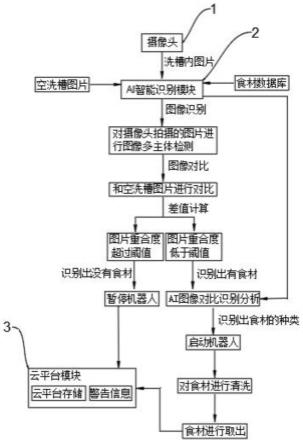
1.本技术涉及人工智能领域,具体涉及一种识别药材的方法和装置。
背景技术:
2.中药是一类天然药材,在新冠肺炎等疾病治疗领域有独特的价值。中药品质的好坏与疗效有较大的关系,很多中药在外观上具有很高的相似度,如人参和西洋参,药材识别错误会造成严重的后果。
3.传统的识别方法包括性状鉴别、粉末鉴别和理化鉴别等,这些方法均需要经过长期培训的专业人员实施,并且识别所需时间较长。如何提高中药的识别效率是当前需要解决的问题。
技术实现要素:
4.本技术提供了一种识别药材的方法和装置,能够提高中药的识别效率。
5.第一方面,提供了一种识别药材的方法,包括:获取药材图像;通过特征提取网络处理所述药材图像,生成多个特征图,其中,所述特征提取网络包括至少一个可变形卷积模块,所述多个特征图的尺度不同;通过特征融合网络处理所述多个特征图中的目标特征图,生成特征融合后的特征图;通过检测网络处理所述特征融合后的特征图,输出所述药材图像的识别结果。
6.传统的特征提取网络使用的是普通卷积核来处理图像,普通卷积核在图像上提取的特征区域都是规则区域(如3
×
3的矩形区域)。由于药材的天然属性,药材图像中的药材形状通常是不规则的,若使用传统的特征提取网络处理药材图像,提取的特征会包含较多的空白特征,一方面会导致药材识别效率下降,另一方面会导致药材识别准确率下降。可变形卷积模块包含一个初始的随机偏移量,随着训练迭代,该随机偏移量会变得符合数据分布,使得卷积核的作用区域更加符合药材的形状。此外,药材图像没有旋转不变性,引入方向参数(即,偏移量)能够带来更多的信息。因此,使用包含可变形卷积模块的特征提取网络处理药材图像的特征图,能够提取出更多的有效特征,从而提高药材的识别效率和识别准确率。
7.可选地,所述特征提取网络还包括预处理模块和至少一个语义提取模块,所述至少一个语义提取模块包括第一语义提取模块,所述至少一个可变形卷积模块包括第一可变形卷积模块,所述通过特征提取网络处理所述药材图像,生成多个特征图,包括:通过所述预处理模块处理所述药材图像,生成第一特征图;通过所述第一语义提取模块处理所述第一特征图,生成第二特征图;通过所述第一可变形卷积模块处理所述第二特征图,生成第三特征图。
8.预处理模块能够将药材图像转换为被可变形卷积模块处理的特征图,语义提取模块能够提取特征图中的特征,以便于特征融合网络继续处理。
9.可选地,所述预处理模块包括focus模块和第一卷积模块,所述通过所述预处理模
块处理所述药材图像,生成第一特征图,包括:通过所述focus模块处理所述药材图像,生成下采样特征;通过所述第一卷积模块处理所述下采样特征,生成所述第一特征图。
10.focus模块(focus)能够实现没有信息丢失的下采样,从而提高药材识别的准确率。
11.可选地,所述特征提取网络还包括协调注意力模块,所述协调注意力模块用于在所述至少一个语义提取模块中最后一个语义提取模块输出的特征图中嵌入位置信息,所述位置信息为所述药材图像中待检测对象的坐标信息。
12.协调注意力模块能够将待检测对象的坐标信息嵌入特征图中,使得特征融合网络可以更快的找到特征图中的有效特征,减小特征融合网络的计算开销。
13.可选地,所述特征融合网络包括第二卷积模块和反卷积模块,所述通过特征融合网络处理所述多个特征图中的目标特征图,生成特征融合后的特征图,包括:通过所述第二卷积模块处理所述协调注意力模块输出的特征图,生成第四特征图;通过所述反卷积模块处理所述第四特征图,生成第五特征图;根据所述第五特征图和所述目标特征图生成所述特征融合后的特征图。
14.在特征融合网络处理特征图时,一种处理方法是通过双线性插值方法(即,上采样)处理第二卷积模块输出的特征图,然而,当药材图像存在多个药材时,这种处理方法会导致药材之间的边界发生渐变和扩散。通过反卷积模块处理特征图能够解决这种问题,提高药材识别的准确率。
15.可选地,所述至少一个语义提取模块为跨阶段局部(cross stage partial,csp)瓶颈网络。
16.可选地,所述获取药材图像,包括:获取多个训练图像,所述多个训练图像包括待检测对象的图像;将所述多个训练图像拼接为合成图像;对所述合成图像进行裁剪,生成所述药材图像,所述药材图像包括所述待检测对象和至少一个干扰对象。
