1.本发明涉及计算机领域,具体涉及一种基于非结构化海量数据的智能分析方法。
背景技术:
2.大数据时代,网络上随时都在产生大量的文本数据,例如,邮件、网页、文档、语音等。为了对现有数据进行利用,我们需要更加全面的对收集到的庞大的数据信息进行分析处理,从中分析和挖掘出有价值的信息。现有技术中,产生的原始数据越来越多的是非结构化数据,对这些原始数据使用之前主要是通过人工进行标注清洗处理,随着信息量增加,光是靠人工处理,一方面,重复工作容易出错,另一方面,随着数据增加,人工前期进行清洗标注效率也不高,很容易出错。因此,如何利用机器算法辅助人工对这些原始数据进行高效的分析和提炼始终是本领域的需要解决的问题。
技术实现要素:
3.本发明针对现有技术的不足,提出一种基于非结构化海量数据的智能分析方法,具体技术方案如下:
4.一种基于非结构化海量数据的智能分析方法,其特征在于:
5.包括如下步骤:
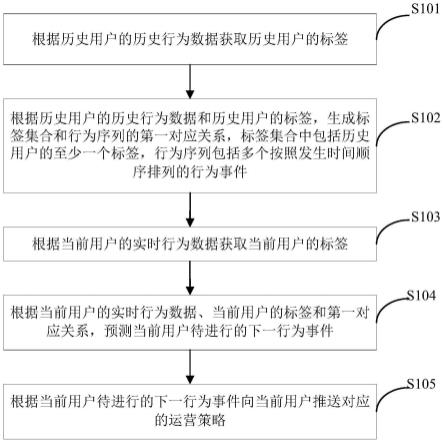
6.s1:设定任务目标,针对任务目标设定有资料库;
7.s2:数据收集器将文件收集到资料库中;
8.s3:设置有标准模板,数据转换模块将所有文件按照标准模板转换成统一的文本格式存储到数据库中;
9.s4:数据处理模块针对数据库中的文本建立初步的术语-文本矩阵,其中矩阵的行代表文本,矩阵中的列代表术语,数据处理模块将术语-文本矩阵发送到审核端;
10.s5:专家通过审核端对术语-文本矩阵进行检验,剔除掉干扰词,缩小矩阵维度,得到最终术语-文本矩阵;
11.s6:设置有聚类模型,数据处理模块调用聚类模型对文本进行聚类分析,得到初步的主题标签,数据处理模块将该主题标签发送到审核端;
12.s7:专家对主题标签进行评估,专家对主题标签进行人工评估增删后,通过审核端将该分类标签保存到数据库中;
13.s8:数据处理模块用标注有分类标签的文本集作为训练数据,训练得到分类模型;
14.s9:数据处理模块调用训练好的分类模型对文本进行分类,将文本划分到对应的标签下面,得到分类文件集合;
15.s10:针对同一分类文件集合,数据处理模块选取不同时间节点的文件集,得到多组文件集合;
16.s11:数据处理模块对每组文件集合中的文件内容作概念关联分析;
17.s12:数据处理模块按照时间节点将同一分类下的关键概念组整理成报告发送到
审核端;
18.s13:审核端将报告呈现可视化展示,方便观察到同一分类下关键概念及其发展趋势。
19.2、根据权利要求1所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述聚类模型采用k均值聚类算法。
20.3、根据权利要求1所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述数据收集器为网络爬虫。
21.4、根据权利要求1所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述收集资料包括文本档案、xml文件、邮件、网页、语音。
22.5、根据权利要求1所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述语音通过语音识别模型转换成文字脚本输入到资料库中。
23.本发明的有益效果为:本发明设置有标准模板,能够将非结构化文本转换为结构化的模板,设置有聚类模型对文本进行聚类分析得到文本的主题类型标签,专家对机器聚类生成的类型作人工辅助调整,接着设置的分类模型对文本按照调整好的类型进行分类,在同一分类下分别按照时间节点做关联分析,有效的发现概念随着时间线的演化。
附图说明
24.图1为本发明的工作流程图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.如图1所示:
27.一种基于非结构化海量数据的智能分析方法,
28.包括如下步骤:
29.s1:设定任务目标,针对任务目标设定有资料库;
30.s2:数据收集器将文件收集到资料库中,其中,在本实施例中,所述收集资料包括文本档案、xml文件、邮件、网页、语音。
31.s3:设置有标准模板,数据转换模块将所有文件按照标准模板转换成统一的文本格式存储到数据库中;
32.s4:数据处理模块针对数据库中的文本建立初步的术语-文本矩阵,其中矩阵的行代表文本,矩阵中的列代表术语,数据处理模块将术语-文本矩阵发送到审核端;
