1.本发明属于计算机科学和人体行为识别技术领域,具体涉及一种融合拓展决策和注意力网络的行为动态识别方法。
背景技术:
2.随着智能手机、手表、手环等可穿戴计算的智能感知设备逐渐成为人们生活中的必需品,用户日常的行为数据日益变成一种宝贵的资源。将智能感知设备采集到的行为数据进行恰当地利用可以极大地促进智能生活的发展。对于个人使用者来说,可穿戴的智能感知设备可以使用户清晰地分析并总结日常所完成的事情,从而提升工作效率;对于企业、科研单位而言,这些机构可以利用大量的行为数据为他们所开展的项目提供帮助,辅助进行工作方向的决策与工作内容的实施;对于政府来说,通过对于大量有效数据的分析可以得到一些宏观层面的调研报告,以便于政策的指定与推广。
3.现有的可穿戴设备通常内置丰富的智能感知模块,如加速度、角加速度、重力加速度、陀螺仪、温度、心跳、脉搏等传感器,此类传感器具有便携性高、能耗低、数据采集能力稳定的特点。因此,利用此类便携的智能感知装置进行用户行为测量与数据采集,可以减少对使用者的干扰,适合于长期使用与检测。此外,针对实际场景的应用,智能感知设备还可以进行自适应调整,将数据资料上载至服务端平台进行分析,也可以通过设备内置硬件进行移动端本地处理,综合保证人体行为识别的性能与效果。通过对于上述传感器数据的智能感知,可以有效保障孩子、老人、工人等用户在各种场景下中的安全,也可以便于各种运动分析领域中对用户的行为数据采集和分析。综上所示,基于在智能感知设备上使用行为动态识别模型进行人体行为识别的方法有着广泛的应用场景。
4.尽管目前已对人体识别领域进行了很多的研究和应用,但如何进一步提升对用户相似行为识别的精确率,以及在现实场景各种因素限制下保持较好的识别与交互反馈性能,仍然需要进一步地探索与研究。受限于移动设备的计算能力、能源消耗与网络情况等因素,为了可以较为实时地对人体行为数据进行识别和交互反馈,能够针对不同应用场景进行自适应调整,兼顾性能以及交互反馈效果的人体行为识别模型成为了一个研究热点。
技术实现要素:
5.本发明的第一个目的在于为了克服现有的人体行为识别方法存在的缺陷,提供一种融合拓展决策和注意力网络的行为动态识别方法multiatt-xgb(multi-channel human signal deep fusion attention network-xgboost),由multiatt多通道深度融合注意网络方法、人体感知识别任务动态调度方法以及xgboost拓展决策网络方法组成,实时地对人体行为数据进行感知识别交互反馈,针对不同应用场景进行自适应调整,设计兼顾性能以及效果的人体行为识别框架。
6.为了实现上述目的,本发明融合拓展决策和注意力网络的动态感知识别方法multiatt-xgb。本方法在服务器端执行multiatt深度融合注意网络,与本地设备端的
xgboost拓展决策网络通过人体识别任务动态调度算法进行结合,以实现在不同场景下自适应动态感知人体行为。
7.针对交互反馈实时性低的问题,本发明提出的multiatt深度融合注意网络可以获取通道间依赖关系来综合性分析多通道人体行为数据,同时反馈的贡献分值向量可以为xgboost的输入通道数据进行阈值筛选,提高后者的计算效率。xgboost拓展决策网络对比其他同类型模型的分类器在保持较低计算复杂度的同时有着较高分类精确率,也更适合于在本地设备端上对传感器数据进行行为识别与人机交互。
8.针对不同场景适应性低的问题,本发明提出感知识别任务动态调度算法保障了不同场景下的任务可以根据设备情况动态地调度在服务器端或者本地设备端通过合适地算法模式进行行为识别,综合提升了智能设备移动场景下的人体行为感知、识别和交互能力。
9.针对行为识别准确率低的问题,本发明提出的行为动态识别模型使用两种精度高、鲁棒性强、效率快的人体行为识别算法multiatt和xgboost,克服现有的人体行为识别中存在的缺陷。同时本发明提出一种动作片段分解方法,以对采集数据进行更准确的动作切分,从而提升后续模型的识别性能。
10.为了解决现有技术的问题,本发明的技术方案如下:
11.一种融合拓展决策和注意力网络的行为动态识别方法,其特征在于包括以下步骤:
12.步骤(1):通过传感器采集数据,删除无用数据和噪声数据进行数据清洗,然后进行数据分解:
13.步骤(1.1):对采集完毕的传感器数据进行整理和定义;
14.令p={p1,p2,
…
pm}为传感器所采集到的数据,m代表片段数;令表示第i个数据片段收集到的传感器数据集,其中代表第pi个片段上的时间序列,代表第pi个片段上发生的事件总数,代表第pi个片段各时间序列对应的传感器数据,
15.令代表传感器上的一个事件,其中而一个人体行为活动序列b是m个事件的序列,b={a1,a2,
…
,am};
16.令d={d1,d2,
…