17.检测网络在识别过程中会对特征融合图(即,特征融合后的特征图)进行网格划分,网格划分会导致一个药材的图像被划分至不同的网格中,造成一个网格中的药材图像不完整,这会导致识别结果出现误差。在本实施例中,药材图像是多张训练图像经过拼接和裁剪后得到的结果,药材图像包含完整的待检测药材图像和不完整的干扰药材图像,从而可以提高检测网络的抗干扰能力。
18.可选地,所述通过检测网络处理所述特征融合后的特征图,包括:通过所述检测网络对所述特征融合后的特征图进行网格划分,其中,所述网格划分对应的网格尺寸与所述药材图像中待检测对象的尺寸负相关。
19.当待检测对象较大时,说明拍摄药材照片时待检测对象距离镜头较近,特征融合图上待检测对象的细节特征(如表面凸起)比较清晰,检测网络可以在特征融合图上划分较小的网格,这样,检测网络可以专注于识别不同网格中的细节特征,提高识别准确率。此外,当待检测对象的部分区域被干扰对象遮挡时,较小的网格划分能够得到更多个没有干扰对象的网格,提高识别准确率。当待检测对象较小时,说明拍摄药材照片时待检测对象距离镜头较远,特征融合图上待检测对象的细节特征比较模糊,较小的网格划分意义不大,较大的网格划分反而能够使检测网络专注于宏观特征(如外观形状),从而提高了识别准确率。
20.第二方面,提供了一种识别药材的装置,包括处理器和存储器,该存储器用于存储
计算机程序,该处理器用于从存储器中调用并运行该计算机程序,使得该装置执行第一方面中任一种方法。
21.第三方面,提供了一种计算机程序产品,所述计算机程序产品包括:计算机程序代码,当所述计算机程序代码被识别药材的装置运行时,使得该装置执行第一方面中任一种方法。
22.第四方面,提供了一种计算机可读介质,所述计算机可读介质存储有程序代码,所述程序代码包括用于执行第一方面中任一种方法的指令。
附图说明
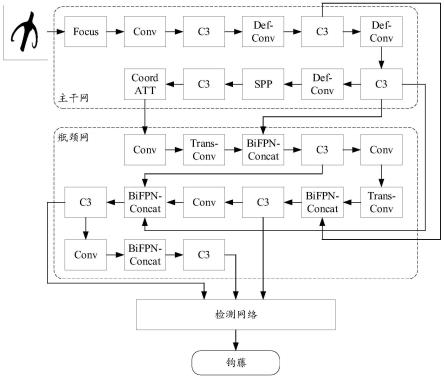
23.图1是适用于本技术的一种网络结构的示意图;
24.图2是本技术提供的一种药材识别网络的示意图;
25.图3是本技术提供的一种可变形卷积处理特征图的过程的示意图;
26.图4是本技术提供的几种卷积核的示意图;
27.图5是本技术提供的一种使用可变形卷积核在特征图上采样的结果的示意图;
28.图6是本技术提供的一种协调注意力模块的网络结构的示意图;
29.图7是本技术提供的两种特征融合网络的部分结构的示意图;
30.图8是本技术提供的两种特征融合网络进行特征融合处理后得到的结果的示意图。
31.图9是本技术提供的两种网格划分方法的示意图;
32.图10是本技术提供的一种训练图像的示意图;
33.图11是本技术提供的一种拼接和裁剪方法的示意图;
34.图12是本技术提供的一种训练方法的示意图;
35.图13是本技术提供的一种识别药材的装置的示意图;
36.图14是本技术提供的一种电子设备的示意图。
具体实施方式
37.下面将结合附图,对本技术中的技术方案进行描述。
38.图1是适用于本技术的一种网络结构的示意图。
39.该网络结构包括特征提取网络、特征融合网络和检测网络,需要说明的是,这种网络划分方式是示意性的,还可以进一步划分出更细微的网络结构,不同的网络结构(如特征提取网络和特征融合网络)的集合也可以被称为一个网络。
40.特征提取网络用于提取药材图像中待检测对象的特征,特征融合网络用于融合待检测对象的特征,检测网络基于融合后的特征识别待检测对象。例如,图1中的药材图像为钩藤图像,钩藤图像输入药材识别网络后,药材识别网络对钩藤图像进行特征提取、特征融合和检测,最终输出钩藤图像的识别结果“钩藤”。
41.需要说明的是,在实际使用过程中,输入药材识别网络的图像可能包含多种药材。
42.下面详细介绍本技术提供的药材识别网络的结构和工作流程。
43.特征提取网络可以是图2所示的主干网(backbone),药材图像进入主干网后,首先经过图像预处理模块中的focus的处理。focus的作用是:减少层数,减少参数,减少每秒浮
点运算次数(floating-point operations per second,flops),减少统一计算设备架构(compute unified device architecture,cuda)内存,提高前向传播和后向传播的速度,以及减小特征提取对平均准确率(mean average precision,map)的负面影响。
44.药材图像经过focus的处理后生成没有信息丢失的下采样特征,从而提高药材识别的准确率。随后,下采样特征被卷积模块(convolution,conv)处理,生成第一特征图。与focus相连的conv主要用于将多通道特征(即,下采样特征)转变为能够进行卷积运算的特征图。
