《s,a,r,s’》,放入dqn中训练。
62.作为本发明所述的针对斗地主游戏动作空间巨大和奖励稀疏的解决方法,步骤5搭建了一个拥有完整的巨大动作空间和奖励稀疏的dqn网络;该dqn网络的结构和参数设置与主牌dqn和副牌dqn网络完全一致。
63.作为本发明所述的针对斗地主游戏动作空间巨大和奖励稀疏的解决方法,步骤6将主副牌dqn和一个dqn的结果进行比较,以游戏胜率作为比较标准并进行可视化展示。
64.本发明是基于强化学习算法dqn的改进,提升智能体在斗地主游戏中的胜率;针对于基于时序差分的强化学习算法在斗地主游戏中因动作空间巨大和奖励稀疏而导致胜率不高,智能性不明显的问题,本发明提出了改进方法;针对于动作空间巨大的问题,本发明使用构建主牌动作空间和副牌动作空间取代一个巨大的完整动作空间;针对于奖励稀疏的问题,本发明基于拆分后的动作空间,设定奖励机制;主牌动作会进一步确定可选副牌,所以对于主牌动作,本发明借鉴人类玩家游戏策略,搭建主牌奖励网络;针对于副牌,本发明采用人为设计奖励规则。
65.具体实施例
66.主副牌dqn网络选择以单一dqn网络作为比较对象;将主副牌dqn和单一dqn智能体分别置于地主、下家农民和上家农民的位置,与随机策略智能体进行游戏;将相同训练条件下智能体游戏胜率作为标准;参见附图6、附图7和附图8。
67.附图6比较地主身份下智能体的游戏胜率,主副牌dqn智能体训练过程较快,且最后稳定在百分之七十的胜率浮动,而单一dqn训练不稳定,速度慢,且效果明显次于主副牌dqn。
68.附图7比较下家农民身份下智能体的游戏胜率;主副牌dqn智能体以较快速度训练至较稳定状态,并保持在约百分之八十五的胜率,明显优越于单一dqn。
69.附图8比较上家农民身份下智能体的游戏胜率;主副牌dqn的胜率比单一dqn高出百分之十至百分之十五。
70.附图6、附图7和附图8强有力地说明了主副牌dqn有效提升了智能体的智能性,大幅度地提升了智能体游戏胜率;拆分动作空间和构建奖励机制能有效提升智能体在斗地主中的游戏表现。
71.以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。