,dn}代表一个独立的传感器的数据集合,其中n表示人体放置的不同传感器的数量,因此即在任意的pi个片段中产生的传感器序列数据都是在d集合中定义的;
17.步骤(1.2):对时序信息进行格式转换;
18.将时序信息转换为时间戳的方式进行格式转换,计算公式如下:
19.p.tim[i]={p.d,p.d[i].hour
×
60
×
60 p.d[i].minute
×
60 p.d[i].second}
[0020]
其中i∈(0,z],z表示最大数据条数,p.d表示日期时间戳,p.d[i]的各类型后缀对应时、分、秒的数据,p.tim[i]返回转换得到的总时间戳;
[0021]
步骤(1.3):定义动作集和综合差;
[0022]
定义动作集s1,是由各个时间片段的人体行为活动序列组成的,其公式如下所示:
[0023][0024]
其中表示在动作集s1中第β1个人体行为活动序列,表示在人体行为活动序列b1中第m1个事件;
[0025]
定义综合差,将由传感器产生的数据划分为两个部分,包括时序差和均值差;总的差值衡量标准为两者的综合,综合差越小,两个时间段是同一种行为的可能性越大,公式如下:
[0026][0027]
其中为第i个时间段与第j个时间段之间的综合差;是第i个时间段和第j个时间段之间的时间差,表示第i个时间段与第j个时间段之间各类别变换大于一定阈值数据的均值差加权和,为第i个时间段和第j个时间段传感器出现一定阈值变换的数据的类别总数;
[0028]
步骤(1.4):进行动作分解;
[0029]
将简化得:
[0030][0031]
其中pi代表第i个时间段,pj代表第j个时间段;代表通过设定阈值筛选出的出现一定变化的数据项总数;是和之间的时间差,表示与之间各类别变换大于一定阈值数据的均值差加权和;利用公式将一定时间段的人体行为数据进行分析处理,整合出n段行为动作,即s={s1,s2,...,sn};
[0032]
当传感器采集到新的数据pj时,将其与历史数据s进行对比:遍历历史数据s中所有行为模式时间片段,寻找最小值对应的时间片段,认为该时间片段对应的行为模式为pj的行为模式,从而完成人体行为动作切分;
[0033][0034]
步骤(2):对上述预处理后得到的数据判断是否初次输入;若是,则执行步骤3,若否,执行步骤4;
[0035]
步骤(3):远端服务器接收到本地设备传输的数据,利用multiatt深度融合注意网络进行人体行为识别,然后将识别数据发送给分类器进行行为分类;所述multiatt深度融
合注意网络是在基础的卷积神经网络上加入了多视图卷积编码器和融合注意门得到;
[0036]
步骤(4):本地设备将上述预处理后的数据通过人体感知识别任务动态调度方法来进行动态任务调度;
[0037]
步骤(5):利用multiatt深度融合注意网络反馈的贡献分值向量为xgboost拓展决策网络的输入通道数据进行阈值筛选,并对调度到本地设备的数据使用xgboost拓展决策树算法进行行为识别。
[0038]
进一步地,步骤(3)所述multiatt深度融合注意网络具体如下:
[0039]
步骤(3.1):通过多视图卷积编码器计算视图参数;
[0040]
利用两个卷积特征编码器,即通道编码器和全局编码器,分别从特定通道和全局视图中提取抽象特征的方法;
[0041]
假定输入的人体信号片段由n个通道组成,表示为x={x1,x2,...,xn};给定第i个通道的输入向量xi,通道视图yi通过encoderj通道编码器得到,如下所示:
[0042]
yi=encoderj(xi,βj)
[0043]
其中βj是encoderj中的学习参数;
[0044]
全局视图yk通过全局编码器计算得到,如下所示:
[0045]
yk=encoderk(xi,βk)
[0046]
其中βk是encoderk中的学习参数;
[0047]
步骤(3.2):利用特征编码器获得对应特征图;
[0048]
通过堆叠多个多核的cnn单元来构建多视图卷积编码器,其中包括卷积层、非线性层和池化层;具体来说,关于两种特征编码器的第m个特征图可以用和表示,计算公式如下:
[0049][0050][0051]
其中和分别是和对应的权值和偏置值,n表示所有的通道数量;
[0052]
步骤(3.3):通过融合注意力机制记录通道信息;
[0053]
融合注意门ri通过全局视图和通道视图的结果计算出通道信息,公式定义为:
[0054][0055]
其中表示yi和yk对应学习权值的转置,ε
rj
是偏置值;
[0056]
步骤(3.4):通过融合注意门得到注意力能量值;
[0057]
根据融合注意门ri整合全局视图和其自身的通道视图表示的信息,定义为:
[0058][0059]
其中
⊙
是元素相乘运算符;
[0060]
如果ri=1,那么意味着只有通道视图信息被传递;如果ri=0,那么意味着只有全局视图信息被传递;
