1.本发明属于软件工程领域,涉及一种层次语义感知的代码表示学习方法,具体涉及一种利用程序分析和深度学习技术,将程序转化为包含代码深层语义信息的分布式向量表示的方法。
背景技术:
2.目前,在软件工程领域,深度学习技术已经被广泛应用于诸如程序分类、克隆检测、代码补全、代码摘要等各种类型的软件开发和维护任务,并且在大量的任务中取得了出色的表现,能够有效帮助开发人员减少时间和人力成本。开发有效的代码表示学习方法来捕获程序深层语义信息是使得模型能够在下游任务中取得良好性能的关键。基于深度学习的代码表示学习方法因其强大的非线性特征提取能力而受到越来越多的关注。
3.大多数基于深度学习的代码表示的研究采用类似自然语言的处理思路,直接利用token序列或抽象语法树来学习代码的语义信息,并生成代码的分布式向量表示。例如,一些研究首先将源代码进行词法分析转化为token序列,然后使用long term memory network(lstm)或者convolutional neural networks(cnn)神经网络对整个序列进行编码。除了基于词法token序列的模型,也有一些研究通过语法分析将代码转化为基于树的表示形式(如抽象语法树(ast)),并应用递归神经网络(rnn)的变体tree-lstm来学习代码的分布式向量表示。然而,无论是基于token序列还是基于语法树的代码表示学习方法,都无法有效地理解代码的深层语义信息。这是因为源代码通常包含比自然语言更丰富和更明显的结构特性(例如,函数调用、循环、语句之间的控制和数据依赖关系以及语句顺序特征等)。因此,最近研究人员提出了一些针对编程语言的深度神经网络,尝试对源代码进行更深入的语义理解。
4.常见的解决方案是使用图神经网络(gnns)对程序依赖图(pdg)或数据流程图(cfg)进行编码来学习程序的结构语义信息。然而,与其他代码表示方式(例如,ast或token序列)相比,pdg或cfg中的每个节点表示一个基本代码块(至少是一条语句的代码段),表示粒度太粗。因此,结合gnns和pdg或cfg的代码表示学习方法无法有效地捕获语句内的细粒度语义信息。
5.此外,当前基于图的代码表示学习方法更多地侧重于捕获程序的结构语义信息,而忽略了语句的顺序语义信息。由于语句的顺序指定了不同的语句在依赖路径和数据流传输路径上的交互关系,因此对于代码的理解也是至关重要。
6.目前,尚未检索到能够同时编码程序的序列和结构语义的深度学习模型。
技术实现要素:
7.本发明的目的是提供一种层次语义感知的代码表示学习方法,该方法的关键步骤包括一个能够编码程序结构语义的深度学习模型graph-lstm和一个基于dfs(深度优先搜索)的语句序列生成算法。通过按照语句的处理顺序来学习每条语句的局部和全局结构语
义信息,使得模型能够同时捕获程序的深层结构和序列语义信息。本发明首次提出适用于程序结构语义编码的基于图的lstm模型graph-lstm,并提出一种能够将源代码序列信息融入到代码表示学习过程中的新框架,提高了模型的特征表示能力。
8.本发明的目的是通过以下技术方案实现的:
9.一种层次语义感知的代码表示学习方法,针对给定的源代码,首先利用程序分析技术构建程序的有向无环语义图,然后抽取语义图中的语法子树信息,并利用tree-lstm模型学习程序中每条语句的局部语义向量表示,最后基于语句的局部语义向量表示,利用graph-lstm模型学习代码的结构和顺序语义信息,具体包括如下步骤:
10.步骤1:解析源代码中的每个方法,抽取方法中语句之间的数据和控制依赖关系,以及每条语句的语法子树,构建层次化程序复合图;
11.步骤2:利用深度遍历算法移除层次化程序复合图中的部分有向边,构造程序的有向无环语义图;
12.步骤3:从程序的语义图中提取语句的语法子树信息,利用tree-lstm深度学习模型学习程序中每条语句的局部语义向量表示;
13.步骤4:从程序的语义图中提取语句之间的顺序和依赖信息,利用graph-lstm模型学习语句的全局语义向量表示;
14.步骤5:应用最大池化技术将可变长度的语句向量序列压缩为一个单一的程序向量。
15.相比于现有技术,本发明具有如下优点:
16.1、本发明提出一种新型的代码表示形式(有向无环语义图),该图不仅可以表示语句内部的语法信息,还可以表示语句之间的数据依赖和控制依赖信息。