45.focus以及与focus相连的conv可以称为预处理模块,其他能够将输入图像转变为能够进行卷积运算的特征图的模块均适用于本技术。
46.随后,第一特征图被至少一个语义提取模块处理,多个语义提取模块能够提高特征提取结果的信息量。在图2中,主干网设置了4个语义提取模块,即,4个c3模块,c3模块指的是包含3个卷积的csp瓶颈网络层(csp bottleneck with 3convolutions)。本技术对语义提取模块的数量和类型均不做限定。
47.第一语义提取模块(主干网中与conv相连的c3)处理conv输出的特征图(第一特征图)后,生成第二特征图;第二特征图被送入第一可变形卷积模块(deformable convolution,def-conv),生成第三特征图。
48.图3是def-conv处理特征图的示意图。
49.输入特征图进入def-conv后,经过可变形卷积处理,得到输出特征图。
50.输入特征图进入def-conv后,实际经历了两路卷积网络的处理,一路卷积网络(图3示出的conv)使用多个滑窗(如输出特征图上的多个方框)在特征图上采样,并学习采样点的变化,输出尺寸为h*w*2n的偏移量(offsets),其中,h表示高度,w表示宽度,2n表示两个方向(x方向和y方向)。图3中的偏移域(offset field)为offsets的可视化表示形式。
51.得到offsets之后,另一路卷积网络(图3未示出)利用根据offsets在输入特征图上采样(即,图3中的可变形卷积处理),输出包含采样结果的特征图(图3中包含方框的输出特征图)。
52.经过偏移量叠加的卷积核如图4所示,其中,图4中的(a)部分为普通3
×
3卷积核的采样点;图4中的(b)、(c)、(d)部分为普通3
×
3卷积核叠加不同的偏移量之后的采样点,即,可变形卷积核的采样点。
53.传统的特征提取网络使用的是普通卷积核来提取图像特征,普通卷积核在图像上提取的特征区域都是固定的规则区域。由于药材的天然属性,药材图像中的药材形状通常是不规则的,若使用传统的特征提取网络处理药材图像,提取的特征会包含较多的空白特征,一方面会导致药材识别效率下降,另一方面会导致药材识别准确率下降。
54.可变形卷积核包含一个初始的随机偏移量,随着训练迭代,该随机偏移量会变得符合数据分布,使得可变形卷积核的采样区域更加符合药材的形状。
55.图5是使用可变形卷积核在特征图上进行采样后得到的结果,可以看出,采样点(圆点)基本都位于药材图像上,因此,使用包含可变形卷积模块的特征提取网络处理药材图像的特征图,减少了空白特征的数量,提高了药材的识别效率和识别准确率。
56.此外,药材图像没有旋转不变性,引入方向参数(即,偏移量)能够带来更多的信息,从而提高药材的识别准确率。
57.第三特征图被后续的c3和def-conv处理后,到达空间金字塔池化模块(spatial pyramid pooling,spp),spp的作用是解决输入图片的大小不一在全连接层产生的问题,此外,spp在处理特征图时进行了多角度的特征提取,能够提高药材识别网络的识别准确率。
58.经过spp处理后的特征图被输入协调注意力模块(coordinate attention,coordatt)。coordatt是一种能够处理拥挤多目标的注意力模块,其结构如图6所示。
59.输入特征图经过残差(residual)层处理后,输出的结果分别作为x平均池化(x avg pool)层、y平均池化(y avg pool)层和重置权重(re-weight)层的输入数据。residual层的尺寸为c
×h×
w,x avg pool层的尺寸为c
×h×
1,y avg pool层的尺寸为c
×1×
w,re-weight层的尺寸为c
×h×
w,其中,c表示通道,h表示高度,w表示宽度。
60.x avg pool层和y avg pool层的输出结果经过拼接(concat)和二维卷积(conv2d)处理后,输出至下一层。concat和conv2d的尺寸为c/r
×1×
(w h),其中,r表示缩小率(reduction ratio),是控制块大小的值。
61.随后,批归一化(batch normalization,bn)层对conv2d的输出结果进行归一化处理,非线性(non-linear)层对bn层的输出结果进行分解(split)操作,使用尺寸为(h,1)或者(1,w)的池化核(pooling kernel)分别沿着水平坐标和垂直坐标对每个通道进行编码。bn层和non-linear层的尺寸为c/r