[0061]
第i个通道的注意力能量值e
g,i
根据综合特征向量进行进一步分配:
[0062][0063]
其中和εe是对应的权值和偏置值;
[0064]
步骤(3.5):使用softmax计算贡献分值向量与上下文向量;
[0065]
基于所有的注意力能量值,贡献分值向量scoreg的归一化操作通过softmax函数实现:
[0066]
scoreg=softmax([e
g,1
,
…
,e
g,i
,
…
,e
g,n
])
[0067]
通过上述公式可以看出,如果第i个通道的贡献分值scoreg很大,则该通道的信息与相应的任务标签的相关度高;然后使用加权聚合法,根据综合特征1≤i≤n和贡献分值向量scoreg计算出上下文向量contextg,计算公式如下:
[0068][0069]
步骤(3.6):进行网络模型训练;
[0070]
为了以端到端方式训练multiatt深度融合注意网络以进行人体行为分类,网络模型将上下文向量contextg和全局视图向量yg结合起来,得出注意力特征y
attention
,定义为:
[0071][0072]
其中是连接运算符,wy和εy是y
attention
对应的权值和偏置值;之后应用softmax层来生成分类任务计算公式如下:
[0073][0074]
其中ws和εs代表对应的权值和偏置值;
[0075]
进一步地,对于给定的m个学习样本multiatt深度融合注意网络的代价函数在可学习参数集δ={(wq,εq)|q=j,k,rj,e,y,s}中的定义为:
[0076][0077]
其中wq,εq分别表示所有学习参数;
[0078]
进一步地,步骤(4)具体是:
[0079]
步骤(4.1):定义调度方法相关参数;
[0080]
将步骤(1)预处理后的数据以计算任务的形式表示,其中i代表任务的编号,是对应任务输入的预处理后的传感器数据,是对应任务完成所需要的计算量;
[0081]
步骤(4.2):建立时间感知模型;
[0082]
首先,建立预计任务执行时间的计算模型,包括任务请求到达时的本地执行时间和任务在服务器上的执行时间
[0083]
任务请求到达时的本地执行时间:
[0084][0085]
其中f
local
代表传感器设备的计算频率;
[0086]
任务在服务器上的执行时间:
[0087][0088]
其中f
server
代表服务器设备的计算频率;
[0089]
然后,建立预计任务传输时间的传输模型,包括传输节点的信噪比f
snr
(d
i,n
);
[0090]
本地设备可以将计算需求转移到服务器上,以减少本地计算负载,在计算卸载的过程中需要考虑移动环境下的网络传输问题;在本地设备卸载任务的过程中,传输节点的信噪比如下所示:
[0091][0092]
其中代表设备i在传输时的电压频率,代表设备i与当前边缘服务器之间的距离造成的信号干扰,α代表路径损失系数,βc代表卸载策略;如果βc=0,任务在本地执行;如果βc≠0,任务被卸载到远端服务器上;
[0093]
步骤(4.3):定义任务的传输时间;
[0094]
在移动网络环境下,本地设备和服务器之间的传输速率定义如下:
[0095]rn
=blog2(1 f
snr
(d
i,n
))
[0096]
其中b代表用户设备和服务器之间的传输带宽;
[0097]
任务的传输时间为:
[0098][0099]
步骤(4.4):定义响应时间;
[0100]
响应时间包含任务上传至上行链路的上传时间远端服务器中应用的执行时间和反馈给用户结果的下行链路的发送时间
[0101][0102]
步骤(4.5):建立能耗感知模型;
[0103]
本地设备的能耗主要包括两部分,一部分是本地执行的能耗,另一部分是任务卸载的能耗,包括上传能耗和下载能耗;在计算设备的能量消耗时,应首先考虑本地运行任务的能量消耗;如果用户没有可用的服务器,或者任务不需要被卸载到服务器上,则允许在本
地执行的任务;由本地本身产生的能耗被称为本地能耗,本地能耗的计算公式如下:
[0104][0105]
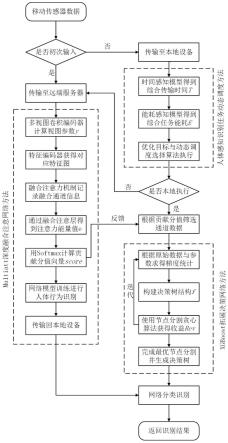
其中代表本地计算任务所需的时间,p
local
代表计算任务的电压频率;
[0106]
在任务调度过程中,由数据传输而产生的能量消耗被称为传输能耗传输能耗可分为任务传输能耗和结果下载能耗,其计算公式如下:
[0107][0108]
其中代表任务传输的上传或下载时间,p
trans
代表任务传输的上传或下载电压,state=up表示任务上传状态,state=down表示任务下载状态;
[0109]
步骤(4.6):制定优化目标并完成模型决策;
[0110]
以最小化能耗与响应时间为优化目标,目标函数表示为:
[0111][0112][0113][0114][0115]