33.s5:专家通过审核端对术语-文本矩阵进行检验,剔除掉干扰词,缩小矩阵维度,得到最终术语-文本矩阵;
34.s6:设置有聚类模型,其中,在本实施例中,聚类模型采用k均值聚类算法。
35.数据处理模块调用聚类模型对文本进行聚类分析,得到初步的主题标签,数据处理模块将该主题标签发送到审核端;
36.s7:专家对主题标签进行评估,专家对主题标签进行人工评估增删后,通过审核端将该分类标签保存到数据库中;
37.s8:数据处理模块用标注有分类标签的文本集作为训练数据,训练得到分类模型;
38.s9:数据处理模块调用训练好的分类模型对文本进行分类,将文本划分到对应的标签下面,得到分类文件集合;
39.s10:针对同一分类文件集合,数据处理模块选取不同时间节点的文件集,得到多组文件集合;
40.s11:数据处理模块对每组文件集合中的文件内容作概念关联分析;
41.s12:数据处理模块按照时间节点将同一分类下的关键概念组整理成报告发送到审核端;
42.s13:审核端将报告呈现可视化展示,方便观察到同一分类下关键概念及其发展趋势。
43.本实施例也可以对语音进行分析,语音通过语音识别模型转换成文字脚本输入到资料库中。
44.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
45.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
技术特征:
1.一种基于非结构化海量数据的智能分析方法,其特征在于:包括如下步骤:s1:设定任务目标,针对任务目标设定有资料库;s2:数据收集器将文件收集到资料库中;s3:设置有标准模板,数据转换模块将所有文件按照标准模板转换成统一的文本格式存储到数据库中;s4:数据处理模块针对数据库中的文本建立初步的术语-文本矩阵,其中矩阵的行代表文本,矩阵中的列代表术语,数据处理模块将术语-文本矩阵发送到审核端;s5:专家通过审核端对术语-文本矩阵进行检验,剔除掉干扰词,缩小矩阵维度,得到最终术语-文本矩阵;s6:设置有聚类模型,数据处理模块调用聚类模型对文本进行聚类分析,得到初步的主题标签,数据处理模块将该主题标签发送到审核端;s7:专家对主题标签进行评估,专家对主题标签进行人工评估增删后,通过审核端将该分类标签保存到数据库中;s8:数据处理模块用标注有分类标签的文本集作为训练数据,训练得到分类模型;s9:数据处理模块调用训练好的分类模型对文本进行分类,将文本划分到对应的标签下面,得到分类文件集合;s10:针对同一分类文件集合,数据处理模块选取不同时间节点的文件集,得到多组文件集合;s11:数据处理模块对每组文件集合中的文件内容作概念关联分析;s12:数据处理模块按照时间节点将同一分类下的关键概念组整理成报告发送到审核端;s13:审核端将报告呈现可视化展示,方便观察到同一分类下关键概念及其发展趋势。2.根据权利要求1所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述聚类模型采用k均值聚类算法。3.根据权利要求2所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述数据收集器为网络爬虫。4.根据权利要求3所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述收集资料包括文本档案、xml文件、邮件、网页、语音。5.根据权利要求4所述一种基于非结构化海量数据的智能分析方法,其特征在于:所述语音通过语音识别模型转换成文字脚本输入到资料库中。
技术总结
一种基于非结构化海量数据的智能分析方法,通过设定任务目标,针对任务目标设定有资料库。数据收集器将文件收集到资料库中。设置有标准模板,数据转换模块将所有文件按照标准模板转换成统一的文本格式存储到数据库中;设置有聚类模型对文本进行聚类分析得到文本的主题类型标签,专家对机器聚类生成的类型作人工辅助调整,接着设置的分类模型对文本按照调整好的类型进行分类,在同一分类下分别按照时间节点做关联分析,有效的发现概念随着时间线的演化。的演化。的演化。
技术研发人员:张昌福 杨文峰 李琳 文杰 杨廷玮泞 袁江远
受保护的技术使用者:贵州航天云网科技有限公司
技术研发日:2022.05.18
技术公布日:2022/7/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。