×1×
(w h)。
62.non-linear层输出的结果分别进入两个conv2d层,这两个conv2d层的尺寸分别为c
×h×
1和c
×1×
w。随后,两个conv2d层输出的结果分别经过对应的映射函数(sigmoid)处理后输入re-weight层,re-weight层对residual层输出的结果和两个映射函数输出的结果进行处理后输入处理结果。
63.在图6所示的处理过程中,在进行2d全局池化时会造成位置信息丢失,non-linear层将通道注意力分解为两个并行的1d特征进行编码,能够将待检测对象的坐标信息嵌入特征图中,使得特征融合网络可以更快的找到特征图中的有效特征,能够减小特征融合网络的计算开销,并且提高检测准确率。
64.回到图2,coordatt输出的特征图进入瓶颈网络层(neck)后,进行特征融合,neck即特征融合网络的一个示例。neck可以对主干网生成的多个特征图中的部分特征图进行融合(如图2中主干网与neck连接的箭头所示)。可选地,neck也可以对主干网生成的全部特征图中进行融合。主干网生成的多个特征图中,进入neck进行融合的特征图可以称为目标特征图,本技术对目标特征图的数量、类型和融合方式不做限定。
65.在特征融合网络处理特征图时,一种处理方法是通过双线性插值方法(即,上采样)处理第二卷积模块(与coordatt相连的conv)输出的特征图,然而,当药材图像存在多个药材时,这种处理方法会导致药材之间的边界发生渐变和扩散。
66.图2中的neck使用了反卷积模块(trans-conv)处理特征图,能够避免药材之间的边界发生渐变和扩散,提高药材识别的准确率。
67.neck还使用了多个双向特征金字塔网络(bi-directional feature pyramid network,bifpn)拼接模块(bifpn-concat),bifpn-concat引入了可学习的权值来学习不同输入特征的重要性,同时重复应用自顶向下和自底向上的多尺度特征融合。
68.图7示出了bifpn和路径聚合网络(path aggregation network,panet)的结构。
69.由图7可以看出,panet使用了自顶向下和自底向上的结构,然而,一些节点只有一
个输入边,这些节点对需要融合不同特征的特征融合网络来说贡献度较小,反而增加了算力消耗。
70.bifpn将这些只有一条输入边的节点去除,简化了网络结构。此外,bifpn增加了一些跳跃连接,使得同一尺度的输入节点能够将输入特征传递至更深一层的节点,使得bifpn能够融合更多的特征。由于跳跃连接连接的节点属于同一尺度层,不会增加过多的计算成本。
71.此外,相比于panet,bifpn包含了更多个融合单元(虚线框所示),能够实现更高层次的特征融合。
72.图8示出了bifpn和panet分别进行特征融合后得到的结果。其中,图8中的(a)部分为bifpn输出的结果,图8中的(b)部分为panet输出的结果,可以看出,(a)部分的特征区域(虚线框内的区域)更大,说明使用bifpn输出的特征图的特征更加丰富,这样,进入检测网络的特征图就会有更丰富的特征,有利于提高药材识别的准确率。
73.图2所示的neck是一个示意性的结构,适用于本技术的特征融合网络还可以具有其他结构,例如,包含更多的bifpn和c3,或者,包含更少的bifpn和c3。
74.neck输出的特征图进入检测网络后,检测网络对特征图进行网格划分,然后以不同尺度的特征图(如3个尺度)进行检测。
75.可选地,网格划分对应的网格尺寸与药材图像中待检测对象的尺寸负相关。即,待检测对象的尺寸越大,网格尺寸越小;待检测对象的尺寸越小,网格尺寸越大。小尺寸网格(40*40)与大尺寸网格(20*20)的示意图如图9所示。
76.当待检测对象较大时,说明拍摄药材照片时待检测对象距离镜头较近,特征融合图上待检测对象的细节特征(如表面凸起)比较清晰,检测网络可以在特征融合图上划分较小的网格,这样,检测网络可以专注于识别不同网格中的细节特征,提高识别准确率。
77.当待检测对象较小时,说明拍摄药材照片时待检测对象距离镜头较远,特征融合图上待检测对象的细节特征比较模糊,较小的网格划分意义不大,较大的网格划分反而能够使检测网络专注于宏观特征(如外观形状),从而提高了识别准确率。