其中e为设备能耗,λ为权重因子,表示传输总时间;
[0116]
选择在目标函数最小的设备端进行任务执行,若为本地执行,则跳转至步骤(5);若为远端服务器执行,则返回至步骤(3)。
[0117]
本发明的第二个目的是提供融合拓展决策和注意力网络的行为动态识别系统,其特征在于包括:
[0118]
数据采集及数据分解模块,通过传感器采集数据,删除无用数据和噪声数据进行数据清洗,然后进行数据分解;
[0119]
数据分配模块,对数据采集及数据分解模块预处理后得到的数据判断是否初次输入;若是则输入至远端服务器,若否则输入至动态任务调度模块;
[0120]
multiatt深度融合注意网络,接收远端服务器的数据进行人体行为识别,然后将识别数据发送给分类器进行行为分类;
[0121]
动态任务调度模块,对数据采集及数据分解模块预处理后得到的数据通过人体感知识别任务动态调度方法进行动态任务调度;
[0122]
xgboost拓展决策网络,利用multiatt深度融合注意网络反馈的贡献分值向量为xgboost拓展决策网络的输入通道数据进行阈值筛选,并对调度到本地设备的数据使用xgboost拓展决策树算法进行行为识别。
[0123]
本发明的第三个目的是提供一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实上述述的方法。
[0124]
本发明的第四个目的是提供一种机器可读存储介质,其特征在于,该机器可读存储介质存储有机器可执行指令,该机器可执行指令在被处理器调用和执行时,机器可执行指令促使处理器实现上述的方法。
[0125]
与现有技术相比,本发明方法具有以下优点:
[0126]
1.高适应性:本发明通过人体感知识别任务动态调度方法设计分析移动设备计算能力、能源消耗以及网络情况,保障了不同场景下的任务可以根据设备情况动态地调度在服务器端或者移动设备端通过合适的算法模式进行行为识别,综合提升了智能设备移动场景下的人体行为感知、识别和交互能力。
[0127]
2.高精确性:multiatt深度融合注意网络使用的算法能够区分不同通道中信号与任务相关的重要性,并依靠信息关联度更大的通道来增强特征表示,以减轻在原始特征空间中不相关和冗余原始特征的影响。同时该算法从多通道人体行为中提取关键信息来综合提升人体行为识别效果,避免关键通道被确定为训练模型的输入时其余的通道被一次性剔除导致忽略了不同情况下通道之间与任务相关的详细信息的情况。并且网络设计融合注意门机制提升了网络对于易混淆动作的识别能力,从而综合提升人体行为识别准确性。
[0128]
3.高有效性:multiatt深度融合注意网络反馈的贡献分值向量可以为拓展决策方法xgboost算法的输入通道数据进行阈值筛选,提高后者的计算效率。人体感知识别任务动态调度算法将会把更适合在移动设备端进行的任务调度给计算量需求较小的拓展决策网络来执行,从而提升模型的有效性。
附图说明
[0129]
图1为基于multiatt-xgb的动态感知识别模型流程图;
[0130]
图2为multiatt深度融合注意网络对多通道人体行为信号进行识别的网络模型;
[0131]
图3为人体感知识别任务动态调度方法执行流程图;
[0132]
图4为uci-har数据集中多种方法精确率对比图;
[0133]
图5为phad数据集中多种方法精确率对比图;
[0134]
图6为不同数据集中xgboost和各算法准确率对比图;
[0135]
图7为不同受试者个数算法准确率对比图;
[0136]
图8为uci-har数据集混淆矩阵图;
[0137]
图9为phad数据集混淆矩阵图;
具体实施方式
[0138]
下面结合说明书附图,对本发明的实施步骤进行进一步说明,但本发明并不局限于以下实施例。
[0139]
步骤(1):通过传感器采集数据,删除无用数据和噪声数据进行数据清洗,然后进行数据分解:
[0140]
步骤(1.1):对采集完毕的传感器数据进行整理和定义;
[0141]
令p={p1,p2,
…
pm}为传感器所采集到的数据,m代表片段数。令表示第i个数据片段收集到的传感器数据集,其中代表第pi个片段上的
时间序列,代表第pi个片段上发生的事件总数,代表第pi个片段各时间序列对应的传感器数据,
[0142]
令代表传感器上的一个事件,其中而一个人体行为活动序列b是m个事件的序列,b={a1,a2,
…
,am}。
[0143]
令d={d1,d2,
…
,dn}代表一个独立的传感器的数据集合,其中n表示人体放置的不同传感器的数量,因此即在任意的pi个片段中产生的传感器序列数据都是在d集合中定义的。
[0144]
步骤(1.2):对时序信息进行格式转换;
[0145]
将时序信息转换为时间戳的方式进行格式转换,计算公式如下:
[0146]
p.tim[i]={p.d,p.d[i].hour