17.2、本发明提出一种新型的代码表示学习网络graph-lstm,该模型能够基于语句的局部语义向量表示,从全局上下文中学习语句的全局语义向量表示,能够解决以往模型中未能同时和充分利用代码的结构语义特征和语句的顺序语义信息的缺点,可以更准确地获得代码的向量表示。
18.3、本发明提出一种新的层次语义感知的代码表示方法,通过对语义图中的语句节点进行拓扑排序,并按照语句的处理顺序来学习每条语句的局部和全局结构语义信息,能够实现将语句的序列信息融入到代码的表示学习过程中,从而提高模型的特征表示能力。
附图说明
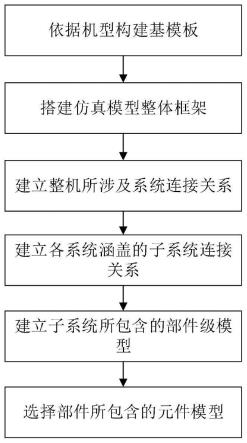
19.图1是本发明提出的层次语义感知的代码表示学习的总体流程图。
20.图2是语义图循环移除算法。
21.图3是计算最大公约数(gcd)的c代码示例。
22.图4是图3中的示例代码对应的不同代码表示形式。
23.图5是图3中的示例代码对应的层次化程序复合图的构造过程。
24.图6是由图5中的层次化程序复合图构造程序的有向无环语义图的过程。
25.图7是对图6中的程序的语义图进行拓扑排序的结果
26.图8是graph-lstm模型的结构和学习过程。
具体实施方式
27.下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
28.本发明提供了一种层次语义感知的代码表示学习方法,所述方法基于程序分析和深度学习技术,首先利用程序分析技术将程序解析为ast和pdg,并基于ast和pdg构造层次化程序复合图。然后利用深度遍历算法移除层次化程序复合图中的部分有向边,构成程序的有向无环语义图。接着,从生成的语义图中抽取语句内的语法子树信息,利用现有的tree-lstm模型学习程序中每条语句的局部语义向量表示。最后,从语义图中抽取语句之间的顺序和依赖信息,并基于语句的局部语义向量表示,利用本发明提出的graph-lstm模型学习代码的全局结构语义特征和顺序语义信息。如图1所示,具体包括如下步骤:
29.步骤1:解析源代码中的每个方法,抽取方法中语句之间的数据和控制依赖关系,以及每条语句的语法子树,构建层次化程序复合图,具体步骤如下:
30.步骤11:将源代码解析为pdg、ast,分别作为代码的结构信息和语法信息,根据ast节点和pdg节点在源代码中的位置建立对应关系;
31.步骤12:将pdg中的节点替换成ast中的语法子树,以语句的ast子树作为语句节点(可将其看成“超级节点”,“超级节点”内的ast子树代表语句内的关系),从pdg中提取语句节点之间的数据依赖、控制依赖关系,构建层次化程序复合图。
32.步骤2:利用深度遍历算法移除层次化程序复合图中的部分有向边,构造程序的有向无环语义图,算法过程如图2所示,具体步骤如下:
33.步骤21:对于程序复合图中的每个节点,将其状态标记为“待搜索”;
34.步骤22:初始化一个空集e,用于存储待删除的边;
35.步骤23:遍历程序复合图中的节点,如果节点的状态是“待搜索”,则以该节点为根节点s,执行步骤24~步骤27进行深度优先遍历,直到图中的所有节点状态都变成“已搜索”时转至步骤28;
36.步骤24:将根节点s状态标记为“正在搜索”;
37.步骤25:沿着根节点s的输出边e遍历邻接节点v;
38.步骤26:如果遍历的邻接节点v的状态是“待搜索”,则将此邻接节点作为根节点,跳转到步骤24进行递归执行;如果遍历的邻接节点的状态是“正在搜索”,则将边e加入到待删除的集合e;
39.步骤27:将根节点s状态标记为“已搜索”;
40.步骤28:此时,由标记为“已搜索”的节点和剩余的边构成的图即为程序的有向无环语义图。
41.步骤3:从程序的语义图中提取语句的语法子树信息,利用现有的tree-lstm模型学习程序中每条语句的局部语义向量表示,具体步骤如下:
42.步骤31:遍历语义图中类型为statement的语句节点;
43.步骤32:递归遍历语句节点的孩子节点,得到该语句节点对应的语法子树;
44.步骤33:使用tree-lstm模型对语法子树进行编码,得到该语句节点的局部语义向量表示。
45.步骤4:从程序的语义图中提取语句之间的顺序和依赖信息,利用本发明提出的代码表示学习模型graph-lstm学习语句的全局语义向量表示,具体步骤如下:
46.步骤41:提取语义图中语句节点之间的数据依赖和控制依赖关系;
47.步骤42:对有向无环语义图的语句节点进行拓扑排序,生成语句节点的处理顺序;
48.步骤43:按照步骤42中生成的语句顺序,对语句节点进行遍历,并在遍历的同时对语句节点执行步骤44~步骤45的操作,以更新该语句节点的向量表示;
49.步骤44:根据步骤41得到的语句节点的数据依赖和控制依赖关系,抽取当前语句节点j的直接邻居节点作为该节点的全局上下文;
50.步骤45:根据当前节点的语句类型xj和当前节点的局部语义向量表示hj以及其邻居节点的局部语义向量表示利用公式利用公式计算graph-lstm模型在该节点的隐藏状态向量表示,f是级联函数,由如下公式组成:
[0051][0052]fjl
=σ(wf·
xj uf·hjl
bf)
[0053][0054][0055][0056][0057][0058]
其中,ij,fj,oj分别代表在第j个节点的输入、忘记和输出门;uj是候选细胞状态;cj和分别代表细胞状态和输出向量;jl表示第j个节点的第l个孩子节点;σ是sigmoid函数,w和u是权重矩阵,b是偏置项,
⊙
代表向量内对应元素相乘。
[0059]
现有的tree-lstm模型根据子节点的隐藏状态来计算父节点的隐藏状态,只适用于具有简单形式的树结构数据,而本发明通过修改节点隐藏状态的计算方式对tree-lstm模型进行了改进,提出一种能够扩展到其它复杂图型结构数据的深度学习模型graph-lstm,并将该模型成功应用于捕获源代码的深层语义信息。
[0060]
步骤5:应用最大池化技术将可变长度的语句向量序列压缩为一个单一的程序向量。
[0061]
实施例1:
[0062]
以计算最大公约数(gcd)的c代码为例(如图3)分析层次化程序复合图的构造过程。
[0063]
(1)首先,将源代码解析为ast,如图4(a)所示;
[0064]
(2)然后,将源代码解析为pdg,如图4(c)所示;
[0065]
(3)最后,将pdg中的语句节点替换为ast中的语法子树,构造层次化程序复合图,具体替换过程如图5所示。
[0066]
实施例2:
[0067]
以计算最大公约数(gcd)的c代码对应的层次化程序复合图为例,利用深度遍历算法移除程序复合图中的部分有向边,构成程序的有向无环语义图。
[0068]
从程序复合图中删除循环与从pdg中删除循环是等价的,这是因为循环结构只可能出现在语句之间的数据依赖和控制依赖(即pdg)关系中,而不可能出现在语句对应的语法子树中。因此,为了简单起见,此实例使用源代码对应的pdg节点的id来表示层次化程序复合图中每个语句对应的语法子树。根据步骤2通过移除部分有向边,构造图3中c程序的有向无环语义图的过程如图6所示。例如图6(a)是以id为1的节点为根节点,首先将其状态由“待搜索(图中以白色椭圆表示)”标记为“正在搜索(灰色椭圆表示)”(步骤24),然后沿着节点1的输出边(1,5)遍历邻接节点5(步骤25),由于邻接节点5的状态是“待搜索”,则依据步骤26将该节点作为根节点跳回步骤24递归执行。此次递归探索的节点路径为“1
→5→7→4→6→
8”,在探索过程中由于邻接节点的状态是“正在搜索”而删除的边为(4,5)、(6,5)、(4,7)和(7,5)。
[0069]
实施例3:
[0070]
以计算最大公约数(gcd)的c代码对应的有向无环语义图为例,利用graph-lstm模型学习语句的全局语义向量表示。
[0071]
首先根据步骤41,抽取示例代码对应的语义图中的语句节点之间的依赖关系,然后按照步骤42对语句节点进行拓扑排序,得到的语句节点的处理顺序为“3
→2→1→5→7→4→6→
8”。结合节点的顺序信息和依赖关系得到拓扑排序后的语句节点关系示意图如图7所示。根据步骤43,依照节点拓扑顺序,处理语句节点。以节点4为例,将与语句节点4具有直接依赖关系的邻居节点(节点2和节点7)作为该节点的全局上下文,将节点4对应的语法子树作为该节点局部上下文。注意每个节点的局部上下文的表示已经在步骤2中进行了计算。根据节点局部和全局上下文更新当前节点隐藏表示的具体计算过程如图8所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。