78.此外,在多目标检测过程中,当待检测对象的部分区域被干扰对象遮挡时,较小的网格划分能够得到更多个没有干扰对象的网格,提高识别准确率。
79.上文详细描述了本技术提供的药材识别网络的结构和工作过程,下面,介绍本技术提供的药材识别网络的训练过程。
80.训练开始前,需要准备训练集和验证集。本技术采用一个多角度、多频中和多特征的采集平台采集图像。
81.由于同一药材会从多个角度进行旋转拍摄,导致拍摄结果出现大量的相似图像,因此,需要对拍摄结果进行清洗,可以删除相似的图像,然后平衡各种药材的图像数量。随后,对采集到的图像进行标注,生成目标检测数据集标签。
82.本技术采用图像前景提取和主成分分析算法进行标注,能够对采集到的图像进行自动化标注,提高效率。标注完成后生成的带标签的训练图像如图10所示,其中,《x_center》表示药材标签框中心点的x坐标,《y_center》表示药材标签框中心点的y坐标,《width》表示药材标签框的宽,《height》表示药材标签框的高。
83.图10所示的训练图像可以直接输入药材识别网络进行训练。可选地,还可以对训
练图像做以下处理后再输入药材识别网络进行训练。
84.将多个训练图像拼接为合成图像;对合成图像进行裁剪,生成药材图像,该药材图像包括待检测对象和至少一个干扰对象。
85.拼接和裁剪过程如图11所示。合成图像(stitched image)包括一个完整的药材和多个不完整的药材,该完整的药材即待检测对象,该多个不完整的药材即干扰对象。对合成图像进行裁剪,得到裁剪图像(cropped image),该裁剪图像即最终输入药材识别网络进行训练的药材图像。
86.进行上述拼接和裁剪的原因在于:检测网络在识别过程中会对特征融合图进行网格划分,网格划分会导致一个药材的图像被划分至不同的网格中,造成一个网格中的药材图像不完整,这会导致识别结果出现误差。
87.在本实施例中,输入药材识别网络进行训练的药材图像是多张训练图像经过拼接和裁剪后得到的结果,药材图像包含完整的待检测药材图像和不完整的干扰药材图像,从而可以提高检测网络的抗干扰能力。
88.最终得到的数据集如表1所示。
89.表1
90.药材名称标签数量(训练集/验证集)重楼1241/313西洋参1255/300钩藤1123/295炉贝916/262北柴胡994/301冬虫夏草(人工)53/14冬虫夏草(野生)230/77豆蔻1117/279黄芩(枯)1670/402黄芩(条)231/65连翘(老)2354/1659连翘(青)2191/596贝母(松贝)416/85贝母(青贝)480/119
91.训练集和验证集准备完成后,可以按照图12所示的方法进行训练。
92.训练开始后,可以将训练集和验证集分批次输入药材识别网络以提升速度。骨干网对输入的训练集和验证集进行特征提取,瓶颈网络层对骨干网输出的结果进行特征融合,检测网对瓶颈网络层输出的结果进行分格(即,划分网络)和检测。基于检测网的输出结果计算损失函数,若损失函数收敛,则可以结束训练;若损失函数不收敛,则进行下一轮迭代。
93.图12所示的方法是适用于本技术的一种可选的方法,本技术对训练药材识别网络的具体方法不做限定。
94.训练完成后,可以对训练药材识别网络的性能进行测试。
95.表2是本技术提供的药材识别网络(chm-yolo)和几种现有的目标检测网络(你只看一次(you only look once,yolo)v4、yolov5m、yolov5x、更快的包含卷积神经网络特征区域(faster region with convolutional neural network feature,faster-rcnn)和全卷积单阶段目标检测(fully convolutional one-stage object detection,fcos))的性能测试结果。
96.表2
[0097][0098]
由表2可以看出,在平均准确率(average precision,ap)50和准确率方面,chm-yolo超过了其他网络。
[0099]
上文详细介绍了本技术提供的识别药材的方法的示例。可以理解的是,相应的装置为了实现上述功能,其包含了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本技术能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0100]