×
60
×
60 p.d[i].minute
×
60 p.d[i].second}
[0147]
其中i∈(0,z],z表示最大数据条数,p.d表示日期时间戳,p.d[i]的各类型后缀对应时、分、秒的数据,p.tim[i]返回转换得到的总时间戳。
[0148]
步骤(1.3):定义动作集和综合差;
[0149]
定义动作集s1,是由各个时间片段的人体行为活动序列组成的,其公式如下所示:
[0150][0151]
表示在动作集s1中第β1个人体行为活动序列,表示在人体行为活动序列b1中第m1个事件。
[0152]
定义综合差,将由传感器产生的数据划分为两个部分,包括时序差和均值差。总的差值衡量标准为两者的综合,综合差越小,两个时间段是同一种行为的可能性越大,公式如下:
[0153][0154]
其中为第i个时间段与第j个时间段之间的综合差。是第i个时间段和第j个时间段之间的时间差,表示第i个时间段与第j个时间段之间各类别变换大于一定阈值数据的均值差加权和,为第i个时间段和第j个时间段传感器出现一定阈值变换的数据的类别总数。
[0155]
步骤(1.4):进行动作分解;
[0156]
将简化得:
[0157]
[0158]
其中pi代表第i个时间段,pj代表第j个时间段。代表通过设定阈值筛选出的出现一定变化的数据项总数。是和之间的时间差,表示与之间各类别变换大于一定阈值数据的均值差加权和。利用公式将一定时间段的人体行为数据进行分析处理,整合出n段行为动作,即s={s1,s2,...,sn}。
[0159]
当传感器采集到新的数据pj时,将其与历史数据s进行对比:遍历历史数据s中所有行为模式时间片段,寻找最小值对应的时间片段,认为该时间片段对应的行为模式为pj的行为模式,从而完成人体行为动作切分;
[0160][0161]
步骤(2):对上述预处理后得到的数据判断是否初次输入。若是,则执行步骤3,若否,执行步骤4。
[0162]
步骤(3):远端服务器接收到本地设备传输的数据,利用multiatt深度融合注意网络进行人体行为识别,然后将识别数据发送给分类器进行行为分类;所述multiatt深度融合注意网络是在基础的卷积神经网络上加入了多视图卷积编码器和融合注意门得到;具体如下:
[0163]
参考图2为multiatt深度融合注意网络对多通道人体行为信号进行识别的网络模型,包含以下步骤:
[0164]
步骤(3.1):通过多视图卷积编码器计算视图参数;
[0165]
利用两个卷积特征编码器(即通道编码器和全局编码器),分别从特定通道和全局视图中提取抽象特征的方法。
[0166]
假定输入的人体信号片段由n个通道组成,表示为x={x1,x2,...,xn}。给定第i个通道的输入向量xi,通道视图yi可以通过encoderj通道编码器得到,如下所示:
[0167]
yi=encoderj(xi,βj)
[0168]
其中βj是encoderj中的学习参数,同样的也可以通过全局编码器计算出一个全局视图表示yk,如下所示:
[0169]
yk=encoderk(xi,βk)
[0170]
其中βk是encoderk中的学习参数,一般来说,encoderj和encoderk都可以通过为特征提取而设计的不同深度学习方法进行参数化。
[0171]
步骤(3.2):利用特征编码器获得对应特征图;
[0172]
在这个模型中,通过堆叠多个多核的cnn单元来构建多视图卷积编码器,其中包括卷积层、非线性层和池化层。具体来说,关于两种特征编码器的第m个特征图可以用和表示,计算公式如下:
[0173]
[0174][0175]
其中和分别是和对应的权值和偏置值,n表示所有的通道数量,将所有通过不同内核提取的特征进行扁平化处理,得出了通道视图和全局视图,和的维度取决于多视图卷积编码器的结构配置。多视图卷积编码器能够做到对每个人体行为数据通道的独特特征进行整体性保留,从而提升编码性能。
[0176]
步骤(3.3):通过融合注意力机制记录融合通道信息;
[0177]
为了对每个通道人体行为数据的重要性进行动态限定,本发明设计了融合注意力机制,该机制为最终的工作中加入了一个门控功能。具体来说,融合门ri可以通过全局视图和通道视图的结果计算出来,公式定义为:
[0178][0179]
其中表示对应学习参数的转置,ε
rj
是偏置值,在公式中采用sigmod参数σ将ri重新划分在[0,1]的范围来控制通过神经网络的多视图信息流。
[0180]
步骤(3.4):通过融合注意层得到注意力能量值;
[0181]
本发明根据融合门ri整合全局视图和其自身的通道视图表示的信息,定义为:
[0182][0183]
其中
⊙
