一种基于ai辅助博弈的无标度网络防御性能提升方法
技术领域
1.本发明涉及人工智能技术领域,尤其涉及一种基于ai辅助博弈的无标度网络防御性能提升方法。
背景技术:
2.为了增强无标度网络的安全性,研究人员重点研究了网络结构的鲁棒性、针对性攻击的最优防御策略等方向。获得最优防御策略的主要挑战之一是难以用传统的数学方法计算均衡点。为了解决这一挑战,研究者们开始使用策略空间不断增加的种群策略。do方法是该类策略中出现比较早的方法,该方法迭代扩展了带有均衡的最佳响应的枚举策略集。
3.人工智能的发展,例如强化学习和深度学习,使得解决多方博弈的均衡不限于上述方法。研究者们通过强化学习缩短隐形僵尸网络的生命周期,优化和动态部署有限数量的防御机制。通过结合广义do方法和深度q网络提出的psro框架,能够用来统一许多现有的多智能体学习方法。该框架已经在一些博弈场景中得到应用,并取得了不错的效果。此外,一些研究者进一步扩展了智能体在攻击图博弈中的能力,让他们能够在博弈中逐渐学习到更好的dnn策略。为了增强安全性,一些工作设计了具有实时信息的绿色安全博弈模型,并为智能体训练策略。针对物联平台中设备海量异质、网络状态多变、平台易受攻击等挑战,本发明提出了一种基于ai辅助博弈的无标度网络防御性能提升方法。
技术实现要素:
4.本发明的目的在于通过结合人工智能与博弈论,解决网络博弈空间巨大的问题,从而找到最佳的抵御网络攻击的策略,构建智能物联平台的主动防御机制,在发现平台故障或网络攻击后,系统能智能地采取应对措施。
5.为了实现上述目的,本发明采用了如下技术方案:
6.一种基于ai辅助博弈的无标度网络防御性能提升方法,具体包括以下步骤:
7.s1、根据无标度网络中节点的相对位置及连接关系,构建一个有向图g=(v,e),其中,v表示节点的集合;e表示所有边的集合;
8.s2、为每个节点分配一个状态变量,用于表示节点的当前状态;其中,用active表示当前节点已经被入侵;用inactive表示当前节点处于安全状态;
9.s3、选择能够反映节点对网络连通性贡献的指标,计算每个节点对应指标的值以及节点的权重;所选择的指标包括结构洞、接近中心性以及中介中心性;
10.s4、对所述s3中计算所得的每个节点对应指标的值以及节点的权重进行排序;
11.s5、采用综合分析方法,根据所述s3、s4中定义的指标及指标排序,对节点的重要性进行排序;
12.s6、通过将所述s5中计算所得的节点的重要性与一个因子相乘,计算q值;
13.s7、选用policy space response oracle来训练智能体;
14.s8、所述s7中提到的智能体训练基于oracle o来搜索策略,采用深度q网络作为
oracle o,更具体的,利用卷积神经网络作为智能体的策略。
15.优选地,所述s3中提到的计算每个节点对应指标的值以及节点的权重,即每个节点的结构洞、接近中心性、中介中心性和权重的计算,具体计算过程如下:
16.a1、结构洞s(u)是反映网络结构中节点重要性的指标,其计算公式为:
[0017][0018]
其中,n(v)表示节点v的邻居节点的集合;p
uv
是与节点u和v相邻的边的归一化相互权重;
[0019]
a2、接近中心性c(u)反映了节点在信息传输路径中的重要性,其计算公式为:
[0020][0021]
其中,d(u,v)表示节点u和v之间的最短路径距离;n是可以到达u的节点数;
[0022]
a3、中介中心性b(u)反映了节点在信息传输中的重要性,其计算公式为:
[0023][0024]
其中,v是所有节点的集合;σ(i,j)是i和j之间的最短路径数;σ(i,j|u)是通过u的最短路径数量;
[0025]
a4、节点的权重w(u)表示网络设备中包含的内容的重要性。
[0026]
优选地,所述s5中提到的对节点的重要性进行排序,具体计算过程如下:
[0027]
b1、将n个节点的节点权重、结构洞、接近中心性及中介中心性四项指标用矩阵a表示,具体为:
[0028][0029]
其中,a
ij
表示节点i的第j个指标;
[0030]
b2、对节点权重、中介中心性和接近中心性三项正面指标进行标准化,具体为:
[0031][0032][0033]
其中,表示第j个指标的最大值,则r
ij
为节点i的第j个指标归一化的结果;
[0034]
b3、对结构洞这一负面指标进行标准化,具体为:
[0035]
[0036][0037]