本技术可以根据上述方法示例对识别药材的装置进行功能单元的划分,例如,可以将各个功能划分为各个功能单元,也可以将两个或两个以上的功能集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。需要说明的是,本技术中对单元的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
[0101]
图13是本技术提供的一种识别药材的装置的结构示意图。该装置1300包括处理单元1310、输入单元1320和输出单元1330,输入单元1320能够在处理单元1310的控制下执行输入步骤,输出单元1330能够在处理单元1310的控制下执行输出步骤。
[0102]
输入单元1320用于:获取药材图像;
[0103]
处理单元1310用于:通过特征提取网络处理所述药材图像,生成多个特征图,其中,所述特征提取网络包括至少一个可变形卷积模块,所述多个特征图的尺度不同;通过特征融合网络处理所述多个特征图中的目标特征图,生成特征融合后的特征图;通过检测网络处理所述特征融合后的特征图,生成所述药材图像的识别结果;
[0104]
输出单元1330用于:输出所述药材图像的识别结果。
[0105]
可选地,所述特征提取网络还包括预处理模块和至少一个语义提取模块,所述至少一个语义提取模块包括第一语义提取模块,所述至少一个可变形卷积模块包括第一可变形卷积模块,所述处理单元1310具体用于:通过所述预处理模块处理所述药材图像,生成第一特征图;通过所述第一语义提取模块处理所述第一特征图,生成第二特征图;通过所述第一可变形卷积模块处理所述第二特征图,生成第三特征图。
[0106]
可选地,所述预处理模块包括focus模块和第一卷卷积模块,所述处理单元1310具体用于:通过所述focus模块处理所述药材图像,生成下采样特征;通过所述第一卷积模块处理所述下采样特征,生成所述第一特征图。
[0107]
可选地,所述特征提取网络还包括协调注意力模块,所述协调注意力模块用于在所述至少一个语义提取模块中最后一个语义提取模块输出的特征图中嵌入位置信息,所述位置信息为所述药材图像中待检测对象的坐标信息。
[0108]
可选地,所述特征融合网络包括第二卷积模块和反卷积模块,所述处理单元1310具体用于:通过所述第二卷积模块处理所述协调注意力模块输出的特征图,生成第四特征图;通过所述反卷积模块处理所述第四特征图,生成第五特征图;根据所述第五特征图和所述目标特征图生成所述特征融合后的特征图。
[0109]
可选地,所述至少一个语义提取模块为跨阶段局部瓶颈网络。
[0110]
可选地,所述输入单元1320具体用于:获取多个训练图像,所述多个训练图像包括待检测对象的图像;将所述多个训练图像拼接为合成图像;对所述合成图像进行裁剪,生成所述药材图像,所述药材图像包括所述待检测对象和至少一个干扰对象。
[0111]
可选地,所述处理单元1310具体用于:通过所述检测网络对所述特征融合后的特征图进行网格划分,其中,所述网格划分对应的网格尺寸与所述药材图像中待检测对象的尺寸负相关。
[0112]
装置1300执行识别药材的方法的具体方式以及产生的有益效果可以参见方法实施例中的相关描述。
[0113]
图14示出了本技术提供的一种电子设备的结构示意图。图14中的虚线表示该单元或该模块为可选的。设备1400可用于实现上述方法实施例中描述的方法。设备1400可以是终端设备或服务器或芯片。
[0114]
设备1400包括一个或多个处理器1401,该一个或多个处理器1401可支持设备1400实现上文所述的方法实施例中的方法。处理器1401可以是通用处理器或者专用处理器。例如,处理器1401可以是中央处理器(central processing unit,cpu)。cpu可以用于对设备1400进行控制,执行软件程序,处理软件程序的数据。设备1400还可以包括通信单元1405,用以实现信号的输入(接收)和输出(发送)。
[0115]
例如,设备1400可以是芯片,通信单元1405可以是该芯片的输入和/或输出电路,或者,通信单元1405可以是该芯片的通信接口,该芯片可以作为终端设备或网络设备或其它电子设备的组成部分。
[0116]
又例如,设备1400可以是终端设备或服务器,通信单元1405可以是该终端设备或该服务器的收发器,或者,通信单元1405可以是该终端设备或该服务器的收发电路。
[0117]
设备1400中可以包括一个或多个存储器1402,其上存有程序1404,程序1404可被处理器1401运行,生成指令1403,使得处理器1401根据指令1403执行上述方法实施例中描