是元素相乘运算符,融合门ri能够获取每个编码器携带的信息在端对端训练中需要保留或遗忘的比例。如果ri=1,那么意味着只有通道视图信息被传递。如果ri=0,那么意味着只有全局视图信息被传递。本方法使用门控单元得出一个更具代表性的综合特征向量作为注意力能量值分配函数的输入。第i个通道的注意力能量值e
g,i
可以根据综合特征向量进行进一步分配:
[0184][0185]
其中和εe是对应的学习参数。
[0186]
步骤(3.5):使用softmax计算贡献分值向量与上下文向量;
[0187]
基于所有的注意力能量值,贡献分值向量scoreg的归一化操作通过softmax函数实现:
[0188]
scoreg=softmax([e
g,1
,
…
,e
g,i
,
…
,e
g,n
])
[0189]
通过分值公式可以看出,如果第i个通道的贡献分值scoreg很大,则该通道的信息与相应的任务标签的相关度高。然后,本发明使用加权聚合法,根据综合特征(1≤i≤n)和贡献分值向量scoreg计算出一个上下文向量contextg,计算公式如下:
[0190][0191]
通过这种方式,本发明提出的模型能够有效地纳入两个特征视图所携带的多视图
信息,从而更好地融合并提取出多通道人体行为信号的代表性特征,提升后续网络模型训练的效果。
[0192]
步骤(3.6):进行网络模型训练;
[0193]
为了以端到端方式训练本发明提出的multiatt模型以进行人体行为分类,网络模型将上下文向量和全局视图向量结合起来,得出注意力特征y
attention
,定义为:
[0194][0195]
其中是连接运算符,wy和εy是y
attention
对应的学习参数。之后应用softmax层来生成分类任务,计算公式如下:
[0196][0197]
其中ws和εs代表对应的学习参数,然后使用交叉熵表示分类损失。对于给定的m个学习样本本发明设计的multiatt网络的代价函数在可学习参数集δ={(wq,εq)|q=j,k,rj,e,y,s}中的定义为:
[0198][0199]
通过对multiatt网络模型的训练,服务器端能够高效且精准地对本地设备实时上传的传感器信号进行分类识别以及结果反馈。
[0200]
步骤(4):本地设备将上述预处理后的数据通过人体感知识别任务动态调度方法来进行动态任务调度;
[0201]
参考图3为人体感知识别任务动态调度方法执行流程图,包含以下步骤:
[0202]
步骤(4.1):定义调度方法相关参数;
[0203]
将对此次数据以计算任务的形式表示,其中i代表任务的编号,是对应任务输入的预处理后的传感器数据,是对应任务完成所需要的计算量。
[0204]
步骤(4.2):制定时间感知模型;
[0205]
判断人体行为识别任务是在本地移动设备上计算还是传输到指定服务器上计算,首先建立预计任务执行时间的计算模型,该模型获得传感器设备的cpu利用率,然后计算出任务请求到达时的本地执行时间:
[0206][0207]
其中f
local
代表传感设备的计算频率。
[0208]
任务在服务器上执行所需的计算时间是:
[0209][0210]
其中f
server
代表服务器设备的计算频率。
[0211]
计算完预计任务执行时间之后,构建计算预计任务传输时间的传输模型。可穿戴设备可以将计算需求转移到服务器上,以减少本地计算负载,在计算卸载的过程中需要考虑移动环境下的网络传输问题。在可穿戴设备卸载任务的过程中,传输节点的信噪比如下所示:
[0212][0213]
其中代表设备i在传输时的电压频率,代表设备i与当前边缘服务器之间的距离造成的信号干扰,α代表路径损失系数,βc代表卸载策略。如果βc=0,任务在本地执行,否则任务被卸载到远端服务器上。
[0214]
步骤(4.3):定义传输速率;
[0215]
在移动网络环境下,本地设备和服务器之间的传输速率定义如下:
[0216]rn
=blog2(1 f
snr
(d
i,n
))
[0217]
其中b代表用户设备和服务器之间的传输带宽。任务的传输时间为:
[0218][0219]
步骤(4.4):定义响应时间;
[0220]
响应时间包含任务上传至上行链路的上传时间,远端服务器中应用的执行时间和反馈给用户结果的下行链路的发送时间:
[0221][0222]
其中代表任务上传时间,是任务执行时间,是任务结果的下载时间。由于下载数据量小,所需的下载时间被忽略了,时间计算模型将得到的结果作为参考指标输出至后续模型决策。
[0223]
步骤(4.5):制定能耗感知模型;
[0224]
本地设备的能耗主要包括两部分,一部分是本地执行的能耗,另一部分是任务卸载的能耗,包括上传能耗和下载能耗。在计算设备的能量消耗时,应首先考虑本地运行任务的能量消耗。如果用户没有可用的服务器,或者任务不需要被卸载到服务器上,则允许在本地执行的任务。由智能感知设备本身产生的能耗被称为本地能耗,本地能耗的计算公式如下:
[0225][0226]
其中代表本地计算任务所需的时间,以及p