其中,表示第j个指标的最小值,则r
ij
为节点i的第j个指标归一化的结果;
[0038]
b4、根据指标的排名,为标准化指标分配不同的权重,用wj表示第j个指标的权重,并且通过分配权重,可以获得具有权重的归一化矩阵x,具体为:
[0039][0040]
其中,wj表示第j个指标的权重,r
ij
为节点i的第j个指标归一化的结果,x
ij
表示wj*r
ij
的结果;
[0041]
b5、获取每个指标的最大值和最小值,并组成最大和最小理想解的向量,具体为:
[0042][0043][0044]
其中,为第一个指标加权的最大值,为第四个指标加权的的最大值,为第一个指标加权的的最小值,为第四个指标加权的的最小值;
[0045]
b6、计算每个节点接近最大理想解a
的程度及接近最小理想解a-的程度具体为:
[0046][0047][0048]
其中,是第j个指标加权的最大值,是第j个指标加权的最小值,x
ij
是加权归一化矩阵x的第i行第j列值;
[0049]
b7、计算节点的重要性pi,具体为:
[0050][0051]
其中,表示节点接近最大理想解a
的程度;表示接近最小理想解a-的程度。
[0052]
优选地,所述s7中提到的智能体训练,具体训练过程如下:
[0053]
c1、为每个智能体通过随机选择合法的动作来初始化一个统一的策略,并形成一个初始策略配置文件s,其中,包含两个智能体的统一策略;
[0054]
c2、通过在博弈环境中模拟配置文件s来获得每个智能体的收益u(s),并用u(s)来
初始化收益张量m并迭代地扩展它;
[0055]
c3、使用meta-solver m来得到m上的纳什均衡分布π;
[0056]
c4、智能体通过oracle o输入π来搜索新的策略,并以受益偏差为准则;
[0057]
c5、当policy space response oracle算法的一次迭代结束时,如果发现至少一个智能体的最优响应,那么将形成所有新的策略配置文件,并得到新的收益u(s)来扩展收益张量m;
[0058]
c6、在更新的收益张量m上计算新的纳什均衡π,并探索新的最佳响应;
[0059]
c7、当没有新的最佳响应时,终止训练并返回最终的纳什均衡π、智能体的策略集和收益张量m作为结果。
[0060]
优选地,所述s8中提到的利用卷积神经网络作为智能体的策略,具体计算过程如下:
[0061]
d1、定义三维张量和来分别表示攻击者和防御者对网络状态的观察,其中,和是有网络形成的邻接矩阵;(i,j)等于1代表着网络图中从节点vi到节点vj有一条边e
ij
,否则等于0;代表攻击者观察到的存在观察误差的全局防御措施,表示攻击者认为在边e
ij
上存在防御措施,否则上存在防御措施,否则代表着没有观察误差的全局防御措施;表示节点的激活状态,表示节点vi处于激活状态,否则处于激活状态,否则表示防御者观察到的存在观察误差的节点激活状态;
[0062]
d2、博弈是由智能体随机选择动作开始,并将得到的和分别作为智能体的cnn输入,从而对智能体进行训练;
[0063]
d3、在每一步结束时,攻击者根据这一步中被激活的节点获得奖励ra以及新的观测o
′a;
[0064]
d4、防御者根据被激活的节点得到处罚rd以及新的观测o
′d;
[0065]
d5、根据得到的o
′a和o
′d,继续oracle o的操作,直至满足预期要求。
[0066]
与现有技术相比,本发明提供了一种基于ai辅助博弈的无标度网络防御性能提升方法,具备以下有益效果:
[0067]
本发明利用无标度网络中的网络对抗博弈,构建了博弈环境,设计了合适的博弈规则,并采用基于值的深度强化学习(drl)、深度q网络(dqn)来指导种群进化。通过利用结合多种指标的q,以cnn为策略的防御代理能够采取合理有效的行动来阻止攻击者的入侵,在保护高权重节点和保持网络连通性之间取得平衡。作为智能物联平台的主动防御机制,本发明能够让平台在发现故障或网络攻击后,智能地采取应对措施。
附图说明
[0068]
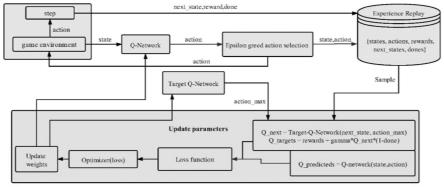
图1为本发明提出的一种基于ai辅助博弈的无标度网络防御性能提升方法的深度q网络中智能体的训练过程示意图;
[0069]
图2为本发明提出的一种基于ai辅助博弈的无标度网络防御性能提升方法的20个
节点的卷积神经网络架构图。
具体实施方式
[0070]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0071]