述的方法。可选地,存储器1402中还可以存储有数据。可选地,处理器1401还可以读取存储器1402中存储的数据,该数据可以与程序1404存储在相同的存储地址,该数据也可以与程序1404存储在不同的存储地址。
[0118]
处理器1401和存储器1402可以单独设置,也可以集成在一起,例如,集成在终端设备的系统级芯片(system on chip,soc)上。
[0119]
处理器1401执行识别药材的方法的具体方式可以参见方法实施例中的相关描述。
[0120]
应理解,上述方法实施例的各步骤可以通过处理器1401中的硬件形式的逻辑电路或者软件形式的指令完成。处理器1401可以是cpu、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field programmable gate array,fpga)或者其它可编程逻辑器件,例如,分立门、晶体管逻辑器件或分立硬件组件。
[0121]
本技术还提供了一种计算机程序产品,该计算机程序产品被处理器1401执行时实现本技术中任一方法实施例所述的方法。
[0122]
该计算机程序产品可以存储在存储器1402中,例如是程序1404,程序1404经过预处理、编译、汇编和链接等处理过程最终被转换为能够被处理器1401执行的可执行目标文件。
[0123]
本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机执行时实现本技术中任一方法实施例所述的方法。该计算机程序可以是高级语言程序,也可以是可执行目标程序。
[0124]
该计算机可读存储介质例如是存储器1402。存储器1402可以是易失性存储器或非易失性存储器,或者,存储器1402可以同时包括易失性存储器和非易失性存储器。其中,非易失性存储器可以是只读存储器(read-only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、电可擦除可编程只读存储器(electrically eprom,eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的ram可用,例如静态随机存取存储器(static ram,sram)、动态随机存取存储器(dynamic ram,dram)、同步动态随机存取存储器(synchronous dram,sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,ddr sdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synchlink dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,dr ram)。
[0125]
本领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的装置和设备的具体工作过程以及产生的技术效果,可以参考前述方法实施例中对应的过程和技术效果,在此不再赘述。
[0126]
在本技术所提供的几个实施例中,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的方法实施例的一些特征可以忽略,或不执行。以上所描述的装置实施例仅仅是示意性的,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,多个单元或组件可以结合或者可以集成到另一个系统。另外,各单元之间的耦合或各个组件之间的耦合可以是直接耦合,也可以是间接耦合,上述耦合包括电的、机械的或其它形式的连接。
[0127]
应理解,在本技术的各种实施例中,各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术的实施例的实施过程构成任何限定。
[0128]
另外,本文中术语“系统”和“网络”在本文中常被可互换使用。本文中的术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
[0129]
总之,以上所述仅为本技术技术方案的较佳实施例而已,并非用于限定本技术的保护范围。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。