local
代表计算任务的电压频率。
[0227]
在任务调度过程中,由数据传输而产生的能量消耗被称为传输能耗,传输能耗可分为任务传输能耗和结果下载能耗,其计算公式如下:
[0228][0229]
其中代表任务传输的上传和下载时间,p
trans
代表任务传输的电压。能源消耗
模型的结果作为参考指标输出至后续模型决策。
[0230]
步骤(4.6):制定优化目标并完成模型决策;
[0231]
本发明以最小化能耗与响应时间为优化目标,目标函数可以表示为:
[0232][0233][0234][0235][0236]
其中e为设备能耗,λ为权重因子。权重因子λ反映了用户对于能耗与延时相对重要性的偏好,λ越高表明用户对于延时的要求越高,λ越低表明用户对于能耗要求越高,用户可以通过调整λ以提高应用对于不同场景的优化效果。对于延时敏感的应用,其对于延时的偏好要高于能耗,用户可以增加λ提高延时对于优化结果的影响。相应地,对于能耗敏感的应用,用户可以适当降低λ,以达到降低设备能耗的目的。
[0237]
选择在目标函数最小的设备端进行任务执行,若为本地执行,则跳转至步骤(5);若为远端服务器执行,则返回至步骤(3)。
[0238]
步骤(5):利用multiatt反馈的贡献分值向量为xgboost的输入通道数据进行阈值筛选,并对调度到本地设备的数据使用xgboost拓展决策树算法进行行为识别:
[0239]
xgboost算法在针对人体行为识别的场景下具有高效的识别能力,其目标函数为:
[0240][0241]
其中,f(y,f(x))代表损失函数,ω(fm)是正则项,代表模型的复杂性。与传统网络gbdt相比,xgboost中增加的正则化项目在避免网络过度拟合的同时简化了模型,第m次迭代的目标函数的计算方法如下:
[0242][0243]
对上式进行二阶tailor扩展为:
[0244][0245]
其中,gi和hi分别为损失函数的一阶梯度和二阶梯度统计,计算公式如下:
[0246][0247][0248]
对上式去除常数项之后,可以得到:
[0249][0250]
根据cart理论,fm(x)可以由决策树的结构p(x)和叶子节点的权重w决定,公式如下:
[0251]fm
(x)=w
p(x)
,w∈r
t
,p:rd→
{1,2,
…
t}
[0252]
其中,p(x)是一个用于将样本映射到叶子节点的映射,代表树的结构。t代表树结构中叶子节点的数量。而正则化项可以被定义为:
[0253][0254]
其中,λ是一个用来调整惩罚因子的参数,γ代表每片叶子节点的复杂程度。整合上述三个公式,得到:
[0255][0256]
其中,ij={i∣p(xi)=j}是叶子节点j对应的样本集,gj=∑gi,hj=∑hi。
[0257]
xgboost算法执行流程
[0258]
当p(xi)确定时,网络可以通过训练计算出叶子节点j对应的最佳权重wj以及对应的目标函数值,得到xgb用来对决策树的结构进行评估:
[0259][0260][0261]
为了得到构建树形结构的最佳参数,本方法采用贪心策略,即通过遍历各个特征数值,选取相应于最大增益的特征值以进行节点的分割。通过节点分割贪心算法,可以得出分割后的收益值rev,计算公式如下:
[0262][0263]
为了实现xgboost在人体行为识别中的最佳性能,需要对网络结构中的参数进行调整。一般来说,使用交叉验证的方式对xgboost的以下参数进行优化:
[0264]
子树数量:在训练过程中,子树数量对应迭代次数。子树结构越多,通常xgboost的模型性能会越好,但是训练时间也会随之提升。
[0265]
学习率:学习率越低,训练得到模型的稳健性越强并且性能越佳,但是对迭代次数以及训练数据的要求也会越高。
[0266]
gamma值:在xgboost中,gamma值指定了损失函数的最小下降值,仅在分裂后损失
函数值降低时,才会执行节点分裂操作。gamma值越大,算法会越保守。
[0267]
l1正则化权重和l2正则化权重:这两个参数可以防止过度拟合。
[0268]
树的最大深度:树的深度越大,模型复杂性越高。
[0269]
模型的复杂性:该参数代表叶子节点样本的最小权重和,也是用来防止过度拟合。
[0270]
通过模型训练出上述参数的较好取值,得到完整的xgboost拓展决策网络模型,通过节点分割方式的优化,该模型可以高效地完成移动端的人体行为识别任务并且把分类结果进行交互反馈。同时在本地设备端计算性能有限的前提下,改进过的xgboost拓展决策网络模型在同类型网络学习算法中有着优异的识别性能。
[0271]
以下对融合拓展决策和注意力网络的行为动态识别模型所使用的算法与其他传统人体行为识别算法进行比较:
[0272]