实施例1:
[0072]
请参阅图1-2,一种基于ai辅助博弈的无标度网络防御性能提升方法,具体包括以下步骤:
[0073]
s1、根据无标度网络中节点的相对位置及连接关系,构建一个有向图g=(v,e),其中,v表示节点的集合;e表示所有边的集合;
[0074]
s2、为每个节点分配一个状态变量,用于表示节点的当前状态;其中,用active表示当前节点已经被入侵;用inactive表示当前节点处于安全状态;
[0075]
s3、选择能够反映节点对网络连通性贡献的指标,计算每个节点对应指标的值以及节点的权重;所选择的指标包括结构洞、接近中心性以及中介中心性;
[0076]
s3中提到的计算每个节点对应指标的值以及节点的权重,即每个节点的结构洞、接近中心性、中介中心性和权重的计算,具体计算过程如下:
[0077]
a1、结构洞s(u)是反映网络结构中节点重要性的指标,其计算公式为:
[0078][0079]
其中,n(v)表示节点v的邻居节点的集合;p
uv
是与节点u和v相邻的边的归一化相互权重;
[0080]
a2、接近中心性c(u)反映了节点在信息传输路径中的重要性,其计算公式为:
[0081][0082]
其中,d(u,v)表示节点u和v之间的最短路径距离;n是可以到达u的节点数;
[0083]
a3、中介中心性b(u)反映了节点在信息传输中的重要性,其计算公式为:
[0084][0085]
其中,v是所有节点的集合;σ(i,j)是i和j之间的最短路径数;σ(i,j|u)是通过u的最短路径数量;
[0086]
a4、节点的权重w(u)表示网络设备中包含的内容的重要性;
[0087]
s4、对s3中计算所得的每个节点对应指标的值以及节点的权重进行排序;
[0088]
s5、采用综合分析方法,根据s3、s4中定义的指标及指标排序,对节点的重要性进行排序;
[0089]
s5中提到的对节点的重要性进行排序,具体计算过程如下:
[0090]
b1、将n个节点的节点权重、结构洞、接近中心性及中介中心性四项指标用矩阵a表示,具体为:
[0091][0092]
其中,a
ij
表示节点i的第j个指标;
[0093]
b2、对节点权重、中介中心性和接近中心性三项正面指标进行标准化,具体为:
[0094][0095][0096]
其中,表示第j个指标的最大值,则r
ij
为节点i的第j个指标归一化的结果;
[0097]
b3、对结构洞这一负面指标进行标准化,具体为:
[0098][0099][0100]
其中,表示第j个指标的最小值,则r
ij
为节点i的第j个指标归一化的结果;
[0101]
b4、根据指标的排名,为标准化指标分配不同的权重,用wj表示第j个指标的权重,并且通过分配权重,可以获得具有权重的归一化矩阵x,具体为:
[0102][0103]
其中,wj表示第j个指标的权重,r
ij
为节点i的第j个指标归一化的结果,x
ij
表示wj*r
ij
的结果;
[0104]
b5、获取每个指标的最大值和最小值,并组成最大和最小理想解的向量,具体为:
[0105][0106][0107]
其中,为第一个指标加权的最大值,为第四个指标加权的的最大值,为第一个指标加权的的最小值,为第四个指标加权的的最小值;
[0108]
b6、计算每个节点接近最大理想解a
的程度及接近最小理想解a-的程度具体为:
[0109][0110][0111]
其中,是第j个指标加权的最大值,是第j个指标加权的最小值,x
ij
是加权归一化矩阵x的第i行第j列值;
[0112]
b7、计算节点的重要性pi,具体为:
[0113][0114]
其中,表示节点接近最大理想解a
的程度;表示接近最小理想解a-的程度;
[0115]
s6、通过将s5中计算所得的节点的重要性与一个因子相乘,计算q值;
[0116]
s7、选用policy space response oracle来训练智能体;
[0117]
s7中提到的智能体训练,具体训练过程如下:
[0118]
c1、为每个智能体通过随机选择合法的动作来初始化一个统一的策略,并形成一个初始策略配置文件s,其中,包含两个智能体的统一策略;
[0119]
c2、通过在博弈环境中模拟配置文件s来获得每个智能体的收益u(s),并用u(s)来初始化收益张量m并迭代地扩展它;
[0120]
c3、使用meta-solver m来得到m上的纳什均衡分布π;