本发明的实验在intel core i9-11900k@3.50ghz,nvidia geforce rtx 3080ti(12gb)gpu,window10专业版系统下,使用基于keras 2.2.0和tensorflow 1.14.0深度学习框架进行模型构建与数据训练。训练的样本数据集为自采集的phad人体行为数据集与相关领域常用数据集wisdm、uci-har、opportunity,从多个评价指标综合对模型中的主要算法multiatt进行性能评估。
[0273]
首先,本节比较了各种信道数目条件下相关领域主流人体行为识别算法与multiatt算法在四个数据集中的精确率情况,具体数值结果如表1和表2所示:
[0274]
表1基于6
×
channel人体行为数据的性能(精确率
±
均方误差)比较
[0275][0276]
表2基于12
×
channel人体行为数据的性能(精确率
±
均方误差)比较
[0277][0278]
从中可以看出,当训练数据维度增加时,multiatt算法对于各个数据集上的识别效果都有着较大的提升,并且当通道维度变为12时,该算法性在各数据集上和其他对比算法都有着一定的领先。multiatt算法通过融合注意力机制对多通道人体行为数据提取关键信息,可以对多通道的数据及逆行更精确分析,从而显著提升人体行为识别效果。
[0279]
为了更进一步地评估multiatt算法在服务器端识别相似行为动作的情况,本节在uci-har和phad两个数据集上进行了psvm算法、mcnn算法、mssda算法和channelattloc算法的具体实现。各算法在两种数据集上的精确率数值对比如表3和表4所示。
[0280]
表3 uci-har数据集算法精确率对比(%)
[0281][0282]
表4 phad数据集算法精确率对比(%)
[0283][0284]
参考图4和图5,本发明方法在uci-har数据集中,走、上楼、下楼、坐、站、躺六个动作的分类预测精确率分别为96.27、95.2、95.64、95.49、97.18、96.91;在phad数据集中,走、上楼、下楼、坐、站、跑六个动作的分类预测精确率分别为96.25、93.3、93.08、97.21、98.82、94.11。可以看出除了个别动作,绝大多数情况下本发明所使用multiatt算法动作分类精确率相较于对比算法都有着极大地提升。
[0285]
参考图6为本发明在本地设备端所使用的xgboost算法与其他五个常用的分类器,即:random forest、gbdt、mlp、svm和knn进行识别准确率比较,并采用了十折交叉验证的方法来寻找xgboost的最佳参数组合,以防止过度拟合。在实验中,训练集被分为十个部分,随机选取其中九个作为训练数据,其余的作为测试数据。
[0286]
参考图7可见,随着受试者数量的增加,算法的平均准确率降低。以xgboost分类器为例,当被测试人数分别为1、10和40的情况下,对应平均准确率为99.63%、92.03%和87.41%。究其原因在于个体的特点与行为习惯不同导致对于相同运动,不同受试者的行为数据采集都会有较大的变化。如果分类器仅基于单个个体采集得到的数据进行训练,则其准确率最高,因为其自身数据用于预测,所有个性化数据都包含在训练和预测中。此外,对于单个个体采集的数据,所有六个分类器的性能都非常相似,准确率高于98%。
[0287]
然而,在这种情况下,受试者太少,导致模型的泛化能力低,容易出现过度拟合。尽管准确率随着被试数量的增加而降低,但与其他算法对比,xgboost在保持较高准确率的同时也更具有鲁棒性。实验混淆矩阵参考图8和图9,上楼、下楼和走三种运动行为数据之间,以及坐与站或者躺的两种静止行为数据之间较为容易混淆,其平均准确率较低,导致整体准确率偏低。原因在于行为间高度相似的运动方式导致所提取特征也有着高度的相似性,从而造成混淆,与上述活动比较,跑行为的识别准确率就明显较高。通过混淆矩阵可以看出,xgboost分类器通过加入正则项至代价函数中来防止过拟合方式,对于易混淆数据也都保持了较好的识别结果。
[0288]
综上所述,本发明设计融合拓展决策和注意力网络的行为动态识别模型中两种主要算法能够更有效地完成人体行为识别任务,相比其他算法综合性能得到提升。同时算法在满足识别效果前提下有着较快的模型训练与识别速度,结合人体感知识别任务动态调度方法,能够实现在移动设备的计算能力以及能耗等因素受限场景下,较为实时地对人体行为数据进行识别和交互反馈,针对不同应用场景进行自适应调整,并且兼顾性能以及效果。
[0289]
以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。因此,本公开将不会被限制于本公开所示的这些实施例,而是要符合与本公开所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。