[0121]
c4、智能体通过oracle o输入π来搜索新的策略,并以受益偏差为准则;
[0122]
c5、当policy space response oracle算法的一次迭代结束时,如果发现至少一个智能体的最优响应,那么将形成所有新的策略配置文件,并得到新的收益u(s)来扩展收益张量m;
[0123]
c6、在更新的收益张量m上计算新的纳什均衡π,并探索新的最佳响应;
[0124]
c7、当没有新的最佳响应时,终止训练并返回最终的纳什均衡π、智能体的策略集和收益张量m作为结果;
[0125]
s8、s7中提到的智能体训练基于oracle o来搜索策略,采用深度q网络作为oracle o,更具体的,利用卷积神经网络作为智能体的策略;
[0126]
s8中提到的利用卷积神经网络作为智能体的策略,具体计算过程如下:
[0127]
d1、定义三维张量和来分别表示攻击者和防御者对网络状态的观察,其中,和是有网络形成的邻接矩阵;(i,j)等于1代表着网络图中从节点vi到节点vj有一条边e
ij
,否则等于0;代表攻击者观察到的存在观察误差的全局防御措施,表示攻击者认为在边e
ij
上存在防御措施,否则上存在防御措施,否则代表着没有观察误差的全局防御措施;表示节点的激活状态,
表示节点vi处于激活状态,否则处于激活状态,否则表示防御者观察到的存在观察误差的节点激活状态;
[0128]
d2、博弈是由智能体随机选择动作开始,并将得到的和分别作为智能体的cnn输入,从而对智能体进行训练;
[0129]
d3、在每一步结束时,攻击者根据这一步中被激活的节点获得奖励ra以及新的观测o
′a;
[0130]
d4、防御者根据被激活的节点得到处罚rd以及新的观测o
′d;
[0131]
d5、根据得到的o
′a和o
′d,继续oracle o的操作,直至满足预期要求。
[0132]
本发明利用无标度网络中的网络对抗博弈,构建了博弈环境,设计了合适的博弈规则,并采用基于值的深度强化学习(drl)、深度q网络(dqn)来指导种群进化。通过利用结合多种指标的q,以cnn为策略的防御代理能够采取合理有效的行动来阻止攻击者的入侵,在保护高权重节点和保持网络连通性之间取得平衡。作为智能物联平台的主动防御机制,本发明能够让平台在发现故障或网络攻击后,智能地采取应对措施。
[0133]
实施例2:
[0134]
请参阅图1-2,基于实施例1但有所不同之处在于,
[0135]
一种基于ai辅助博弈的无标度网络防御性能提升方法,具体包括以下步骤:
[0136]
步骤1:根据无标度网络中节点的相对位置及连接关系,构建出一个有向图g=(v,e);
[0137]
步骤2:依次计算节点的权重、结构洞、接近中心性以及中介中心性,并根据四个指标获取对应的q值;
[0138]
步骤3:执行psro算法,每个智能体通过随机选择合法的动作来初始化一个统一的策略,并形成一个初始策略配置文件s,其中,包含两个智能体的统一策略;
[0139]
步骤4:通过在博弈环境中模拟配置文件s来获得每个智能体的收益u(s),并用u(s)来初始化收益张量m并迭代地扩展它;
[0140]
步骤5:使用meta-solver m来得到m上的纳什均衡分布π;
[0141]
步骤6:智能体通过oracle o输入π来搜索新的策略,具体为根据得到的和分别作为智能体的cnn输入,从而对智能体进行训练;
[0142]
步骤7:在每一步结束时,攻击者根据这一步中被激活的节点获得奖励ra[0143]
以及新的观测o
′a,防御者根据被激活的节点得到处罚rd以及新的观测o
′d;
[0144]
步骤8:根据得到的o
′a和o
′d,继续oracle o的操作,直至满足预期要求;
[0145]
步骤9:当psro算法的一次迭代结束时,如果发现至少一个智能体的最优响应,那么将形成所有新的策略配置文件,并得到新的收益u(s)来扩展收益张量m;
[0146]
步骤10:在更新的收益张量m上计算新的纳什均衡π,并探索新的最佳响应;
[0147]
步骤11:当没有新的最佳响应时,终止训练并返回最终的纳什均衡π、智能体的策略集和收益张量m作为结果。
[0148]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,
任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。